Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Von Bedeutung
Azure Synapse Analytics Data Explorer (Vorschau) wird am 7. Oktober 2025 eingestellt. Nach diesem Datum werden Arbeitslasten, die im Synapse-Daten-Explorer ausgeführt werden, gelöscht, und die zugehörigen Anwendungsdaten gehen verloren. Es wird dringend empfohlen , zu Eventhouse in Microsoft Fabric zu migrieren.
Das Microsoft Cloud Migration Factory (CMF)-Programm wurde entwickelt, um Kunden bei der Migration zu Fabric zu unterstützen. Das Programm bietet dem Kunden kostenlos praktische Tastaturressourcen. Diese Ressourcen werden für einen Zeitraum von 6-8 Wochen mit einem vordefinierten und vereinbarten Umfang zugewiesen. Kunden nominierungen werden vom Microsoft-Kontoteam oder direkt durch Senden einer Anfrage zur Hilfe an das CMF-Team akzeptiert.
Die Datenaufnahme ist der Prozess, der zum Laden von Datensätzen aus einer oder mehreren Quellen verwendet wird, um Daten in eine Tabelle im Azure Synapse-Daten-Explorer-Pool zu importieren. Nach der Erfassung stehen die Daten für die Abfrage zur Verfügung.
Der Azure Synapse Data Explorer-Datenverwaltungsdienst, der für die Datenaufnahme verantwortlich ist, implementiert den folgenden Prozess:
- Ruft Daten in Batches oder Streaming aus einer externen Quelle ab und liest Anforderungen aus einer ausstehenden Azure-Warteschlange.
- Batchdaten, die an dieselbe Datenbank und Tabelle fließen, sind für den Aufnahmedurchsatz optimiert.
- Die anfänglichen Daten werden überprüft, und das Format wird bei Bedarf konvertiert.
- Weitere Datenmanipulation, einschließlich übereinstimmender Schemas, Organisieren, Indizieren, Codieren und Komprimieren der Daten.
- Daten werden gemäß der festgelegten Aufbewahrungsrichtlinie im Speicher gespeichert.
- Erfasste Daten werden in die Engine übernommen, in der sie für Abfragen verfügbar sind.
Unterstützte Datenformate, Eigenschaften und Berechtigungen
Aufnahmeeigenschaften: Die Eigenschaften, die sich darauf auswirken, wie die Daten aufgenommen werden (z. B. Tagging, Zuordnung, Erstellungszeit).
Berechtigungen: Zum Aufnehmen von Daten benötigt der Prozess Berechtigungen auf Datenbankingestorebene. Andere Aktionen, z. B. Abfragen, erfordern möglicherweise Datenbankadministrator-, Datenbankbenutzer- oder Tabellenadministratorberechtigungen.
Batchverarbeitung im Vergleich zu Streaming-Erfassungen
Bei der Batcherfassung werden die Daten in Batches zusammengefasst und für einen hohen Erfassungsdurchsatz optimiert. Diese Methode ist der bevorzugte und leistungsstärkste Typ der Aufnahme. Die Daten werden gemäß den Erfassungseigenschaften in Batches zusammengefasst. Kleine Datenbatches werden zusammengeführt und für schnelle Abfrageergebnisse optimiert. Die Erfassungsbatchrichtlinie kann für Datenbanken oder Tabellen festgelegt werden. Der maximale Batchwert beträgt standardmäßig 5 Minuten, 1000 Elemente oder eine Gesamtgröße von 1 GB. Der Grenzwert für die Datengröße für einen Batchaufnahmebefehl beträgt 4 GB.
Streaming-Erfassung ist eine fortlaufende Datenaufnahme aus einer Streamingquelle. Durch die Streamingerfassung sinkt die Latenz bei kleinen Datensätzen pro Tabelle auf nahezu Echtzeit. Die Daten werden anfänglich im Zeilenspeicher erfasst und dann in Spaltenspeichererweiterungen verschoben.
Aufnahmemethoden und -tools
Der Azure Synapse-Daten-Explorer unterstützt mehrere Aufnahmemethoden, die jeweils eigene Zielszenarien aufweisen. Diese Methoden umfassen Erfassungstools, Connectors und Plug-Ins für verschiedene Dienste, verwaltete Pipelines, die programmgesteuerte Erfassung mithilfe von SDKs und Direktzugriff auf die Erfassung.
