Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für:![]() Azure SQL-Datenbank
Azure SQL-Datenbank![]() SQL-Datenbank in Fabric
SQL-Datenbank in Fabric
In diesem Artikel wird die Architektur der Azure SQL-Datenbank und der SQL-Datenbank in Fabric beschrieben, die Verfügbarkeit durch lokale Redundanz und hohe Verfügbarkeit durch Zonenredundanz erreicht.
Overview
Azure SQL-Datenbank und SQL-Datenbank in Fabric werden in der neuesten stabilen Version der SQL Server-Datenbank-Engine unter dem Windows-Betriebssystem mit allen einschlägigen Patches ausgeführt. SQL-Datenbank verarbeitet automatisch wichtige Wartungsaufgaben, z. B. Patches, Sicherungen, Windows- und SQL-Engine-Upgrades, aber auch ungeplante Ereignisse wie Ausfälle der zugrunde liegenden Hardware oder Software oder Netzwerkfehler. Wenn eine Datenbank oder ein Pool für elastische Datenbanken in SQL-Datenbank gepatcht oder ein Failover ausgeführt wird, hat die Downtime keine Auswirkungen, wenn Sie in Ihrer App Wiederholungslogik einsetzen. SQL-Datenbank kann auch unter den kritischsten Umständen schnell wiederhergestellt werden. So wird sichergestellt, dass Ihre Daten immer verfügbar sind. Die meisten Benutzer*innen bemerken nicht, dass kontinuierlich Upgrades durchgeführt werden.
Standardmäßig erzielt die Azure SQL-Datenbank Verfügbarkeit durch lokale Redundanz, um sicherzustellen, dass Ihre Datenbank mit Unterbrechungen umgehen kann, darunter:
- Durch Kunden initiierte Verwaltungsvorgänge, die zu einer kurzen Ausfallzeit führen
- Service-Wartungsvorgänge
- Probleme mit den:
- Rack, in dem die Maschinen, die Ihren Dienst betreiben, ausgeführt werden
- physischer Computer, auf dem das SQL-Datenbankmodul gehostet wird
- Andere Probleme mit dem SQL-Datenbank-Engine
- Andere potenzielle ungeplante lokale Ausfälle
Die Standardverfügbarkeitslösung wurde entwickelt, um sicherzustellen, dass zugesicherte Daten aufgrund von Fehlern nie verloren gehen, dass Wartungsvorgänge minimale Auswirkungen auf Ihre Arbeitsauslastung haben und dass die Datenbank kein einzelner Fehlerpunkt in Ihrer Softwarearchitektur ist.
Um jedoch die Auswirkungen auf Ihre Daten im Falle eines Ausfalls auf eine gesamte Zone zu minimieren, können Sie eine hohe Verfügbarkeit erzielen, indem Sie Zonenredundanz aktivieren. Ohne Zonenredundanz erfolgen Failover lokal innerhalb desselben Rechenzentrums, was dazu führen kann, dass Ihre Datenbank nicht verfügbar ist, bis der Ausfall behoben wird. Die einzige Möglichkeit zum Wiederherstellen ist eine Notfallwiederherstellungslösung, z. B. Geofailover über aktive Georeplikation, Failovergruppen oder eine Geowiederherstellung einer georedundanten Sicherung. Weitere Informationen finden Sie unter Übersicht der Geschäftskontinuität.
Es gibt drei Architekturmodelle für Verfügbarkeit:
- Remotespeichermodell, das auf der Trennung der Compute- und Speicherebene basiert. Das Remotespeichermodell basiert auf der Verfügbarkeit und Zuverlässigkeit der Remotespeicherebene. Diese Architektur ist auf budgetgebundene Geschäftsanwendungen ausgelegt, die bei Wartungsarbeiten gewisse Leistungseinbußen tolerieren können.
- Lokales Speichermodell, das auf einem Cluster von Datenbank-Engine-Prozessen basiert. Das lokale Speichermodell basiert darauf, dass immer ein Quorum der verfügbaren Datenbankmodulknoten vorhanden ist. Diese Architektur ist auf unternehmenskritische Anwendungen mit hoher E/A-Leistung und einer hohen Transaktionsrate ausgelegt und garantiert bei Wartungsaktivitäten minimale Leistungseinbußen für Ihre Workload.
