Mit gespeicherten Fertigstellungen können Sie den Unterhaltungsverlauf aus Chatabschlusssitzungen erfassen, die als Datasets für Auswertungen und Feinabstimmungen verwendet werden.
Support für gespeicherte Vervollständigungen
Modell- und Regionsverfügbarkeit
Solange Sie die Chatabschluss-API für die Ableitung verwenden, können Sie gespeicherte Fertigstellungen nutzen. Sie wird für alle Azure OpenAI-Modelle und in allen unterstützten Regionen (einschließlich globaler Regionen) unterstützt.
Um gespeicherte Fertigstellungen für Ihre Azure OpenAI-Bereitstellung zu aktivieren, legen Sie die Einstellung store auf True fest. Verwenden Sie die Einstellungmetadata, um das gespeicherte Fertigstellungs-Dataset mit zusätzlichen Informationen zu erweitern.
import os
from openai import OpenAI
from azure.identity import DefaultAzureCredential, get_bearer_token_provider
token_provider = get_bearer_token_provider(
DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default"
)
client = OpenAI(
base_url="https://YOUR-RESOURCE-NAME.openai.azure.com/openai/v1/",
api_key=token_provider,
)
completion = client.chat.completions.create(
model="gpt-4o", # replace with model deployment name
store= True,
metadata = {
"user": "admin",
"category": "docs-test",
},
messages=[
{"role": "system", "content": "Provide a clear and concise summary of the technical content, highlighting key concepts and their relationships. Focus on the main ideas and practical implications."},
{"role": "user", "content": "Ensemble methods combine multiple machine learning models to create a more robust and accurate predictor. Common techniques include bagging (training models on random subsets of data), boosting (sequentially training models to correct previous errors), and stacking (using a meta-model to combine base model predictions). Random Forests, a popular bagging method, create multiple decision trees using random feature subsets. Gradient Boosting builds trees sequentially, with each tree focusing on correcting the errors of previous trees. These methods often achieve better performance than single models by reducing overfitting and variance while capturing different aspects of the data."}
]
)
print(completion.choices[0].message)
Von Bedeutung
Verwenden Sie API-Schlüssel mit Vorsicht. Fügen Sie den API-Schlüssel nicht direkt in Ihren Code ein, und machen Sie ihn nicht öffentlich zugänglich. Wenn Sie einen API-Schlüssel verwenden, speichern Sie ihn sicher in Azure Key Vault. Weitere Informationen zur sicheren Verwendung von API-Schlüsseln in Ihren Apps finden Sie unter API-Schlüssel mit Azure Key Vault.
Weitere Informationen zur Sicherheit von KI-Diensten finden Sie unter Authentifizieren von Anforderungen an Azure AI-Dienste.
import os
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
base_url="https://YOUR-RESOURCE-NAME.openai.azure.com/openai/v1/"
)
completion = client.chat.completions.create(
model="gpt-4o", # replace with model deployment name
store= True,
metadata = {
"user": "admin",
"category": "docs-test",
},
messages=[
{"role": "system", "content": "Provide a clear and concise summary of the technical content, highlighting key concepts and their relationships. Focus on the main ideas and practical implications."},
{"role": "user", "content": "Ensemble methods combine multiple machine learning models to create a more robust and accurate predictor. Common techniques include bagging (training models on random subsets of data), boosting (sequentially training models to correct previous errors), and stacking (using a meta-model to combine base model predictions). Random Forests, a popular bagging method, create multiple decision trees using random feature subsets. Gradient Boosting builds trees sequentially, with each tree focusing on correcting the errors of previous trees. These methods often achieve better performance than single models by reducing overfitting and variance while capturing different aspects of the data."}
]
)
print(completion.choices[0].message)
Microsoft Entra ID
curl $AZURE_OPENAI_ENDPOINT/openai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $AZURE_OPENAI_AUTH_TOKEN" \
-d '{
"model": "gpt-4o",
"store": true,
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Hello!"
}
]
}'
API-Schlüssel
curl $AZURE_OPENAI_ENDPOINT/openai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{
"model": "gpt-4o",
"store": true,
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Hello!"
}
]
}'
{
"id": "chatcmpl-B4eQ716S5wGUyFpGgX2MXnJEC5AW5",
"choices": [
{
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"message": {
"content": "Ensemble methods enhance machine learning performance by combining multiple models to create a more robust and accurate predictor. The key techniques include:\n\n1. **Bagging (Bootstrap Aggregating)**: Involves training multiple models on random subsets of the data to reduce variance and overfitting. A popular method within bagging is Random Forests, which build numerous decision trees using random subsets of features and data samples.\n\n2. **Boosting**: Focuses on sequentially training models, where each new model attempts to correct the errors made by previous ones. Gradient Boosting is a common boosting technique that builds trees sequentially, concentrating on the mistakes of earlier trees to improve accuracy.\n\n3. **Stacking**: Uses a meta-model to combine predictions from various base models, leveraging their strengths to enhance overall predictions.\n\nThese ensemble methods generally outperform individual models because they effectively handle overfitting, reduce variance, and capture diverse aspects of the data. In practical applications, they are valued for their ability to improve model accuracy and stability.",
"refusal": null,
"role": "assistant",
"audio": null,
"function_call": null,
"tool_calls": null
},
"content_filter_results": {
"hate": {
"filtered": false,
"severity": "safe"
},
"protected_material_code": {
"filtered": false,
"detected": false
},
"protected_material_text": {
"filtered": false,
"detected": false
},
"self_harm": {
"filtered": false,
"severity": "safe"
},
"sexual": {
"filtered": false,
"severity": "safe"
},
"violence": {
"filtered": false,
"severity": "safe"
}
}
}
],
"created": 1740448387,
"model": "gpt-4o-2024-08-06",
"object": "chat.completion",
"service_tier": null,
"system_fingerprint": "fp_b705f0c291",
"usage": {
"completion_tokens": 205,
"prompt_tokens": 157,
"total_tokens": 362,
"completion_tokens_details": {
"accepted_prediction_tokens": 0,
"audio_tokens": 0,
"reasoning_tokens": 0,
"rejected_prediction_tokens": 0
},
"prompt_tokens_details": {
"audio_tokens": 0,
"cached_tokens": 0
}
},
"prompt_filter_results": [
{
"prompt_index": 0,
"content_filter_results": {
"hate": {
"filtered": false,
"severity": "safe"
},
"jailbreak": {
"filtered": false,
"detected": false
},
"self_harm": {
"filtered": false,
"severity": "safe"
},
"sexual": {
"filtered": false,
"severity": "safe"
},
"violence": {
"filtered": false,
"severity": "safe"
}
}
}
]
}
Sobald gespeicherte Fertigstellungen für eine Azure OpenAI-Bereitstellung aktiviert sind, werden sie im Azure AI Foundry-Portal im Bereich gespeicherte Fertigstellungen angezeigt.
