Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Die Volltextsuche ist ein Ansatz beim Abrufen von Informationen, die mit Nur-Text-Inhalten übereinstimmen, die in einem Index gespeichert sind. Bei der Abfragezeichenfolge „Hotels in San Diego am Strand“ sucht die Suchmaschine beispielsweise basierend auf diesen Begriffen nach tokenisierten Zeichenfolgen. Um Scans effizienter zu gestalten, werden Abfragezeichenfolgen lexikalisch analysiert: Alle Begriffe werden in Kleinbuchstaben umgewandelt, Stoppwörter wie „der“, „die“, „das“ werden entfernt und Begriffe werden auf die einfache Stammform reduziert. Wenn übereinstimmende Begriffe gefunden werden, ruft die Suchmaschine sie ab, sortiert sie nach Relevanz und gibt die obersten Ergebnisse zurück.
Die Abfrageausführung kann komplex sein. Dieser Artikel ist für Entwickler bestimmt, die eingehendere Informationen zur Funktionsweise der Volltextsuche in Azure KI Search benötigen. Bei Textabfragen liefert Azure AI Search in den meisten Szenarien problemlos erwartete Ergebnisse, aber gelegentlich erhalten Sie möglicherweise ein Ergebnis, das irgendwie "deaktiviert" erscheint. In diesen Situationen können Sie mit einem Hintergrund in den vier Phasen der Abfrageausführung von Lucene (Abfrageanalyse, lexikalische Analyse, Dokumentabgleich und Bewertung) bestimmte Änderungen an Abfrageparametern oder indexkonfigurationen identifizieren, die das gewünschte Ergebnis erzeugen.
Hinweis
Azure AI Search verwendet Apache Lucene für die Volltextsuche, die Lucene-Integration ist jedoch nicht erschöpfend. Wir machen die Lucene-Funktionalität selektiv verfügbar und erweitern sie, um die für Azure KI Search wichtigen Szenarien zu ermöglichen.
Architektur – Übersicht und Diagramm
Die Abfrageausführung besteht aus vier Phasen:
- Abfrageanalyse
- Lexikalische Analyse
- Dokumentabgleich/-abruf
- Bewertung
Eine Abfrage der Volltextsuche beginnt mit der Analyse des Abfragetexts, um die Suchbegriffe und Operatoren zu extrahieren. Es gibt zwei Parser, sodass Sie zwischen Geschwindigkeit und Komplexität wählen können. Als nächstes erfolgt eine Analysephase, in der einzelne Abfrageausdrücke in bestimmten Fällen auch aufgeteilt und neu zusammengesetzt werden können. Dieser Schritt hilft dabei, eine größere Abdeckung für mehr potenzielle Übereinstimmungen zu erreichen. Das Suchmodul überprüft dann den Index, um Dokumente mit übereinstimmenden Begriffen zu finden und bewertet jeden Treffer. Anschließend wird ein Resultset nach einer Relevanzbewertung sortiert, die jedem einzelnen Dokument zugewiesen wird, für das sich eine Übereinstimmung ergibt. Die in der Liste ganz oben aufgeführten Dokumente werden an die aufrufende Anwendung zurückgegeben.
Das folgende Diagramm veranschaulicht die Komponenten, die zum Verarbeiten einer Suchanforderung verwendet werden:
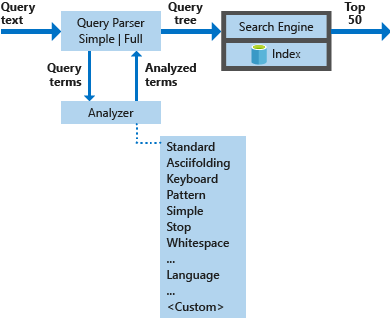
| Wichtige Komponenten | Beschreibung der Funktion |
|---|---|
| Abfrageparser | Dient zum Trennen von Abfrageausdrücken von Abfrageoperatoren und zum Erstellen der Abfragestruktur, die an das Suchmodul gesendet werden soll. |
| Analysemodule | Dienen zum Durchführen der lexikalischen Analyse für Abfrageausdrücke. Dieser Vorgang kann das Transformieren, Entfernen oder Erweitern von Abfragebegriffen umfassen. |
| Index | Eine effiziente Datenstruktur zum Speichern und Organisieren von Suchbegriffen, die aus indizierten Dokumenten extrahiert werden. |
| Suchmodul | Dient zum Abrufen und Bewerten von Dokumenten mit Übereinstimmungen basierend auf dem Inhalt des invertierten Index. |
Anatomie einer Suchanfrage
Eine Suchanfrage ist eine vollständige Spezifikation dessen, was in einem Resultset zurückgegeben werden soll. In ihrer einfachsten Form handelt es sich um eine leere Abfrage ohne Kriterien jeglicher Art. Ein realistischeres Beispiel enthält Parameter, mehrere Abfrageausdrücke, die ggf. auf einen bestimmten Feldbereich festgelegt sind, und unter Umständen einen Filterausdruck und Regeln für die Sortierung.