- Hyperscale-Modell, das ein verteiltes System mit hochverfügbaren Komponenten wie Serverknoten, Seitenservern, Protokolldienst und persistentem Speicher verwendet. Jede Komponente, die eine Hyperscale-Datenbank unterstützt, bietet ihre eigene Redundanz und Resilienz gegenüber Ausfällen. Serverknoten, Seitenserver und der Protokolldienst werden in Azure Service Fabric ausgeführt. Dieser Dienst kontrolliert die Integrität der einzelnen Komponenten und führt bei Bedarf ein Failover auf verfügbare fehlerfreie Knoten durch. Persistenter Speicher verwendet Azure Storage mit nativen Hochverfügbarkeits- und Redundanzfunktionen. Weitere Informationen finden Sie unter Hyperscale-Architektur mit verteilten Funktionen.
In jedem der drei Verfügbarkeitsmodelle unterstützt SQL-Datenbank Optionen für lokale Redundanz und Zonenredundanz. Lokale Redundanz bietet Resilienz in einem Rechenzentrum, während Zonenredundanz die Resilienz weiter erhöht, indem sie vor Ausfällen einer Verfügbarkeitszone innerhalb einer Region schützt.
In der folgenden Tabelle sind die Verfügbarkeitsoptionen basierend auf Dienstebenen aufgeführt:
| Dienstebene | Hochverfügbarkeitsmodell | Lokal redundante Verfügbarkeit | Zonenredundante Verfügbarkeit |
|---|---|---|---|
| Universell (virtueller Kern) | Remotespeicher | Yes | Yes |
| Unternehmenskritisch (virtueller Kern) | Lokaler Speicher | Yes | Yes |
| Hyperscale (vCore) | Hyperscale | Yes | Yes |
| Grundlegend (DTU) | Remotespeicher | Yes | No |
| Standard (DTU) | Remotespeicher | Yes | No |
| Premium (DTU) | Lokaler Speicher | Yes | Yes |
Weitere Informationen zu bestimmten SLAs für verschiedene Dienstebenen finden Sie in der Vereinbarung zum Servicelevel für Azure SQL-Datenbank.
Verfügbarkeit durch lokale Redundanz
Lokal redundante Verfügbarkeit basiert auf der Speicherung Ihrer Datenbank in lokal redundantem Speicher (LRS), der Ihre Daten dreimal innerhalb eines einzelnen Rechenzentrums in der primären Region kopiert und Ihre Daten bei lokalen Ausfällen schützt, z. B. bei einem kleinen Netzwerk oder einem Stromausfall. LRS ist die kostengünstigste Redundanzoption und bietet im Vergleich zu anderen Optionen die geringste Dauerhaftigkeit. Bei einem Notfall von großem Ausmaß in einer Region (Feuer, Überschwemmung usw.) gehen jedoch eventuell alle Replikate in einem Speicherkonto, das LRS verwendet, verloren oder könnten nicht mehr wiederhergestellt werden. Um Ihre Daten bei Verwendung der Option für lokal redundante Verfügbarkeit zusätzlich zu schützen, sollten Sie daher eine resilientere Speicheroption für Ihre Datenbanksicherungen verwenden. Dies gilt nicht für Hyperscale-Datenbanken, bei denen derselbe Speicher sowohl für Datendateien als auch für Sicherungen verwendet wird.
Lokal redundante Verfügbarkeit ist für alle Datenbanken in allen Dienstebenen und mit einem Recovery Point Objective (RPO) verfügbar, das angibt, dass die Menge des Datenverlusts null ist.
Dienstebenen „Basic“, „Standard“ und „Universell“
Die Dienstebenen "Basic" und "Standard" der Übersicht des DTU-basierten Einkaufsmodells und die Dienstebene "General Purpose" des vCore-basierten Einkaufsmodells verwenden das Remotespeicherverfügbarkeitsmodell sowohl für serverfreie als auch für die bereitgestellte Computing. Das folgende Diagramm zeigt Knoten mit den getrennten Compute- und Speicherebenen.
Das Modell für Remotespeicherverfügbarkeit umfasst zwei Ebenen:
Eine zustandslose Computeebene, auf der der Datenbank-Engine-Prozess ausgeführt wird und die nur vorübergehende und zwischengespeicherte Daten enthält, z. B. die Datenbanken
tempdbundmodelauf der angefügten SSD, Plancache, Puffer- und Columnstore-Pool im Arbeitsspeicher. Dieser zustandslose Knoten wird vom Azure Service Fabric-Dienst gesteuert, der die Datenbank-Engine initialisiert, die Integrität des Knotens steuert und bei Bedarf ein Failover auf einen anderen Knoten durchführt.Eine zustandsbehaftete Datenebene mit den Datenbankdateien (
.mdfand.ldf), die in Azure Blob Storage gespeichert sind. Azure Blob Storage verfügt über integrierte Datenverfügbarkeits- und Redundanzfunktionen. Dadurch wird sichergestellt, dass jeder Datensatz in der Protokolldatei bzw. jede Seite in der Datendatei erhalten bleibt, auch wenn der Datenbank-Engine-Prozess abstürzt.