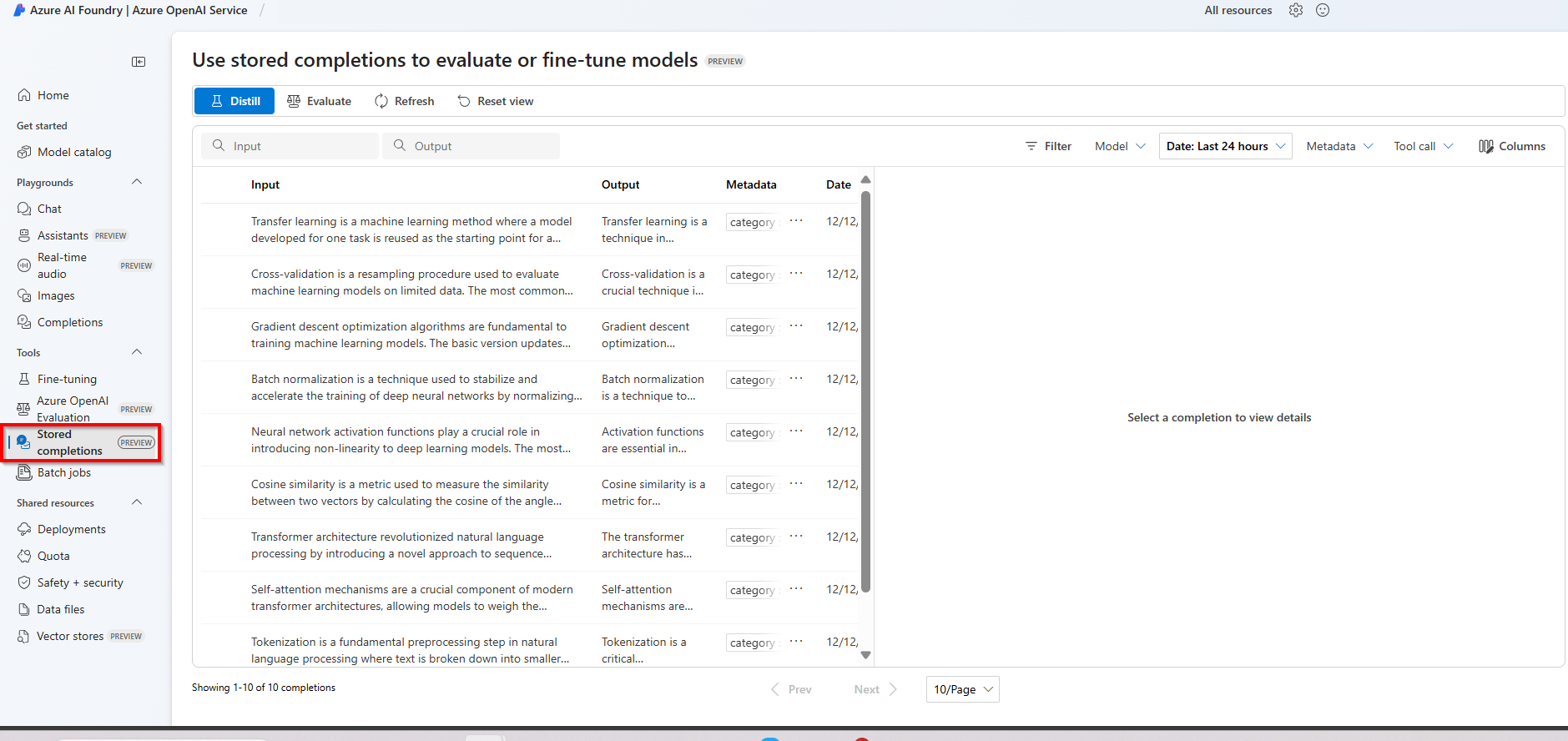
Destillation
Mit der Destillation können Sie Ihre gespeicherten Fertigstellungen in ein fein abgestimmtes Dataset umwandeln. Ein gängiger Anwendungsfall ist die Verwendung gespeicherter Fertigstellungen mit einem größeren, leistungsfähigeren Modell für eine bestimmte Aufgabe und die anschließende Verwendung der gespeicherten Fertigstellungen zum Trainieren eines kleineren Modells anhand hochwertiger Beispiele für Modellinteraktionen.
Für die Destillation sind mindestens 10 gespeicherte Fertigstellungen erforderlich. Es wird jedoch empfohlen, Hunderte bis Tausende von gespeicherten Fertigstellungen bereitzustellen, um die besten Ergebnisse zu erzielen.
Verwenden Sie im Bereich gespeicherte Fertigstellungenim Azure AI Foundry-Portal die Optionen Filter, um die Fertigstellungen auszuwählen, mit denen Sie Ihr Modell trainieren möchten.