Das folgende Beispiel ist eine Suchanforderung, die Sie mithilfe der REST-API an Azure AI Search senden können:
POST /indexes/hotels/docs/search?api-version=2025-09-01
{
"search": "Spacious, air-condition* +\"Ocean view\"",
"searchFields": "description, title",
"searchMode": "any",
"filter": "price ge 60 and price lt 300",
"orderby": "geo.distance(___location, geography'POINT(-159.476235 22.227659)')",
"queryType": "full"
}
Für diese Anforderung führt das Suchmodul die folgenden Schritte aus:
Findet die Dokumente, für die der Preis zwischen 60 und 300 USD liegt.
Führt die Abfrage aus. In diesem Beispiel besteht die Suchabfrage aus Ausdrücken und Ausdrücken:
"Spacious, air-condition* +\"Ocean view\""(Benutzer geben in der Regel keine Interpunktion ein, aber indem sie in das Beispiel eingeschlossen wird, können wir erklären, wie Analysegeräte sie behandeln.)Für diese Abfrage durchsucht das Suchmodul die Felder mit der Beschreibung und dem Titel, die in „searchFields“ angegeben sind, nach Dokumenten, die
"Ocean view"enthalten, sowie nach dem Begriff"spacious"oder nach Begriffen, die mit"air-condition"beginnen. Der Parameter „searchMode“ wird verwendet, um eine Übereinstimmung für einen beliebigen Begriff (Standard) oder alle Begriffe zu erzielen, wenn ein Begriff nicht explizit erforderlich ist (+).Sortiert die sich ergebenden Hotels nach ihrer Entfernung zu einem bestimmten geografischen Ort und gibt die Ergebnisse dann an die aufrufende Anwendung zurück.
Der Großteil dieses Artikels befasst sich mit der Verarbeitung der Suchabfrage: "Spacious, air-condition* +\"Ocean view\"". Auf die Filterung und Sortierung wird hier nicht näher eingegangen. Weitere Informationen finden Sie in der Referenzdokumentation zur Search-API.
Phase 1: Abfrageanalyse
Wie bereits erwähnt, ist die Abfragezeichenfolge die erste Zeile der Anfrage:
"search": "Spacious, air-condition* +\"Ocean view\"",
Der Abfrageparser trennt Operatoren (z * . B. und + im Beispiel) von Suchbegriffen und entschlüsselt die Suchabfrage in Unterabfragen eines unterstützten Typs:
- Begriffsabfrage für eigenständige Begriffe (z.B. „spacious“)
- Ausdrucksabfrage für Begriffe in Anführungszeichen (z.B. „ocean view“)
-
Präfixabfrage für Ausdrücke, auf die der Präfixoperator
*folgt (z.B. „air-condition“)
Eine vollständige Liste der unterstützten Abfragetypen finden Sie unter Lucene-Abfragesyntax.
Mit Operatoren, denen eine Unterabfrage zugeordnet ist, wird bestimmt, ob die Abfrage erfüllt werden „muss“ oder erfüllt sein „sollte“, damit ein Dokument als Übereinstimmung angesehen wird.
+"Ocean view" „muss“ aufgrund des Operators + beispielsweise erfüllt sein.