Erfassung mit verwalteten Pipelines
Für Organisationen, die eine Verwaltung (Drosselung, Wiederholungen, Überwachungen, Warnungen usw.) über einen externen Dienst durchführen möchten, stellt die Verwendung eines Connectors wahrscheinlich die geeignetste Lösung dar. Die Erfassung in der Warteschlange eignet sich für große Datenmengen. Der Azure Synapse-Daten-Explorer unterstützt die folgenden Azure-Pipelines:
- Event Hub: Eine Pipeline, die Ereignisse von Diensten an Azure Synapse-Daten-Explorer überträgt. Weitere Informationen finden Sie unter "Erfassen von Daten aus dem Event Hub in Azure Synapse Data Explorer".
- Synapse-Pipelines: Ein vollständig verwalteter Datenintegrationsdienst für Analysearbeitslasten in Synapse-Pipelines verbindet sich mit über 90 unterstützten Quellen, um eine effiziente und robuste Datenübertragung zu ermöglichen. Synapse-Pipelines bereiten Daten vor, transformieren und bereichern Daten, um Einblicke zu geben, die auf verschiedene Arten überwacht werden können. Dieser Dienst kann als einmalige Lösung, in regelmäßigen Abständen oder von bestimmten Ereignissen ausgelöst werden.
Programmgesteuerte Erfassung mithilfe von SDKs
Azure Synapse Data Explorer stellt SDKs bereit, die für die Abfrage- und Datenaufnahme verwendet werden können. Die programmgesteuerte Erfassung ist für die Reduzierung der Aufnahmekosten (COGs) optimiert, indem Speichertransaktionen während und nach dem Aufnahmeprozess minimiert werden.
Bevor Sie beginnen, gehen Sie wie folgt vor, um die Endpoints des Daten-Explorer-Pools zum Konfigurieren der programmgesteuerten Erfassung abzurufen.
Wählen Sie in Synapse Studio im linken Bereich die Option Verwalten>Data Explorer-Pools aus.
Wählen Sie den Daten-Explorer-Pool aus, den Sie zum Anzeigen seiner Details verwenden möchten.
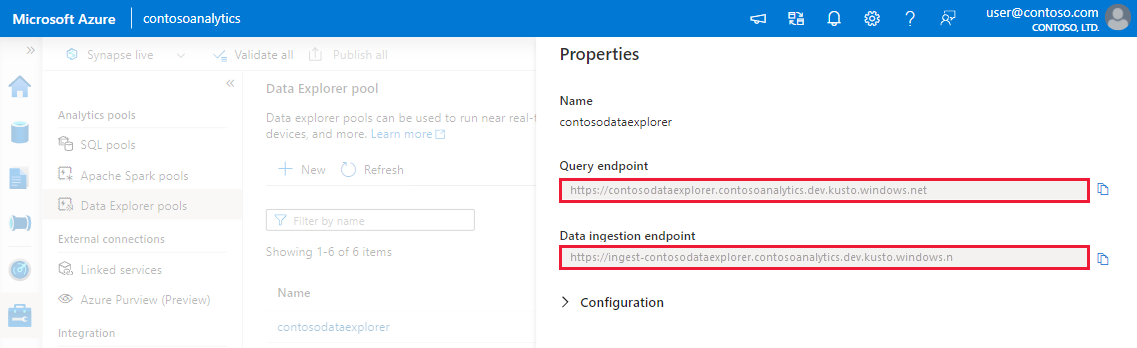
Notieren Sie sich die Endpunkte "Abfrage" und "Datenaufnahme". Verwenden Sie den Abfrageendpunkt als Cluster, wenn Verbindungen mit Ihrem Daten-Explorer-Pool konfiguriert werden. Verwenden Sie beim Konfigurieren von SDKs für die Datenaufnahme den Datenaufnahmeendpunkt.
Verfügbare SDKs und Open-Source-Projekte
Werkzeuge
- Mit nur einem Klick können Sie Daten schnell erfassen, indem Sie Tabellen aus einer Vielzahl von Quelltypen erstellen und anpassen. Bei der 1-Klick-Erfassung werden basierend auf der Datenquelle in Azure Synapse Data Explorer automatisch Tabellen und Zuordnungsstrukturen vorschlagen. Die Ein-Klick-Aufnahme kann für die einmalige Aufnahme verwendet werden oder um eine kontinuierliche Aufnahme über das Ereignisraster im Container zu definieren, in den die Daten aufgenommen wurden.