Um mit der Destillation zu beginnen, wählen Sie Destillieren aus
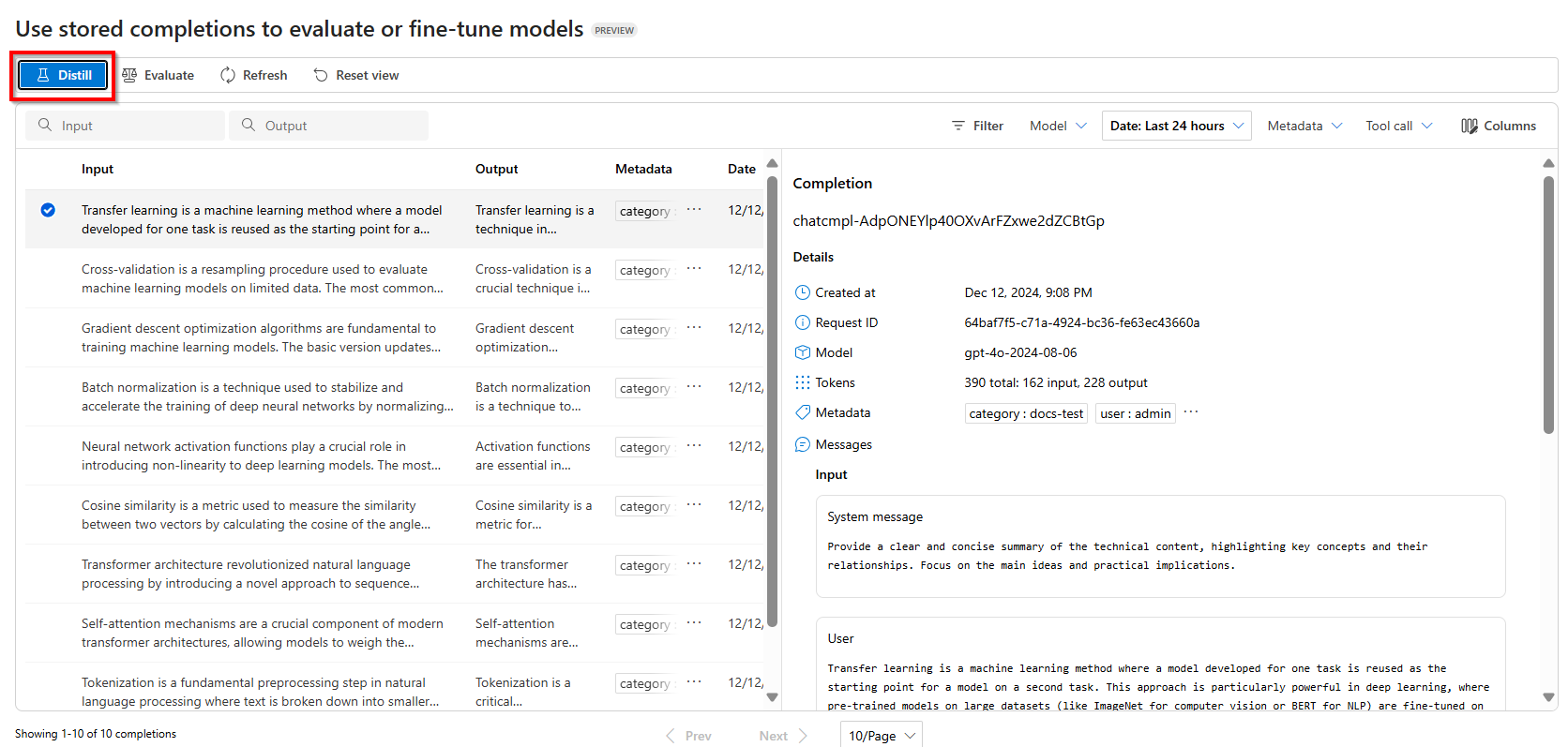
Wählen Sie das Modell aus, das Sie mit Ihrem gespeicherten Fertigstellungs-Dataset optimieren möchten.
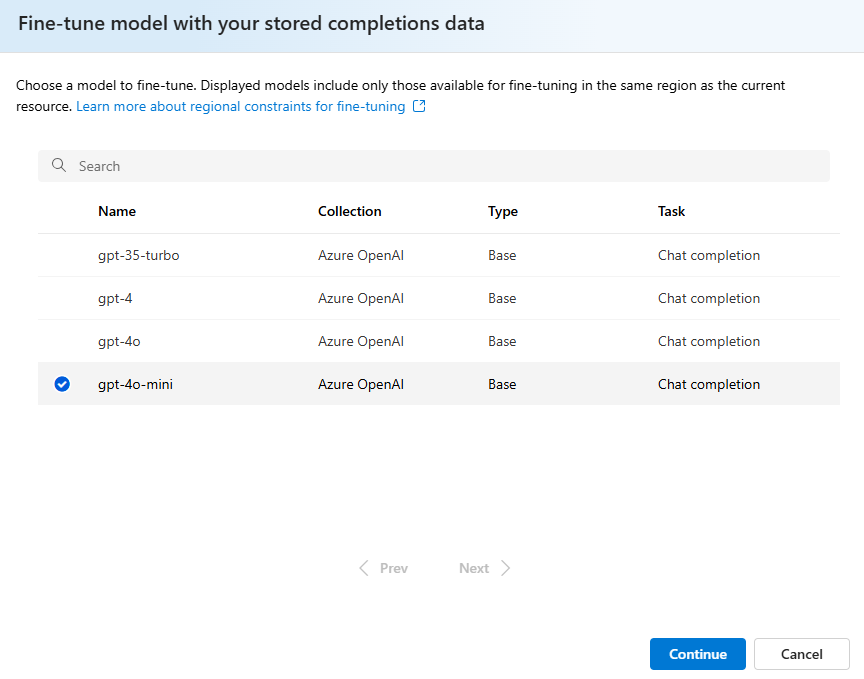
Bestätigen Sie, welche Version des Modells Sie optimieren möchten:
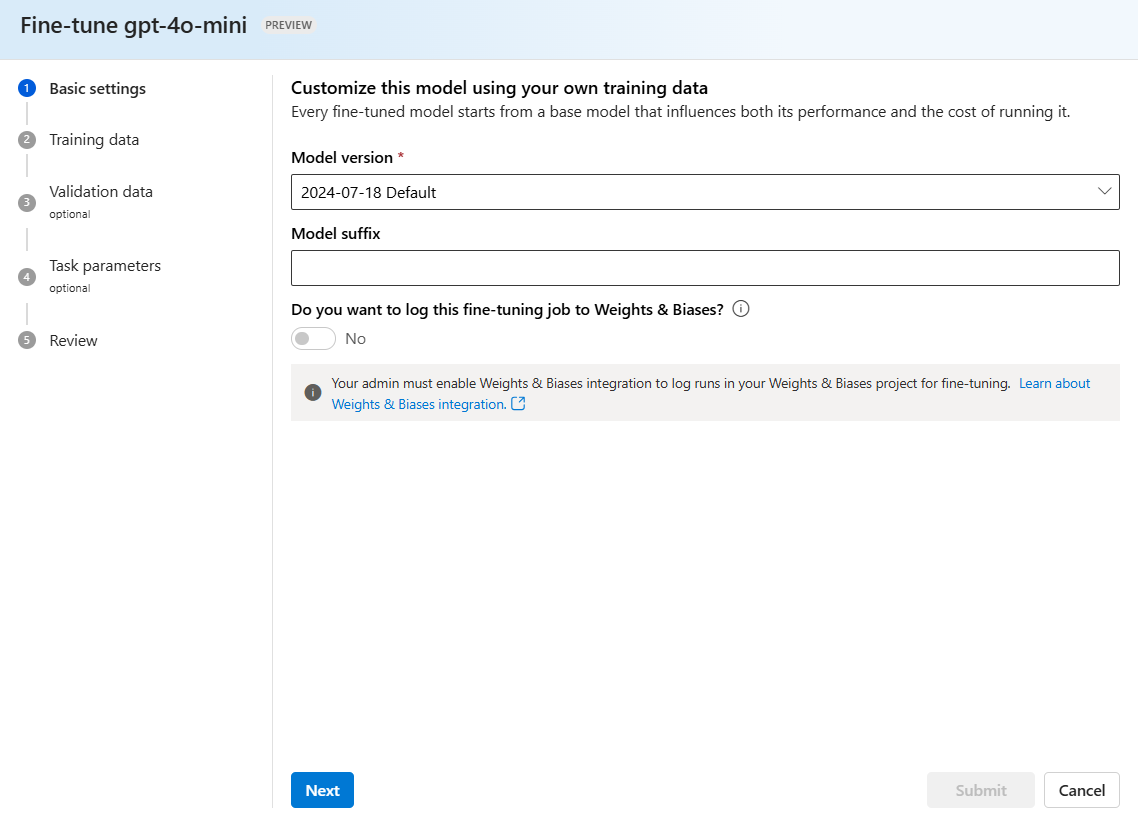
Eine .jsonl-Datei mit einem zufällig generierten Namen wird als Schulungs-Dataset aus Ihren gespeicherten Fertigstellungen erstellt. Wählen Sie die Datei >Weiter aus.
