Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
GILT FÜR: Azure CLI ML-Erweiterung v2 (aktuell)Python-SDK azure-ai-ml v2 (aktuell)
Azure CLI ML-Erweiterung v2 (aktuell)Python-SDK azure-ai-ml v2 (aktuell)
In diesem Artikel erfahren Sie, wie Sie mithilfe der SweepJob-Klasse eine effiziente Hyperparameteroptimierung mit dem Azure Machine Learning SDK v2 und CLI v2 automatisieren.
- Definieren des Parametersuchbereichs
- Auswählen eines Samplingalgorithmus
- Festlegen des Optimierungsziels
- Konfigurieren einer Richtlinie für vorzeitige Beendigung
- Festlegen von Einschränkungen für Sweep-Aufträge
- Experiment einreichen
- Visualisieren von Schulungsaufträgen
- Wählen Sie die beste Konfiguration aus.
Was ist die Hyperparameteroptimierung?
Hyperparameter sind anpassbare Einstellungen, die die Modellschulung steuern. Bei neuralen Netzwerken wählen Sie z. B. die Anzahl der ausgeblendeten Ebenen und die Anzahl der Knoten pro Ebene aus. Die Modellleistung hängt stark von diesen Werten ab.
Hyperparameteroptimierung (oder Hyperparameteroptimierung) ist der Prozess der Suche nach der Hyperparameterkonfiguration, die die beste Leistung liefert. Dieser Vorgang ist oft rechenintensiv und manuell.
Mit Azure Machine Learning können Sie die Hyperparameteroptimierung automatisieren und parallel Experimente durchführen, um Hyperparameter effizient zu optimieren.
Definieren des Suchbereichs
Optimieren Sie Hyperparameter, indem Sie den für jeden Hyperparameter definierten Wertebereich untersuchen.
Hyperparameter können diskret oder fortlaufend sein und eine Wertverteilung aufweisen, die mit einem Parameterausdruck ausgedrückt wird.
Diskrete Hyperparameter
Diskrete Hyperparameter werden als eine Choice unter diskreten Werten angegeben.
Choice kann Folgendes sein:
- Ein oder mehrere durch Trennzeichen getrennte Werte
- Ein
range-Objekt - Ein beliebiges
list-Objekt
from azure.ai.ml.sweep import Choice
command_job_for_sweep = command_job(
batch_size=Choice(values=[16, 32, 64, 128]),
number_of_hidden_layers=Choice(values=range(1,5)),
)
Referenzen:
In diesem Fall batch_size nimmt eine von [16, 32, 64, 128] und number_of_hidden_layers eine von [1, 2, 3, 4].
Die folgenden erweiterten diskreten Hyperparameter können ferner mithilfe einer Verteilung angegeben werden:
-
QUniform(min_value, max_value, q)– Gibt einen Wert zurück wie round(Uniform(min_value, max_value) / q) * q -
QLogUniform(min_value, max_value, q)– Gibt einen Wert zurück wie round(exp(Uniform(min_value, max_value)) / q) * q -
QNormal(mu, sigma, q)– Gibt einen Wert zurück wie round(Normal(mu, sigma) / q) * q -
QLogNormal(mu, sigma, q)– Gibt einen Wert zurück wie round(exp(Normal(mu, sigma)) / q) * q
Kontinuierliche Hyperparameter
Fortlaufende Hyperparameter werden als Verteilung über einen fortlaufenden Wertebereich angegeben:
-
Uniform(min_value, max_value)– Gibt einen Wert zurück, der gleichmäßig zwischen min_value und max_value verteilt ist -
LogUniform(min_value, max_value)– Gibt einen gemäß „exp(Uniform(min_value, max_value))“ ermittelten Wert zurück, sodass der Logarithmus des Rückgabewerts einheitlich verteilt ist -
Normal(mu, sigma): Gibt einen realen Wert zurück, der mit einem Mittelwert mu und der Standardabweichung sigma normalverteilt ist -
LogNormal(mu, sigma)– Gibt einen gemäß „exp(Normal(mu, sigma))“ ermittelten Wert zurück, sodass der Logarithmus des Rückgabewerts normalverteilt ist
Im Folgenden sehen Sie ein Beispiel für die Definition des Parameterbereichs:
from azure.ai.ml.sweep import Normal, Uniform
command_job_for_sweep = command_job(
learning_rate=Normal(mu=10, sigma=3),
keep_probability=Uniform(min_value=0.05, max_value=0.1),
)
Referenzen:
Dieser Code definiert einen Suchbereich mit zwei Parametern: learning_rate und keep_probability.
learning_rate weist eine Normalverteilung mit dem Mittelwert 10 und der Standardabweichung 3 auf.
keep_probability weist eine gleichmäßige Verteilung mit dem Mindestwert 0,05 und dem Höchstwert 0,1 auf.