Wenn das Datenbankmodul oder das Betriebssystem aktualisiert oder ein Fehler erkannt wird, verschiebt Azure Service Fabric den Zustandslosen Datenbankmodulprozess auf einen anderen zustandslosen Computeknoten mit ausreichend freier Kapazität. Daten in Azure Blob Storage sind vom Verschiebevorgang nicht betroffen, und die Daten- und Protokolldateien werden an den neu initialisierten Datenbank-Engine-Prozess angefügt. Dieser Prozess garantiert Hochverfügbarkeit, bei umfangreichen Workloads ist jedoch möglicherweise eine gewisse Leistungsbeeinträchtigung während des Übergangs festzustellen, da der neue Datenbank-Engine-Prozess mit einem kalten Cache gestartet wird.
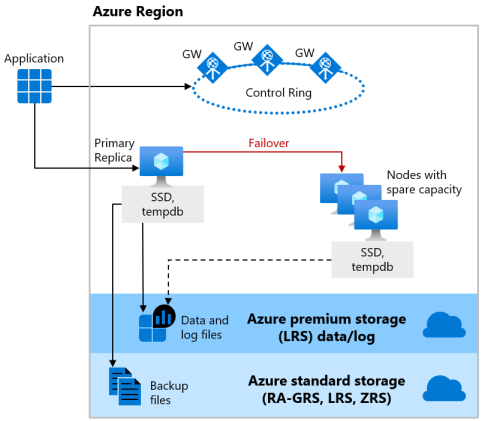
Dienstebenen „Premium“ und „Unternehmenskritisch“
Die Dienstebenen „Premium“ des DTU-basierten Kaufmodells und die Dienstebene „Unternehmenskritisch“ des vCore-basierten Kaufmodells nutzen das Modell für die Verfügbarkeit von lokalem Speicher, das eine Integration von Computeressourcen (Datenbank-Engine-Prozess) und Speicher (lokal angefügte SSD) auf einem einzigen Knoten bietet. Hochverfügbarkeit wird durch Replizieren von Compute- und Speicherressourcen auf weiteren Knoten erreicht.
Die zugrunde liegenden Datenbankdateien (MDF- und LDF-Dateien) werden auf dem angefügten SSD-Speicher platziert, um eine E/A mit äußerst niedriger Latenz für Ihre Workload zu erzielen. Hochverfügbarkeit wird anhand einer ähnlichen Technologie wie AlwaysOn-Verfügbarkeitsgruppen in SQL Server implementiert. Der Cluster umfasst ein einzelnes primäres Replikat, der für Lese-/Schreib-Workloads der Kunden zugänglich ist, sowie bis zu drei sekundäre Replikate (Compute und Speicher) mit Kopien der Daten. Das primäre Replikat pusht ständig Änderungen der Reihe nach an die sekundären Replikate und stellt sicher, dass die Daten vor dem Ausführen eines Commits für jede Transaktion auf einer ausreichenden Anzahl von sekundären Replikaten gespeichert werden. Durch diesen Prozess wird sichergestellt, dass bei einem Ausfall des primären Replikats oder eines lesbaren sekundären Replikats stets ein vollständig synchronisiertes Replikat vorhanden ist, auf das ein Failover ausgeführt werden kann. Das Failover wird von der Azure Service Fabric initiiert. Sobald ein sekundäres Replikat zum neuen primären Replikat wird, wird ein weiteres sekundäres Replikat erstellt, um sicherzustellen, dass der Cluster über eine ausreichende Anzahl von Replikaten verfügt, um ein Quorum beizubehalten. Nach Abschluss eines Failovers werden Azure SQL-Verbindungen automatisch an das neue primäre Replikat oder das lesbare sekundäre Replikat umgeleitet.
