Die Azure Monitor-Pipeline erweitert die Datenerfassungsfunktionen von Azure Monitor auf Edge- und Multicloud-Umgebungen. Es ermöglicht die Erfassung im großen Maßstab und das Routing von Telemetriedaten, bevor sie an die Cloud gesendet werden. Die Pipeline kann Daten lokal zwischenspeichern und mit der Cloud synchronisieren, wenn die Konnektivität wiederhergestellt wird, und Telemetrie an Azure Monitor weiterleiten, wenn das Netzwerk segmentiert ist und Daten nicht direkt an die Cloud gesendet werden können. In diesem Artikel wird beschrieben, wie Sie die Azure Monitor-Pipeline in Ihrer Umgebung aktivieren und konfigurieren.
Überblick
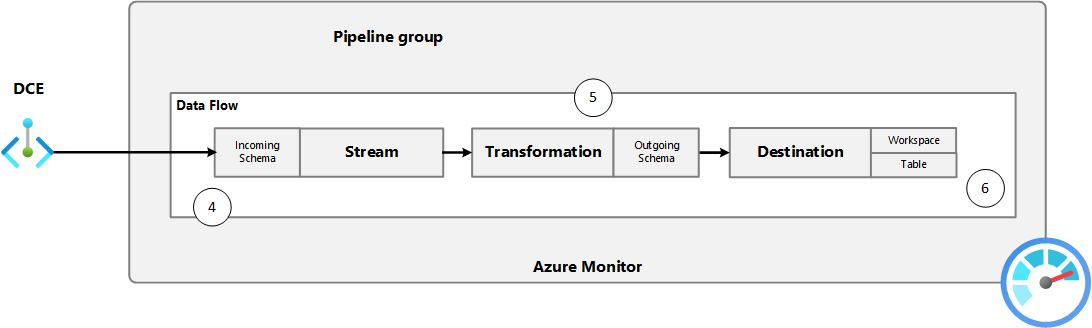
Die Azure Monitor-Pipeline ist eine containerisierte Lösung, die auf einem Arc-fähigen Kubernetes-Cluster bereitgestellt wird und openTelemetry Collector als Grundlage nutzt. Das folgende Diagramm zeigt die Komponenten der Pipeline. Mindestens ein Datenfluss lauscht auf eingehende Daten von Clients, und die Pipelineerweiterung leitet die Daten an die Cloud weiter – bei Bedarf unter Verwendung des lokalen Cache.
Die Pipelinekonfigurationsdatei definiert die Datenflüsse und Cacheeigenschaften für die Pipeline. Der DCR definiert das Schema der Daten, die an die Cloud gesendet werden, eine Transformation zum Filtern oder Ändern der Daten und das Ziel, an das die Daten gesendet werden sollen. Jede Datenflussdefinition für die Pipelinekonfiguration gibt den DCR und datenstrom innerhalb dieses DCR an, der diese Daten in der Cloud verarbeitet.

Hinweis
Private Link wird von der Azure Monitor-Pipeline für die Verbindung zur Cloud unterstützt.
Die folgenden Komponenten und Konfigurationen sind erforderlich, um die Azure Monitor-Pipeline zu aktivieren. Wenn Sie das Azure-Portal zum Konfigurieren der Pipeline verwenden, wird jede dieser Komponenten für Sie erstellt. Bei anderen Methoden müssen Sie die einzelnen Komponenten konfigurieren.
| Komponente |
BESCHREIBUNG |
| Controllererweiterung für die Edgepipeline |
Erweiterung, die Ihrem Kubernetes-Cluster mit Arc-Unterstützung hinzugefügt wird, um Pipelinefunktionen zu unterstützen: microsoft.monitor.pipelinecontroller. |
| Controllerinstanz für die Edgepipeline |
Eine Instanz der Pipeline, die auf Ihrem Arc-fähigen Kubernetes-Cluster ausgeführt wird. |
| Datenfluss |
Kombination von Empfängern und Exportern, die in der Controllerinstanz der Pipeline ausgeführt werden. Empfänger akzeptieren Daten von Clients, und Exporter übermitteln diese Daten an Azure Monitor. |
| Pipelinekonfiguration |
Konfigurationsdatei, die die Datenflüsse für die Pipelineinstanz definiert. Jeder Datenfluss enthält einen Empfänger und einen Exporter. Der Empfänger lauscht auf eingehende Daten, und der Exporter sendet die Daten an das Ziel. |
| Datensammlungsendpunkt (Data Collection Endpoint, DCE) |
Endpunkt, an den die Daten an Azure Monitor in der Cloud gesendet werden. Die Pipelinekonfiguration enthält eine Eigenschaft für die URL des Datensammlungsendpunkts, damit die Pipelineinstanz weiß, wohin die Daten gesendet werden sollen. |
| Konfiguration |
BESCHREIBUNG |
| Datensammlungsregel (Data Collection Rule, DCR) |
Konfigurationsdatei, die definiert, wie die Daten von Azure Monitor empfangen werden und wo sie gesendet werden. Die DCR kann auch eine Transformation enthalten, um die Daten zu filtern oder zu ändern, bevor sie an das Ziel gesendet werden. |
| Pipelinekonfiguration |
Konfigurationsdatei, die die Datenflüsse für die Pipelineinstanz definiert (einschließlich der Datenflüsse und des Cache). |
Unterstützte Konfigurationen
Unterstützte Distributionen
Die Azure Monitor-Pipeline wird für die folgenden Kubernetes-Verteilungen unterstützt:
- Kanonisch
- Cluster-API-Anbieter für Azure
- K3
- Rancher Kubernetes Engine
- VMware Tanzu Kubernetes Grid
Unterstützte Standorte
Die Azure Monitor-Pipeline wird in den folgenden Azure-Regionen unterstützt:
- Kanada, Mitte
- USA, Osten 2
- Italien Nord
- USA, Westen 2
- Westeuropa
Weitere Informationen finden Sie unter Produktverfügbarkeit nach Region
Voraussetzungen
Arbeitsablauf
Wenn Sie die Azure Monitor-Pipeline über das Azure-Portal konfigurieren, müssen Sie nicht im Detail mit den verschiedenen Schritten vertraut sein, die von der Pipeline ausgeführt werden. Wenn Sie jedoch eine andere Installationsmethode verwenden oder eine komplexere Konfiguration benötigen, bei der die Daten beispielsweise transformiert werden müssen, bevor sie am Ziel gespeichert werden, ist ein detaillierteres Verständnis erforderlich.
In den folgenden Tabellen und Diagrammen werden die detaillierten Schritte und Komponenten im Prozess zum Sammeln von Daten mithilfe der Pipeline beschrieben und an die Cloud für die Speicherung in Azure Monitor übergeben. Außerdem enthalten die Tabellen die jeweils erforderliche Konfiguration für die einzelnen Komponenten.
