Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
In this article, you learn how to use voice live with generative AI and Azure AI Speech in the Azure AI Foundry portal.
You create and run an application to use voice live directly with generative AI models for real-time voice agents.
Using models directly allows specifying custom instructions (prompts) for each session, offering more flexibility for dynamic or experimental use cases.
Models may be preferable when you want fine-grained control over session parameters or need to frequently adjust the prompt or configuration without updating an agent in the portal.
The code for model-based sessions is simpler in some respects, as it does not require managing agent IDs or agent-specific setup.
Direct model use is suitable for scenarios where agent-level abstraction or built-in logic is unnecessary.
To instead use the Voice live API with agents, see the Voice live API agents quickstart.
Prerequisites
- An Azure subscription. Create one for free.
- An Azure AI Foundry resource created in one of the supported regions. For more information about region availability, see the voice live overview documentation.
Tip
To use voice live, you don't need to deploy an audio model with your Azure AI Foundry resource. Voice live is fully managed, and the model is automatically deployed for you. For more information about models availability, see the voice live overview documentation.
Try out voice live in the Speech playground
To try out the voice live demo, follow these steps:
Go to your project in Azure AI Foundry.
Select Playgrounds from the left pane.
In the Speech playground tile, select Try the Speech playground.
Select Speech capabilities by scenario > Voice live.

Select a sample scenario, such as Casual chat.
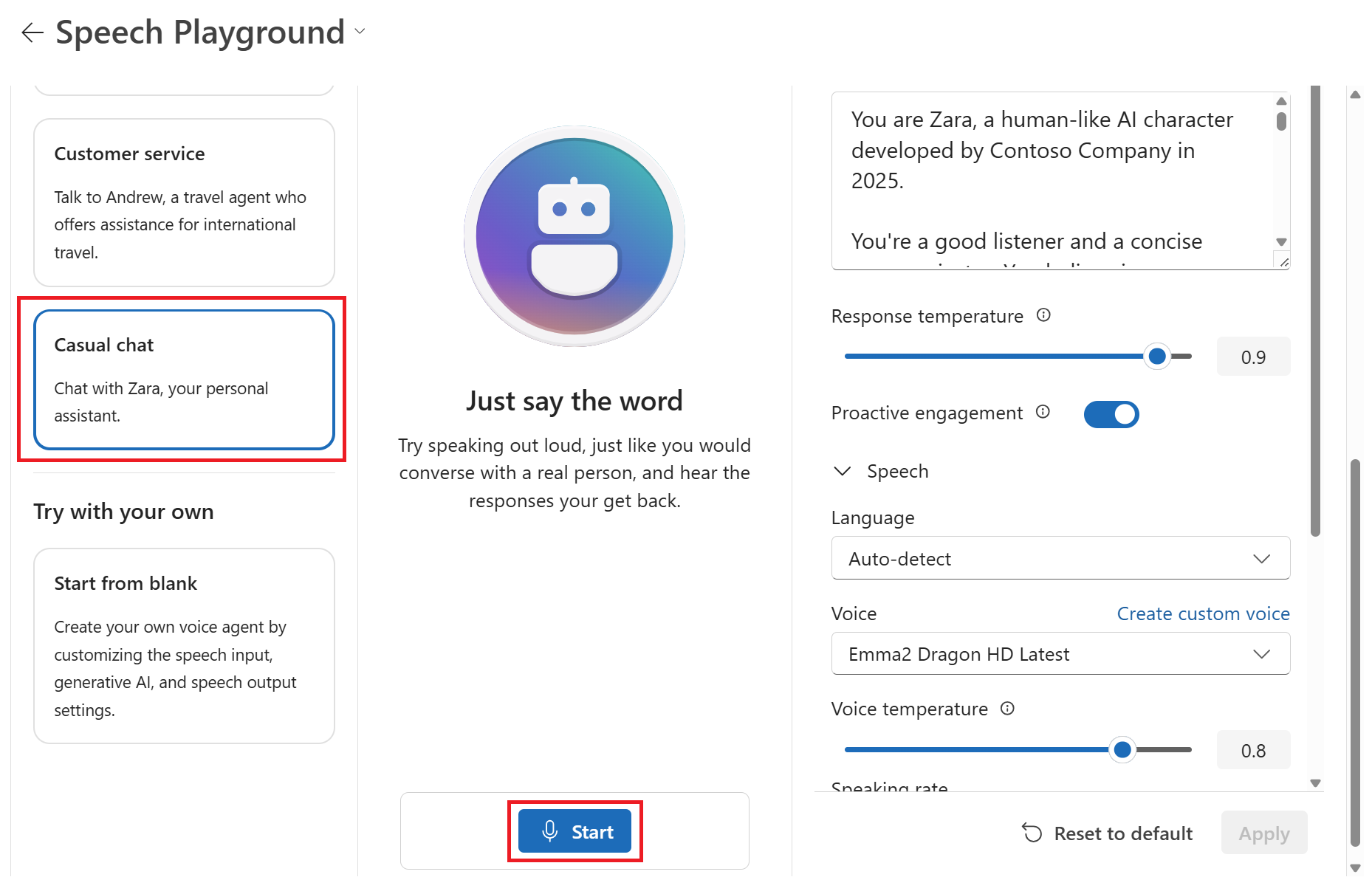
Select Start to start chatting with the chat agent.
