Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Spillover manages traffic fluctuations on provisioned deployments by routing overage traffic to a corresponding standard deployment. Spillover is an optional capability that can be set for all requests on a given deployment or can be managed on a per-request basis. When spillover is enabled, Azure OpenAI in Azure AI Foundry Models sends any overage traffic from your provisioned deployment to a standard deployment for processing.
Note
Spillover is currently not available for the responses API.
Prerequisites
You need to have a provisioned managed deployment and a standard deployment.
The provisioned and standard deployments must be in the same Azure OpenAI resource to be eligible for spillover.
The data processing level of your standard deployment must match your provisioned deployment (for example, a global provisioned deployment must be used with a global standard spillover deployment).
When to enable spillover on provisioned deployments
To maximize the utilization of your provisioned deployment, you can enable spillover for all global and data zone provisioned deployments. With spillover, bursts or fluctuations in traffic can be automatically managed by the service. This capability reduces the risk of experiencing disruptions when a provisioned deployment is fully utilized. Alternatively, spillover is configurable per-request to provide flexibility across different scenarios and workloads. Spillover can also now be used for the Azure AI Foundry Agent Service.
When does spillover come into effect?
When you enable spillover for a deployment or configure it for a given inference request, spillover initiates when a specific non-200 response code is received for a given inference request as a result of one of these scenarios:
Provisioned throughput units (PTU) are completely used, resulting in a
429response code.You send a long context token request, resulting in a
400error code. For example, when usinggpt 4.1series models, PTU supports only context lengths less than 128k and returns HTTP 400.Server errors when processing your request, resulting in error code
500or503.
When a request results in one of these non-200 response codes, Azure OpenAI automatically sends the request from your provisioned deployment to your standard deployment to be processed.
Note
Even if a subset of requests is routed to the standard deployment, the service prioritizes sending requests to the provisioned deployment before sending any overage requests to the standard deployment, which might incur additional latency.
How to know a request spilled over
The following HTTP response headers indicate that a specific request spilled over:
x-ms-spillover-from-<deployment-name>. This header contains the PTU deployment name. The presence of this header indicates that the request was a spillover request.x-ms-<deployment-name>. This header contains the name of the deployment that served the request. If the request spilled over, the deployment name is the name of the standard deployment.
For a request that spilled over, if the standard deployment request failed for any reason, the original PTU response is used in the response to the customer. The customer sees a header x-ms-spillover-error that contains the response code of the spillover request (such as 429 or 500) so that they know the reason for the failed spillover.
How does spillover affect cost?
Since spillover uses a combination of provisioned and standard deployments to manage traffic fluctuations, billing for spillover involves two components:
For any requests processed by your provisioned deployment, only the hourly provisioned deployment cost applies. No additional costs are incurred for these requests.
For any requests routed to your standard deployment, the request is billed at the associated input token, cached token, and output token rates for the specified model version and deployment type.
Enable spillover for all requests on a provisioned deployment
To deploy a model with the spillover capability, navigate to the Azure AI Foundry. On the left navigation menu, then select Deployments.
Select Deploy model. In the menu that appears, select Customize.

Specify one the provisioned options as the Deployment type, for example Global Provisioned Throughput. Select Traffic spillover to enable spillover for your provisioned deployment.
Tip
- To enable spillover, your account must have at least one active pay-as-you-go deployment that matches the model and version of your current provisioned deployment.
- To see how to enable spillover for select inference requests, click the REST API tab above.

How do I monitor my spillover usage?
Since the spillover capability relies on a combination of provisioned and standard deployments to manage traffic overages, monitoring can be conducted at the deployment level for each deployment. To view how many requests were processed on the primary provisioned deployment versus the spillover standard deployment, apply the splitting feature within Azure Monitor metrics to view the requests processed by each deployment and their respective status codes. Similarly, the splitting feature can be used to view how many tokens were processed on the primary provisioned deployment versus the spillover standard deployment for a given time period. For more information on observability within Azure OpenAI, review the Monitor Azure OpenAI documentation.
Monitor metrics in the Azure portal
The following Azure Monitor metrics chart provides an example of the split of requests between the primary provisioned deployment and the spillover standard deployment when spillover is initiated. To create a chart, navigate to your resource in the Azure portal.
Select Monitoring > metrics from the left navigation menu.