| Schritt |
Maßnahme |
Unterstützende Konfiguration |
| 1. |
Der Client sendet Daten an den Pipelineempfänger. |
Der Client ist mit der IP-Adresse und dem Port des Empfängers der Edgepipeline konfiguriert und sendet Daten im erwarteten Format für den Empfängertyp. |
| 2. |
Der Empfänger leitet Daten an den Exporter weiter. |
Empfänger und Exporter sind in der gleichen Pipeline konfiguriert. |
| 3. |
Exporter versucht, die Daten an die Cloud zu senden. |
Der Exporter in der Pipelinekonfiguration enthält die URL des DCE, einen eindeutigen Bezeichner für die DCR und den Datenstrom in der DCR, der definiert, wie die Daten verarbeitet werden. |
| 3a. |
Der Exporter speichert Daten im lokalen Cache, wenn keine Verbindung zum DCE hergestellt werden kann. |
Das persistente Volume für den Cache und die Konfiguration des lokalen Cache ist in der Pipelinekonfiguration aktiviert. |

| Schritt |
Maßnahme |
Unterstützende Konfiguration |
| 4. |
Azure Monitor akzeptiert die eingehenden Daten. |
Der DCR enthält eine Schemadefinition für den eingehenden Datenstrom, die mit dem Schema der daten übereinstimmen muss, die aus der Pipeline stammen. |
| 5. |
Azure Monitor wendet eine Transformation auf die Daten an. |
Die DCR enthält eine Transformation, um die Daten zu filtern oder zu ändern, bevor sie an das Ziel gesendet werden. Die Transformation kann Daten filtern, Spalten entfernen oder hinzufügen oder das zugehörige Schema vollständig ändern. Die Ausgabe der Transformation muss dem Schema der Zieltabelle entsprechen. |
| 6. |
Azure Monitor sendet die Daten an das Ziel. |
Die DCR enthält ein Ziel, das den Log Analytics-Arbeitsbereich und die Tabelle für die Speicherung der Daten angibt. |
Segmentiertes Netzwerk
Netzwerksegmentierung ist ein Modell, bei dem softwaredefinierte Perimeter verwendet werden, um einen anderen Sicherheitsstatus für verschiedene Teile Ihres Netzwerks zu erstellen. In diesem Modell gibt es möglicherweise ein Netzwerksegment, das keine Verbindung mit dem Internet oder mit anderen Netzwerksegmenten herstellen kann. Die Azure Monitor-Pipeline kann verwendet werden, um Daten aus diesen Netzwerksegmenten zu sammeln und an die Cloud zu senden.
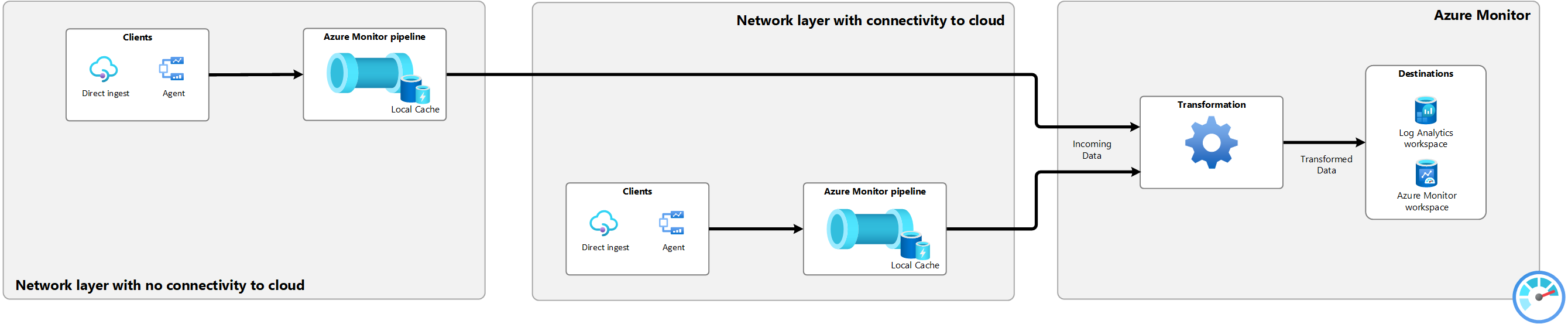
Um die Azure Monitor-Pipeline in einer mehrschichtigen Netzwerkkonfiguration verwenden zu können, müssen Sie der Zulassungsliste für den Arc-aktivierten Kubernetes-Cluster folgende Einträge hinzufügen. Weitere Informationen finden Sie im Artikel „Konfigurieren von Azure IoT Layered Network Management Preview in einem Ebene 4-Cluster“ unter Konfigurieren des Layered Network Management Preview-Diensts
- destinationUrl: "*.ingest.monitor.azure.com"
destinationType: external
- destinationUrl: "login.windows.net"
destinationType: external
Erstellen einer Tabelle im Log Analytics-Arbeitsbereich
Bevor Sie den Datensammlungsprozess für die Pipeline konfigurieren, müssen Sie eine Tabelle im Log Analytics-Arbeitsbereich erstellen, um die Daten zu empfangen. Dies muss eine benutzerdefinierte Tabelle sein, da integrierte Tabellen derzeit nicht unterstützt werden. Das Schema der Tabelle muss mit den empfangenen Daten übereinstimmen. Es gibt jedoch mehrere Schritte im Erfassungsprozess, in denen Sie die eingehenden Daten ändern können. Daher muss das Tabellenschema nicht unbedingt mit den Quelldaten übereinstimmen, die Sie sammeln. Die einzige Anforderung für die Tabelle im Log Analytics-Arbeitsbereich ist, dass sie über eine TimeGenerated-Spalte verfügen muss.
Ausführliche Informationen zu verschiedenen Tabellenerstellungsmethoden finden Sie unter Hinzufügen oder Löschen von Tabellen und Spalten in Azure Monitor-Protokollen. Verwenden Sie z. B. den folgenden CLI-Befehl, um eine Tabelle mit drei Spalten (Body, TimeGenerated und SeverityText) zu erstellen:
az monitor log-analytics workspace table create --workspace-name my-workspace --resource-group my-resource-group --name my-table_CL --columns TimeGenerated=datetime Body=string SeverityText=string
Aktivieren der Zwischenspeicherung
In einigen Umgebungen kann es bei Edgegeräten aufgrund von Faktoren wie Netzwerküberlastung, Signalstörungen, Stromausfall oder Mobilität zu vorübergehenden Verbindungsunterbrechungen kommen. In diesen Umgebungen können Sie die Pipeline so konfigurieren, dass Daten zwischengespeichert werden, indem Sie ein persistentes Volume in Ihrem Cluster erstellen. Der Prozess hierfür variiert je nach Umgebung. Die Konfiguration muss jedoch folgende Anforderungen erfüllen:
- Der Metadatennamespace muss der gleiche sein wie bei der angegebenen Instanz der Azure Monitor-Pipeline.
- Der Zugriffsmodus muss
ReadWriteMany unterstützen.
Nachdem das Volume im entsprechenden Namespace erstellt wurde, muss es mithilfe von Parametern in der unten angegebenen Pipelinekonfigurationsdatei konfiguriert werden.
Vorsicht
Jedes Replikat der Edgepipeline speichert Daten an einem Speicherort im persistenten Volume, das für dieses Replikat spezifisch ist. Wenn Sie die Anzahl der Replikate verringern, während die Verbindung des Clusters zur Cloud unterbrochen ist, verhindert dies, dass die Daten zurückgefüllt werden, sobald die Konnektivität wiederhergestellt wird.
Daten werden nach dem FIFO-Prinzip (First In, First Out) aus dem Cache abgerufen. Alle Daten, die älter als 48 Stunden sind, werden verworfen.
Die aktuellen Optionen für die Aktivierung und Konfiguration werden auf den folgenden Registerkarten erläutert.
Wenn Sie zum Aktivieren und Konfigurieren der Pipeline das Azure-Portal verwenden, werden alle erforderlichen Komponenten basierend auf den von Ihnen ausgewählten Optionen erstellt. Das erspart Ihnen die komplexe Erstellung der einzelnen Komponenten, aber Sie müssen möglicherweise andere Methoden verwenden, um
Führen Sie im Azure-Portal eine der folgenden Aktionen aus, um den Installationsprozess für die Azure Monitor-Pipeline zu starten:
- Klicken Sie im Menü Azure Monitor-Pipelines (Vorschau) auf Erstellen.
- Wählen Sie im Menü für Ihren Kubernetes-Cluster mit Arc-Unterstützung die Option Erweiterungen aus, und fügen Sie dann die Azure Monitor-Pipelineerweiterung (Vorschau) hinzu.
Auf der Registerkarte Allgemein werden Sie zur Angabe der folgenden Informationen aufgefordert, um die Erweiterung und die Pipelineinstanz in Ihrem Cluster bereitzustellen.