Hinweis
Auf gespeicherte Fertigstellungs-destillationsschulungsdateien kann nicht direkt zugegriffen werden und sie können nicht extern exportiert bzw. heruntergeladen werden.
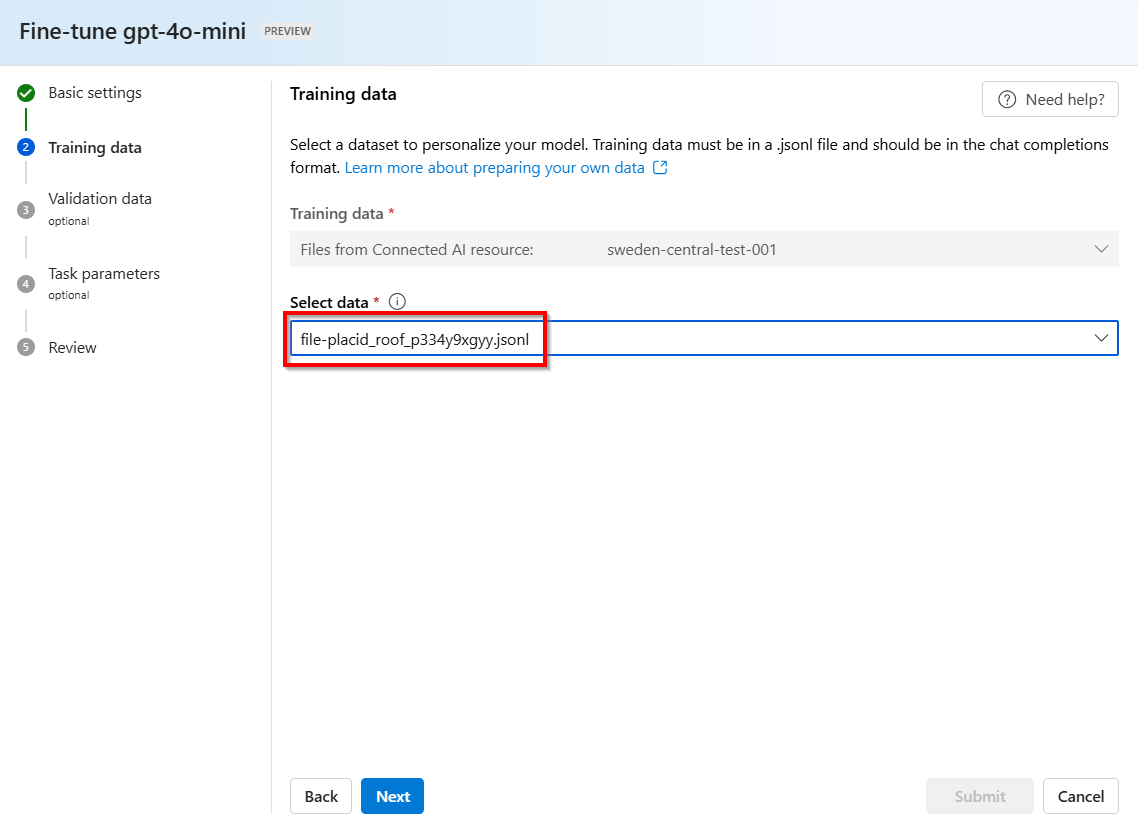
Die restlichen Schritte entsprechen den typischen Azure OpenAI-Optimierungsschritten. Weitere Informationen finden Sie im Leitfaden: Erste Schritte zur Optimierung.
Auswertung
Die Auswertung großer Sprachmodelle ist ein wichtiger Schritt bei der Messung ihrer Leistung über verschiedene Aufgaben und Dimensionen hinweg. Dies ist besonders wichtig für fein abgestimmte Modelle, bei denen die Beurteilung der Leistungsgewinne (oder Verluste) aus dem Training von entscheidender Bedeutung ist. Gründliche Auswertungen können Ihnen dabei helfen, zu verstehen, wie sich verschiedene Versionen des Modells auf Ihre Anwendung oder Ihr Szenario auswirken können.
Gespeicherte Fertigstellungen können als Dataset für laufende Auswertungen verwendet werden.
Verwenden Sie im Bereich gespeicherte Fertigstellungenim Azure AI Foundry-Portal die Optionen Filter, um die Fertigstellungen auszuwählen, die Teil Ihres Auswertungs-Dataset sein sollen.
