Once your model is fine-tuned, you can deploy the model and can use it in your own application.
When you deploy the model, you make the model available for inferencing, and that incurs an hourly hosting charge. Fine-tuned models, however, can be stored in Azure AI Foundry at no cost until you're ready to use them.
Azure OpenAI provides choices of deployment types for fine-tuned models on the hosting structure that fits different business and usage patterns: Standard, Global Standard (preview) and Provisioned Managed (preview). Learn more about deployment types for fine-tuned models and the concepts of all deployment types.
Deploy your fine-tuned model
To deploy your custom model, select the custom model to deploy, and then select Deploy.
The Deploy model dialog box opens. In the dialog box, enter your Deployment name and then select Create to start the deployment of your custom model.
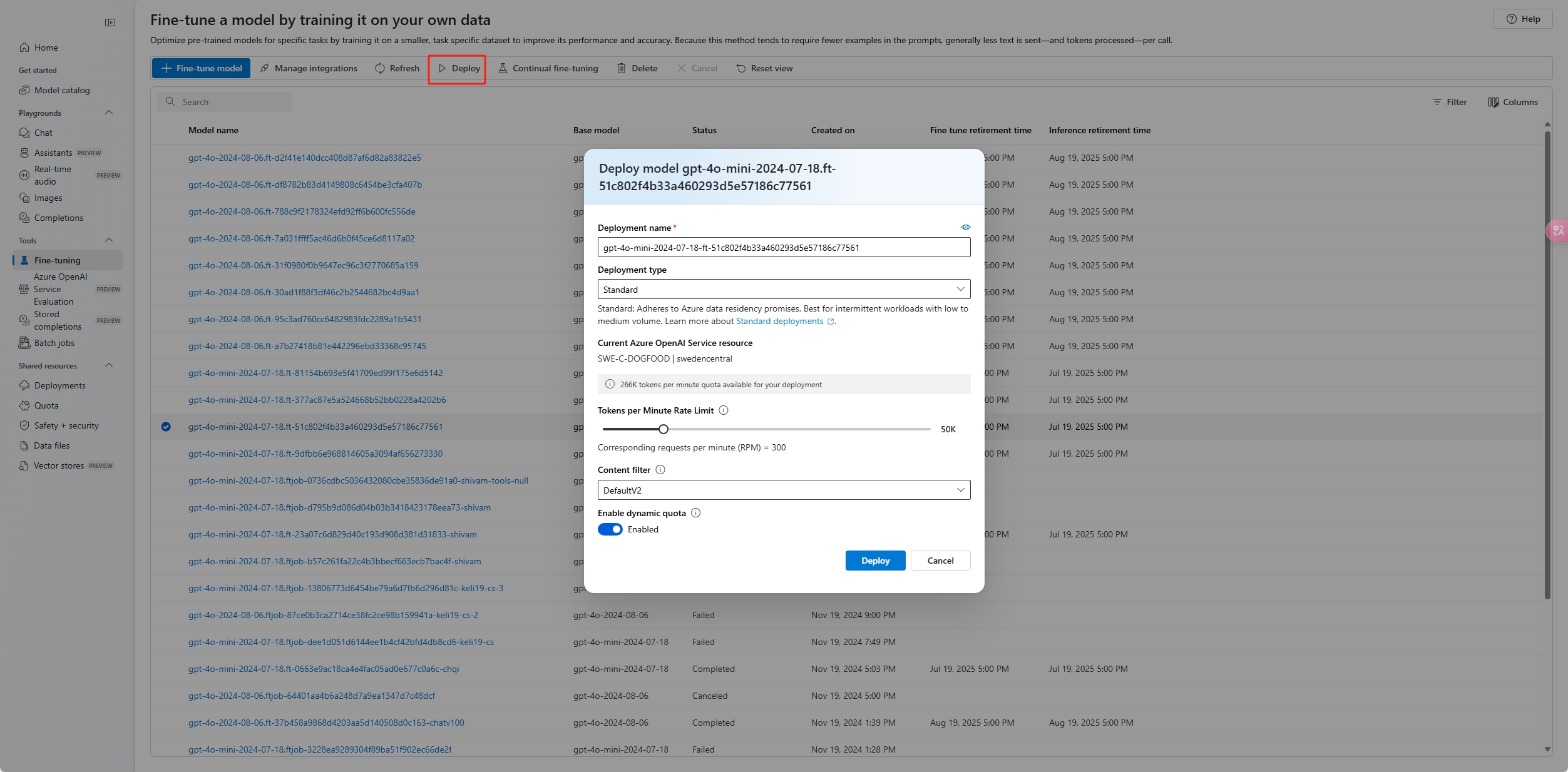
You can monitor the progress of your deployment on the Deployments pane in Azure AI Foundry portal.