Die Einstellungen in diesem Tab werden in der folgenden Tabelle beschrieben.
| Eigentum |
BESCHREIBUNG |
| Instanzname |
Name für die Azure Monitor-Pipelineinstanz. Muss für das Abonnement eindeutig sein. |
| Abonnement |
Azure-Abonnement zur Erstellung der Pipelineinstanz. |
| Ressourcengruppe |
Ressourcengruppe zum Erstellen der Pipelineinstanz. |
| Clustername |
Wählen Sie Ihren Kubernetes-Cluster mit Arc-Unterstützung aus, in dem die Pipeline installiert wird. |
| Benutzerdefinierter Speicherort |
Benutzerdefinierter Speicherort Ihres Kubernetes-Clusters mit Arc-Unterstützung. Hierfür wird automatisch der Name eines benutzerdefinierten Speicherorts angegeben, der für Ihren Cluster erstellt wird. Sie können aber auch einen anderen benutzerdefinierten Speicherort im Cluster auswählen. |
Auf der Registerkarte Dataflow können Sie Dataflows für die Pipelineinstanz erstellen und bearbeiten. Jeder Dataflow enthält folgende Details:
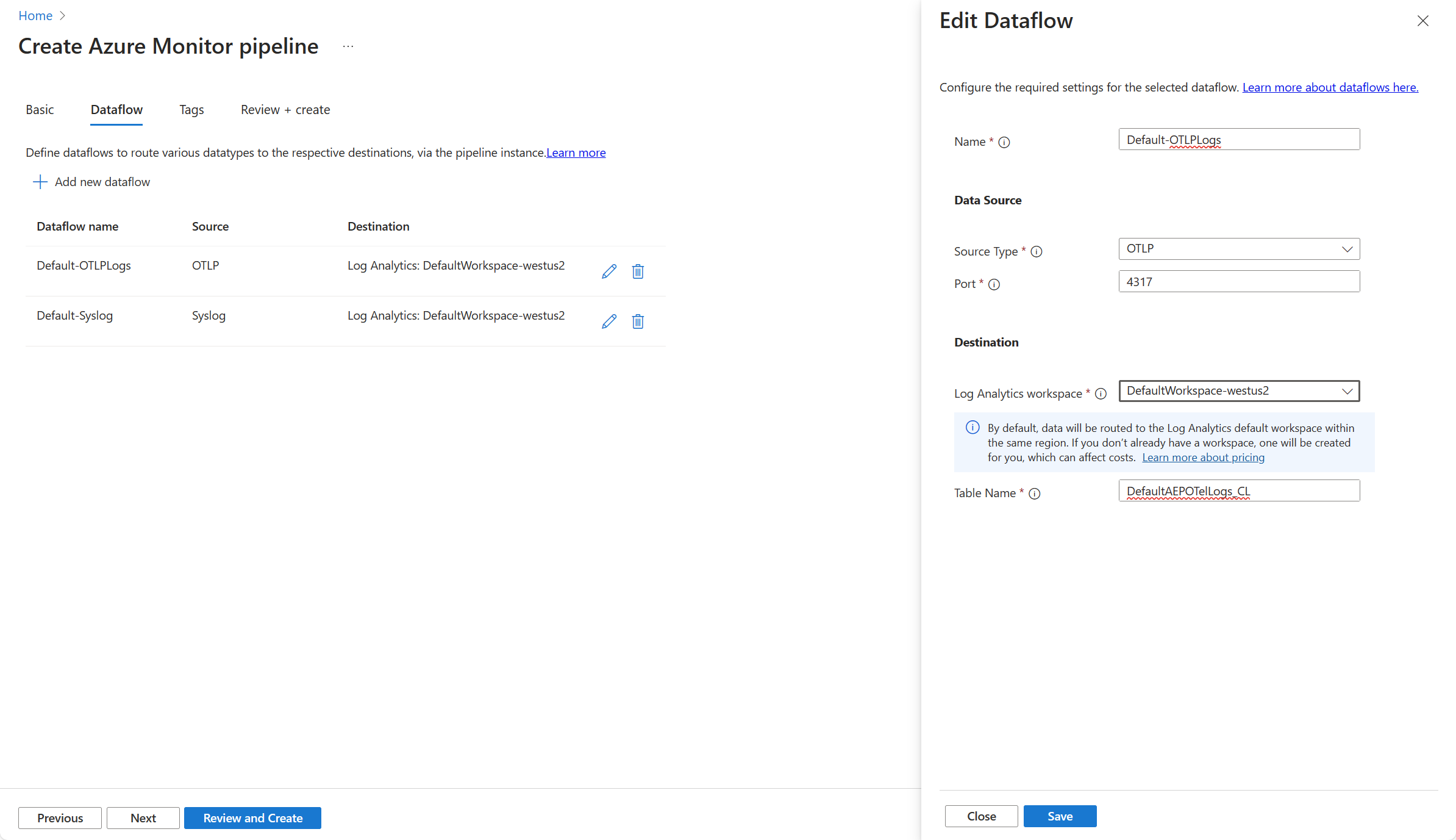
Die Einstellungen in diesem Tab werden in der folgenden Tabelle beschrieben.
| Eigentum |
BESCHREIBUNG |
| Name |
Der Name für den Datenfluss. Muss für diese Pipeline eindeutig sein. |
| Quellentyp |
Die Art der gesammelten Daten. Die folgenden Quellentypen werden derzeit unterstützt:
- Syslog
– OTLP |
| Hafen |
Der Port, an dem die Pipeline auf eingehende Daten lauscht. Wenn zwei Datenflüsse denselben Port verwenden, empfangen und verarbeiten sie die Daten. |
| Log Analytics-Arbeitsbereich |
Der Log Analytics-Arbeitsbereich, an den die Daten gesendet werden. |
| Tabellenname |
Der Name der Tabelle im Log Analytics-Arbeitsbereich, an die die Daten gesendet werden sollen. |
Im Folgenden sind die Schritte zum Erstellen und Konfigurieren der komponenten aufgeführt, die für die Azure Monitor-Pipeline mit Azure CLI erforderlich sind.
Edgepipelineerweiterung
Mit dem folgenden Befehl wird die Edge-Pipeline-Erweiterung zu Ihrem Arc-aktivierten Kubernetes-Cluster hinzugefügt.
az k8s-extension create --name <pipeline-extension-name> --extension-type microsoft.monitor.pipelinecontroller --scope cluster --cluster-name <cluster-name> --resource-group <resource-group> --cluster-type connectedClusters --release-train Preview
## Example
az k8s-extension create --name my-pipe --extension-type microsoft.monitor.pipelinecontroller --scope cluster --cluster-name my-cluster --resource-group my-resource-group --cluster-type connectedClusters --release-train Preview
Benutzerdefinierter Speicherort
Die folgende ARM-Vorlage erstellt den benutzerdefinierten Speicherort für Ihren Kubernetes-Cluster mit Arc-Unterstützung.
az customlocation create --name <custom-___location-name> --resource-group <resource-group-name> --namespace <name of namespace> --host-resource-id <connectedClusterId> --cluster-extension-ids <extensionId>
## Example
az customlocation create --name my-cluster-custom-___location --resource-group my-resource-group --namespace my-cluster-custom-___location --host-resource-id /subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/my-resource-group/providers/Microsoft.Kubernetes/connectedClusters/my-cluster --cluster-extension-ids /subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/my-resource-group/providers/Microsoft.Kubernetes/connectedClusters/my-cluster/providers/Microsoft.KubernetesConfiguration/extensions/my-cluster
DCE
Die folgende ARM-Vorlage erstellt den Datensammlungsendpunkt (DATA Collection Endpoint, DCE), der für die Pipeline erforderlich ist, um eine Verbindung mit der Cloud herzustellen. Sie können eine vorhandene DCE verwenden, wenn Sie in der gleichen Region bereits über eine verfügen. Ersetzen Sie die Eigenschaften in der folgenden Tabelle, bevor Sie die Vorlage bereitstellen:
az monitor data-collection endpoint create -g "myResourceGroup" -l "eastus2euap" --name "myCollectionEndpoint" --public-network-access "Enabled"
## Example
az monitor data-collection endpoint create --name strato-06-dce --resource-group strato --public-network-access "Enabled"
DCR
Der DCR wird in Azure Monitor gespeichert und definiert, wie die Daten verarbeitet werden, wenn sie von der Pipeline empfangen werden. Die Pipelinekonfiguration spezifiziert den immutable ID des DCR und den stream im DCR, der die Daten verarbeitet. Die immutable ID wird beim Erstellen der DCR automatisch generiert.