Der Abfrageparser strukturiert die Unterabfragen in eine Abfragestruktur (eine interne Struktur, die die Abfrage darstellt), die sie an die Suchmaschine übergibt. In der ersten Phase der Abfrageanalyse sieht die Abfragestruktur wie folgt aus:

Unterstützte Parser: Lucene, einfach und vollständig („simple“ und „full“)
Azure AI Search macht zwei verschiedene Abfragesprachen verfügbar: simple (Standard) und full. Indem Sie den Parameter queryType für Ihre Suchanfrage festlegen, weisen Sie den Abfrageparser an, welche Abfragesprache zur Verwendung ausgewählt werden soll. Er verfügt somit über die Funktionen zum Interpretieren der Operatoren und der Syntax.
Die Einfache Abfragesprache ist intuitiv und robust, häufig geeignet für die Interpretation von Benutzereingaben as-is ohne clientseitige Verarbeitung. Sie unterstützt Abfrageoperatoren, die Sie aus anderen Websuchmodulen kennen.
Bei der vollständigen Lucene-Abfragesprache, die Sie durch das Festlegen von
queryType=fullerhalten, wird die einfache Abfragesprache erweitert. Es wird Unterstützung für weitere Operatoren und Abfragetypen hinzugefügt, z.B. Platzhalter, Fuzzy Matching, reguläre Ausdrücke und feldbezogene Abfragen. Ein regulärer Ausdruck, der mit einfacher Abfragesyntax gesendet wird, wird beispielsweise als Abfragezeichenfolge und nicht als Ausdruck interpretiert. Für die Beispielabfrage in diesem Artikel wird die vollständige Lucene-Abfragesprache verwendet.
Auswirkung von searchMode auf den Parser
Ein anderer Parameter der Suchanforderung, der sich auf die Analyse auswirkt, ist der Parameter „searchMode“. Er steuert den Standardoperator für boolesche Abfragen: „any“ (Standard) oder „all“.
Bei „searchMode=any“, also der Standardeinstellung, lautet die Trennung zwischen „spacious“ und „air-condition“ OR (||), sodass der Text der Beispielabfrage Folgendem entspricht:
Spacious,||air-condition*+"Ocean view"
Explizite Operatoren, z.B. + in +"Ocean view", sind in der booleschen Abfrage eindeutig (der Begriff muss übereinstimmen). Weniger eindeutig ist, wie die restlichen Begriffe interpretiert werden müssen: „spacious“ und „air-condition“. Soll das Suchmodul nach Übereinstimmungen für „ocean view“ und „spacious“ und „air-condition“ suchen? Oder soll nach „ocean view“ und einem der beiden anderen Begriffe gesucht werden?
Standardmäßig („searchMode=any“) wird vom Suchmodul die weniger eingeschränkte Interpretation vorausgesetzt. Für eines der Felder sollte sich eine Übereinstimmung ergeben. Dies wird mit „OR“ angegeben. In der Abbildung mit der ersten Abfragestruktur weiter oben, die die beiden Vorgänge vom Typ „sollte“ enthält, ist die Standardeinstellung dargestellt.
Angenommen, wir legen jetzt „searchMode=all“ fest. In diesem Fall wird die Leerstelle als Vorgang vom Typ „and“ interpretiert. Beide verbleibenden Begriffe müssen im Dokument vorhanden sein, um als Übereinstimmung zu gelten. Die resultierende Beispielabfrage würde wie folgt interpretiert:
+Spacious,+air-condition*+"Ocean view"
Eine geänderte Abfragestruktur für diese Abfrage, bei der ein übereinstimmende Dokument die Schnittmenge aller drei Unterabfragen ist, würde wie folgt aussehen:

Hinweis
Die Auswahl von "searchMode=any" über "searchMode=all" ist eine Entscheidung, die am besten durch ausführen von repräsentativen Abfragen getroffen wird. Benutzer, die Operatoren verwenden (häufig beim Durchsuchen von Dokumentspeichern), empfinden die Ergebnisse ggf. als intuitiver, wenn „searchMode=all“ für boolesche Abfragen genutzt wird. Weitere Informationen zum Zusammenspiel zwischen "searchMode" und Operatoren finden Sie unter Einfache Abfragesyntax.