Verwenden Sie für die CLI das Sweep-Job-YAML-Schema, um den Suchbereich zu definieren.
search_space:
conv_size:
type: choice
values: [2, 5, 7]
dropout_rate:
type: uniform
min_value: 0.1
max_value: 0.2
Stichprobenentnahme im Hyperparameterraum
Geben Sie die Samplingmethode für den Hyperparameterbereich an. Azure Machine Learning unterstützt:
- Zufallssampling
- Rastersampling
- Bayessches Sampling
Zufallssampling
Das Zufällige Sampling unterstützt diskrete und kontinuierliche Hyperparameter und unterstützt eine frühzeitige Beendigung von Aufträgen mit geringer Leistung. Viele Benutzer beginnen mit zufälligen Samplings, um vielversprechende Regionen zu identifizieren und dann zu verfeinern.
Bei zufälliger Stichprobenentnahme werden Werte gleichmäßig (oder gemäß der angegebenen Zufallsregel) aus dem definierten Suchraum entnommen. Verwenden Sie nach dem Erstellen Ihres Befehlsauftrags sweep zur Definition des Samplingalgorithmus.
from azure.ai.ml.entities import CommandJob
from azure.ai.ml.sweep import RandomSamplingAlgorithm, SweepJob, SweepJobLimits
command_job = CommandJob(
inputs=dict(kernel="linear", penalty=1.0),
compute=cpu_cluster,
environment=f"{job_env.name}:{job_env.version}",
code="./scripts",
command="python scripts/train.py --kernel $kernel --penalty $penalty",
experiment_name="sklearn-iris-flowers",
)
sweep = SweepJob(
sampling_algorithm=RandomSamplingAlgorithm(seed=999, rule="sobol", logbase="e"),
trial=command_job,
search_space={"ss": Choice(type="choice", values=[{"space1": True}, {"space2": True}])},
inputs={"input1": {"file": "top_level.csv", "mode": "ro_mount"}}, # type:ignore
compute="top_level",
limits=SweepJobLimits(trial_timeout=600),
)
Referenzen:
Sobol
Sobol ist eine quasi zufällige Sequenz, die die Raumfüllung und Reproduzierbarkeit verbessert. Geben Sie einen Seed an und legen Sie rule="sobol" auf RandomSamplingAlgorithm fest.
from azure.ai.ml.sweep import RandomSamplingAlgorithm
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = RandomSamplingAlgorithm(seed=123, rule="sobol"),
...
)
Referenzen: RandomSamplingAlgorithm
Rastersampling
Rastersampling unterstützt diskrete Hyperparameter. Verwenden Sie das Rastersampling, wenn Sie es sich leisten können, Suchbereiche umfassend zu durchsuchen. Dies unterstützt die vorzeitige Beendigung von Aufträgen mit geringer Leistung.
Beim Rastersampling wird eine einfache Rastersuche für alle möglichen Werte durchgeführt. Das Rastersampling kann nur für choice-Hyperparameter verwendet werden. Der folgende Bereich enthält insgesamt sechs Stichproben:
from azure.ai.ml.sweep import Choice
command_job_for_sweep = command_job(
batch_size=Choice(values=[16, 32]),
number_of_hidden_layers=Choice(values=[1,2,3]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "grid",
...
)
Referenzen: Auswahl
Bayessches Sampling
Bayesian Sampling (Bayesian Optimization) wählt neue Proben basierend auf früheren Ergebnissen aus, um die primäre Metrik effizient zu verbessern.