Um die Auswertung zu konfigurieren, wählen Sie Auswerten aus
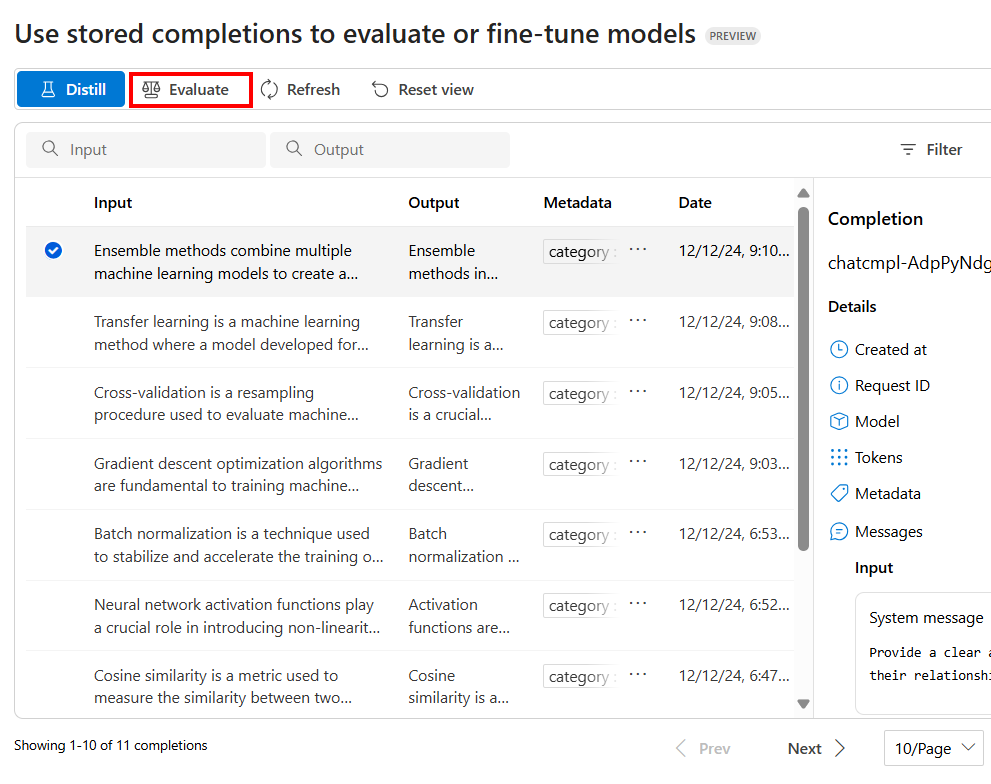
Dadurch wird der Bereich Auswertungen mit einer vorausgefüllten .jsonl-Datei mit einem zufällig generierten Namen gestartet, die als Auswertungs-Dataset aus Ihren gespeicherten Fertigstellungen erstellt wird.
Hinweis
Auf gespeicherte Fertigstellungs-Bewertungsdatendateien kann nicht direkt zugegriffen und sie können nicht extern exportiert bzw. heruntergeladen werden.
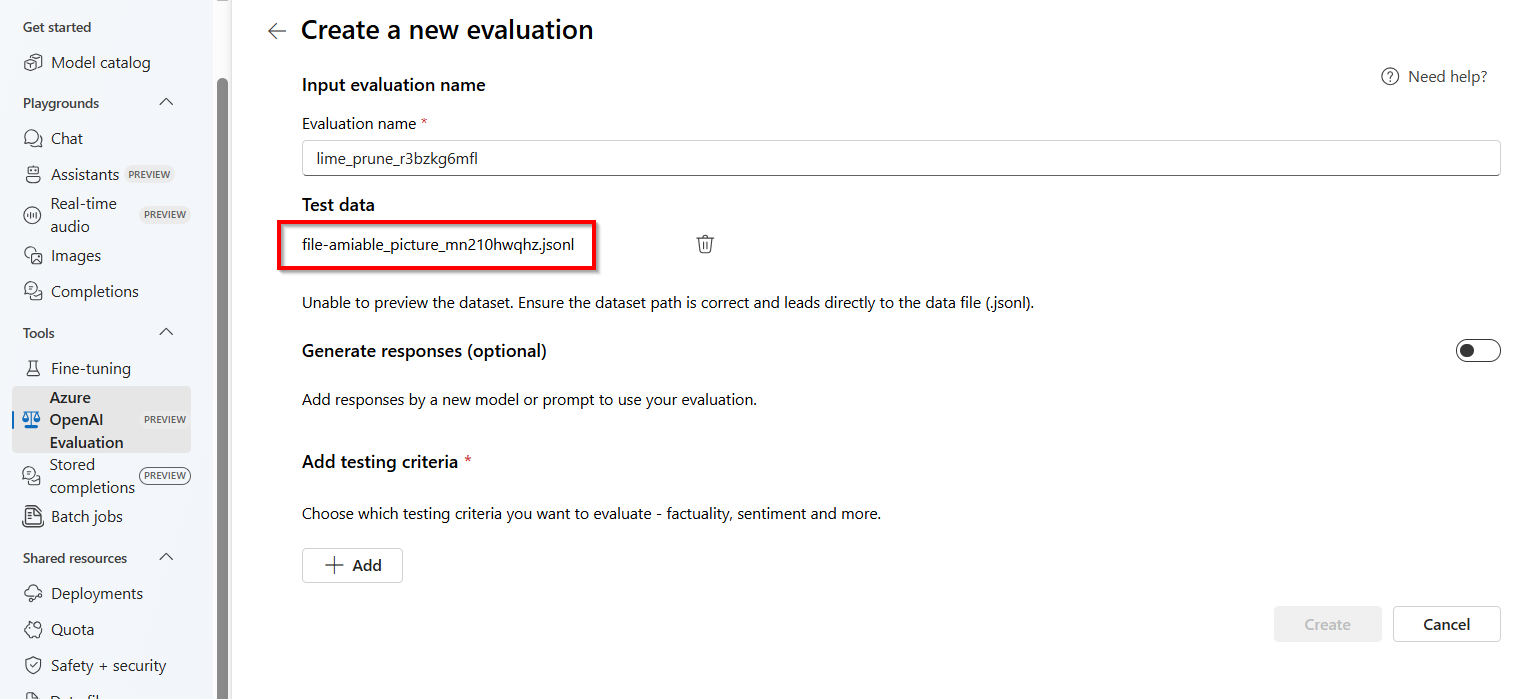
Weitere Informationen zur Auswertung finden Sie unter Erste Schritte mit Auswertungen
API für gespeicherte Fertigstellungen
Um auf die gespeicherten Vervollständigungs-API-Befehle zuzugreifen, müssen Sie möglicherweise Ihre Version der OpenAI-Bibliothek aktualisieren.
pip install --upgrade openai
Liste gespeicherter Vervollständigungen
Zusätzliche Parameter:
-
metadata: Filtern nach dem Schlüssel-Wert-Paar in den gespeicherten Vervollständigungen
-
after: Bezeichner für die letzte gespeicherte Abschlussnachricht aus der vorherigen Paginierungsanforderung.
-
limit: Anzahl der gespeicherten Abschlussmeldungen, die abgerufen werden sollen.