Als weiteren Vorteil bietet das Modell für die Verfügbarkeit von lokalem Speicher die Möglichkeit, Azure SQL-Verbindungen mit Schreibschutz auf eines der sekundären Replikate umzuleiten. Dieses Feature wird als horizontale Leseskalierung bezeichnet. Es bietet 100 % zusätzliche Computekapazität ohne zusätzliche Kosten, um reine Lesevorgänge, wie z. B. analytische Workloads, vom primären Replikat auszulagern.
Hyperscale-Dienstebene
Die Architektur der Hyperscale-Dienstebene wird in der Architektur der verteilten Funktionen beschrieben, die ein detailliertes Diagramm enthält.
Das Verfügbarkeitsmodell in Hyperscale umfasst vier Ebenen:
Eine zustandslose Computeebene, auf der die Prozesse der Datenbank-Engine ausgeführt werden und die nur vorübergehende und zwischengespeicherte Daten enthält, z. B. nicht abdeckenden RBPEX-Cache, die Datenbanken
tempdbundmodelusw. auf der angefügten SSD, und Plancache, Pufferpool und Columnstore-Pool im Arbeitsspeicher. Diese zustandslose Ebene enthält das primäre Computereplikat und optional eine Reihe sekundärer Computereplikate, die als Failoverziele dienen können.Eine durch Seitenserver gebildete zustandslose Speicherebene. Diese Ebene ist die verteilte Speicher-Engine für die Datenbank-Engine-Prozesse, die auf den Computereplikaten ausgeführt werden. Jeder Seitenserver enthält nur vorübergehende und zwischengespeicherte Daten, wie z.B. abdeckenden RBPEX-Cache auf der angefügten SSD und im Arbeitsspeicher zwischengespeicherte Datenseiten. Jeder Seitenserver verfügt über einen gekoppelten Seitenserver in einer Aktiv-Aktiv-Konfiguration, um Lastenausgleich, Redundanz und Hochverfügbarkeit zu gewährleisten.
Eine zustandsbehaftete Speicherschicht für Transaktionsprotokolle, die vom Computeknoten gebildet wird, auf dem der Protokolldienstprozess, die Zielzone für Transaktionsprotokolle und der langfristige Speicher für Transaktionsprotokolle ausgeführt werden. Für die Zielzone und den langfristigen Speicher wird Azure Storage eingesetzt. Dieser Dienst bietet Verfügbarkeit und Redundanz für das Transaktionsprotokoll und gewährleistet Datenbeständigkeit für durchgeführte Transaktionen.
Eine zustandsbehaftete Datenspeicherebene mit den Datenbankdateien (MDF- und NDF-Dateien), die in Azure Storage gespeichert und von Seitenservern aktualisiert werden. Diese Ebene nutzt die Features von Azure Storage für Datenverfügbarkeit und Redundanz. Sie garantiert, dass jede Seite in einer Datendatei erhalten bleibt, auch wenn Prozesse auf anderen Ebenen der Hyperscale-Architektur abstürzen oder Computeknoten ausfallen.
Computeknoten auf allen Hyperscale-Ebenen werden in Azure Service Fabric ausgeführt. Dieser Dienst kontrolliert die Integrität jedes Knotens und führt bei Bedarf ein Failover auf verfügbare fehlerfreie Knoten durch.
Weitere Informationen zur Hochverfügbarkeit in Hyperscale finden Sie unter Hochverfügbarkeit der Datenbank in Hyperscale.
Hohe Verfügbarkeit durch Zonenredundanz
Bei zonenredundanten Bereitstellungen verwendet Azure SQL-Datenbank die Anzahl der Azure-Verfügbarkeitszonen in einer bestimmten Region, zwei oder mehr häufig drei. Compute- und Speicherkomponenten erstrecken sich über zwei oder drei Zonen, wie von Azure SQL zur optimalen Resilienz ausgewählt, an separaten physischen Standorten mit unabhängiger Stromversorgung, Kühlung und Netzwerken. Azure SQL wählt automatisch die Anzahl der Zonen basierend auf regionaler Verfügbarkeit und Dienstoptimierung aus. Ihre Bereitstellung verwendet nicht weniger Zonen als für die Resilienz erforderlich.
Zonenredundante Verfügbarkeit ist für Datenbanken in den Dienstebenen „Unternehmenskritisch“, „Universell“ und „Hyperscale“ des vCore-basierten Kaufmodells, und nur die Dienstebene „Premium“ des DTU-basierten Kaufmodells verfügbar - die Dienstebenen „Basic“ und „Standard“ unterstützen nicht die Zonenredundanz.