Bayessches Sampling wird empfohlen, wenn Sie es sich leisten können, den Hyperparameterbereich zu erkunden. Optimale Ergebnisse erzielen Sie mit einer maximalen Anzahl von Aufträgen, die größer als oder gleich dem 20-fachen der Anzahl der zu optimierenden Hyperparameter ist.
Die Anzahl der gleichzeitigen Aufträge wirkt sich auf die Effektivität des Optimierungsprozesses aus. Eine kleinere Anzahl gleichzeitiger Aufträge kann zu einer besseren Samplingkonvergenz führen, da durch den geringeren Parallelitätsgrad die Anzahl der Aufträge zunimmt, die von früheren Aufträgen profitieren.
Bayesian Sampling unterstützt choice, uniformund quniform Verteilungen.
from azure.ai.ml.sweep import Uniform, Choice
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "bayesian",
...
)
Referenzen:
Angeben des Sweep-Ziels
Definieren Sie das Ziel Ihres Sweep-Auftrags, indem Sie die primäre Metrik und das Ziel angeben, die durch die Hyperparameteroptimierung optimiert werden sollen. Jeder Trainingsauftrag wird im Hinblick auf die primäre Metrik ausgewertet. Bei der Richtlinie zur vorzeitigen Beendigung wird die primäre Metrik zum Erkennen von Aufträgen mit geringer Leistung verwendet.
-
primary_metric: Der Name der primären Metrik muss exakt mit dem Namen der vom Trainingsskript protokollierten Metrik übereinstimmen. -
goal:Kann entwederMaximizeoderMinimizesein und bestimmt, ob die primäre Metrik beim Auswerten der Aufträge maximiert oder minimiert wird.
from azure.ai.ml.sweep import Uniform, Choice
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "bayesian",
primary_metric="accuracy",
goal="Maximize",
)
Referenzen:
In diesem Beispiel wird "accuracy" maximiert.
Protokollieren von Metriken für die Hyperparameteroptimierung
Ihr Trainingsskript muss die primäre Metrik mit dem genauen Namen protokollieren, der vom Sweep-Auftrag erwartet wird.
Protokollieren Sie die primäre Metrik mit dem folgenden Beispielcodeausschnitt in Ihrem Trainingsskript:
import mlflow
mlflow.log_metric("accuracy", float(val_accuracy))
Verweise: mlflow.log_metric
Mit dem Trainingsskript wird der val_accuracy-Wert berechnet und als die primäre Metrik „accuracy“ protokolliert. Jedes Mal, wenn die Metrik protokolliert wird, wird der Wert vom Dienst zur Hyperparameteroptimierung empfangen. Die Häufigkeit der Berichterstellung können Sie bestimmen.
Weitere Informationen zur Protokollierung von Werten für Trainingsaufträge finden Sie unter Aktivieren der Protokollierung in Azure Machine Learning-Trainingsaufträgen.
Festlegen einer Richtlinie für vorzeitige Beendigung
Beenden Sie frühzeitig schlecht funktionierende Aufträge, um die Effizienz zu verbessern.
Sie können die folgenden Parameter konfigurieren, mit denen die Anwendung einer Richtlinie gesteuert wird:
-
evaluation_interval: die Anwendungshäufigkeit der Richtlinie. Jede Protokollierung der primären Metrik durch das Trainingsskript zählt als ein Intervall. Beim Wert 1 fürevaluation_intervalwird die Richtlinie jedes Mal angewendet, wenn das Trainingsskript die primäre Metrik meldet. Beim Wert 2 fürevaluation_intervalwird die Richtlinie bei jeder zweiten Meldung angewendet. Wenn kein Intervall angegeben wird, wirdevaluation_intervalstandardmäßig auf 0 festgelegt. -
delay_evaluation: Verzögert die erste Auswertung der Richtlinie für eine angegebene Anzahl Intervalle. Dies ist ein optionaler Parameter, der zum Verhindern der vorzeitigen Beendigung von Trainingsaufträgen die Ausführung aller Konfigurationen für eine Mindestanzahl von Intervallen ermöglicht. Wenn er angegeben wird, wird dir Richtlinie bei jedem Vielfachen von evaluation_interval angewendet, das größer als oder gleich groß wie delay_evaluation ist. Wenn kein Intervall angegeben wird, wirddelay_evaluationstandardmäßig auf 0 festgelegt.