-
order: Reihenfolge der Ergebnisse nach Index (aufsteigend oder absteigend).
from openai import OpenAI
from azure.identity import DefaultAzureCredential, get_bearer_token_provider
token_provider = get_bearer_token_provider(
DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default"
)
client = OpenAI(
base_url="https://YOUR-RESOURCE-NAME.openai.azure.com/openai/v1/",
api_key=token_provider,
)
response = client.chat.completions.list()
print(response.model_dump_json(indent=2))
from openai import OpenAI
client = OpenAI(
base_url="https://YOUR-RESOURCE-NAME.openai.azure.com/openai/v1/",
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
)
response = client.chat.completions.list()
print(response.model_dump_json(indent=2))
Microsoft Entra ID
curl https://YOUR-RESOURCE-NAME.openai.azure.com/openai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $AZURE_OPENAI_AUTH_TOKEN" \
API-Schlüssel
curl https://YOUR-RESOURCE-NAME.openai.azure.com/openai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
{
"data": [
{
"id": "chatcmpl-A1bC2dE3fH4iJ5kL6mN7oP8qR9sT0u",
"choices": [
{
"finish_reason": null,
"index": 0,
"logprobs": null,
"message": {
"content": "Ensemble methods enhance machine learning performance by combining multiple models to create a more robust and accurate predictor. The key techniques include:\n\n1. **Bagging (Bootstrap Aggregating):** This involves training models on random subsets of the data to reduce variance and prevent overfitting. Random Forests, a popular bagging method, build multiple decision trees using random feature subsets, leading to robust predictions.\n\n2. **Boosting:** This sequential approach trains models to correct the errors of their predecessors, thereby focusing on difficult-to-predict data points. Gradient Boosting is a common implementation that sequentially builds decision trees, each improving upon the prediction errors of the previous ones.\n\n3. **Stacking:** This technique uses a meta-model to combine the predictions of multiple base models, leveraging their diverse strengths to enhance overall prediction accuracy.\n\nThe practical implications of ensemble methods include achieving superior model performance compared to single models by capturing various data patterns and reducing overfitting and variance. These methods are widely used in applications where high accuracy and model reliability are critical.",
"refusal": null,
"role": "assistant",
"audio": null,
"function_call": null,
"tool_calls": null
}
}
],
"created": 1740447656,
"model": "gpt-4o-2024-08-06",
"object": null,
"service_tier": null,
"system_fingerprint": "fp_b705f0c291",
"usage": {
"completion_tokens": 208,
"prompt_tokens": 157,
"total_tokens": 365,
"completion_tokens_details": null,
"prompt_tokens_details": null
},
"request_id": "0000aaaa-11bb-cccc-dd22-eeeeee333333",
"seed": -430976584126747957,
"top_p": 1,
"temperature": 1,
"presence_penalty": 0,
"frequency_penalty": 0,
"metadata": {
"user": "admin",
"category": "docs-test"
}
}
],
"has_more": false,
"object": "list",
"total": 1,
"first_id": "chatcmpl-A1bC2dE3fH4iJ5kL6mN7oP8qR9sT0u",
"last_id": "chatcmpl-A1bC2dE3fH4iJ5kL6mN7oP8qR9sT0u"
}
Abrufen der gespeicherten Vervollständigung
Rufen Sie die gespeicherte Vervollständigung nach ID ab.
from openai import OpenAI
from azure.identity import DefaultAzureCredential, get_bearer_token_provider
token_provider = get_bearer_token_provider(
DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default"
)
client = OpenAI(
base_url="https://YOUR-RESOURCE-NAME.openai.azure.com/openai/v1/",
api_key=token_provider
)
response = client.chat.completions.retrieve("chatcmpl-A1bC2dE3fH4iJ5kL6mN7oP8qR9sT0u")
print(response.model_dump_json(indent=2))
from openai import OpenAI
client = OpenAI(
base_url="https://YOUR-RESOURCE-NAME.openai.azure.com/openai/v1/",
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
)
response = client.chat.completions.retrieve("chatcmpl-A1bC2dE3fH4iJ5kL6mN7oP8qR9sT0u")
print(response.model_dump_json(indent=2))
Microsoft Entra ID
curl https://YOUR-RESOURCE-NAME.openai.azure.com/openai/v1/chat/completions/chatcmpl-A1bC2dE3fH4iJ5kL6mN7oP8qR9sT0u \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $AZURE_OPENAI_AUTH_TOKEN" \
API-Schlüssel
curl https://YOUR-RESOURCE-NAME.openai.azure.com/openai/v1/chat/completions/chatcmpl-A1bC2dE3fH4iJ5kL6mN7oP8qR9sT0u \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
{
"id": "chatcmpl-A1bC2dE3fH4iJ5kL6mN7oP8qR9sT0u",
"choices": [
{
"finish_reason": null,
"index": 0,
"logprobs": null,
"message": {
"content": "Ensemble methods enhance machine learning performance by combining multiple models to create a more robust and accurate predictor. The key techniques include:\n\n1. **Bagging (Bootstrap Aggregating):** This involves training models on random subsets of the data to reduce variance and prevent overfitting. Random Forests, a popular bagging method, build multiple decision trees using random feature subsets, leading to robust predictions.\n\n2. **Boosting:** This sequential approach trains models to correct the errors of their predecessors, thereby focusing on difficult-to-predict data points. Gradient Boosting is a common implementation that sequentially builds decision trees, each improving upon the prediction errors of the previous ones.\n\n3. **Stacking:** This technique uses a meta-model to combine the predictions of multiple base models, leveraging their diverse strengths to enhance overall prediction accuracy.\n\nThe practical implications of ensemble methods include achieving superior model performance compared to single models by capturing various data patterns and reducing overfitting and variance. These methods are widely used in applications where high accuracy and model reliability are critical.",
"refusal": null,
"role": "assistant",
"audio": null,
"function_call": null,
"tool_calls": null
}
}
],
"created": 1740447656,
"model": "gpt-4o-2024-08-06",
"object": "chat.completion",
"service_tier": null,
"system_fingerprint": "fp_b705f0c291",
"usage": {
"completion_tokens": 208,
"prompt_tokens": 157,
"total_tokens": 365,
"completion_tokens_details": null,
"prompt_tokens_details": null
},
"request_id": "0000aaaa-11bb-cccc-dd22-eeeeee333333",
"seed": -430976584126747957,
"top_p": 1,
"temperature": 1,
"presence_penalty": 0,
"frequency_penalty": 0,
"metadata": {
"user": "admin",
"category": "docs-test"
}
}
Abrufen gespeicherter Nachrichten für Chatvervollständigungen
Zusätzliche Parameter:
-
after: Bezeichner für die letzte gespeicherte Abschlussnachricht aus der vorherigen Paginierungsanforderung.
-
limit: Anzahl der gespeicherten Abschlussmeldungen, die abgerufen werden sollen.
