Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Important
Items marked (preview) in this article are currently in public preview. This preview is provided without a service-level agreement, and we don't recommend it for production workloads. Certain features might not be supported or might have constrained capabilities. For more information, see Supplemental Terms of Use for Microsoft Azure Previews.
When you have critical applications and business processes that rely on Azure resources, you need to monitor and get alerts for your system. The Azure Monitor service collects and aggregates metrics and logs from every component of your system, including Foundry Models deployments. You can use this information to view availability, performance, and resilience, and get notifications of issues.
This document explains how you can use metrics and logs to monitor model deployments in Foundry Models.
Prerequisites
To use monitoring capabilities for model deployments in Foundry Models, you need the following:
An Azure AI services resource. For more information, see Create an Azure AI Services resource.
Tip
If you're using Serverless API Endpoints and you want to take advantage of monitoring capabilities explained in this document, migrate your Serverless API Endpoints to Foundry Models.
At least one model deployment.
Access to diagnostic information for the resource.
Metrics
Azure Monitor collects metrics from Foundry Models automatically. No configuration is required. These metrics are:
- Stored in the Azure Monitor time-series metrics database.
- Lightweight and capable of supporting near real-time alerting.
- Used to track the performance of a resource over time.
View metrics
Azure Monitor metrics can be queried using multiple tools, including:
Azure AI Foundry portal
You can view metrics within Azure AI Foundry portal. To view them, follow these steps:
Go to Azure AI Foundry portal.
Navigate to your model deployment by selecting Deployments, and then select the name of the deployment you want to see metrics about.
Select the tab Metrics.
You can access an overview of common metrics that might be of interest. For cost-related metrics, use the Azure Cost Management deep link, which provides access to detailed post-consumption cost metrics in the Cost analysis section located in the Azure portal. Cost data in Azure portal displays actual post-consumption charges for model consumption, including other AI resources within Azure AI Foundry. Follow this link for a full list of AI resources. There's approximately a five hour delay from the billing event to when it can be viewed in Azure portal cost analysis.

Important
The Azure Cost Management deep link provides a direct link within the Azure portal, allowing users to access detailed cost metrics for deployed AI models. This deep link integrates with the Azure Cost Analysis service view, offering transparent and actionable insights into model-level costs. The deep link directs users to the Cost Analysis view in the Azure portal, providing a one-click experience to view deployments per resource, including input/output token cost/consumption. To view cost data, you need at least read access for an Azure account. For information about assigning access to Microsoft Cost Management data, see Assign access to data.
You can view and analyze metrics with Azure Monitor metrics explorer to further slice and filter your model deployment metrics.
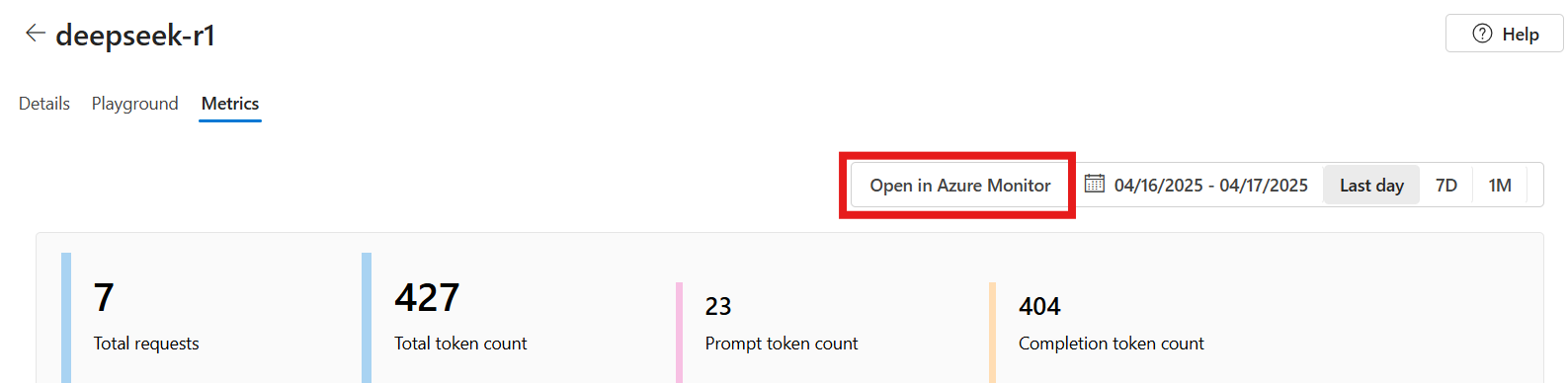
Use Metrics explorer to analyze the metrics.