Ersetzen Sie die Eigenschaften in der folgenden Vorlage, und speichern Sie diese in einer JSON-Datei, bevor Sie den CLI-Befehl ausführen, um die DCR zu erstellen. Ausführliche Informationen zur Struktur einer Datensammlungsregel finden Sie unter Datensammlungsregeln in Azure Monitor.
| Parameter |
BESCHREIBUNG |
name |
Name der DCR. Muss für das Abonnement eindeutig sein. |
___location |
Speicherort der DCR. Muss dem Standort des Datensammlungsendpunkts entsprechen. |
dataCollectionEndpointId |
Ressourcen-ID der DCE. |
streamDeclarations |
Das Schema der empfangenen Daten. Pro Dataflow in der Pipelinekonfiguration wird jeweils ein Datenstrom benötigt. Der Name muss in der DCR eindeutig sein und mit Custom- beginnen. Die Abschnitte vom Typ column in den folgenden Beispielen sollten für die OLTP- und Syslog-Datenflüsse verwendet werden. Wenn das Schema für Ihre Zieltabelle abweicht, können Sie es mithilfe einer im Parameter transformKql definierten Transformation ändern. |
destinations |
Dient zum Hinzufügen eines weiteren Abschnitts, um Daten an mehrere Arbeitsbereiche zu senden. |
- name |
Der Name für das Ziel, auf das im Abschnitt dataFlows verwiesen werden soll. Muss für die DCR eindeutig sein. |
- workspaceResourceId |
Ressourcen-ID des Log Analytics-Arbeitsbereichs. |
- workspaceId |
Die Arbeitsbereichs-ID des Log Analytics-Arbeitsbereichs. |
dataFlows |
Dient zum Abgleichen von Datenströmen und Zielen. Jeweils ein Eintrag pro Kombination aus Datenstrom und Ziel. |
- streams |
Mindestens ein Datenstrom (definiert in streamDeclarations). Sie können mehrere Datenströme einschließen, wenn sie an das gleiche Ziel gesendet werden. |
- destinations |
Mindestens ein Ziel (definiert in destinations). Sie können mehrere Ziele einschließen, wenn sie an das gleiche Ziel gesendet werden. |
- transformKql |
Transformation, die auf die Daten angewendet werden soll, bevor sie an das Ziel gesendet werden. Verwenden Sie source, um die Daten unverändert zu senden. Die Ausgabe der Transformation muss dem Schema der Zieltabelle entsprechen. Weitere Informationen zu Transformationen finden Sie unter Transformationen für die Datensammlung in Azure Monitor. |
- outputStream |
Dient zum Angeben der Zieltabelle im Log Analytics-Arbeitsbereich. Die Tabelle muss bereits im Arbeitsbereich vorhanden sein. Bei benutzerdefinierten Tabellen muss dem Tabellennamen Custom- vorangestellt werden. Integrierte Tabellen werden derzeit nicht mit der Azure Monitor-Pipeline unterstützt. |
{
"properties": {
"dataCollectionEndpointId": "/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/my-resource-group/providers/Microsoft.Insights/dataCollectionEndpoints/my-dce",
"streamDeclarations": {
"Custom-OTLP": {
"columns": [
{
"name": "Body",
"type": "string"
},
{
"name": "TimeGenerated",
"type": "datetime"
},
{
"name": "SeverityText",
"type": "string"
}
]
},
"Custom-Syslog": {
"columns": [
{
"name": "Body",
"type": "string"
},
{
"name": "TimeGenerated",
"type": "datetime"
},
{
"name": "SeverityText",
"type": "string"
}
]
}
},
"dataSources": {},
"destinations": {
"logAnalytics": [
{
"name": "LogAnayticsWorkspace01",
"workspaceResourceId": "/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/my-resource-group/providers/Microsoft.OperationalInsights/workspaces/my-workspace",
}
]
},
"dataFlows": [
{
"streams": [
"Custom-OTLP"
],
"destinations": [
"LogAnayticsWorkspace01"
],
"transformKql": "source",
"outputStream": "Custom-OTelLogs_CL"
},
{
"streams": [
"Custom-Syslog"
],
"destinations": [
"LogAnayticsWorkspace01"
],
"transformKql": "source",
"outputStream": "Custom-Syslog_CL"
}
]
}
}
Verwenden Sie den folgenden Befehl, um das DCR zu installieren:
az monitor data-collection rule create --name 'myDCRName' --___location <___location> --resource-group <resource-group> --rule-file '<dcr-file-path.json>'
## Example
az monitor data-collection rule create --name my-pipeline-dcr --___location westus2 --resource-group 'my-resource-group' --rule-file 'C:\MyDCR.json'
Zugriff auf DCR
Der Arc-fähige Kubernetes-Cluster muss Zugriff auf den DCR haben, um Daten an die Cloud zu senden. Verwenden Sie den folgenden Befehl, um die Objekt-ID der systemseitig zugewiesenen Identität für Ihren Cluster abzurufen:
az k8s-extension show --name <extension-name> --cluster-name <cluster-name> --resource-group <resource-group> --cluster-type connectedClusters --query "identity.principalId" -o tsv
## Example:
az k8s-extension show --name my-pipeline-extension --cluster-name my-cluster --resource-group my-resource-group --cluster-type connectedClusters --query "identity.principalId" -o tsv
Verwenden Sie die Ausgabe dieses Befehls als Eingabe für den folgenden Befehl, um die Azure Monitor-Pipeline zu autorisieren, ihre Telemetriedaten an die DCR zu senden.
az role assignment create --assignee "<extension principal ID>" --role "Monitoring Metrics Publisher" --scope "/subscriptions/<subscription-id>/resourceGroups/<resource-group>/providers/Microsoft.Insights/dataCollectionRules/<dcr-name>"
## Example:
az role assignment create --assignee "00000000-0000-0000-0000-000000000000" --role "Monitoring Metrics Publisher" --scope "/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/my-resource-group/providers/Microsoft.Insights/dataCollectionRules/my-dcr"
Edge-Pipeline-Konfiguration
Die Edgepipelinekonfiguration definiert die Details der Pipelineinstanz und stellt die datenflüsse bereit, die zum Empfangen und Senden von Telemetrie an die Cloud erforderlich sind.