Select End to end the chat session.
Select a new generative AI model from the drop-down list via Configuration > GenAI > Generative AI model.
Note
You can also select an agent that you configured in the Agents playground. For more information, see the voice live with Foundry agents quickstart.

Edit other settings as needed, such as the Response instructions, Voice, and Speaking rate.
Select Start to start speaking again and select End to end the chat session.



In this article, you learn how to use Azure AI Speech voice live with Azure AI Foundry models using the VoiceLive SDK for Python.
Reference documentation | Package (PyPi) | Additional samples on GitHub
You create and run an application to use voice live directly with generative AI models for real-time voice agents.
Using models directly allows specifying custom instructions (prompts) for each session, offering more flexibility for dynamic or experimental use cases.
Models may be preferable when you want fine-grained control over session parameters or need to frequently adjust the prompt or configuration without updating an agent in the portal.
The code for model-based sessions is simpler in some respects, as it does not require managing agent IDs or agent-specific setup.
Direct model use is suitable for scenarios where agent-level abstraction or built-in logic is unnecessary.
To instead use the Voice live API with agents, see the Voice live API agents quickstart.
Prerequisites
- An Azure subscription. Create one for free.
- Python 3.10 or later version. If you don't have a suitable version of Python installed, you can follow the instructions in the VS Code Python Tutorial for the easiest way of installing Python on your operating system.
- An Azure AI Foundry resource created in one of the supported regions. For more information about region availability, see Region support.
Tip
To use voice live, you don't need to deploy an audio model with your Azure AI Foundry resource. Voice live is fully managed, and the model is automatically deployed for you. For more information about models availability, see the voice live overview documentation.
Microsoft Entra ID prerequisites
For the recommended keyless authentication with Microsoft Entra ID, you need to:
- Install the Azure CLI used for keyless authentication with Microsoft Entra ID.
- Assign the
Cognitive Services Userrole to your user account. You can assign roles in the Azure portal under Access control (IAM) > Add role assignment.
Set up
Create a new folder
voice-live-quickstartand go to the quickstart folder with the following command:mkdir voice-live-quickstart && cd voice-live-quickstartCreate a virtual environment. If you already have Python 3.10 or higher installed, you can create a virtual environment using the following commands:
Activating the Python environment means that when you run
pythonorpipfrom the command line, you then use the Python interpreter contained in the.venvfolder of your application. You can use thedeactivatecommand to exit the python virtual environment, and can later reactivate it when needed.Tip
We recommend that you create and activate a new Python environment to use to install the packages you need for this tutorial. Don't install packages into your global python installation. You should always use a virtual or conda environment when installing python packages, otherwise you can break your global installation of Python.
Create a file named requirements.txt. Add the following packages to the file:
azure-ai-voicelive[aiohttp] pyaudio python-dotenv azure-identityInstall the packages:
pip install -r requirements.txt
Retrieve resource information
Create a new file named .env in the folder where you want to run the code.