Phase 2: Lexikalische Analyse
Mit lexikalischen Analysemodulen werden Begriffsabfragen und Ausdrucksabfragen verarbeitet, nachdem die Abfragestruktur erstellt wurde. Ein Analysemodul akzeptiert die Texteingaben des Parsers, verarbeitet den Text und sendet dann mit Token versehene Begriffe zurück, damit sie in die Abfragestruktur einbezogen werden können.
Die häufigste Form der lexikalischen Analyse ist die linguistische Analyse, die Abfragebegriffe basierend auf regeln, die für eine bestimmte Sprache spezifisch sind. Dazu gehören:
- Reduzieren eines Abfrageausdrucks auf die Stammform eines Worts.
- Entfernen nicht wesentlicher Wörter (Stoppwörter, z. B. "das" oder "und" in Englisch).
- Aufteilen eines zusammengesetzten Worts in Komponententeile.
- Kleinschreibung eines Worts in Großbuchstaben.
Bei all diesen Vorgängen werden Unterschiede zwischen der Texteingabe des Benutzers und den im Index gespeicherten Begriffen normalerweise beseitigt. Vorgänge dieser Art gehen über die Textverarbeitung hinaus und erfordern umfassende Kenntnisse der Sprache. Um diese Ebene der linguistischen Erkennung hinzuzufügen, unterstützt Azure KI Search eine lange Liste an Sprachanalysetools von Lucene und Microsoft.
Hinweis
Je nach Szenario können Analyseanforderungen von minimal bis aufwendig reichen. Sie können die Komplexität der lexikalischen Analyse steuern, indem Sie einen der vordefinierten Analysegeräte auswählen oder einen eigenen benutzerdefinierten Analyzer erstellen. Der Bereich der Analysen ist auf die suchbaren Felder festgelegt, und die Analysen werden als Teil einer Felddefinition angegeben. So können Sie die lexikalische Analyse pro Feld festlegen. Wenn nicht angegeben, wird der Standardmäßige Lucene Analyzer verwendet.
In unserem Beispiel enthält die erste Abfragestruktur vor der Analyse den Begriff „Spacious“ mit einem großen „S“ und einem Komma, das vom Abfrageparser als Teil des Abfrageausdrucks interpretiert wird (ein Komma wird nicht als Operator einer Abfragesprache angesehen).
Wenn die Standardanalyse den Begriff verarbeitet, wird der Begriff "Ozeanansicht" und "geräumige" kleingeschrieben und das Kommazeichen entfernt. Die geänderte Abfragestruktur sieht wie folgt aus:

Testen des Analyseverhaltens
Das Verhalten einer Analyse kann mit der Analyse-API getestet werden. Geben Sie den Text an, den Sie analysieren möchten, um zu sehen, welche Begriffe der angegebene Analyse generiert. Sie können beispielsweise die folgende Anfrage ausgeben, um zu ermitteln, wie die Standardanalyse den Text „air-condition“ verarbeitet:
{
"text": "air-condition",
"analyzer": "standard"
}
Die Standardanalyse teilt den Eingabetext in die folgenden beiden Token auf und fügt Attribute wie Start- und Endoffset (zur Hervorhebung von Treffern) und die Position (für den Wortgruppenabgleich) hinzu:
{
"tokens": [
{
"token": "air",
"startOffset": 0,
"endOffset": 3,
"position": 0
},
{
"token": "condition",
"startOffset": 4,
"endOffset": 13,
"position": 1
}
]
}
Ausnahmen bei der lexikalischen Analyse
Lexikalische Analyse gilt nur für Abfragetypen, die vollständige Ausdrücke erfordern, entweder eine Ausdrucksabfrage oder eine Ausdrucksabfrage. Sie gilt nicht für Abfragetypen mit unvollständigen Begriffen – Präfixabfrage, Wildcardabfrage und regex-Abfrage – oder für eine Fuzzy-Abfrage. Diese Abfragetypen, einschließlich der Präfixabfrage mit dem Ausdruck air-condition* in unserem Beispiel, werden direkt zur Abfragestruktur hinzugefügt, wobei die Analysestufe umgangen wird. Die einzige Transformation, die für die Abfrageausdrücke dieser Typen durchgeführt wird, ist die Umwandlung in Kleinbuchstaben.
