Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Mit der Abfragebeschleunigung können Anwendungen und Analyseframeworks die Datenverarbeitung erheblich optimieren, indem nur die Daten abgerufen werden, die sie zum Ausführen eines bestimmten Vorgangs benötigen. Dies reduziert die Zeit- und Verarbeitungsleistung, die erforderlich ist, um kritische Einblicke in gespeicherte Daten zu gewinnen.
Überblick
Die Abfragebeschleunigung akzeptiert filterte Prädikate und Spaltenprojektionen, mit denen Anwendungen Zeilen und Spalten zum Zeitpunkt des Lesens von Daten vom Datenträger filtern können. Nur die Daten, die die Bedingungen eines Prädikats erfüllen, werden über das Netzwerk an die Anwendung übertragen. Dies reduziert die Netzwerklatenz und die Berechnungskosten.
Sie können SQL verwenden, um die Zeilenfilter-Prädikate und Spaltenprojektionen in einer Abfragebeschleunigungsanforderung anzugeben. Eine Anforderung verarbeitet nur eine Datei. Daher werden erweiterte relationale Features von SQL, z. B. Verknüpfungen und Gruppierungen nach Aggregaten, nicht unterstützt. Die Abfragebeschleunigung unterstützt CSV- und JSON-formatierte Daten als Eingabe für jede Anforderung.
Die Abfragebeschleunigungsfunktion ist nicht auf Data Lake Storage beschränkt (Speicherkonten, für die der hierarchische Namespace aktiviert ist). Die Abfragebeschleunigung ist mit den Blobs in Speicherkonten kompatibel, für die kein hierarchischer Namespace aktiviert ist. Dies bedeutet, dass Sie bei der Verarbeitung von Daten, die Sie bereits als Blobs in Speicherkonten gespeichert haben, die gleiche Reduzierung der Netzwerklatenz und die Berechnungskosten erzielen können.
Ein Beispiel für die Verwendung der Abfragebeschleunigung in einer Clientanwendung finden Sie unter "Filtern von Daten mithilfe der Azure Data Lake Storage-Abfragebeschleunigung".
Datenfluss
Das folgende Diagramm veranschaulicht, wie eine typische Anwendung Abfragebeschleunigung zum Verarbeiten von Daten verwendet.
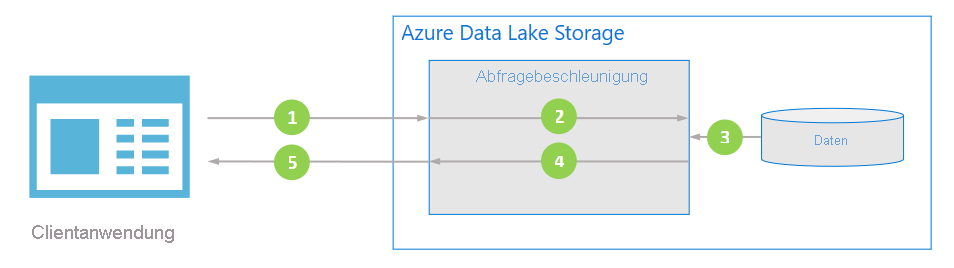
Die Clientanwendung fordert Dateidaten an, indem Prädikate und Spaltenprojektionen angegeben werden.
Die Abfragebeschleunigung analysiert die angegebene SQL-Abfrage und verteilt Arbeit zum Analysieren und Filtern von Daten.
Prozessoren lesen die Daten vom Datenträger, analysiert die Daten mithilfe des entsprechenden Formats und filtert dann Daten, indem die angegebenen Prädikate und Spaltenprojektionen angewendet werden.
Die Abfragebeschleunigung kombiniert die Antwortfragmente, um sie zurück an die Clientanwendung zu übertragen.
Die Clientanwendung empfängt und analysiert die gestreamte Antwort. Die Anwendung muss keine anderen Daten filtern und kann die gewünschte Berechnung oder Transformation direkt anwenden.