-
order: Reihenfolge der Ergebnisse nach Index (aufsteigend oder absteigend).
from openai import OpenAI
from azure.identity import DefaultAzureCredential, get_bearer_token_provider
token_provider = get_bearer_token_provider(
DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default"
)
client = OpenAI(
base_url="https://YOUR-RESOURCE-NAME.openai.azure.com/openai/v1/",
api_key=token_provider,
)
response = client.chat.completions.messages.list("chatcmpl-A1bC2dE3fH4iJ5kL6mN7oP8qR9sT0u", limit=2)
print(response.model_dump_json(indent=2))
from openai import OpenAI
client = OpenAI(
base_url="https://YOUR-RESOURCE-NAME.openai.azure.com/openai/v1/",
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
)
response = client.chat.completions.messages.list("chatcmpl-A1bC2dE3fH4iJ5kL6mN7oP8qR9sT0u", limit=2)
print(response.model_dump_json(indent=2))
Microsoft Entra ID
curl https://YOUR-RESOURCE-NAME.openai.azure.com/openai/v1/chat/completions/chatcmpl-A1bC2dE3fH4iJ5kL6mN7oP8qR9sT0u/messages \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $AZURE_OPENAI_AUTH_TOKEN" \
API-Schlüssel
curl https://YOUR-RESOURCE-NAME.openai.azure.com/openai/v1/chat/completions/chatcmpl-A1bC2dE3fH4iJ5kL6mN7oP8qR9sT0u/messages \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
{
"data": [
{
"content": "Provide a clear and concise summary of the technical content, highlighting key concepts and their relationships. Focus on the main ideas and practical implications.",
"refusal": null,
"role": "system",
"audio": null,
"function_call": null,
"tool_calls": null,
"id": "chatcmpl-A1bC2dE3fH4iJ5kL6mN7oP8qR9sT0u-0"
},
{
"content": "Ensemble methods combine multiple machine learning models to create a more robust and accurate predictor. Common techniques include bagging (training models on random subsets of data), boosting (sequentially training models to correct previous errors), and stacking (using a meta-model to combine base model predictions). Random Forests, a popular bagging method, create multiple decision trees using random feature subsets. Gradient Boosting builds trees sequentially, with each tree focusing on correcting the errors of previous trees. These methods often achieve better performance than single models by reducing overfitting and variance while capturing different aspects of the data.",
"refusal": null,
"role": "user",
"audio": null,
"function_call": null,
"tool_calls": null,
"id": "chatcmpl-A1bC2dE3fH4iJ5kL6mN7oP8qR9sT0u-1"
}
],
"has_more": false,
"object": "list",
"total": 2,
"first_id": "chatcmpl-A1bC2dE3fH4iJ5kL6mN7oP8qR9sT0u-0",
"last_id": "chatcmpl-A1bC2dE3fH4iJ5kL6mN7oP8qR9sT0u-1"
}
Aktualisieren der Vervollständigungen des gespeicherten Chats
Fügen Sie einer vorhandenen gespeicherten Vervollständigung Metadatenschlüssel-Wert-Paare hinzu.
from openai import OpenAI
from azure.identity import DefaultAzureCredential, get_bearer_token_provider
token_provider = get_bearer_token_provider(
DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default"
)
client = AzureOpenAI(
base_url="https://YOUR-RESOURCE-NAME.openai.azure.com/openai/v1/",
api_key=token_provider,
)
response = client.chat.completions.update(
"chatcmpl-C2dE3fH4iJ5kL6mN7oP8qR9sT0uV1w",
metadata={"fizz": "buzz"}
)
print(response.model_dump_json(indent=2))
from openai import OpenAI
client = OpenAI(
base_url="https://YOUR-RESOURCE-NAME.openai.azure.com/openai/v1/",
api_key=os.getenv("AZURE_OPENAI_API_KEY")
)
response = client.chat.completions.update(
"chatcmpl-C2dE3fH4iJ5kL6mN7oP8qR9sT0uV1w",
metadata={"fizz": "buzz"}
)
print(response.model_dump_json(indent=2))
Microsoft Entra ID
curl -X https://YOUR-RESOURCE-NAME.openai.azure.com/openai/v1/chat/completions/chatcmpl-A1bC2dE3fH4iJ5kL6mN7oP8qR9sT0u \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $AZURE_OPENAI_AUTH_TOKEN"
-d '{
"metadata": {
"fizz": "buzz"
}
}'
API-Schlüssel
curl -X https://YOUR-RESOURCE-NAME.openai.azure.com/openai/v1/chat/completions/chatcmpl-A1bC2dE3fH4iJ5kL6mN7oP8qR9sT0u \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY"
-d '{
"metadata": {
"fizz": "buzz"
}
}'
"id": "chatcmpl-A1bC2dE3fH4iJ5kL6mN7oP8qR9sT0u",
"choices": [
{
"finish_reason": null,
"index": 0,
"logprobs": null,
"message": {
"content": "Ensemble methods enhance machine learning performance by combining multiple models to create a more robust and accurate predictor. The key techniques include:\n\n1. **Bagging (Bootstrap Aggregating):** This involves training models on random subsets of the data to reduce variance and prevent overfitting. Random Forests, a popular bagging method, build multiple decision trees using random feature subsets, leading to robust predictions.\n\n2. **Boosting:** This sequential approach trains models to correct the errors of their predecessors, thereby focusing on difficult-to-predict data points. Gradient Boosting is a common implementation that sequentially builds decision trees, each improving upon the prediction errors of the previous ones.\n\n3. **Stacking:** This technique uses a meta-model to combine the predictions of multiple base models, leveraging their diverse strengths to enhance overall prediction accuracy.\n\nThe practical implications of ensemble methods include achieving superior model performance compared to single models by capturing various data patterns and reducing overfitting and variance. These methods are widely used in applications where high accuracy and model reliability are critical.",
"refusal": null,
"role": "assistant",
"audio": null,
"function_call": null,
"tool_calls": null
}
}
],
"created": 1740447656,
"model": "gpt-4o-2024-08-06",
"object": "chat.completion",
"service_tier": null,
"system_fingerprint": "fp_b705f0c291",
"usage": {
"completion_tokens": 208,
"prompt_tokens": 157,
"total_tokens": 365,
"completion_tokens_details": null,
"prompt_tokens_details": null
},
"request_id": "0000aaaa-11bb-cccc-dd22-eeeeee333333",
"seed": -430976584126747957,
"top_p": 1,
"temperature": 1,
"presence_penalty": 0,
"frequency_penalty": 0,
"metadata": {
"user": "admin",
"category": "docs-test"
"fizz": "buzz"
}
}
Löschen der gespeicherten Chatvervollständigung
Löschen Sie die gespeicherte Vervollständigung nach Vervollständigungs-ID.