Ersetzen Sie die Eigenschaften in der folgenden Tabelle, bevor Sie die Vorlage bereitstellen:
| Eigentum |
BESCHREIBUNG |
|
Allgemein |
|
name |
Name der Pipelineinstanz. Muss innerhalb des Abonnements eindeutig sein. |
___location |
Speicherort der Pipelineinstanz. |
extendedLocation |
|
|
Empfänger |
Jeweils ein Eintrag pro Empfänger. Jeder Eintrag gibt die Art der empfangenen Daten sowie den Port, an dem gelauscht wird, und einen eindeutigen Namen an, der im Abschnitt pipelines der Konfiguration verwendet wird. |
type |
Die Art der empfangenen Daten. Aktuell verfügbare Optionen sind OTLP und Syslog. |
name |
Der Name für den Empfänger, auf den im Abschnitt service verwiesen wird. Muss für die Pipelineinstanz eindeutig sein. |
endpoint |
Die Adresse und der Port, an denen der Empfänger lauscht. Verwenden Sie 0.0.0.0 für alle Adressen. |
|
Prozessoren |
Reserviert für zukünftige Verwendung. |
|
exporters |
Jeweils ein Eintrag pro Ziel. |
type |
Derzeit wird nur der Typ AzureMonitorWorkspaceLogs unterstützt. |
name |
Muss für die Pipelineinstanz eindeutig sein. Der Name wird im Abschnitt pipelines der Konfiguration verwendet. |
dataCollectionEndpointUrl |
URL des DCE, an die die Pipeline die Daten sendet. Sie können dies im Azure-Portal suchen, in dem Sie zur DCE navigieren und den Wert für Protokollerfassung kopieren. |
dataCollectionRule |
Unveränderliche ID des DCR, die die Datensammlung in der Cloud definiert. Kopieren Sie im Azure-Portal in der JSON-Ansicht Ihrer DCR den Wert der unveränderlichen ID im Abschnitt Allgemein. |
- stream |
Der Name des Datenstroms in Ihrer DCR, der die Daten akzeptiert. |
- maxStorageUsage |
Die Kapazität des Cache. Wenn 80 Prozent dieser Kapazität erreicht sind, werden die ältesten Daten gelöscht, um Platz für weitere Daten freizugeben. |
- retentionPeriod |
Aufbewahrungszeitraum in Minuten. Nach dieser Zeitspanne werden die Daten reduziert. |
- schema |
Schema der Daten, die an die Cloud gesendet werden. Dies muss dem Schema entsprechen, das im Datenstrom in der DCR definiert ist. Das im Beispiel verwendete Schema ist sowohl für Syslog als auch für OTLP gültig. |
|
Dienstleistung |
Jeweils ein Eintrag pro Pipelineinstanz. Es wird nur eine einzelne Instanz pro Pipelineerweiterung empfohlen. |
|
Pipelines |
Jeweils ein Eintrag pro Datenfluss. Jeder Eintrag ordnet ein receiver einem exporter zu. |
name |
Eindeutiger Name der Pipeline. |
receivers |
Mindestens ein Empfänger, der auf zu empfangende Daten lauscht. |
processors |
Reserviert für zukünftige Verwendung. |
exporters |
Mindestens ein Exporteur, der die Daten an die Cloud sendet. |
persistence |
Name des persistenten Volumes für den Cache. Entfernen Sie diesen Parameter, wenn Sie den Cache nicht aktivieren möchten. |
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"metadata": {
"description": "This template deploys an edge pipeline for azure monitor."
},
"resources": [
{
"type": "Microsoft.monitor/pipelineGroups",
"___location": "eastus",
"apiVersion": "2023-10-01-preview",
"name": "my-pipeline-group-name",
"extendedLocation": {
"name": "/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/my-resource-group/providers/Microsoft.ExtendedLocation/customLocations/my-custom-___location",
"type": "CustomLocation"
},
"properties": {
"receivers": [
{
"type": "OTLP",
"name": "receiver-OTLP",
"otlp": {
"endpoint": "0.0.0.0:4317"
}
},
{
"type": "Syslog",
"name": "receiver-Syslog",
"syslog": {
"endpoint": "0.0.0.0:514"
}
}
],
"processors": [],
"exporters": [
{
"type": "AzureMonitorWorkspaceLogs",
"name": "exporter-log-analytics-workspace",
"azureMonitorWorkspaceLogs": {
"api": {
"dataCollectionEndpointUrl": "https://my-dce-4agr.eastus-1.ingest.monitor.azure.com",
"dataCollectionRule": "dcr-00000000000000000000000000000000",
"stream": "Custom-OTLP",
"schema": {
"recordMap": [
{
"from": "body",
"to": "Body"
},
{
"from": "severity_text",
"to": "SeverityText"
},
{
"from": "time_unix_nano",
"to": "TimeGenerated"
}
]
}
},
"cache": {
"maxStorageUsage": 10000,
"retentionPeriod": 60
}
}
}
],
"service": {
"pipelines": [
{
"name": "DefaultOTLPLogs",
"receivers": [
"receiver-OTLP"
],
"processors": [],
"exporters": [
"exporter-log-analytics-workspace"
],
"type": "logs"
},
{
"name": "DefaultSyslogs",
"receivers": [
"receiver-Syslog"
],
"processors": [],
"exporters": [
"exporter-log-analytics-workspace"
],
"type": "logs"
}
],
"persistence": {
"persistentVolumeName": "my-persistent-volume"
}
},
"networkingConfigurations": [
{
"externalNetworkingMode": "LoadBalancerOnly",
"routes": [
{
"receiver": "receiver-OTLP"
},
{
"receiver": "receiver-Syslog"
}
]
}
]
}
}
]
}
Verwenden Sie den folgenden Befehl, um die Vorlage zu installieren:
az deployment group create --resource-group <resource-group-name> --template-file <path-to-template>
## Example
az deployment group create --resource-group my-resource-group --template-file C:\MyPipelineConfig.json
Sie können alle erforderlichen Komponenten für die Azure Monitor-Pipeline mithilfe der unten gezeigten einzelnen ARM-Vorlage bereitstellen. Bearbeiten Sie die Parameterdatei mit spezifischen Werten für Ihre Umgebung. Die einzelnen Abschnitte der Vorlage werden weiter unten beschrieben – einschließlich der Abschnitte, die vor der Verwendung geändert werden müssen.