Phase 3: Dokumentabgleich/-abruf
Der Dokumentabruf bezieht sich auf das Suchen nach Dokumenten mit übereinstimmenden Ausdrücken im Index. Diese Phase wird am besten durch ein Beispiel verstanden. Beginnen wir mit einem Hotelsindex mit dem folgenden einfachen Schema:
{
"name": "hotels",
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false },
{ "name": "title", "type": "Edm.String", "searchable": true },
{ "name": "description", "type": "Edm.String", "searchable": true }
]
}
Wir nehmen weiter an, dass dieser Index die folgenden vier Dokumente enthält:
{
"value": [
{
"id": "1",
"title": "Hotel Atman",
"description": "Spacious rooms, ocean view, walking distance to the beach."
},
{
"id": "2",
"title": "Beach Resort",
"description": "Located on the north shore of the island of Kauaʻi. Ocean view."
},
{
"id": "3",
"title": "Playa Hotel",
"description": "Comfortable, air-conditioned rooms with ocean view."
},
{
"id": "4",
"title": "Ocean Retreat",
"description": "Quiet and secluded"
}
]
}
Indizierte Ausdrücke
Für das Verständnis des Abrufs ist es hilfreich, einige Grundlagen zur Indizierung zu kennen. Die Speichereinheit ist ein invertierter Index (einer für jedes suchbare Feld). In einem invertierten Index ist eine sortierte Liste aller Ausdrücke aus allen Dokumenten enthalten. Jeder Ausdruck wird der Liste mit den Dokumenten zugeordnet, in denen er vorkommt. Dies ist im Beispiel unten dargestellt.
Zum Erstellen der Ausdrücke in einem invertierten Index führt das Suchmodul eine lexikalische Analyse für den Inhalt von Dokumenten durch. Dies ähnelt der Vorgehensweise während der Abfrageverarbeitung:
- Texteingaben werden je nach Analysekonfiguration an einen Analyzer übergeben, Kleinbuchstaben, Interpunktionsstreifen usw.
- Token sind die Ausgabe der lexikalischen Analyse.
- Ausdrücke werden dem Index hinzugefügt.
Es ist zwar nicht unbedingt erforderlich, aber häufig werden die gleichen Analysen für Such- und Indiziervorgänge verwendet, sodass Abfrageausdrücke eher wie Ausdrücke im Index aussehen.
Hinweis
In Azure KI Search können Sie verschiedene Analysen für das Indizieren und Suchen nach zusätzlichen Feldparametern vom Typ indexAnalyzer und searchAnalyzer angeben. Wenn keine Angabe vorhanden ist, wird die Analyse, die mit der analyzer-Eigenschaft festgelegt wird, sowohl für die Indizierung als auch für die Suche verwendet.
Invertierter Index z. B. Dokumente
Wir kehren zu unserem Beispiel zurück. Für das Feld title sieht der invertierte Index wie folgt aus:
| Begriff | Dokumentliste |
|---|---|
| atman | 1 |
| beach | 2 |
| hotel | 1, 3 |
| ocean | 4 |
| playa | 3 |
| resort | 2 |
| retreat | 4 |
Im Titelfeld wird nur das Hotel in zwei Dokumenten angezeigt: 1 und 3.
Für das Beschreibungsfeld sieht der Index wie folgt aus:
| Begriff | Dokumentliste |
|---|---|
| air | 3 |
| and | 4 |
| beach | 1 |
| conditioned | 3 |
| comfortable | 3 |
| distance | 1 |
| island | 2 |
| kauaʻi | 2 |
| located | 2 |
| north | 2 |
| ocean | 1, 2, 3 |
| of | 2 |
| on | 2 |
| quiet | 4 |
| rooms | 1, 3 |
| secluded | 4 |
| shore | 2 |
| spacious | 1 |
| the | 1, 2 |
| Bis | 1 |
| view | 1, 2, 3 |
| walking | 1 |
| durch | 3 |
Abgleichen von Abfragebegriffen mit indizierten Ausdrücken
Basierend auf den obigen invertierten Indizes kehren Sie zur Beispielabfrage zurück, und sehen Sie sich an, wie für die Beispielabfrage Dokumente mit Übereinstimmungen gefunden werden. Hier zur Erinnerung noch einmal die fertige Abfragestruktur:
Während der Ausführung der Abfrage werden einzelne Abfragen für die suchbaren Felder unabhängig voneinander ausgeführt.