Azure Machine Learning unterstützt die folgenden Richtlinien für vorzeitige Beendigung:
Banditenrichtlinie
Die Banditenrichtlinie verwendet einen Pufferfaktor oder eine Menge plus Auswertungsintervall. Sie beendet einen Auftrag, wenn die primäre Metrik außerhalb der zulässigen Pufferzeit des besten Auftrags liegt.
Legen Sie die folgenden Konfigurationsparameter fest:
slack_factoroderslack_amount: Zulässiger Unterschied vom besten Job.slack_factorist ein Verhältnis;slack_amountist ein absoluter Wert.Betrachten Sie als Beispiel die Anwendung einer Banditenrichtlinie auf das Intervall 10. Angenommen, der Auftrag mit der besten Leistung in Intervall 10 hat für das Ziel, die primäre Metrik zu maximieren, die primäre Metrik 0,8 gemeldet. Wenn die Richtlinie mit einem
slack_factorvon 0,2 angegeben wurde, werden alle Trainingsaufträge, deren beste Metrik im Intervall 10 kleiner als 0,66 (0,8/(1+slack_factor)) ist, beendet.evaluation_interval: (optional) die Anwendungshäufigkeit der Richtliniedelay_evaluation: (optional) verzögert die erste Auswertung der Richtlinie für eine angegebene Anzahl Intervalle
from azure.ai.ml.sweep import BanditPolicy
sweep_job.early_termination = BanditPolicy(slack_factor = 0.1, delay_evaluation = 5, evaluation_interval = 1)
Referenzen: BanditPolicy
In diesem Beispiel wird die Richtlinie zur frühzeitigen Beendigung bei jedem Intervall angewendet, wenn Metriken gemeldet werden, beginnend bei Auswertungsintervall 5. Alle Aufträge, deren beste Metrik kleiner als (1/(1+0,1) oder 91 % der Aufträge mit der besten Leistung ist, wird beendet.
Medianstopprichtlinie
Die Medianstopprichtlinie ist eine Richtlinie für vorzeitige Beendigung, die auf dem gleitenden Durchschnitt der von den Aufträgen gemeldeten primären Metriken basiert. Diese Richtlinie berechnet den gleitenden Durchschnitt für alle Trainingsaufträge und beendet Aufträge, bei denen der Wert der primären Metrik schlechter ist als der Median der Durchschnittswerte.
Diese Richtlinie akzeptiert die folgenden Konfigurationsparameter:
-
evaluation_interval: die Anwendungshäufigkeit der Richtlinie (optionaler Parameter). -
delay_evaluation: verzögert die erste Auswertung der Richtlinie für eine angegebene Anzahl Intervalle (optionaler Parameter).
from azure.ai.ml.sweep import MedianStoppingPolicy
sweep_job.early_termination = MedianStoppingPolicy(delay_evaluation = 5, evaluation_interval = 1)
Verweise: MedianStoppingPolicy
In diesem Beispiel wird die Richtlinie zur frühzeitigen Beendigung bei jedem Intervall angewendet, beginnend bei Auswertungsintervall 5. Ein Auftrag wird im fünften Intervall beendet, wenn die beste primäre Metrik schlechter als der Median des gleitenden Durchschnitts der Intervalle 1:5 für alle Trainingsaufträge ist.
Kürzungsauswahlrichtlinie
Die Kürzungsauswahlrichtlinie bricht bei jedem Auswertungsintervall einen Prozentsatz der Aufträge mit der schlechtesten Leistung ab. Aufträge werden anhand der primären Metrik verglichen.