Microsoft Entra ID
from openai import OpenAI
from azure.identity import DefaultAzureCredential, get_bearer_token_provider
token_provider = get_bearer_token_provider(
DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default"
)
client = OpenAI(
base_url="https://YOUR-RESOURCE-NAME.openai.azure.com/openai/v1/",
api_key=token_provider
)
response = client.chat.completions.delete("chatcmpl-A1bC2dE3fH4iJ5kL6mN7oP8qR9sT0u")
print(response.model_dump_json(indent=2))
from openai import OpenAI
client = OpenAI(
base_url="https://YOUR-RESOURCE-NAME.openai.azure.com/openai/v1/",
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
)
response = client.chat.completions.delete("chatcmpl-A1bC2dE3fH4iJ5kL6mN7oP8qR9sT0u")
print(response.model_dump_json(indent=2))
curl -X DELETE -D - https://YOUR-RESOURCE-NAME.openai.azure.com/openai/v1/chat/completions/chatcmpl-A1bC2dE3fH4iJ5kL6mN7oP8qR9sT0u \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $AZURE_OPENAI_AUTH_TOKEN"
API-Schlüssel
curl -X DELETE -D - https://YOUR-RESOURCE-NAME.openai.azure.com/openai/v1/chat/completions/chatcmpl-A1bC2dE3fH4iJ5kL6mN7oP8qR9sT0u \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY"
"id"• "chatcmp1-A1bC2dE3fH4iJ5kL6mN7oP8qR9sT0u",
"deleted": true,
"object": "chat. completion. deleted"
Problembehandlung
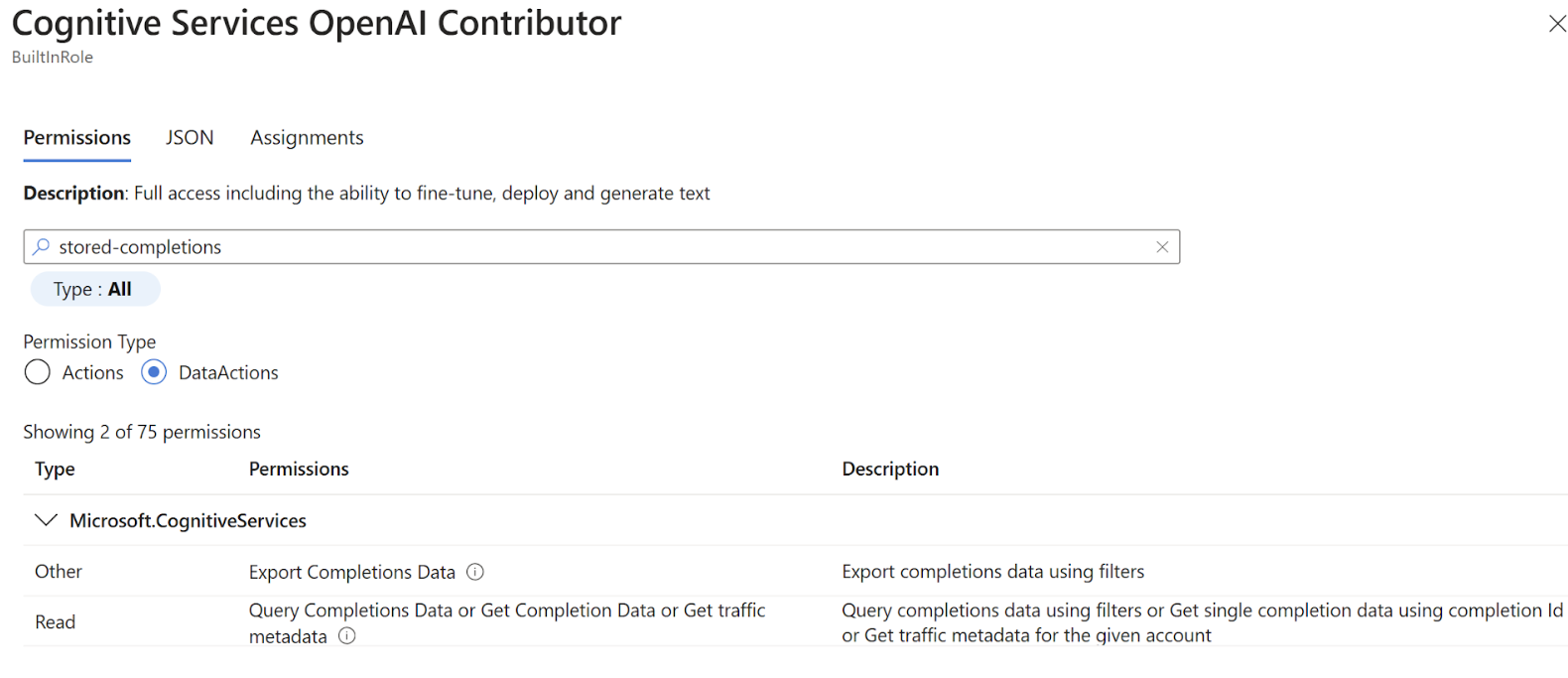
Benötige ich spezielle Berechtigungen, um gespeicherte Fertigstellungen zu verwenden?
Der Zugriff auf gespeicherte Fertigstellungen wird über zwei DataActions gesteuert:
Microsoft.CognitiveServices/accounts/OpenAI/stored-completions/readMicrosoft.CognitiveServices/accounts/OpenAI/stored-completions/action
Standardmäßig hat Cognitive Services OpenAI Contributor Zugriff auf beide Berechtigungen:
Wie lösche ich gespeicherte Daten?
Daten können gelöscht werden, indem die zugeordnete Azure OpenAI-Ressource gelöscht wird. Wenn Sie nur gespeicherte Fertigstellungsdaten löschen möchten, müssen Sie einen Fall beim Kundensupport öffnen.
Wie viel gespeicherte Fertigstellungsdaten kann ich speichern?
Sie können maximal 10 GB Daten speichern.
Kann ich verhindern, dass gespeicherte Fertigstellungen in einem Abonnement aktiviert werden?
Sie müssen einen Fall beim Kundensupport öffnen, um gespeicherte Fertigstellungen auf Abonnementebene zu deaktivieren.
TypeError: Completions.create() hat ein unerwartetes Argument "store" erhalten.
Dieser Fehler tritt auf, wenn Sie eine ältere Version der OpenAI-Clientbibliothek verwenden, die vor der Veröffentlichung der Funktion für gespeicherte Vervollständigungen veröffentlicht wurde. Führen Sie pip install openai --upgrade aus.