Während jede Dienstebene Zonenredundanz anders implementiert, stellen alle Implementierungen ein RPO (Recovery Point Objective) mit null Verlust von zugesicherten Daten beim Failover sicher, wenn eine einzelne Verfügbarkeitszone innerhalb einer Azure-Region nicht verfügbar ist.
Azure SQL optimiert die Zonenplatzierung für Ihre Bereitstellung automatisch. Alle Verfügbarkeitszonenkonfigurationen mit zwei oder drei Zonen bieten die gleichen SLA- und Resilienzgarantien für hohe Verfügbarkeit.
Universelle Dienstebene
Zonenredundante Konfiguration für die Dienstebene „Universell“ wird sowohl für serverlose als auch für bereitgestellte Computeressourcen für Datenbanken im vCore-Kaufmodell angeboten. Diese Konfiguration nutzt Azure-Verfügbarkeitszonen zum Replizieren von Datenbanken über mehrere physische Standorte innerhalb einer Azure-Region hinweg. Durch die Auswahl von Zonenredundanz können Sie Ihre neuen und vorhandenen serverlosen und bereitgestellten Einzeldatenbanken des Typs „Universell“ und Pools für elastische Datenbanken für eine viel größere Anzahl von Fehlern – einschließlich schwerwiegender Ausfälle des Rechenzentrums – resilient gestalten, ohne die Anwendungslogik ändern zu müssen.
Bei der zonenredundanten Konfiguration für die Dienstebene „Universell“ gibt es zwei Ebenen:
- Eine zustandsbehaftete Datenebene mit den Datenbankdateien (.mdf/.ldf), die in ZRS (zonenredundanter Speicher) gespeichert sind. Mithilfe von ZRS werden die Daten- und Protokolldateien synchron in mehrere Azure-Verfügbarkeitszonen in der primären Region kopiert. Dies liegt in zwei oder drei Zonen, wie von Azure SQL zur optimalen Resilienz ausgewählt.
- Eine zustandslose Computeebene, auf der der Prozess „sqlservr.exe“ ausgeführt wird und die nur vorübergehende und zwischengespeicherte Daten enthält, z. B. die Datenbanken
tempdbundmodelauf der angefügten SSD, Plancache, Puffer- und Columnstore-Pool im Arbeitsspeicher. Dieser zustandslose Knoten wird von Azure Service Fabric gesteuert, die „sqlservr.exe“ initialisiert, die Integrität des Knotens steuert und bei Bedarf ein Failover zu einem anderen Knoten durchführt. Für zonenredundante serverlose und bereitgestellte Datenbanken vom Typ „Universell“ stehen jederzeit Knoten mit freier Kapazität in anderen Verfügbarkeitszonen für ein Failover bereit.
Die zonenredundante Version der Hochverfügbarkeitsarchitektur für die Dienstebene für allgemeine Zwecke wird in den folgenden Diagrammen in einer Zwei-Zonen- oder drei-Zonen-Region veranschaulicht:
| Region mit zwei Zonen | Region mit drei Zonen |
|---|---|

|

|
Wenn die Berechnung in zwei Verfügbarkeitszonen bereitgestellt wird:
- Sicherung und Speicher werden weiterhin über drei Verfügbarkeitszonen in der Region synchronisiert.
- Zonenredundanter Speicher wird wie immer in drei Verfügbarkeitszonen synchronisiert.
Wenn die Berechnung in drei Verfügbarkeitszonen bereitgestellt wird:
- Sicherung und Speicher werden über drei Verfügbarkeitszonen in der Region synchronisiert.
Alle Azure-Regionen mit Verfügbarkeitszonensupport unterstützen zonenredundante allgemeine Datenbanken.
Für die redundante Zonenverfügbarkeit ist die Auswahl eines anderen Wartungsfensters als der Standard derzeit in ausgewählten Regionen verfügbar. Weitere Informationen finden Sie unter Verfügbarkeit des Wartungsfensters nach Region für Azure SQL-Datenbank.
Zonenredundanz ist für die Dienstebenen „Basic“ und „Standard“ im DTU-Kaufmodell nicht verfügbar.