Bessere Leistung bei geringeren Kosten
Die Abfragebeschleunigung optimiert die Leistung, indem die Datenmenge reduziert wird, die von Ihrer Anwendung übertragen und verarbeitet wird.
Um einen aggregierten Wert zu berechnen, rufen Anwendungen häufig alle Daten aus einer Datei ab, verarbeiten und filtern sie dann lokal. Eine Analyse der Eingabe-/Ausgabemuster für Analyseworkloads zeigt, dass Anwendungen in der Regel nur 20% der Daten benötigen, die sie lesen, um eine bestimmte Berechnung durchzuführen. Diese Statistik gilt auch nach der Anwendung von Techniken wie Partitionsschneiden. Dies bedeutet, dass 80% dieser Daten unnötig über das Netzwerk übertragen, analysiert und von Anwendungen gefiltert werden. Dieses Muster, das zum Entfernen nicht benötigter Daten konzipiert ist, verursacht erhebliche Berechnungskosten.
Obwohl Azure über ein branchenführendes Netzwerk verfügt, ist die Übertragung von Daten über dieses Netzwerk in Bezug auf Durchsatz und Latenz immer noch teuer für die Anwendungsleistung. Durch das Filtern der unerwünschten Daten während der Speicheranforderung beseitigt die Abfragebeschleunigung diese Kosten.
Darüber hinaus erfordert die CPU-Auslastung, die zum Analysieren und Filtern nicht benötigter Daten erforderlich ist, dass Ihre Anwendung eine größere Anzahl und größere VMs bereitstellen kann, um ihre Arbeit zu erledigen. Durch das Übertragen dieser Rechenlast auf die Abfragebeschleunigung können Anwendungen erhebliche Kosteneinsparungen erzielen.
Anwendungen, die von der Abfragebeschleunigung profitieren können
Die Abfragebeschleunigung wurde für verteilte Analyseframeworks und Datenverarbeitungsanwendungen entwickelt.
Verteilte Analyseframeworks wie Apache Spark und Apache Hive enthalten eine Speicherstraktionsebene innerhalb des Frameworks. Diese Engines umfassen auch Abfrageoptimierer, die Kenntnisse über die Funktionen des zugrunde liegenden E/A-Diensts enthalten können, wenn sie einen optimalen Abfrageplan für Benutzerabfragen bestimmen. Diese Frameworks beginnen mit der Integration der Abfragebeschleunigung. Infolgedessen profitieren Benutzende dieser Frameworks von einer verbesserten Abfragelatenz und geringeren Gesamtkosten, ohne Änderungen an den Abfragen vornehmen zu müssen.
Die Abfragebeschleunigung wurde auch für Datenverarbeitungsanwendungen entwickelt. Diese Arten von Anwendungen führen in der Regel große Datentransformationen durch, die möglicherweise nicht direkt zu Analyseerkenntnissen führen, sodass sie nicht immer etablierte verteilte Analyseframeworks verwenden. Diese Anwendungen haben häufig eine direktere Beziehung zum zugrunde liegenden Speicherdienst, sodass sie direkt von Features wie der Abfragebeschleunigung profitieren können.
Ein Beispiel dafür, wie eine Anwendung die Abfragebeschleunigung integrieren kann, finden Sie unter Filtern von Daten mithilfe der Azure Data Lake Storage-Abfragebeschleunigung.
Preisgestaltung
Aufgrund der erhöhten Computelast innerhalb des Azure Data Lake Storage-Diensts unterscheidet sich das Preismodell für die Verwendung der Abfragebeschleunigung vom normalen Azure Data Lake Storage-Transaktionsmodell. Die Abfragebeschleunigung berechnet Kosten für die Menge der gescannten Daten sowie Kosten für die Menge der an den Abfragenden zurückgegebenen Daten. Weitere Informationen finden Sie unter Azure Data Lake Storage-Preise.
Trotz des geänderten Abrechnungsmodells ist das Preismodell für die Abfragebeschleunigung so angelegt, dass die Gesamtkosten für eine Workload geringer ausfallen, da die wesentlich höheren Kosten für VMs gesenkt werden.