The UI does not support cross region deployment, while Python SDK or REST supports.
import json
import os
import requests
token = os.getenv("<TOKEN>")
subscription = "<YOUR_SUBSCRIPTION_ID>"
resource_group = "<YOUR_RESOURCE_GROUP_NAME>"
resource_name = "<YOUR_AZURE_OPENAI_RESOURCE_NAME>"
model_deployment_name = "gpt-35-turbo-ft" # custom deployment name that you will use to reference the model when making inference calls.
deploy_params = {'api-version': "2024-10-21"}
deploy_headers = {'Authorization': 'Bearer {}'.format(token), 'Content-Type': 'application/json'}
deploy_data = {
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": <"fine_tuned_model">, #retrieve this value from the previous call, it will look like gpt-35-turbo-0125.ft-b044a9d3cf9c4228b5d393567f693b83
"version": "1"
}
}
}
deploy_data = json.dumps(deploy_data)
request_url = f'https://management.azure.com/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.CognitiveServices/accounts/{resource_name}/deployments/{model_deployment_name}'
print('Creating a new deployment...')
r = requests.put(request_url, params=deploy_params, headers=deploy_headers, data=deploy_data)
print(r)
print(r.reason)
print(r.json())
| variable |
Definition |
| token |
There are multiple ways to generate an authorization token. The easiest method for initial testing is to launch the Cloud Shell from the Azure portal. Then run az account get-access-token. You can use this token as your temporary authorization token for API testing. We recommend storing this in a new environment variable. |
| subscription |
The subscription ID for the associated Azure OpenAI resource. |
| resource_group |
The resource group name for your Azure OpenAI resource. |
| resource_name |
The Azure OpenAI resource name. |
| model_deployment_name |
The custom name for your new fine-tuned model deployment. This is the name that will be referenced in your code when making chat completion calls. |
| fine_tuned_model |
Retrieve this value from your fine-tuning job results in the previous step. It will look like gpt-35-turbo-0125.ft-b044a9d3cf9c4228b5d393567f693b83. You will need to add that value to the deploy_data json. Alternatively you can also deploy a checkpoint, by passing the checkpoint ID which will appear in the format ftchkpt-e559c011ecc04fc68eaa339d8227d02d |
Cross region deployment
Fine-tuning supports deploying a fine-tuned model to a different region than where the model was originally fine-tuned. You can also deploy to a different subscription/region.
The only limitations are that the new region must also support fine-tuning and when deploying cross subscription the account generating the authorization token for the deployment must have access to both the source and destination subscriptions.
Below is an example of deploying a model that was fine-tuned in one subscription/region to another.
import json
import os
import requests
token= os.getenv("<TOKEN>")
subscription = "<DESTINATION_SUBSCRIPTION_ID>"
resource_group = "<DESTINATION_RESOURCE_GROUP_NAME>"
resource_name = "<DESTINATION_AZURE_OPENAI_RESOURCE_NAME>"
source_subscription = "<SOURCE_SUBSCRIPTION_ID>"
source_resource_group = "<SOURCE_RESOURCE_GROUP>"
source_resource = "<SOURCE_RESOURCE>"
source = f'/subscriptions/{source_subscription}/resourceGroups/{source_resource_group}/providers/Microsoft.CognitiveServices/accounts/{source_resource}'
model_deployment_name = "gpt-35-turbo-ft" # custom deployment name that you will use to reference the model when making inference calls.