Die Begriffsabfrage „spacious“ ergibt eine Übereinstimmung mit Dokument 1 (Hotel Atman).
Die Präfixabfrage „air-condition*“ ergibt keine Übereinstimmung für Dokumente.
Dieses Verhalten verwechselt manchmal Entwickler. Obwohl der Ausdruck „air-conditioned“ im Dokument vorhanden ist, wird er von der Standardanalyse in zwei Ausdrücke unterteilt. Wir wissen, dass Präfixabfragen, die Teilausdrücke enthalten, nicht analysiert werden. Daher werden Begriffe mit dem Präfix "Klimaanlage" im invertierten Index nachschlagen und nicht gefunden.
Bei der Ausdrucksabfrage „ocean view“ wird nach den Begriffen „ocean“ und „view“ gesucht und die Nähe der Begriffe zueinander im Originaldokument überprüft. Dokumente 1, 2 und 3 stimmen mit dieser Abfrage im Beschreibungsfeld überein. Beachten Sie, dass Dokument 4 den Begriff "Ozean" im Titel hat, aber nicht als Übereinstimmung betrachtet wird, da wir nach dem Ausdruck "Ozeanansicht" und nicht nach einzelnen Wörtern suchen.
Hinweis
Eine Suchabfrage wird unabhängig für alle suchbaren Felder im Azure KI Search-Index ausgeführt, sofern Sie den Satz der Felder nicht mit dem Parameter searchFields beschränken. Dies ist in der Beispielsuchanforderung dargestellt. Dokumente, für die sich in den ausgewählten Feldern Übereinstimmungen ergeben, werden zurückgegeben.
Insgesamt sind für die betreffende Abfrage die Dokumente, die übereinstimmen, 1, 2 und 3.
Phase 4: Bewertung
Jedem Dokument eines Suchergebnisses wird eine Relevanzbewertung zugewiesen. Die Funktion der Relevanzbewertung besteht darin, die Dokumente höher einzustufen, die in Bezug auf die Suchabfrage die beste Beantwortung der Suchabfrage eines Benutzers darstellen. Die Bewertung wird basierend auf den statistischen Eigenschaften der Ausdrücke berechnet, für die sich Übereinstimmungen ergeben. Im Kern der Bewertungsformel ist die Häufigkeits-Inverse-Dokumenthäufigkeit (TF/IDF). In Abfragen, die seltene und häufige Ausdrücke enthalten, werden mit TF/IDF Ergebnisse höhergestuft, die den seltenen Ausdruck enthalten. Für einen hypothetischen Index mit allen Wikipedia-Artikeln gilt für Dokumente, für die die Abfrage the president durchgeführt wurde, beispielsweise Folgendes: Dokumente, die Übereinstimmungen für president enthalten, werden mit einer höheren Relevanz als Dokumente versehen, die Übereinstimmungen für the enthalten.
Beispiel für die Bewertung
Für die drei Dokumente, für die sich Übereinstimmungen mit unserer Beispielabfrage ergeben haben, galt Folgendes:
search=Spacious, air-condition* +"Ocean view"
{
"value": [
{
"@search.score": 0.25610128,
"id": "1",
"title": "Hotel Atman",
"description": "Spacious rooms, ocean view, walking distance to the beach."
},
{
"@search.score": 0.08951007,
"id": "3",
"title": "Playa Hotel",
"description": "Comfortable, air-conditioned rooms with ocean view."
},
{
"@search.score": 0.05967338,
"id": "2",
"title": "Ocean Resort",
"description": "Located on a cliff on the north shore of the island of Kauai. Ocean view."