Befehle zur Steuerung der Erfassung in der Kusto-Abfragesprache
Es gibt eine Reihe von Methoden, mit denen Daten direkt durch Kusto Query Language (KQL)-Befehle in die Engine übernommen werden können. Da diese Methode die Datenverwaltungsdienste umgeht, ist sie nur für Die Erkundung und Prototyperstellung geeignet. Verwenden Sie diese Methode nicht in Produktions- oder Volumenszenarien.
Inlineerfassung: An die Engine wird ein Steuerungsbefehl (.ingest inline) gesendet, und die zu erfassenden Daten werden direkt im Befehlstext angegeben. Diese Methode ist für improvisierte Testzwecke vorgesehen.
Erfassen aus Abfrage: An die Engine wird ein Steuerungsbefehl „.set“, „.append“, „.set-or-append“ oder „.set-or-replace“ gesendet, und die Daten werden indirekt als die Ergebnisse einer Abfrage oder eines Befehls angegeben.
Erfassen aus Speicher (Pull): An die Engine wird ein Steuerungsbefehl .ingest into gesendet, und die Daten werden in einem externen Speicher (beispielsweise in Azure Blob Storage) gespeichert, auf den die Engine zugreifen kann und auf den durch den Befehl verwiesen wird.
Ein Beispiel für die Verwendung von Erfassungssteuerungsbefehlen finden Sie unter Schnellstart: Analysieren mit Data Explorer.
Aufnahmeprozess
Nachdem Sie die am besten geeignete Aufnahmemethode für Ihre Anforderungen ausgewählt haben, führen Sie die folgenden Schritte aus:
Festlegen einer Aufbewahrungsrichtlinie
Daten, die in eine Tabelle im Azure Synapse-Daten-Explorer aufgenommen werden, unterliegen der effektiven Aufbewahrungsrichtlinie der Tabelle. Wurde für eine Tabelle nicht explizit eine effektive Aufbewahrungsrichtlinie festgelegt, wird sie von der Aufbewahrungsrichtlinie der Datenbank abgeleitet. Die heiße Speicherebene für die Aufbewahrung ist eine Funktion aus der Clustergröße und Ihrer Aufbewahrungsrichtlinie. Wenn Sie mehr Daten erfassen, als Speicherplatz verfügbar ist, werden die zuerst erfassten Daten in die kalte Aufbewahrung überführt.
Stellen Sie sicher, dass die Aufbewahrungsrichtlinie der Datenbank für Ihre Anforderungen geeignet ist. Ist dies nicht der Fall, überschreiben Sie sie explizit auf Tabellenebene. Weitere Informationen finden Sie unter "Aufbewahrungsrichtlinie".
Tabelle erstellen
Um Daten aufzunehmen, muss vorher eine Tabelle erstellt werden. Verwenden Sie eine der folgenden Optionen:
Erstellen Sie eine Tabelle mit einem Befehl. Ein Beispiel für die Verwendung des Befehls "Tabelle erstellen" finden Sie unter "Analysieren mit Dem Daten-Explorer".
Erstellen Sie eine Tabelle mit der 1-Klick-Erfassung.
Hinweis
Wenn ein Datensatz unvollständig ist oder ein Feld nicht als erforderlicher Datentyp analysiert werden kann, werden die entsprechenden Tabellenspalten mit NULL-Werten aufgefüllt.
Schemazuordnung erstellen
Die Schemazuordnung hilft beim Binden von Quelldatenfeldern an Zieltabellenspalten. Mithilfe der Zuordnung können Sie Daten aus verschiedenen Quellen basierend auf den definierten Attributen in die gleiche Tabelle aufnehmen. Verschiedene Arten von Zuordnungen werden unterstützt, sowohl zeilenorientierte (CSV, JSON und AVRO) als auch spaltenorientierte (Parquet). Bei den meisten Methoden können Zuordnungen auch vorab in der Tabelle erstellt und vom Erfassungsbefehlsparameter referenziert werden.
Festlegen der Updaterichtlinie (optional)
Einige der Datenformatzuordnungen (Parquet, JSON und Avro) unterstützen einfache und nützliche Transformationen während der Erfassung. Wenn für das Szenario eine komplexere Verarbeitung zum Zeitpunkt der Aufnahme erforderlich ist, verwenden Sie die Updaterichtlinie, die eine leichte Verarbeitung mithilfe von Kusto Query Language-Befehlen ermöglicht. Die Aktualisierungsrichtlinie führt automatisch Extraktionen und Transformationen für aufgenommene Daten in der ursprünglichen Tabelle aus und erfasst die resultierenden Daten in einer oder mehreren Zieltabellen. Legen Sie Ihre Updaterichtlinie fest.