deploy_params = {'api-version': "2024-10-21"}
deploy_headers = {'Authorization': 'Bearer {}'.format(token), 'Content-Type': 'application/json'}
deploy_data = {
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": <"FINE_TUNED_MODEL_NAME">, # This value will look like gpt-35-turbo-0125.ft-0ab3f80e4f2242929258fff45b56a9ce
"version": "1",
"source": source
}
}
}
deploy_data = json.dumps(deploy_data)
request_url = f'https://management.azure.com/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.CognitiveServices/accounts/{resource_name}/deployments/{model_deployment_name}'
print('Creating a new deployment...')
r = requests.put(request_url, params=deploy_params, headers=deploy_headers, data=deploy_data)
print(r)
print(r.reason)
print(r.json())
To deploy between the same subscription, but different regions you would just have subscription and resource groups be identical for both source and destination variables and only the source and destination resource names would need to be unique.
Cross tenant deployment
The account used to generate access tokens with az account get-access-token --tenant should have Cognitive Services OpenAI Contributor permissions to both the source and destination Azure OpenAI resources. You will need to generate two different tokens, one for the source tenant and one for the destination tenant.
import requests
subscription = "DESTINATION-SUBSCRIPTION-ID"
resource_group = "DESTINATION-RESOURCE-GROUP"
resource_name = "DESTINATION-AZURE-OPENAI-RESOURCE-NAME"
model_deployment_name = "DESTINATION-MODEL-DEPLOYMENT-NAME"
fine_tuned_model = "gpt-4o-mini-2024-07-18.ft-f8838e7c6d4a4cbe882a002815758510" #source fine-tuned model id example id provided
source_subscription_id = "SOURCE-SUBSCRIPTION-ID"
source_resource_group = "SOURCE-RESOURCE-GROUP"
source_account = "SOURCE-AZURE-OPENAI-RESOURCE-NAME"
dest_token = "DESTINATION-ACCESS-TOKEN" # az account get-access-token --tenant DESTINATION-TENANT-ID
source_token = "SOURCE-ACCESS-TOKEN" # az account get-access-token --tenant SOURCE-TENANT-ID
headers = {
"Authorization": f"Bearer {dest_token}",
"x-ms-authorization-auxiliary": f"Bearer {source_token}",
"Content-Type": "application/json"
}
url = f"https://management.azure.com/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.CognitiveServices/accounts/{resource_name}/deployments/{model_deployment_name}?api-version=2024-10-01"
payload = {
"sku": {
"name": "standard",
"capacity": 1
},
"properties": {
"model": {
"format": "OpenAI",
"name": fine_tuned_model,
"version": "1",
"sourceAccount": f"/subscriptions/{source_subscription_id}/resourceGroups/{source_resource_group}/providers/Microsoft.CognitiveServices/accounts/{source_account}"
}
}
}
response = requests.put(url, headers=headers, json=payload)
# Check response
print(f"Status Code: {response.status_code}")
print(f"Response: {response.json()}")
The following example shows how to use the REST API to create a model deployment for your customized model. The REST API generates a name for the deployment of your customized model.
curl -X POST "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>api-version=2024-10-21" \
-H "Authorization: Bearer <TOKEN>" \
-H "Content-Type: application/json" \
-d '{
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": "<FINE_TUNED_MODEL>",
"version": "1"
}
}
}'
| variable |
Definition |
| token |
There are multiple ways to generate an authorization token. The easiest method for initial testing is to launch the Cloud Shell from the Azure portal. Then run az account get-access-token. You can use this token as your temporary authorization token for API testing. We recommend storing this in a new environment variable. |
| subscription |
The subscription ID for the associated Azure OpenAI resource. |
| resource_group |
The resource group name for your Azure OpenAI resource. |
| resource_name |
The Azure OpenAI resource name. |
| model_deployment_name |
The custom name for your new fine-tuned model deployment. This is the name that will be referenced in your code when making chat completion calls. |
| fine_tuned_model |
Retrieve this value from your fine-tuning job results in the previous step. It will look like gpt-35-turbo-0125.ft-b044a9d3cf9c4228b5d393567f693b83. You'll need to add that value to the deploy_data json. Alternatively you can also deploy a checkpoint, by passing the checkpoint ID which will appear in the format ftchkpt-e559c011ecc04fc68eaa339d8227d02d |
Cross region deployment
Fine-tuning supports deploying a fine-tuned model to a different region than where the model was originally fine-tuned. You can also deploy to a different subscription/region.