}
]
}
Für Dokument 1 hat die Abfrage die beste Übereinstimmung ergeben, da sowohl der Begriff spacious als auch der erforderliche Ausdruck ocean view im Feld „description“ vorkommt. Für die nächsten beiden Dokumente ergibt sich nur eine Übereinstimmung mit dem Ausdruck ocean view. Möglicherweise sind Sie überrascht, dass die Relevanzbewertungen für Dokumente 2 und 3 unterschiedlich sind, obwohl sie mit der Abfrage auf die gleiche Weise übereinstimmen. Das liegt daran, dass die Bewertungsformel mehr Komponenten aufweist als nur TF/IDF. In diesem Fall wurde Dokument 3 eine etwas höhere Bewertung zugewiesen, da dessen Beschreibung kürzer ist. Informieren Sie sich über Lucene's Practical Scoring Formula (Bewertungsformel von Lucene), damit Sie verstehen, wie sich die Feldlänge und andere Faktoren auf die Relevanzbewertung auswirken können.
Einige Abfragetypen (Wildcard, Präfix und Regex) tragen immer zur Gesamtbewertung des Dokuments bei. Dadurch können Übereinstimmungen, die durch die Abfrageerweiterung gefunden werden, in die Ergebnisse aufgenommen werden, ohne dass sich dies auf die Rangfolge auswirkt.
In einem Beispiel ist dargestellt, warum dies wichtig ist. Platzhaltersuchen, einschließlich Präfixsuchen, sind definitionlich mehrdeutig, da die Eingabe eine partielle Zeichenfolge mit potenziellen Übereinstimmungen bei einer sehr großen Anzahl unterschiedlicher Ausdrücke ist. Betrachten Sie eine Eingabe von "tour*", mit Übereinstimmungen auf "Touren", "Tourettes" und "Tourmaline". Aufgrund der Art dieser Ergebnisse lässt sich nicht sicher ableiten, welche Begriffe wertvoller als andere sind. Aus diesem Grund ignorieren wir Ausdruckshäufigkeiten beim Bewerten von Abfragen von Typen wildcard, präfix und regex. Bei einer mehrteiligen Suchanfrage, die Teilbegriffe und vollständige Begriffe enthält, werden Ergebnisse aus der Teileingabe mit einer konstanten Bewertung eingebunden, um die Bevorzugung von potenziell unerwarteten Übereinstimmungen zu vermeiden.
Relevanzoptimierung
Es gibt zwei Möglichkeiten, wie Sie Relevanzbewertungen in Azure KI Search optimieren können:
Mit Bewertungsprofilen werden Dokumente in der Rangfolgenliste der Ergebnisse basierend auf einer Gruppe von Regeln höhergestuft. In unserem Beispiel können wir Dokumente, für die sich Übereinstimmungen im Feld „title“ ergeben, als relevanter als Dokumente einstufen, für die sich Übereinstimmungen im Feld „description“ ergeben. Wenn unser Index ein Preisfeld für jedes Hotel hatte, könnten wir Dokumente mit niedrigeren Preisen bewerben. Weitere Informationen zum Hinzufügen von Bewertungsprofilen zu einem Suchindex.
Beim Term Boosting („Begriffsverstärkung“, nur in der vollständigen Lucene-Abfragesyntax verfügbar) wird der Verstärkungsoperator
^bereitgestellt, der auf alle Teile der Abfragestruktur angewendet werden kann. In unserem Beispiel könnten wir anstatt nach dem Präfix air-condition* auch entweder nach dem exakten Begriff air-condition oder dem Präfix suchen. Dokumente, für die sich eine Übereinstimmung mit dem exakten Begriff ergibt, werden dann höher eingestuft, indem die Begriffsabfrage verstärkt wird: air-condition^2||air-condition*. Weitere Informationen zum „Term Boosting“ einer Abfrage.