Diese Richtlinie akzeptiert die folgenden Konfigurationsparameter:
-
truncation_percentage: Der Prozentsatz der Aufträge mit der schwächsten Leistung, die bei jedem Auswertungsintervall beendet werden sollen. Eine ganze Zahl zwischen 1 und 99. -
evaluation_interval: (optional) die Anwendungshäufigkeit der Richtlinie -
delay_evaluation: (optional) verzögert die erste Auswertung der Richtlinie für eine angegebene Anzahl Intervalle -
exclude_finished_jobs: Gibt an, ob abgeschlossene Aufträge beim Anwenden der Richtlinie ausgeschlossen werden sollen.
from azure.ai.ml.sweep import TruncationSelectionPolicy
sweep_job.early_termination = TruncationSelectionPolicy(evaluation_interval=1, truncation_percentage=20, delay_evaluation=5, exclude_finished_jobs=true)
Verweise: TruncationSelectionPolicy
In diesem Beispiel wird die Richtlinie zur frühzeitigen Beendigung bei jedem Intervall angewendet, beginnend bei Auswertungsintervall 5. Ein Auftrag wird bei Intervall 5 beendet, wenn ihre Leistung in den unteren 20 % der Leistung aller Aufträge im Intervall 5 liegt. Beim Anwenden der Richtlinie werden abgeschlossene Aufträge ausgeschlossen.
Keine Beendigungsrichtlinie (Standard)
Ist keine Richtlinie angegeben, lässt der Dienst zur Optimierung von Hyperparametern alle Trainingsaufträge bis zum Abschluss ausführen.
sweep_job.early_termination = None
Referenzen: SweepJob
Wählen einer Richtlinie für frühzeitige Beendigung
- Bei einer konservativen Richtlinie, die eine Ersparnis ohne Beendigung vielversprechender Aufträge ermöglicht, sollten Sie eine Medianstopprichtlinie mit den Werten 1 für
evaluation_intervalund 5 fürdelay_evaluationverwenden. Dies ist eine konservative Einstellung, die annähernd 25–35 % Ersparnis ohne Verluste bei der primären Metrik erbringen kann (bezogen auf unsere Auswertungsdaten). - Bei aggressiveren Einsparungen verwenden Sie die Banditenrichtlinie mit einem strengeren (kleineren) zulässigen Puffer oder die Kürzungsauswahlrichtlinie mit einem höheren Kürzungsprozentsatz.
Festlegen von Grenzwerten für Ihren Sweep-Auftrag
Kontrollieren Sie Ihr Ressourcenbudget, indem Sie Grenzwerte für Ihren Sweep-Auftrag festlegen.
-
max_total_trials: Maximale Anzahl von Testaufträgen. Muss eine ganze Zahl zwischen 1 und 1000 sein. -
max_concurrent_trials: (Optional) Maximale Anzahl von Testaufträgen, die gleichzeitig ausgeführt werden können. Wenn hierfür kein Wert angegeben ist, werden so viele Aufträge parallel gestartet, wie durch „max_total_trials“ festgelegt. Wenn dieser Wert angegeben wird, muss es sich um eine ganze Zahl zwischen 1 und 1000 handeln. -
timeout: Die maximale Zeit in Sekunden, die der gesamte Sweep-Auftrag ausgeführt werden darf. Sobald dieser Grenzwert erreicht ist, bricht das System den Sweep-Auftrag ab (einschließlich aller zugehörigen Tests). -
trial_timeout: Die maximale Zeit in Sekunden, die jeder Testauftrag ausgeführt werden darf. Sobald dieser Grenzwert erreicht ist, bricht das System den Test ab.
Hinweis
Wenn sowohl „max_total_trials“ als auch „timeout“ angegeben ist, wird das Experiment zur Optimierung der Hyperparameter beendet, wenn der erste dieser beiden Schwellenwerte erreicht ist.
Hinweis
Die Anzahl der gleichzeitigen Testaufträge wird durch die im angegebenen Computeziel verfügbaren Ressourcen beschränkt. Stellen Sie sicher, dass das Computeziel die verfügbaren Ressourcen für die gewünschte Parallelität aufweist.
sweep_job.set_limits(max_total_trials=20, max_concurrent_trials=4, timeout=1200)
Referenzen: SweepJob.set_limits
Mit diesem Code wird das Experiment zur Optimierung der Hyperparameter so konfiguriert, dass insgesamt maximal 20 Testaufträge verwendet werden, wobei jeweils vier Testaufträge mit einem Timeout von 1.200 Sekunden für den gesamten Sweep-Auftrag ausgeführt werden.