Metrics explorer
Metrics explorer is a tool in the Azure portal that allows you to view and analyze metrics for Azure resources. For more information, see Analyze metrics with Azure Monitor metrics explorer.
To use Azure Monitor, follow these steps:
Go to Azure portal.
Type and select Monitor on the search box.
Select Metrics in the left navigation bar.
On Select scope, select the resources you want to monitor. You can select either one resource or select a resource group or subscription. If that's the case, ensure you select Resource types as Azure AI Services.
The metric explorer shows. Select the metrics that you want to explore. The following example shows the number of requests made to the model deployments in the resource.
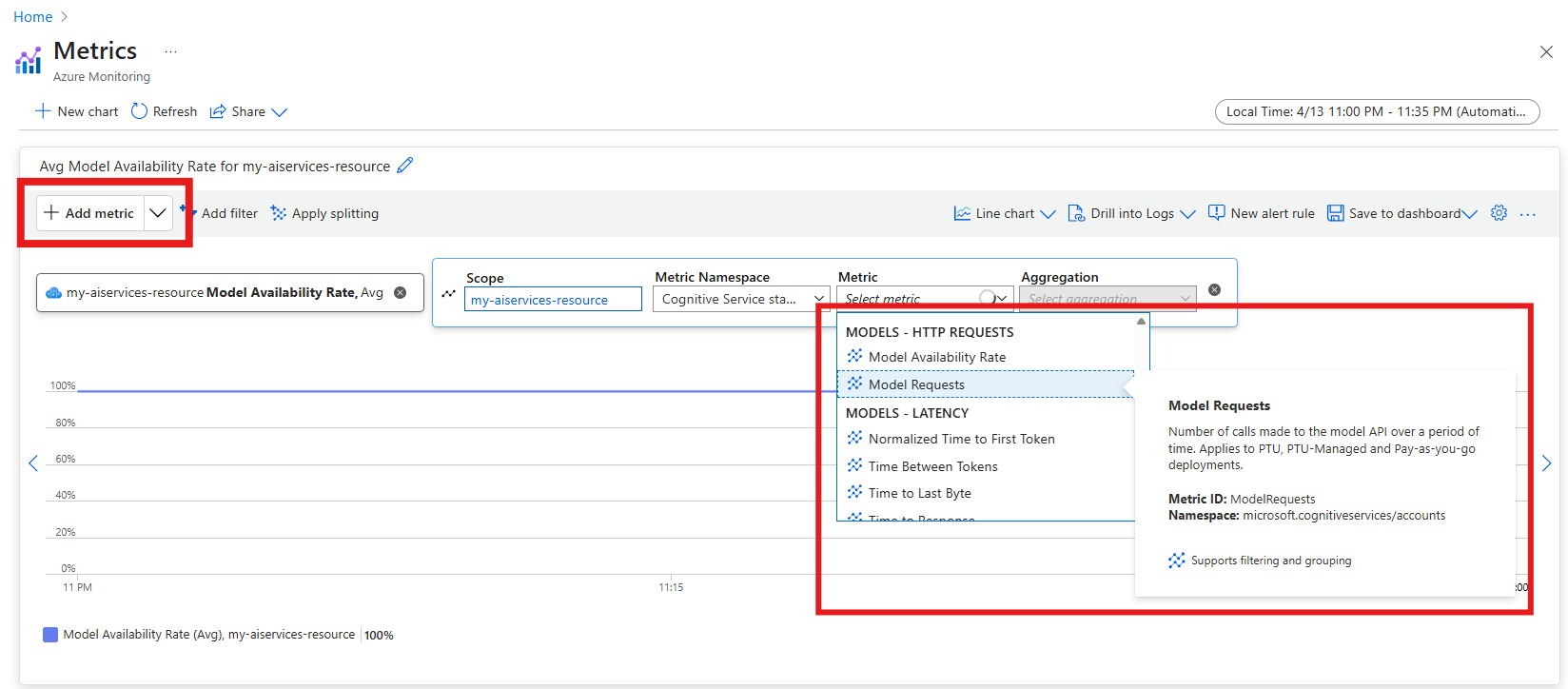
Important
Metrics in category Azure OpenAI contain metrics for Azure OpenAI models in the resource. Category Models contains all the models available in the resource, including Azure OpenAI, DeepSeek, Phi, etc. We recommend switching to this new set of metrics.