| Komponente |
Typ |
BESCHREIBUNG |
| Log Analytics-Arbeitsbereich |
Microsoft.OperationalInsights/workspaces |
Entfernen Sie diesen Abschnitt, wenn Sie einen bereits vorhandenen Log Analytics-Arbeitsbereich verwenden. Der einzige erforderliche Parameter ist der Name des Arbeitsbereichs. Die unveränderliche ID für den Arbeitsbereich, die für andere Komponenten erforderlich ist, wird automatisch erstellt. |
| Datensammlungsendpunkt (Data Collection Endpoint, DCE) |
Microsoft.Insights/dataCollectionEndpoints |
Entfernen Sie diesen Abschnitt, wenn Sie ein bestehendes DCE verwenden. Der einzige erforderliche Parameter ist der DCE-Name. Die Protokollerfassungs-URL des DCE, die für andere Komponenten benötigt wird, wird automatisch erstellt. |
| Edgepipelineerweiterung |
Microsoft.KubernetesConfiguration/extensions |
Der einzige erforderliche Parameter ist der Name der Pipelineerweiterung. |
| Benutzerdefinierter Speicherort |
Microsoft.ExtendedLocation/customLocations |
Benutzerdefinierter Speicherort des Kubernetes-Clusters mit Arc-Unterstützung |
| Edge-Pipeline-Instanz |
Microsoft.monitor/pipelineGroups |
Die Edge-Pipeline-Instanz, die die Konfiguration des Listeners, der Exporter und der Datenflüsse enthält. Die Eigenschaften der Pipelineinstanz müssen geändert werden, bevor die Vorlage bereitgestellt wird. |
| Datensammlungsregel (Data Collection Rule, DCR) |
Microsoft.Insights/dataCollectionRules |
Der einzige erforderliche Parameter ist der DCR-Name. Allerdings müssen Sie die Eigenschaften der DCR vor der Bereitstellung der Vorlage ändern. |
Vorlagendatei
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"___location": {
"type": "string"
},
"clusterId": {
"type": "string"
},
"clusterExtensionIds": {
"type": "array"
},
"customLocationName": {
"type": "string"
},
"cachePersistentVolume": {
"type": "string"
},
"cacheMaxStorageUsage": {
"type": "int"
},
"cacheRetentionPeriod": {
"type": "int"
},
"dceName": {
"type": "string"
},
"dcrName": {
"type": "string"
},
"logAnalyticsWorkspaceName": {
"type": "string"
},
"pipelineExtensionName": {
"type": "string"
},
"pipelineGroupName": {
"type": "string"
},
"tagsByResource": {
"type": "object",
"defaultValue": {}
}
},
"resources": [
{
"type": "Microsoft.OperationalInsights/workspaces",
"name": "[parameters('logAnalyticsWorkspaceName')]",
"___location": "[parameters('___location')]",
"apiVersion": "2017-03-15-preview",
"tags": "[ if(contains(parameters('tagsByResource'), 'Microsoft.OperationalInsights/workspaces'), parameters('tagsByResource')['Microsoft.OperationalInsights/workspaces'], json('{}')) ]",
"properties": {
"sku": {
"name": "pergb2018"
}
}
},
{
"type": "Microsoft.Insights/dataCollectionEndpoints",
"name": "[parameters('dceName')]",
"___location": "[parameters('___location')]",
"apiVersion": "2021-04-01",
"tags": "[ if(contains(parameters('tagsByResource'), 'Microsoft.Insights/dataCollectionEndpoints'), parameters('tagsByResource')['Microsoft.Insights/dataCollectionEndpoints'], json('{}')) ]",
"properties": {
"configurationAccess": {},
"logsIngestion": {},
"networkAcls": {
"publicNetworkAccess": "Enabled"
}
}
},
{
"type": "Microsoft.Insights/dataCollectionRules",
"name": "[parameters('dcrName')]",
"___location": "[parameters('___location')]",
"apiVersion": "2021-09-01-preview",
"dependsOn": [
"[resourceId('Microsoft.OperationalInsights/workspaces', 'DefaultWorkspace-westus2')]",
"[resourceId('Microsoft.Insights/dataCollectionEndpoints', 'Aep-mytestpl-ZZPXiU05tJ')]"
],
"tags": "[ if(contains(parameters('tagsByResource'), 'Microsoft.Insights/dataCollectionRules'), parameters('tagsByResource')['Microsoft.Insights/dataCollectionRules'], json('{}')) ]",
"properties": {
"dataCollectionEndpointId": "[resourceId('Microsoft.Insights/dataCollectionEndpoints', 'Aep-mytestpl-ZZPXiU05tJ')]",
"streamDeclarations": {
"Custom-OTLP": {
"columns": [
{
"name": "Body",
"type": "string"
},
{
"name": "TimeGenerated",
"type": "datetime"
},
{
"name": "SeverityText",
"type": "string"
}
]
},
"Custom-Syslog": {
"columns": [
{
"name": "Body",
"type": "string"
},
{
"name": "TimeGenerated",
"type": "datetime"
},
{
"name": "SeverityText",
"type": "string"
}
]
}
},
"dataSources": {},
"destinations": {
"logAnalytics": [
{
"name": "DefaultWorkspace-westus2",
"workspaceResourceId": "[resourceId('Microsoft.OperationalInsights/workspaces', 'DefaultWorkspace-westus2')]",
"workspaceId": "[reference(resourceId('Microsoft.OperationalInsights/workspaces', 'DefaultWorkspace-westus2'))].customerId"
}
]
},
"dataFlows": [
{
"streams": [
"Custom-OTLP"
],
"destinations": [
"localDest-DefaultWorkspace-westus2"
],
"transformKql": "source",
"outputStream": "Custom-OTelLogs_CL"
},
{
"streams": [
"Custom-Syslog"
],
"destinations": [
"DefaultWorkspace-westus2"
],
"transformKql": "source",
"outputStream": "Custom-Syslog_CL"
}
]
}
},
{
"type": "Microsoft.KubernetesConfiguration/extensions",
"apiVersion": "2022-11-01",
"name": "[parameters('pipelineExtensionName')]",
"scope": "[parameters('clusterId')]",