Add the
Azure OpenAI Requestsrequests metric.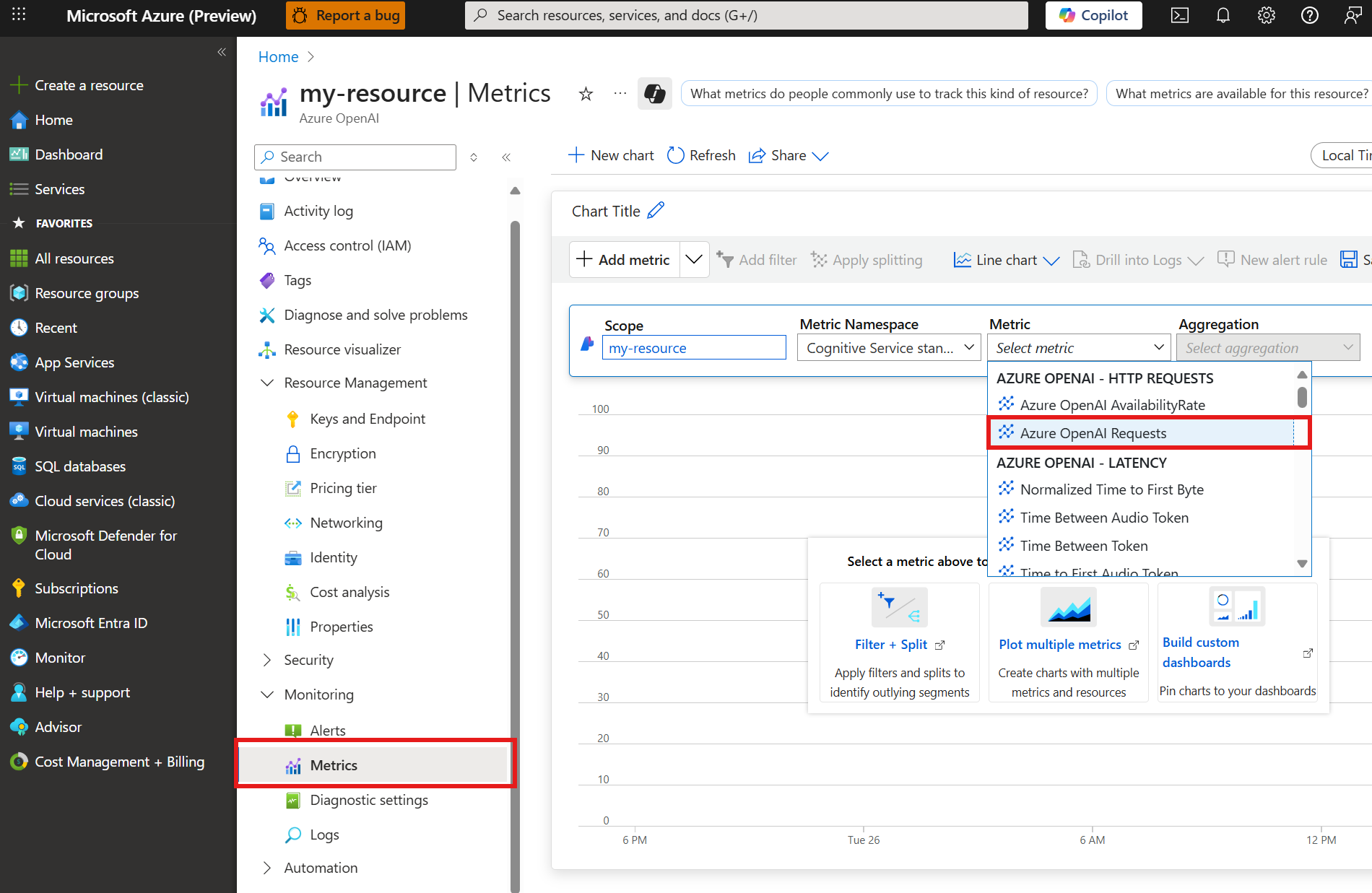
Select Apply splitting and apply the
ModelDeploymentNamesplit andStatusCodesplits to theAzure OpenAI Requestsmetric. This will show you a chart with the200(success) and429(too many requests) response codes that are generated for your resource.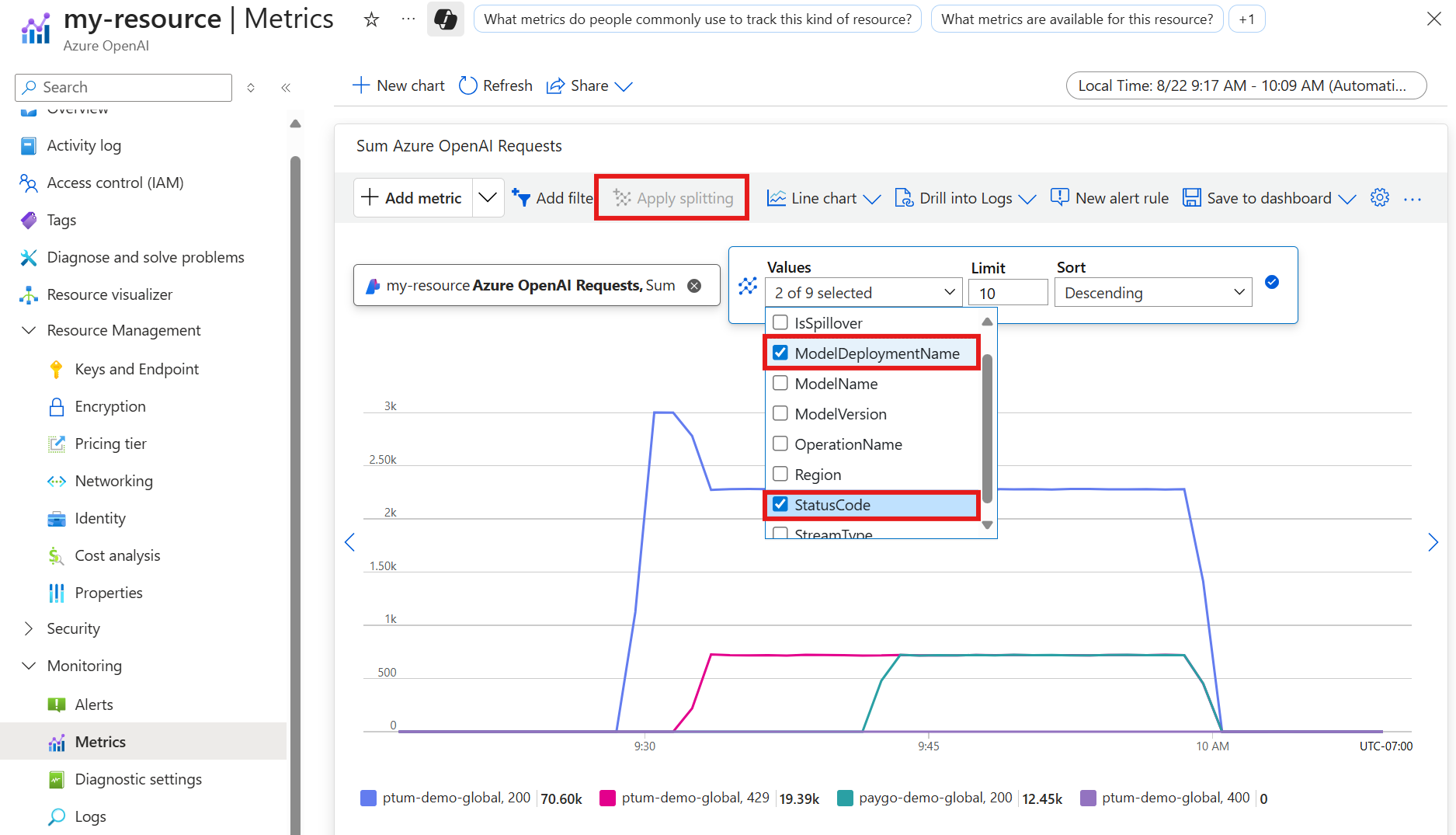
Be sure to add the model deployments you want to view when applying the
ModelDeploymentNamesplit.
The following example shows an instance where a spike in requests sent to the provisioned throughput deployment generates
429error codes. Shortly after, spillover occurs and requests begin to be sent to the pay-as-you-go deployment being used for spillover, generating200responses for that deployment.
Note
As requests are sent to the pay-as-you-go deployment, they still will generate 429 response codes on the provisioned deployment before being redirected.






Viewing spillover metrics
Applying the IsSpillover split lets you view the requests to your deployment that are being redirected to your spillover deployment. Following from the previous example, you can see how the 429 responses from the primary deployment match the 200 response codes generated by the spillover deployment.