Konfigurieren des Experiments zur Hyperparameteroptimierung
Geben Sie Folgendes an, um Ihr Experiment zur Hyperparameteroptimierung zu konfigurieren:
- Den definierten Suchbereich für Hyperparameter
- Ihren Samplingalgorithmus
- Ihre Richtlinie für vorzeitige Beendigung
- Ihr Ziel
- Ressourceneinschränkungen
- CommandJob oder CommandComponent
- SweepJob
SweepJob kann ein Hyperparameter-Sweeping für den Befehl oder die Befehlskomponente ausführen.
Hinweis
Das in sweep_job verwendete Computeziel muss über genügend Ressourcen für Ihren Parallelitätsgrad verfügen. Weitere Informationen zu Computezielen finden Sie unter Computeziele.
Konfigurieren Sie Ihr Experiment zur Hyperparameteroptimierung:
from azure.ai.ml import MLClient
from azure.ai.ml import command, Input
from azure.ai.ml.sweep import Choice, Uniform, MedianStoppingPolicy
from azure.identity import DefaultAzureCredential
# Create your base command job
command_job = command(
code="./src",
command="python main.py --iris-csv ${{inputs.iris_csv}} --learning-rate ${{inputs.learning_rate}} --boosting ${{inputs.boosting}}",
environment="AzureML-lightgbm-3.2-ubuntu18.04-py37-cpu@latest",
inputs={
"iris_csv": Input(
type="uri_file",
path="https://azuremlexamples.blob.core.windows.net/datasets/iris.csv",
),
"learning_rate": 0.9,
"boosting": "gbdt",
},
compute="cpu-cluster",
)
# Override your inputs with parameter expressions
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.01, max_value=0.9),
boosting=Choice(values=["gbdt", "dart"]),
)
# Call sweep() on your command job to sweep over your parameter expressions
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm="random",
primary_metric="test-multi_logloss",
goal="Minimize",
)
# Specify your experiment details
sweep_job.display_name = "lightgbm-iris-sweep-example"
sweep_job.experiment_name = "lightgbm-iris-sweep-example"
sweep_job.description = "Run a hyperparameter sweep job for LightGBM on Iris dataset."
# Define the limits for this sweep
sweep_job.set_limits(max_total_trials=20, max_concurrent_trials=10, timeout=7200)
# Set early stopping on this one
sweep_job.early_termination = MedianStoppingPolicy(
delay_evaluation=5, evaluation_interval=2
)
Referenzen:
Die command_job Funktion wird als Funktion aufgerufen, sodass Sie Parameterausdrücke anwenden können. Die sweep Funktion ist mit trialSamplingalgorithmus, Objektiv, Grenzwerten und Compute konfiguriert. Der Codeausschnitt stammt aus dem Beispielnotebook Ausführen des Hyperparameter-Sweepings für einen Befehl oder eine Befehlskomponente. In diesem Beispiel sind learning_rate und boosting optimiert. Das frühe Beenden wird durch ein MedianStoppingPolicy ausgelöst, das einen Auftrag beendet, dessen primäre Metrik schlechter ist als der Median der laufenden Durchschnittswerte aller Aufträge (weitere Informationen finden Sie in der MedianStoppingPolicy-Referenz).
Erfahren Sie, wie die Parameterwerte empfangen, analysiert und an das Trainingsskript zur Optimierung weitergegeben werden, in diesem Codebeispiel.
Wichtig
Das Training wird bei jedem Sweep-Auftrag für Hyperparameter von Grund auf neu gestartet (einschließlich Neuerstellung des Modells und aller Datenladeprogramme). Zur Kompensierung können Sie eine Azure Machine Learning-Pipeline oder einen manuellen Prozess verwenden, um einen möglichst großen Teil der Datenaufbereitung vor den Trainingsaufträgen durchzuführen.
Übermitteln des Experiments zur Hyperparameteroptimierung
Nachdem Sie Ihre Konfiguration für die Hyperparameteroptimierung definiert haben, übermitteln Sie den Auftrag:
# submit the sweep
returned_sweep_job = ml_client.create_or_update(sweep_job)
# get a URL for the status of the job
returned_sweep_job.services["Studio"].endpoint
Referenzen:
Visualisieren der Aufträge zur Hyperparameteroptimierung
Visualisieren Sie Hyperparameter-Optimierungsaufträge in Azure Machine Learning Studio. Ausführliche Informationen finden Sie unter Auftragsdatensätze im Studio anzeigen.