Dienstebenen „Premium“ und „Unternehmenskritisch“
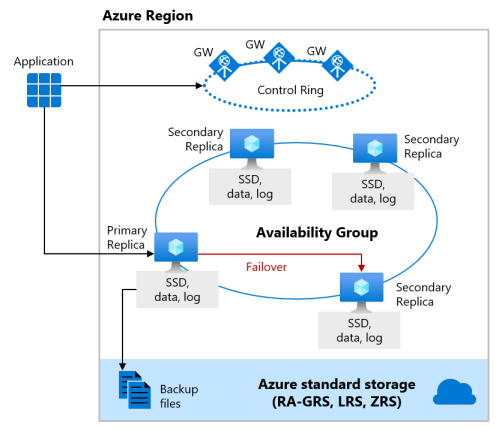
Wenn Zonenredundanz für die Dienstebenen Premium- oder Unternehmenskritisch aktiviert ist, werden die Replikate in verschiedenen Verfügbarkeitszonen in derselben Region platziert. Um einen Single Point of Failure auszuschließen, wird der Steuerring zudem in mehreren Zonen als drei Gatewayringe (GW) kopiert. Die Weiterleitung an einen bestimmten Gatewayring wird durch Azure Traffic Manager gesteuert. Da die zonenredundante Konfiguration in den Premium- oder Unternehmenskritisch-Dienstebenen ihre vorhandenen Replikate verwendet, um sie in verschiedenen Verfügbarkeitszonen zu platzieren, können Sie sie ohne zusätzliche Kosten aktivieren. Durch die Auswahl einer zonenredundanten Konfiguration können Sie Ihre Datenbanken und Pools für elastische Datenbanken der Dienstebenen „Premium“ oder „Unternehmenskritisch“ für deutlich mehr Ausfallszenarien resistent machen (z. B. für schwerwiegende Ausfälle von Rechenzentren), ohne Änderungen an der Anwendungslogik vornehmen zu müssen. Sie können zudem alle vorhandenen Datenbanken oder Pools für elastische Datenbanken der Dienstebenen „Premium“ oder „Unternehmenskritisch“ in die zonenredundante Konfiguration konvertieren.
Die zonenredundante Version der Hochverfügbarkeitsarchitektur für die Business Critical-Dienstebene wird in den folgenden Diagrammen in einer Region mit zwei oder drei Zonen veranschaulicht:
| Region mit zwei Zonen | Region mit drei Zonen |
|---|---|

|

|
Wenn die Berechnung in zwei Verfügbarkeitszonen bereitgestellt wird:
- Für den unternehmenskritischen Speicher werden lokal redundante Verfügbarkeitsspeicher für Daten und Protokolldateien über zwei Verfügbarkeitszonen hinweg synchronisiert.
- Für andere Ebenen werden Sicherung und Speicher über drei Verfügbarkeitszonen in der Region synchronisiert.
- Zonenredundanter Speicher wird wie immer in drei Verfügbarkeitszonen synchronisiert.
Wenn die Berechnung in drei Verfügbarkeitszonen bereitgestellt wird:
- Für den unternehmenskritischen Speicher werden lokal redundante Verfügbarkeitsspeicher für Daten und Protokolldateien in drei Verfügbarkeitszonen synchronisiert.
- Für andere Ebenen werden Sicherung und Speicher über drei Verfügbarkeitszonen in der Region synchronisiert.
Beachten Sie Folgendes, wenn Sie Ihre Datenbanken der Dienstebenen „Premium“ oder „Unternehmenskritisch“ mit Zonenredundanz konfigurieren:
- Alle Azure-Regionen mit Verfügbarkeitszonen-Unterstützung unterstützen zoneredundante Premium- und Business Critical Datenbanken.
- Für die redundante Zonenverfügbarkeit ist die Auswahl eines anderen Wartungsfensters als der Standard derzeit in ausgewählten Regionen verfügbar. Weitere Informationen finden Sie unter Verfügbarkeit des Wartungsfensters nach Region für Azure SQL-Datenbank.
Hyperscale-Dienstebene
Es ist möglich, Zonenredundanz für Datenbanken der Hyperscale-Dienstebene zu konfigurieren. Weitere Informationen finden Sie unter Erstellen einer zonenredundanten Hyperscale-Datenbank.
Wenn Sie diese Konfiguration aktivieren, wird die Resilienz auf Zonenebene durch replikationsübergreifende Verfügbarkeitszonen für alle Hyperscale-Ebenen sichergestellt. Durch die Auswahl von Zonenredundanz können Sie dafür sorgen, dass Ihre Hyperscale-Datenbanken bei einer viel größeren Anzahl von Fehlern (u. a. schwerwiegende Ausfälle des Rechenzentrums) resilient sind, ohne dass dazu die Anwendungslogik geändert werden muss.