You can add as many metrics as needed to either the same chart or to a new chart.
If you need, you can filter metrics by any of the available dimensions of it.

It's useful to break down specific metrics by some of the dimensions. The following example shows how to break down the number of requests made to the resource by model by using the option Add splitting:
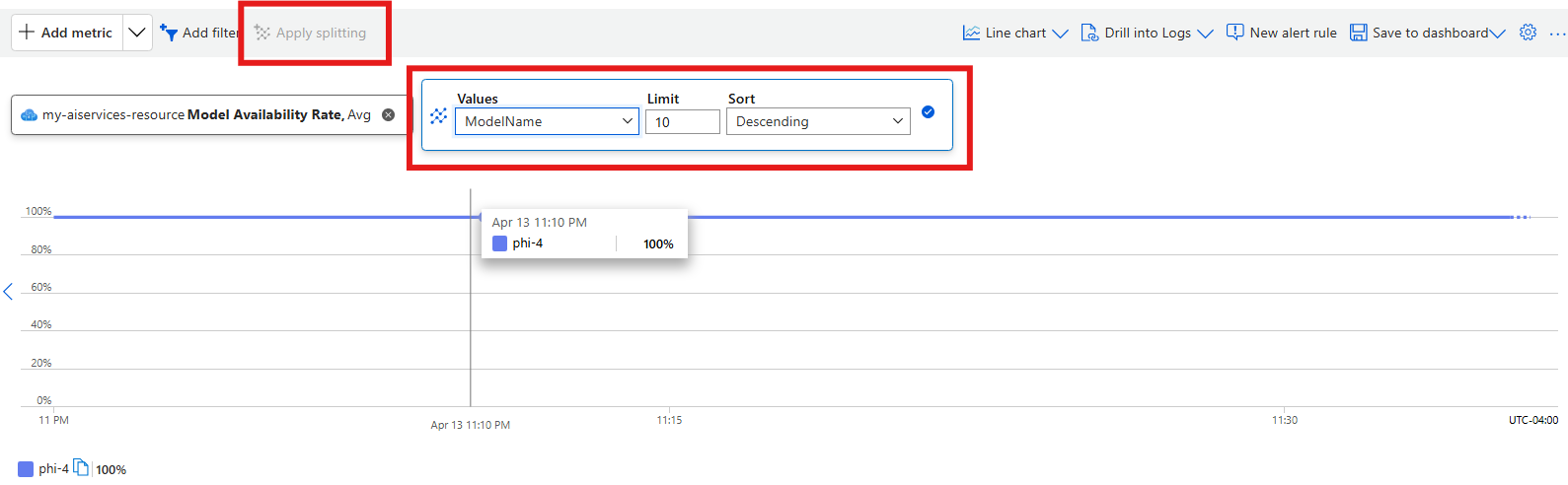
You can save your dashboards at any time to avoid having to configure them each time.



Kusto query language (KQL)
If you configure diagnostic settings to send metrics to Log Analytics, you can use the Azure portal to query and analyze log data by using the Kusto query language (KQL).
To query metrics, follow these steps:
Ensure you have configure diagnostic settings.
Go to Azure portal.
Locate the Azure AI Services resource you want to query.
In the left navigation bar, navigate to Monitoring > Logs.
Select the Log Analytics workspace that you configured with diagnostics.
From the Log Analytics workspace page, under Overview on the left pane, select Logs. The Azure portal displays a Queries window with sample queries and suggestions by default. You can close this window.