"tags": "[ if(contains(parameters('tagsByResource'), 'Microsoft.KubernetesConfiguration/extensions'), parameters('tagsByResource')['Microsoft.KubernetesConfiguration/extensions'], json('{}')) ]",
"identity": {
"type": "SystemAssigned"
},
"properties": {
"aksAssignedIdentity": {
"type": "SystemAssigned"
},
"autoUpgradeMinorVersion": false,
"extensionType": "microsoft.monitor.pipelinecontroller",
"releaseTrain": "preview",
"scope": {
"cluster": {
"releaseNamespace": "my-strato-ns"
}
},
"version": "0.37.3-privatepreview"
}
},
{
"type": "Microsoft.ExtendedLocation/customLocations",
"apiVersion": "2021-08-15",
"name": "[parameters('customLocationName')]",
"___location": "[parameters('___location')]",
"tags": "[ if(contains(parameters('tagsByResource'), 'Microsoft.ExtendedLocation/customLocations'), parameters('tagsByResource')['Microsoft.ExtendedLocation/customLocations'], json('{}')) ]",
"dependsOn": [
"[parameters('pipelineExtensionName')]"
],
"properties": {
"hostResourceId": "[parameters('clusterId')]",
"namespace": "[toLower(parameters('customLocationName'))]",
"clusterExtensionIds": "[parameters('clusterExtensionIds')]",
"hostType": "Kubernetes"
}
},
{
"type": "Microsoft.monitor/pipelineGroups",
"___location": "[parameters('___location')]",
"apiVersion": "2023-10-01-preview",
"name": "[parameters('pipelineGroupName')]",
"tags": "[ if(contains(parameters('tagsByResource'), 'Microsoft.monitor/pipelineGroups'), parameters('tagsByResource')['Microsoft.monitor/pipelineGroups'], json('{}')) ]",
"dependsOn": [
"[parameters('customLocationName')]",
"[resourceId('Microsoft.Insights/dataCollectionRules','Aep-mytestpl-ZZPXiU05tJ')]"
],
"extendedLocation": {
"name": "[resourceId('Microsoft.ExtendedLocation/customLocations', parameters('customLocationName'))]",
"type": "CustomLocation"
},
"properties": {
"receivers": [
{
"type": "OTLP",
"name": "receiver-OTLP-4317",
"otlp": {
"endpoint": "0.0.0.0:4317"
}
},
{
"type": "Syslog",
"name": "receiver-Syslog-514",
"syslog": {
"endpoint": "0.0.0.0:514"
}
}
],
"processors": [],
"exporters": [
{
"type": "AzureMonitorWorkspaceLogs",
"name": "exporter-lu7mbr90",
"azureMonitorWorkspaceLogs": {
"api": {
"dataCollectionEndpointUrl": "[reference(resourceId('Microsoft.Insights/dataCollectionEndpoints','Aep-mytestpl-ZZPXiU05tJ')).logsIngestion.endpoint]",
"stream": "Custom-DefaultAEPOTelLogs_CL-FqXSu6GfRF",
"dataCollectionRule": "[reference(resourceId('Microsoft.Insights/dataCollectionRules', 'Aep-mytestpl-ZZPXiU05tJ')).immutableId]",
"cache": {
"maxStorageUsage": "[parameters('cacheMaxStorageUsage')]",
"retentionPeriod": "[parameters('cacheRetentionPeriod')]"
},
"schema": {
"recordMap": [
{
"from": "body",
"to": "Body"
},
{
"from": "severity_text",
"to": "SeverityText"
},
{
"from": "time_unix_nano",
"to": "TimeGenerated"
}
]
}
}
}
}
],
"service": {
"pipelines": [
{
"name": "DefaultOTLPLogs",
"receivers": [
"receiver-OTLP"
],
"processors": [],
"exporters": [
"exporter-lu7mbr90"
]
}
],
"persistence": {
"persistentVolume": "[parameters('cachePersistentVolume')]"
}
}
}
}
],
"outputs": {}
}
Beispiel für Parameterdatei
{
"$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentParameters.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"___location": {
"value": "eastus"
},
"clusterId": {
"value": "/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/my-resource-group/providers/Microsoft.Kubernetes/connectedClusters/my-arc-cluster"
},
"clusterExtensionIds": {
"value": ["/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/my-resource-group/providers/Microsoft.KubernetesConfiguration/extensions/my-pipeline-extension"]
},
"customLocationName": {
"value": "my-custom-___location"
},
"dceName": {
"value": "my-dce"
},
"dcrName": {
"value": "my-dcr"
},
"logAnalyticsWorkspaceName": {
"value": "my-workspace"
},
"pipelineExtensionName": {
"value": "my-pipeline-extension"
},
"pipelineGroupName": {
"value": "my-pipeline-group"
},
"tagsByResource": {
"value": {}
}
}
}
Überprüfen der Konfiguration
Überprüfen Sie die im Cluster laufenden Pipelinekomponenten
Navigieren Sie im Azure-Portal zum Menü Kubernetes Service-Instanzen, und wählen Sie Ihren Kubernetes-Cluster mit Arc-Unterstützung aus. Wählen Sie Dienste und eingehende Elemente aus, und vergewissern Sie sich, dass die folgenden Dienste angezeigt werden:
-
<Pipelinename>-external-service
-
<Pipelinename>-service
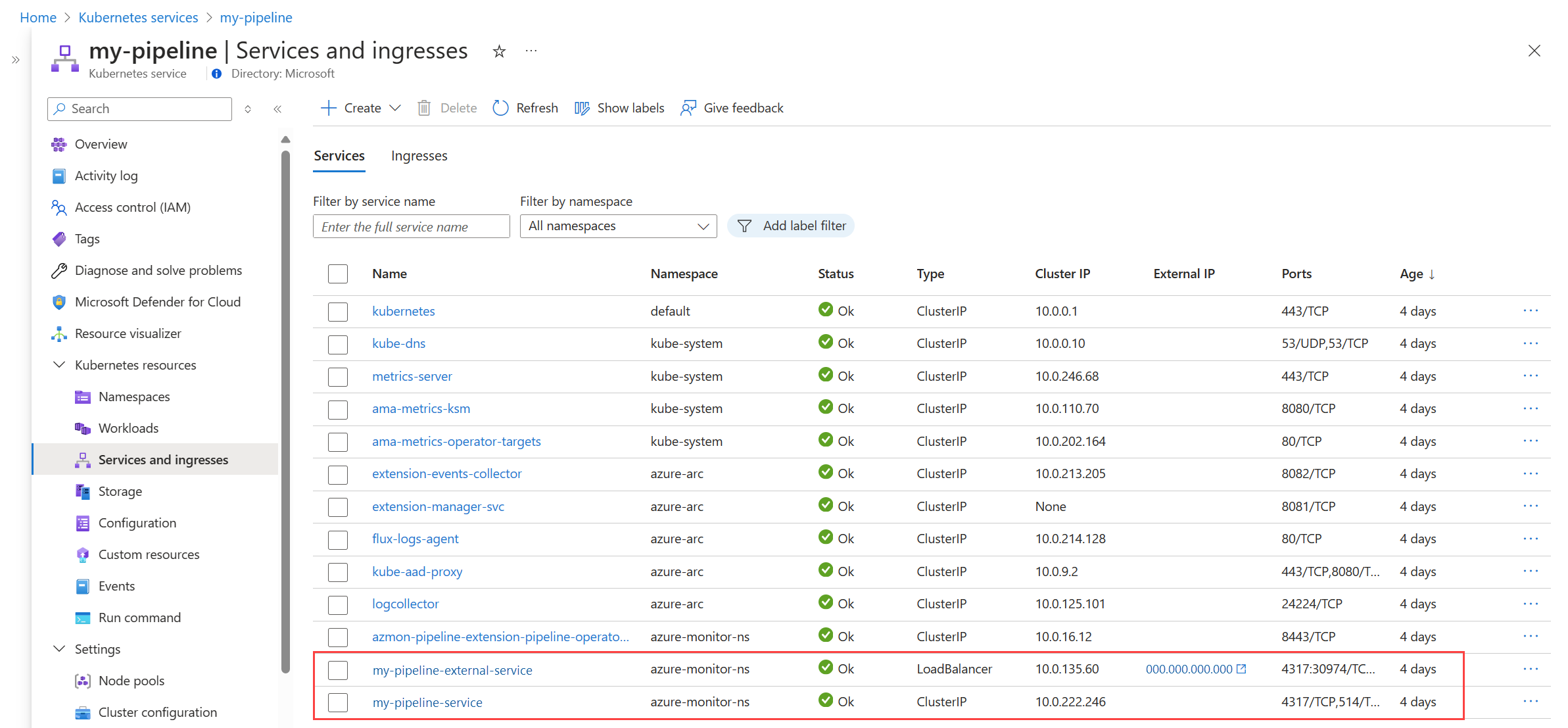
Klicken Sie auf den Eintrag für <Pipelinename>-external-service, und notieren Sie sich die IP-Adresse und den Port aus der Spalte Endpunkte. Hierbei handelt es sich um die externe IP-Adresse und um den Port, an die bzw. an den Ihre Clients Daten senden. Informationen zum Abrufen dieser Adresse vom Client finden Sie unter Abrufen des Eingangsendpunkts.
Herzschlag überprüfen
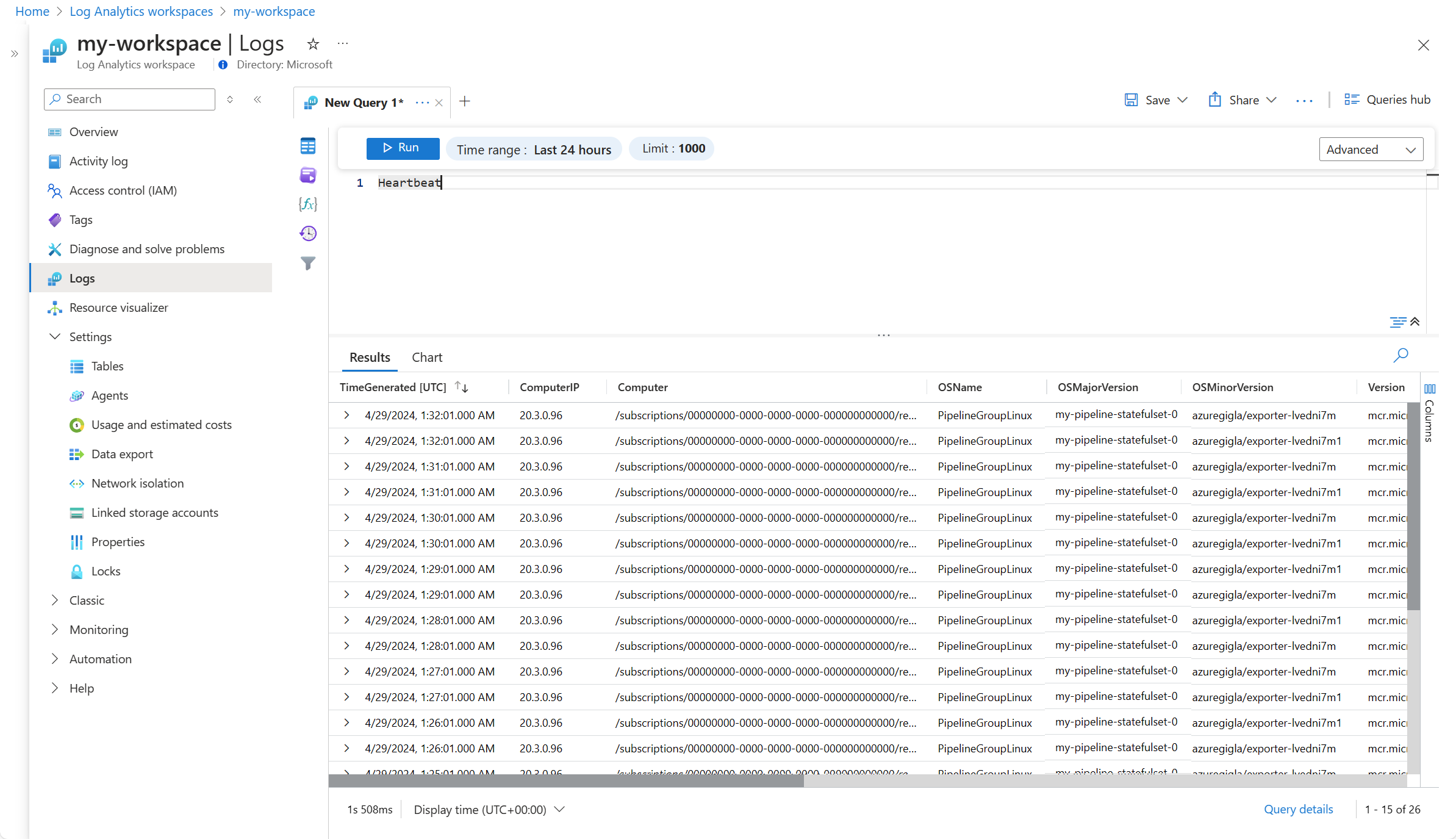
Jede in Ihrer Pipelineinstanz konfigurierte Pipeline sendet jede Minute einen Heartbeat-Datensatz an die Tabelle Heartbeat in Ihrem Log Analytics-Arbeitsbereich. Der Inhalt der OSMajorVersion-Spalte muss dem Namen Ihrer Pipelineinstanz entsprechen. Enthält die Pipelineinstanz mehrere Arbeitsbereiche, wird der erste konfigurierte Arbeitsbereich verwendet.