Metrikdiagramm: Diese Visualisierung dient zum Nachverfolgen der Metriken, die im Rahmen der Hyperparameteroptimierung für die einzelnen untergeordneten HyperDrive-Aufträge protokolliert werden. Jede Zeile stellt einen untergeordneten Auftrag dar, und jeder Punkt misst den primären Metrikwert bei dieser Laufzeititeration.
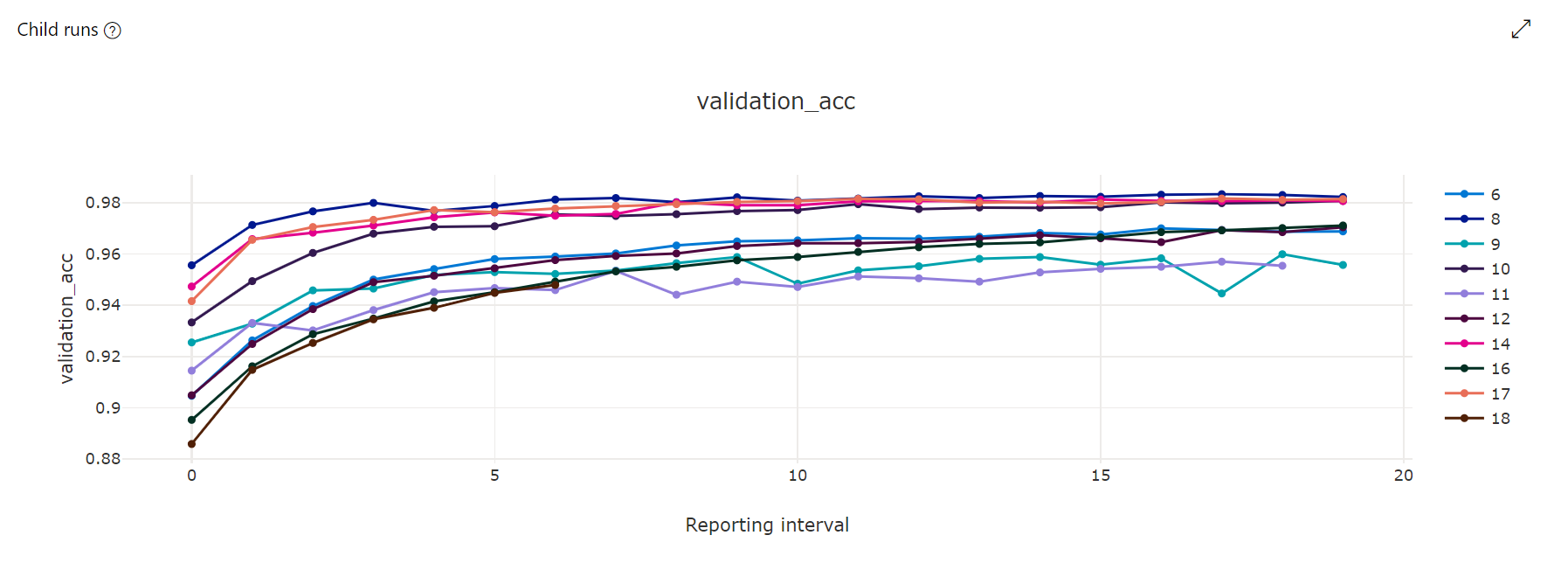
Diagramm mit parallelen Koordinaten: Diese Visualisierung zeigt die Korrelation zwischen der Leistung der primären Metrik und individuellen Hyperparameterwerten. Das Diagramm ist interaktiv. Das bedeutet, die Achsen können durch Auswählen und Ziehen der Achsenbezeichnung verschoben werden. Außerdem können Werte auf einer einzelnen Achse hervorgehoben werden. (Klicken und ziehen Sie vertikal entlang einer einzelnen Achse, um einen gewünschten Wertebereich hervorzuheben.) Auf der rechten Seite des Diagramms mit parallelen Koordinaten befindet sich eine Achse, die den besten Metrikwert entsprechend der für diese Auftragsinstanz festgelegten Hyperparameter kennzeichnet. Mit dieser Achse wird die Diagrammgradientenlegende besser lesbar auf die Daten projiziert.