To examine the Azure Metrics, use the table
AzureMetricsfor your resource, and run the following query:AzureMetrics | take 100 | project TimeGenerated, MetricName, Total, Count, Maximum, Minimum, Average, TimeGrain, UnitNameNote
When you select Monitoring > Logs in the menu for your resource, Log Analytics opens with the query scope set to the current resource. The visible log queries include data from that specific resource only. To run a query that includes data from other resources or data from other Azure services, select Logs from the Azure Monitor menu in the Azure portal. For more information, see Log query scope and time range in Azure Monitor Log Analytics for details.
Other tools
Tools that allow more complex visualization include:
- Workbooks, customizable reports that you can create in the Azure portal. Workbooks can include text, metrics, and log queries.
- Grafana, an open platform tool that excels in operational dashboards. You can use Grafana to create dashboards that include data from multiple sources other than Azure Monitor.
- Power BI, a business analytics service that provides interactive visualizations across various data sources. You can configure Power BI to automatically import log data from Azure Monitor to take advantage of these visualizations.
Metrics reference
The following categories of metrics are available:
Models - Requests
| Metric | Internal name | Unit | Aggregation | Dimensions |
|---|---|---|---|---|
| Model Availability Rate Availability percentage with the following calculation: (Total Calls - Server Errors)/Total Calls. Server Errors include any HTTP responses >=500. |
ModelAvailabilityRate |
Percent | Minimum, Maximum, Average | ApiName, OperationName, Region, StreamType, ModelDeploymentName, ModelName, ModelVersion |
| Model Requests Number of calls made to the model inference API over a period of time that resulted in a service error (>500). |
ModelRequests |
Count | Total (Sum) | ApiName, OperationName, Region, StreamType, ModelDeploymentName, ModelName, ModelVersion, StatusCode |
Models - Latency
| Metric | Internal name | Unit | Aggregation | Dimensions |
|---|---|---|---|---|
| Time To Response Recommended latency (responsiveness) measure for streaming requests. Applies to PTU and PTU-managed deployments. Calculated as time taken for the first response to appear after a user sends a prompt, as measured by the API gateway. This number increases as the prompt size increases and/or cache hit size reduces. Note: this metric is an approximation as measured latency is heavily dependent on multiple factors, including concurrent calls and overall workload pattern. In addition, it does not account for any client-side latency that may exist between your client and the API endpoint. Refer to your own logging for optimal latency tracking. |
TimeToResponse |
Milliseconds | Maximum, Minimum, Average | ApiName, OperationName, Region, StreamType, ModelDeploymentName, ModelName, ModelVersion, StatusCode |
| Normalized Time Between Tokens For streaming requests; model token generation rate, measured in milliseconds. Applies to PTU and PTU-managed deployments. |
NormalizedTimeBetweenTokens |
Milliseconds | Maximum, Minimum, Average | ApiName, OperationName, Region, StreamType, ModelDeploymentName, ModelName, ModelVersion |
Models - Usage
| Metric | Internal name | Unit | Aggregation | Dimensions |
|---|---|---|---|---|
| Input Tokens Number of prompt tokens processed (input) on a model. Applies to PTU, PTU-managed and standard deployments. |
InputTokens |
Count | Total (Sum) | ApiName, Region, ModelDeploymentName, ModelName, ModelVersion |
| Output Tokens Number of tokens generated (output) from a model. Applies to PTU, PTU-managed and standard deployments. |
OutputTokens |
Count | Total (Sum) | ApiName, Region, ModelDeploymentName, ModelName, ModelVersion |
| Total Tokens Number of inference tokens processed on a model. Calculated as prompt tokens (input) plus generated tokens (output). Applies to PTU, PTU-managed and standard deployments. |
TotalTokens |
Count | Total (Sum) | ApiName, Region, ModelDeploymentName, ModelName, ModelVersion |
| Tokens Cache Match Rate Percentage of prompt tokens that hit the cache. Applies to PTU and PTU-managed deployments. |
TokensCacheMatchRate |
Percentage | Average | Region, ModelDeploymentName, ModelName, ModelVersion |
| Provisioned Utilization Utilization % for a provisoned-managed deployment, calculated as (PTUs consumed / PTUs deployed) x 100. When utilization is greater than or equal to 100%, calls are throttled and error code 429 returned. |
TokensCacheMatchRate |
Percentage | Average | Region, ModelDeploymentName, ModelName, ModelVersion |
| Provisioned Consumed Tokens Total tokens minus cached tokens over a period of time. Applies to PTU and PTU-managed deployments. |
ProvisionedConsumedTokens |
Count | Total (Sum) | Region, ModelDeploymentName, ModelName, ModelVersion |
| Audio Input Tokens Number of audio prompt tokens processed (input) on a model. Applies to PTU-managed model deployments. |
AudioInputTokens |
Count | Total (Sum) | Region, ModelDeploymentName, ModelName, ModelVersion |
| Audio Output Tokens Number of audio prompt tokens generated (output) on a model. Applies to PTU-managed model deployments. |
AudioOutputTokens |
Count | Total (Sum) | Region, ModelDeploymentName, ModelName, ModelVersion |
Logs
Resource logs provide insight into operations that were done by an Azure resource. Logs are generated automatically, but you must route them to Azure Monitor logs to save or query by configuring a diagnostic setting. Logs are organized in categories when you create a diagnostic setting, you specify which categories of logs to collect.