Rufen Sie den Heartbeat-Datensatz mithilfe einer Protokollabfrage ab, wie im folgenden Beispiel gezeigt:
Clientkonfiguration
Nach der Installation Ihrer Edgepipelineerweiterung und der entsprechenden Instanz müssen Sie Ihre Clients so konfigurieren, dass sie Daten an die Pipeline sendet.
Eingangsendpunkt abrufen
Jeder Client benötigt die externe IP-Adresse des Azure Monitor-Pipelinedienstes. Verwenden Sie den folgenden Befehl, um diese Adresse abzurufen:
kubectl get services -n <namespace where azure monitor pipeline was installed>
- Wenn sich die Anwendung, die Protokolle erzeugt, außerhalb des Clusters befindet, kopieren Sie den Wert external-ip des Dienstes <pipeline name>-service oder <pipeline name>-external-service mit dem Lastenausgleichstyp.
- Wenn sich die Anwendung in einem Pod innerhalb des Clusters befindet, kopieren Sie den Wert von cluster-ip.
Hinweis
Wenn das Externe-IP-Feld auf "Ausstehend" festgelegt ist, müssen Sie eine externe IP für diesen Eingangs manuell gemäß Ihrer Clusterkonfiguration konfigurieren.
| Kunde |
BESCHREIBUNG |
| Syslog |
Aktualisieren Sie Syslog-Clients, sodass sie Daten an den Pipelineendpunkt und den Port Ihres Syslog-Dataflows senden. |
| OTLP |
Die Azure Monitor-Edgepipeline macht einen gRPC-basierten OTLP-Endpunkt am Port 4317 verfügbar. Die Konfiguration Ihrer Instrumentierung zum Senden von Daten an diesen OTLP-Endpunkt hängt von der Instrumentierungsbibliothek selbst ab. Informationen zum OTLP-Endpunkt oder -Collector finden Sie in der OpenTelemetry-Dokumentation. Die Methode mit Umgebungsvariablen ist in der OTLP Exporter-Konfiguration dokumentiert. |
Überprüfen der Daten
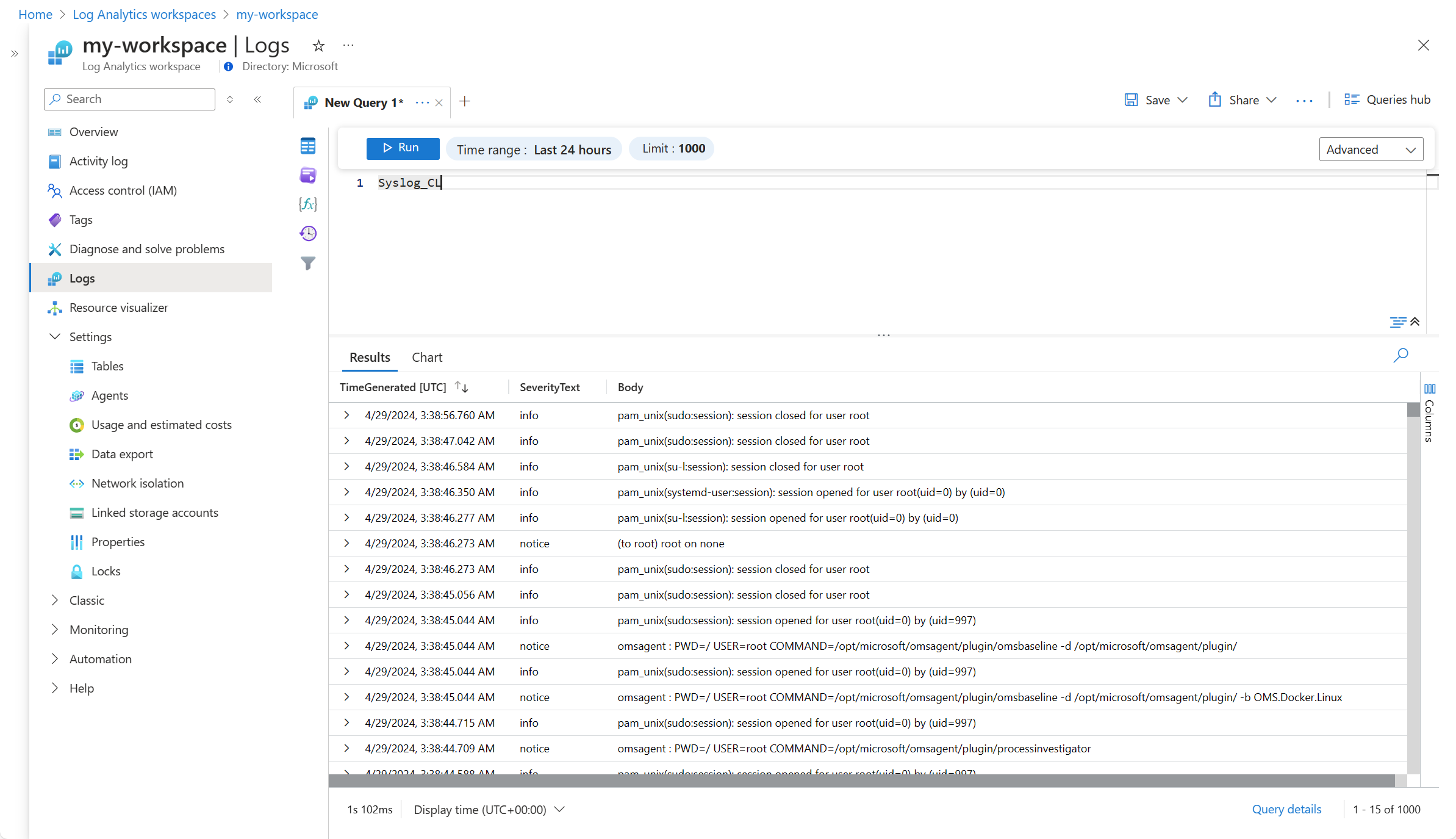
Der letzte Schritt besteht darin, zu überprüfen, ob die Daten im Log Analytics-Arbeitsbereich empfangen werden. Für diese Überprüfung können Sie im Log Analytics-Arbeitsbereich eine Abfrage ausführen, um Daten aus der Tabelle abzurufen.
Nächste Schritte