The only limitations are that the new region must also support fine-tuning and when deploying cross subscription the account generating the authorization token for the deployment must have access to both the source and destination subscriptions.
Below is an example of deploying a model that was fine-tuned in one subscription/region to another.
curl -X PUT "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>api-version=2024-10-21" \
-H "Authorization: Bearer <TOKEN>" \
-H "Content-Type: application/json" \
-d '{
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": "<FINE_TUNED_MODEL>",
"version": "1",
"source": "/subscriptions/{sourceSubscriptionID}/resourceGroups/{sourceResourceGroupName}/providers/Microsoft.CognitiveServices/accounts/{sourceAccount}"
}
}
}'
To deploy between the same subscription, but different regions, you would just have subscription and resource groups be identical for both source and destination variables and only the source and destination resource names would need to be unique.
Cross tenant deployment
The account used to generate access tokens with az account get-access-token --tenant should have Cognitive Services OpenAI Contributor permissions to both the source and destination Azure OpenAI resources. You will need to generate two different tokens, one for the source tenant and one for the destination tenant.
curl -X PUT "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>?api-version=2024-10-01" \
-H "Authorization: Bearer <DESTINATION TOKEN>" \
-H "x-ms-authorization-auxiliary: Bearer <SOURCE TOKEN>" \
-H "Content-Type: application/json" \
-d '{
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": "<FINE_TUNED_MODEL>",
"version": "1",
"sourceAccount": "/subscriptions/{sourceSubscriptionID}/resourceGroups/{sourceResourceGroupName}/providers/Microsoft.CognitiveServices/accounts/{sourceAccount}"
}
}
}'
Deploy a model with Azure CLI
The following example shows how to use the Azure CLI to deploy your customized model. With the Azure CLI, you must specify a name for the deployment of your customized model. For more information about how to use the Azure CLI to deploy customized models, see az cognitiveservices account deployment.
To run this Azure CLI command in a console window, you must replace the following <placeholders> with the corresponding values for your customized model:
| Placeholder |
Value |
| <YOUR_AZURE_SUBSCRIPTION> |
The name or ID of your Azure subscription. |
| <YOUR_RESOURCE_GROUP> |
The name of your Azure resource group. |
| <YOUR_RESOURCE_NAME> |
The name of your Azure OpenAI resource. |
| <YOUR_DEPLOYMENT_NAME> |
The name you want to use for your model deployment. |
| <YOUR_FINE_TUNED_MODEL_ID> |
The name of your customized model. |
az cognitiveservices account deployment create
--resource-group <YOUR_RESOURCE_GROUP>
--name <YOUR_RESOURCE_NAME>
--deployment-name <YOUR_DEPLOYMENT_NAME>
--model-name <YOUR_FINE_TUNED_MODEL_ID>
--model-version "1"
--model-format OpenAI
--sku-capacity "1"
--sku-name "Standard"
Important
After you deploy a customized model, if at any time the deployment remains inactive for greater than fifteen (15) days,
the deployment is deleted. The deployment of a customized model is inactive if the model was deployed more than fifteen (15) days ago
and no completions or chat completions calls were made to it during a continuous 15-day period.
The deletion of an inactive deployment doesn't delete or affect the underlying customized model,
and the customized model can be redeployed at any time.
As described in Azure OpenAI in Azure AI Foundry Models pricing,
each customized (fine-tuned) model that's deployed incurs an hourly hosting cost regardless of whether completions
or chat completions calls are being made to the model. To learn more about planning and managing costs with Azure OpenAI,
refer to the guidance in Plan to manage costs for Azure OpenAI.