Durchführen von Bewertungen in einem verteilten Index
Alle Indizes in Azure KI Search werden automatisch in mehrere Shards unterteilt, sodass wir den Index beim Hoch- oder Herunterskalieren des Diensts schnell auf mehrere Knoten verteilen können. Wenn eine Suchanforderung ausgestellt wird, wird sie unabhängig von jedem Shard ausgestellt. Die Ergebnisse aller Shards werden dann zusammengeführt und nach der Bewertung sortiert (falls keine andere Sortierung festgelegt ist). Es ist wichtig, dass Sie Folgendes wissen: Die Bewertungsfunktion wägt die Vorkommenshäufigkeit von Abfragebegriffen gegenüber der inversen Dokumenthäufigkeit für alle Dokumente des Shards ab. Nicht übergreifend für alle Shards!
Dies bedeutet, dass eine Relevanzbewertung für identische Dokumente unterschiedliche ausfallen kann, wenn diese sich auf unterschiedlichen Shards befinden. Glücklicherweise sind diese Unterschiede vernachlässigbar, wenn im Index eine größere Zahl von Dokumenten enthalten ist, weil die Begriffe gleichmäßiger verteilt sind. Es ist nicht möglich, davon auszugehen, auf welche Seite ein bestimmtes Dokument eingefügt wird. Wenn wir aber davon ausgehen, dass sich ein Dokumentschlüssel nicht ändert, wird es immer demselben Shard zugewiesen.
Im Allgemeinen ist die Dokumentbewertung nicht das am besten geeignete Attribut zum Sortieren von Dokumenten, wenn die Stabilität der Sortierung wichtig ist. Wenn beispielsweise zwei Dokumente mit einer identischen Bewertung vorhanden sind, kann nicht garantiert werden, dass bei nachfolgenden Ausführungen derselben Abfrage das Selbe zuerst angezeigt wird. Die Dokumentbewertung soll nur als allgemeiner Hinweis auf die Relevanz des Dokuments relativ zu anderen Dokumenten des Resultsets dienen.
Schlussbemerkung
Aufgrund des Erfolgs kommerzieller Suchmaschinen sind die Erwartungen in Bezug auf die Volltextsuche für private Daten gestiegen. Für nahezu alle Arten von Suchoberflächen erwarten wir mittlerweile, dass die Suchmaschine unsere Absicht erkennt – auch bei falsch geschriebenen oder unvollständigen Suchbegriffen. Wir erwarten vielleicht sogar Übereinstimmungen anhand von ähnlichen Begriffen oder Synonymen, die wir nie angegeben haben.
Aus technischer Sicht ist die Volltextsuche hochkomplex und erfordert eine anspruchsvolle linguistische Analyse und einen systematischen Verarbeitungsansatz, bei dem Abfrageausdrücke herausgefiltert, erweitert und transformiert werden, um die relevanten Ergebnisse zu liefern. Diese komplexen Anforderungen sind mit vielen Faktoren verbunden, die sich auf das Ergebnis einer Abfrage auswirken können. Aus diesem Grund ist es sinnvoll, Zeit für die Einarbeitung in die Details der Volltextsuche zu investieren. Mit diesem Wissen ergeben sich für Sie nützliche Vorteile bei der Analyse von unerwarteten Ergebnissen.
In diesem Artikel wurde die Volltextsuche im Rahmen von Azure KI Search beschrieben. Wir hoffen, dass er genügend Hintergrundinformationen enthält, die Ihnen das Erkennen von potenziellen Ursachen und Lösungen für häufig auftretende Abfrageprobleme ermöglichen.
Nächste Schritte
Erstellen Sie den Beispielindex, probieren Sie verschiedene Abfragen aus, und überprüfen Sie die Ergebnisse. Eine Anleitung finden Sie unter Erstellen und Abfragen eines Index im Azure-Portal.
Probieren Sie andere Abfragesyntax in den Beispielen unter Durchsuchen von Dokumenten oder unter Einfache Abfragesyntax in Azure Search im Suchexplorer im Azure-Portal aus.
Sehen Sie sich die Bewertungsprofile an, wenn Sie die Rangfolge in Ihrer Suchanwendung optimieren möchten.
Wenden Sie sprachspezifische lexikalische Analysegeräte an.
Konfigurieren Sie benutzerdefinierte Analysen für die minimale oder spezielle Verarbeitung anhand von bestimmten Feldern.
Verwandte Inhalte
Search Documents (Azure Search Service REST API) (Suchen nach Dokumenten (Azure Search Service-REST-API))