Die zonenredundante Verfügbarkeit wird sowohl in eigenständigen Hyperscale-Datenbanken als auch in Hyperscale-Pools für elastische Datenbanken unterstützt. Weitere Informationen finden Sie in der Übersicht über hyperskalige elastische Pools in der Azure SQL-Datenbank.
Die folgenden Diagramme veranschaulichen die zugrunde liegende Architektur für zonenredundante Hyperscale-Datenbanken in einer zwei- oder dreizonen Region:
| Region mit zwei Zonen | Region mit drei Zonen |
|---|---|

|

|
Wenn die Berechnung in zwei Verfügbarkeitszonen bereitgestellt wird:
- Sicherung und Speicher werden über drei Verfügbarkeitszonen in der Region synchronisiert.
- Zonenredundanter Speicher wird wie immer in drei Verfügbarkeitszonen synchronisiert.
Wenn die Berechnung in drei Verfügbarkeitszonen bereitgestellt wird:
- Sicherung und Speicher werden über drei Verfügbarkeitszonen in der Region synchronisiert.
Beachten Sie die folgenden Einschränkungen:
Alle Azure-Regionen mit Verfügbarkeitszone unterstützen zonenredundante Hyperscale-Datenbank.
- Für Hyperscale Premium-Serie und speicheroptimierte Premium-Serienhardware ist Zonenredundanz in bestimmten Regionen verfügbar. Weitere Informationen finden Sie unter Verfügbarkeit der Hyperscale Premium-Serie nach Region für Azure SQL-Datenbank.
Die zonenredundante Konfiguration kann nur während der Datenbankerstellung angegeben werden. Diese Einstellung kann nach der Bereitstellung der Ressource nicht mehr geändert werden. Verwenden Sie Datenbankkopie, Zeitpunktwiederherstellung oder erstellen Sie ein Georeplikat, um die zonenredundante Konfiguration für eine vorhandene Hyperscale-Datenbank zu aktualisieren. Wenn eine dieser Aktualisierungsoptionen verwendet wird und sich die Zieldatenbank in einer anderen Region befindet als die Quelldatenbank oder wenn sich die Redundanz des Datenbanksicherungsspeichers der Zieldatenbank von der der Quelldatenbank unterscheidet, ist der Kopiervorgang von der Größe der Daten abhängig.
Für die redundante Zonenverfügbarkeit ist die Auswahl eines anderen Wartungsfensters als der Standard derzeit in ausgewählten Regionen verfügbar. Weitere Informationen finden Sie unter Verfügbarkeit des Wartungsfensters nach Region für Azure SQL-Datenbank.
Es gibt derzeit keine Option zum Angeben von Zonenredundanz bei der Migration einer Datenbank zu Hyperscale mithilfe des Azure-Portals. Zonenredundanz kann jedoch mithilfe von Azure PowerShell, Azure CLI oder der REST-API angegeben werden, wenn eine vorhandene Datenbank von einer anderen Azure SQL-Datenbank-Dienstebene zu Hyperscale migriert wird. Hier finden Sie ein Beispiel für die Azure CLI:
az sql db update --resource-group "myRG" --server "myServer" --name "myDB" --edition Hyperscale --zone-redundant true`Mindestens ein Hochverfügbarkeits-Computereplikat und die Verwendung zonenredundanter oder geozonenredundanter Sicherungsspeicher ist erforderlich, um die zonenredundante Konfiguration für Hyperscale zu aktivieren.
Zonenredundante Verfügbarkeit der Datenbank
In Azure SQL-Datenbank ist ein Server ein logisches Konstrukt, das als zentraler Verwaltungspunkt für eine Sammlung von Datenbanken fungiert. Auf der Serverebene können Sie Anmeldungen, Authentifizierungsmethode, Firewallregeln, Überwachungsregeln, Bedrohungserkennungsrichtlinien und Failovergruppen verwalten. Daten im Zusammenhang mit einigen dieser Features, z. B. Anmeldungen und Firewallregeln, werden in der master-Datenbank gespeichert. Ebenso werden Daten für einige DMVs, z. B. sys.resource_stats, in der master-Datenbank gespeichert.