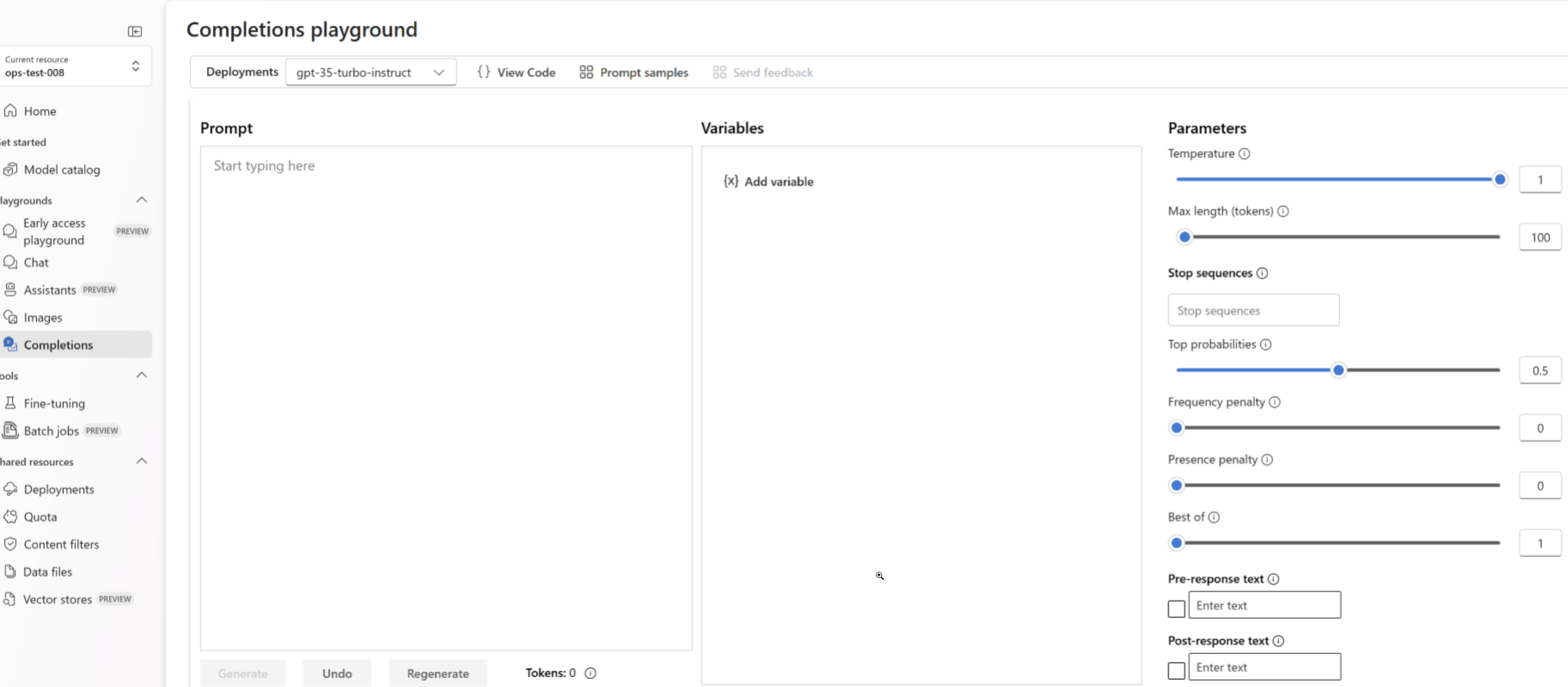
Use your deployed fine-tuned model
After your custom model deploys, you can use it like any other deployed model. You can use the Playgrounds in the Azure AI Foundry portal to experiment with your new deployment. You can continue to use the same parameters with your custom model, such as temperature and max_tokens, as you can with other deployed models.
import os
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-02-01"
)
response = client.chat.completions.create(
model="gpt-35-turbo-ft", # model = "Custom deployment name you chose for your fine-tuning model"
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Does Azure OpenAI support customer managed keys?"},
{"role": "assistant", "content": "Yes, customer managed keys are supported by Azure OpenAI."},
{"role": "user", "content": "Do other Azure services support this too?"}
]
)
print(response.choices[0].message.content)
curl $AZURE_OPENAI_ENDPOINT/openai/deployments/<deployment_name>/chat/completions?api-version=2024-10-21 \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{"messages":[{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "Does Azure OpenAI support customer managed keys?"},{"role": "assistant", "content": "Yes, customer managed keys are supported by Azure OpenAI."},{"role": "user", "content": "Do other Azure services support this too?"}]}'
Prompt caching
Azure OpenAI fine-tuning supports prompt caching with select models. Prompt caching allows you to reduce overall request latency and cost for longer prompts that have identical content at the beginning of the prompt. To learn more about prompt caching, see getting started with prompt caching.