Configure diagnostic settings
All of the metrics are exportable with diagnostic settings in Azure Monitor. To analyze logs and metrics data with Azure Monitor Log Analytics queries, you need to configure diagnostic settings for your Azure AI Services resource. You need to perform this operation on each resource.
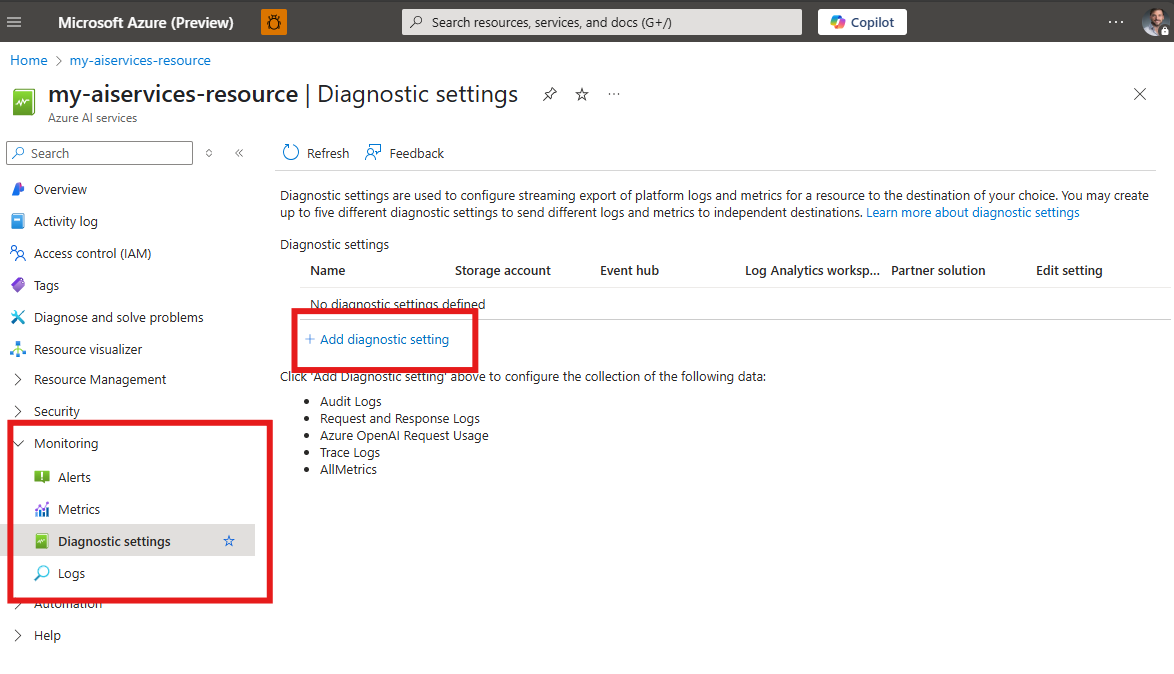
There's a cost for collecting data in a Log Analytics workspace, so only collect the categories you require for each service. The data volume for resource logs varies significantly between services.