Wenn eine Datenbank mit einer zonenredundanten Konfiguration auf einem logischen Server erstellt wird, wird auch die dem Server zugeordnete master-Datenbank automatisch als zonenredundant festgelegt. Dadurch wird sichergestellt, dass Anwendungen, die die Datenbank nutzen, bei einem Zonenausfall nicht betroffen sind, da von der master-Datenbank abhängige Features, z. B. Anmeldungen und Firewallregeln, weiterhin verfügbar sind. Das Festlegen der master-Datenbank als zonenredundant ist ein asynchroner Prozess, der eine Zeit lang im Hintergrund ausgeführt wird.
Wenn keine der Datenbanken auf einem Server zonenredundant ist oder wenn Sie einen leeren Server erstellen, ist die dem Server zugeordnete master-Datenbank nicht zonenredundant. Wenn Sie Ihre Azure SQL-Datenbank migrieren möchten, um Zonenredundanz zu verwenden, führen Sie die Schritte unter Migrieren der Azure SQL-Datenbank zur Unterstützung der Verfügbarkeitszone aus.
Um die ZoneRedundant-Eigenschaft der master-Datenbank zu überprüfen, verwenden Sie die Azure PowerShell, das Azure CLI oder die REST-API-Schritte im Abschnitt Status der Verfügbarkeitszone der Azure SQL-Datenbank.
Testen der Resilienz von Anwendungsfehlern
Hochverfügbarkeit ist ein wesentlicher Bestandteil der SQL-Datenbank-Plattform, der für Ihre Datenbankanwendung transparent ausgeführt wird. Es ist uns jedoch bewusst, dass Sie möglicherweise testen möchten, wie sich die bei geplanten oder ungeplanten Ereignissen eingeleiteten automatischen Failover-Vorgänge ggf. auf eine Anwendung auswirken, ehe Sie sie in der Produktionsumgebung einsetzen. Sie können ein Failover manuell auslösen, indem Sie eine spezielle API zum Neustarten einer Datenbank oder eines Pools für elastische Datenbanken aufrufen. Bei einer zonenredundanten serverlosen oder bereitgestellten Datenbank vom Typ „Universell“ oder einem Pool für elastische Datenbanken würde der API-Aufruf dazu führen, dass Clientverbindungen zur neuen primären Datenbank in einer anderen Verfügbarkeitszone als der Verfügbarkeitszone der alten primären Datenbank umgeleitet werden. Zusätzlich zu den Tests, wie sich das Failover auf bestehende Datenbanksitzungen auswirkt, können Sie also auch prüfen, ob sich aufgrund von Änderungen an der Netzwerklatenz auch die Gesamtleistung ändert. Da Neustartvorgänge aufwendig sind und eine große Anzahl von ihnen die Plattform belasten könnte, ist für jede Datenbank oder jeden Pool für elastische Datenbanken nur alle 15 Minuten ein Failoveraufruf erlaubt.
Weitere Informationen zu hoher Verfügbarkeit und Notfallwiederherstellung in Azure SQL-Datenbank erfahren Sie in der Checkliste für hohe Verfügbarkeit und Notfallwiederherstellung – Azure SQL-Datenbank.
Ein Failover kann mithilfe von PowerShell, der Rest-API oder Azure CLI initiiert werden:
| Bereitstellungstyp | PowerShell | REST API | Azure CLI |
|---|---|---|---|
| Database | Invoke-AzSqlDatabaseFailover | Datenbankfailover | az rest könnte für einen REST-API-Aufruf über die Azure CLI verwendet werden |
| Elastischer Pool | Invoke-AzSqlElasticPoolFailover | Failover für den Pool für elastische Datenbanken | az rest könnte für einen REST-API-Aufruf über die Azure CLI verwendet werden |
Important
Der Failoverbefehl ist für lesbare sekundäre Replikate von Hyperscale-Datenbanken nicht verfügbar.
Conclusion
Azure SQL-Datenbank verfügt über eine integrierte Hochverfügbarkeitslösung, die tief in die Azure-Plattform integriert ist. Sie ist bei der Fehlererkennung und Wiederherstellung von Service Fabric, in Verbindung mit dem Datenschutz von Azure Blob Storage und für höhere Fehlertoleranz von Verfügbarkeitszonen abhängig. Darüber hinaus nutzt Azure SQL-Datenbank die Technologie der AlwaysOn-Verfügbarkeitsgruppen von SQL Server für Datensynchronisierung und Failover. Dank der Kombination dieser Technologien können Anwendungen die Vorteile eines gemischten Speichermodells voll ausschöpfen und sehr anspruchsvolle SLAs unterstützen.