Deployment Types
Azure OpenAI fine-tuning supports the following deployment types.
Standard
Standard deployments provides a pay-per-call billing model, and the model available in each region as well as throughput may be limited.
| Models |
Region |
| GPT-4o-finetune |
East US2, North Central US, Sweden Central |
| gpt-4o-mini-2024-07-18 |
North Central US, Sweden Central |
| GPT-4-finetune |
North Central US, Sweden Central |
| GPT-35-Turbo-finetune |
East US2, North Central US, Sweden Central, Switzerland West |
| GPT-35-Turbo-1106-finetune |
East US2, North Central US, Sweden Central, Switzerland West |
| GPT-35-Turbo-0125-finetune |
East US2, North Central US, Sweden Central, Switzerland West |
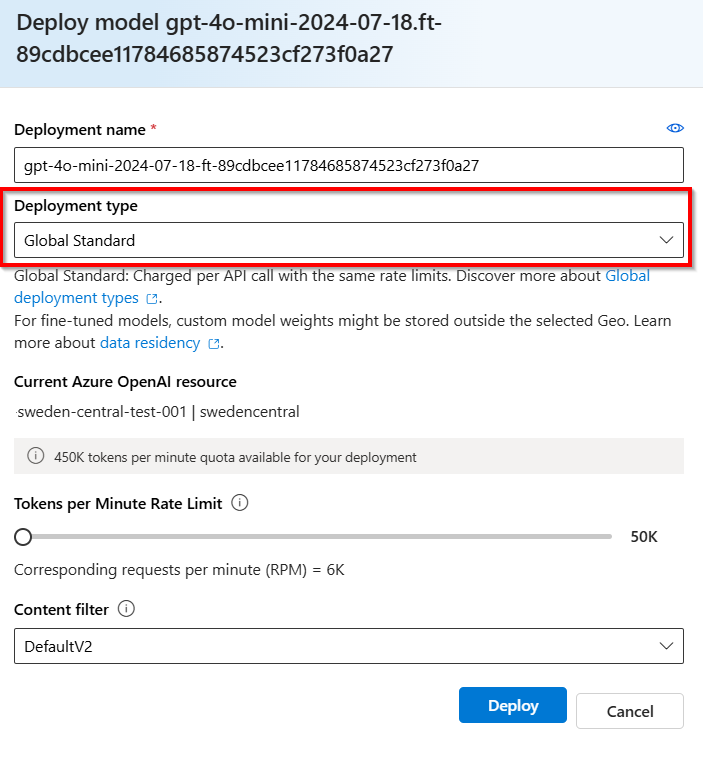
Global Standard
Global standard fine-tuned deployments offer cost savings, but custom model weights may temporarily be stored outside the geography of your Azure OpenAI resource.
| Models |
Region |
| GPT-4.1-finetune |
East US2, North Central US, and Sweden Central |
| GPT-4.1-mini-finetune |
East US2, North Central US, and Sweden Central |
| GPT-4.1-nano-finetune |
East US2, North Central US, and Sweden Central |
| GPT-4o-finetune |
East US2, North Central US, and Sweden Central |
| GPT-4o-mini-finetune |
East US2, North Central US, and Sweden Central |
Provisioned Managed
| Models |
Region |
| GPT-4o-finetune |
North Central US, Sweden Central |
| GPT-4o-mini-finetune |
North Central US, Sweden Central |
Provisioned managed fine-tuned deployments offer predictable performance for latency-sensitive agents and applications. They use the same regional provisioned throughput (PTU) capacity as base models, so if you already have regional PTU quota you can deploy your fine-tuned model in support regions.
Clean up your deployment
To delete a deployment, use the Deployments - Delete REST API and send an HTTP DELETE to the deployment resource. Like with creating deployments, you must include the following parameters:
- Azure subscription ID
- Azure resource group name
- Azure OpenAI resource name
- Name of the deployment to delete
Below is the REST API example to delete a deployment:
curl -X DELETE "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>api-version=2024-10-21" \
-H "Authorization: Bearer <TOKEN>"
You can also delete a deployment in Azure AI Foundry portal, or use Azure CLI.
Next steps