Zweidimensionales Punktdiagramm: Diese Visualisierung zeigt die Korrelation zwischen zwei individuellen Hyperparametern zusammen mit ihrem zugeordneten primären Metrikwert.

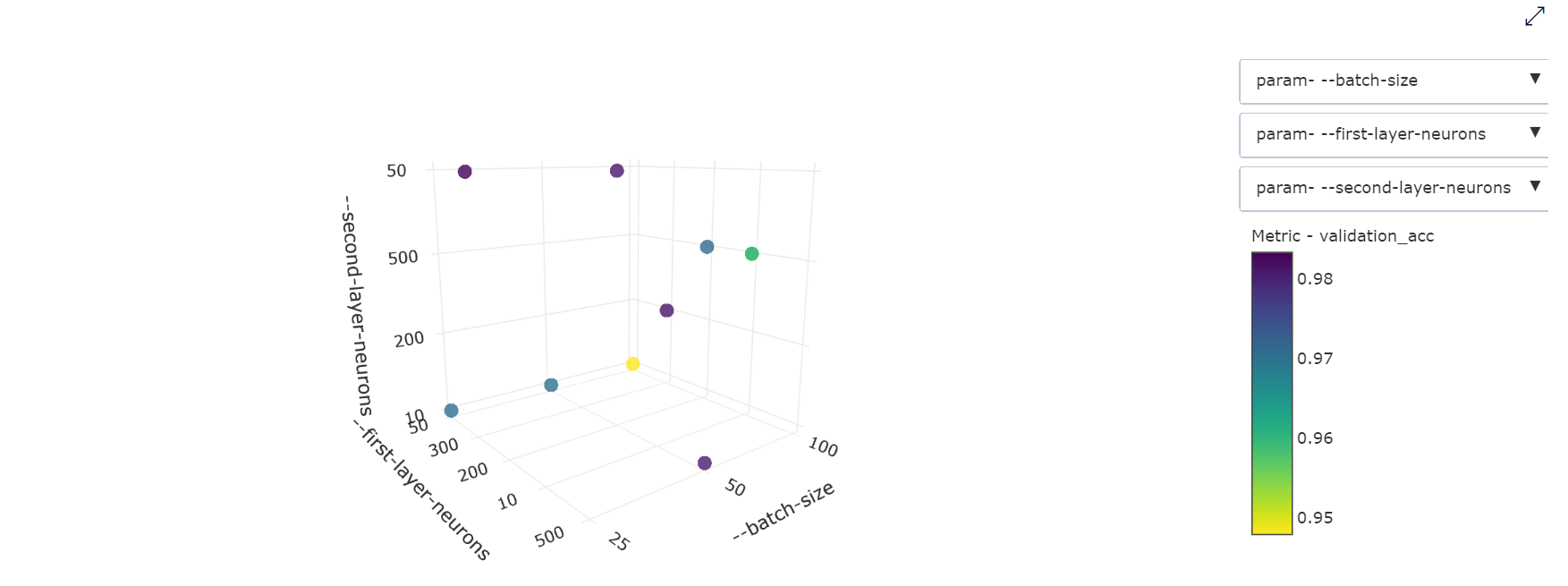
Dreidimensionales Punktdiagramm: Diese Visualisierung ist mit der zweidimensionalen Variante identisch, ermöglicht jedoch die Verwendung von drei Hyperparameterdimensionen für die Korrelation mit dem primären Metrikwert. Sie können auch das Diagramm auswählen und ziehen, um die Ausrichtung des Diagramms zu ändern und verschiedene Korrelationen im dreidimensionalen Raum anzuzeigen.
Suchen des besten Testauftrags
Rufen Sie nach Abschluss aller Optimierungsaufträge die besten Testausgaben ab:
# Download best trial model output
ml_client.jobs.download(returned_sweep_job.name, output_name="model")
Referenzen:
Sie können die Befehlszeilenschnittstelle verwenden, um alle Standard- und benannten Ausgaben des besten Testauftrags und die Protokolle des Sweep-Auftrags herunterzuladen.
az ml job download --name <sweep-job> --all
Optional können Sie nur die beste Testversion herunterladen:
az ml job download --name <sweep-job> --output-name model