In the .env file, add the following environment variables for authentication:
AZURE_VOICELIVE_ENDPOINT=<your_endpoint>
AZURE_VOICELIVE_MODEL=<your_model>
AZURE_VOICELIVE_API_VERSION=2025-10-01
AZURE_VOICELIVE_API_KEY=<your_api_key> # Only required if using API key authentication
Replace the default values with your actual endpoint, model, API version, and API key.
| Variable name | Value |
|---|---|
AZURE_VOICELIVE_ENDPOINT |
This value can be found in the Keys and Endpoint section when examining your resource from the Azure portal. |
AZURE_VOICELIVE_MODEL |
The model you want to use. For example, gpt-4o or gpt-realtime-mini. For more information about models availability, see the Voice Live API overview documentation. |
AZURE_VOICELIVE_API_VERSION |
The API version you want to use. For example, 2025-10-01. |
Learn more about keyless authentication and setting environment variables.
Start a conversation
The sample code in this quickstart uses either Microsoft Entra ID or an API key for authentication. You can set the script argument to be either your API key or your access token.
Create the
voice-live-quickstart.pyfile with the following code:# ------------------------------------------------------------------------- # Copyright (c) Microsoft Corporation. All rights reserved. # Licensed under the MIT License. # ------------------------------------------------------------------------- from __future__ import annotations import os import sys import argparse import asyncio import base64 from datetime import datetime import logging import queue import signal from typing import Union, Optional, TYPE_CHECKING, cast from azure.core.credentials import AzureKeyCredential from azure.core.credentials_async import AsyncTokenCredential from azure.identity.aio import AzureCliCredential, DefaultAzureCredential from azure.ai.voicelive.aio import connect from azure.ai.voicelive.models import ( AudioEchoCancellation, AudioNoiseReduction, AzureStandardVoice, InputAudioFormat, Modality, OutputAudioFormat, RequestSession, ServerEventType, ServerVad ) from dotenv import load_dotenv import pyaudio if TYPE_CHECKING: # Only needed for type checking; avoids runtime import issues from azure.ai.voicelive.aio import VoiceLiveConnection ## Change to the directory where this script is located os.chdir(os.path.dirname(os.path.abspath(__file__))) # Environment variable loading load_dotenv('./.env', override=True) # Set up logging ## Add folder for logging if not os.path.exists('logs'): os.makedirs('logs') ## Add timestamp for logfiles timestamp = datetime.now().strftime("%Y-%m-%d_%H-%M-%S") ## Set up logging logging.basicConfig( filename=f'logs/{timestamp}_voicelive.log', filemode="w", format='%(asctime)s:%(name)s:%(levelname)s:%(message)s', level=logging.INFO ) logger = logging.getLogger(__name__) class AudioProcessor: """ Handles real-time audio capture and playback for the voice assistant. Threading Architecture: - Main thread: Event loop and UI - Capture thread: PyAudio input stream reading - Send thread: Async audio data transmission to VoiceLive - Playback thread: PyAudio output stream writing """ loop: asyncio.AbstractEventLoop class AudioPlaybackPacket: """Represents a packet that can be sent to the audio playback queue.""" def __init__(self, seq_num: int, data: Optional[bytes]): self.seq_num = seq_num self.data = data def __init__(self, connection): self.connection = connection self.audio = pyaudio.PyAudio() # Audio configuration - PCM16, 24kHz, mono as specified self.format = pyaudio.paInt16 self.channels = 1 self.rate = 24000 self.chunk_size = 1200 # 50ms # Capture and playback state self.input_stream = None self.playback_queue: queue.Queue[AudioProcessor.AudioPlaybackPacket] = queue.Queue() self.playback_base = 0 self.next_seq_num = 0 self.output_stream: Optional[pyaudio.Stream] = None logger.info("AudioProcessor initialized with 24kHz PCM16 mono audio") def start_capture(self): """Start capturing audio from microphone.""" def _capture_callback( in_data, # data _frame_count, # number of frames _time_info, # dictionary _status_flags): """Audio capture thread - runs in background.""" audio_base64 = base64.b64encode(in_data).decode("utf-8") asyncio.run_coroutine_threadsafe( self.connection.input_audio_buffer.append(audio=audio_base64), self.loop ) return (None, pyaudio.paContinue) if self.input_stream: return # Store the current event loop for use in threads self.loop = asyncio.get_event_loop() try: self.input_stream = self.audio.open( format=self.format, channels=self.channels, rate=self.rate, input=True, frames_per_buffer=self.chunk_size, stream_callback=_capture_callback, ) logger.info("Started audio capture") except Exception: logger.exception("Failed to start audio capture") raise def start_playback(self): """Initialize audio playback system.""" if self.output_stream: return remaining = bytes() def _playback_callback( _in_data, frame_count, # number of frames _time_info, _status_flags): nonlocal remaining frame_count *= pyaudio.get_sample_size(pyaudio.paInt16) out = remaining[:frame_count] remaining = remaining[frame_count:] while len(out) < frame_count: try: packet = self.playback_queue.get_nowait() except queue.Empty: out = out + bytes(frame_count - len(out)) continue except Exception: logger.exception("Error in audio playback") raise if not packet or not packet.data: # None packet indicates end of stream logger.info("End of playback queue.") break if packet.seq_num < self.playback_base: # skip requested # ignore skipped packet and clear remaining if len(remaining) > 0: remaining = bytes() continue num_to_take = frame_count - len(out) out = out + packet.data[:num_to_take] remaining = packet.data[num_to_take:] if len(out) >= frame_count: return (out, pyaudio.paContinue) else: return (out, pyaudio.paComplete) try: self.output_stream = self.audio.open( format=self.format, channels=self.channels, rate=self.rate, output=True, frames_per_buffer=self.chunk_size, stream_callback=_playback_callback ) logger.info("Audio playback system ready") except Exception: logger.exception("Failed to initialize audio playback") raise def _get_and_increase_seq_num(self): seq = self.next_seq_num self.next_seq_num += 1 return seq def queue_audio(self, audio_data: Optional[bytes]) -> None: """Queue audio data for playback.""" self.playback_queue.put( AudioProcessor.AudioPlaybackPacket( seq_num=self._get_and_increase_seq_num(), data=audio_data)) def skip_pending_audio(self): """Skip current audio in playback queue.""" self.playback_base = self._get_and_increase_seq_num() def shutdown(self): """Clean up audio resources.""" if self.input_stream: self.input_stream.stop_stream() self.input_stream.close() self.input_stream = None logger.info("Stopped audio capture") # Inform thread to complete if self.output_stream: self.skip_pending_audio() self.queue_audio(None) self.output_stream.stop_stream() self.output_stream.close() self.output_stream = None logger.info("Stopped audio playback") if self.audio: self.audio.terminate() logger.info("Audio processor cleaned up") class BasicVoiceAssistant: """Basic voice assistant implementing the VoiceLive SDK patterns.""" def __init__( self, endpoint: str, credential: Union[AzureKeyCredential, AsyncTokenCredential], model: str, voice: str, instructions: str, ): self.endpoint = endpoint self.credential = credential self.model = model self.voice = voice self.instructions = instructions self.connection: Optional["VoiceLiveConnection"] = None self.audio_processor: Optional[AudioProcessor] = None self.session_ready = False self._active_response = False self._response_api_done = False async def start(self): """Start the voice assistant session.""" try: logger.info("Connecting to VoiceLive API with model %s", self.model) # Connect to VoiceLive WebSocket API async with connect( endpoint=self.endpoint, credential=self.credential, model=self.model, ) as connection: conn = connection self.connection = conn # Initialize audio processor ap = AudioProcessor(conn) self.audio_processor = ap # Configure session for voice conversation await self._setup_session() # Start audio systems ap.start_playback() logger.info("Voice assistant ready! Start speaking...") print("\n" + "=" * 60) print("🎤 VOICE ASSISTANT READY") print("Start speaking to begin conversation") print("Press Ctrl+C to exit") print("=" * 60 + "\n") # Process events await self._process_events() finally: if self.audio_processor: self.audio_processor.shutdown() async def _setup_session(self): """Configure the VoiceLive session for audio conversation.""" logger.info("Setting up voice conversation session...") # Create voice configuration voice_config: Union[AzureStandardVoice, str] if self.voice.startswith("en-US-") or self.voice.startswith("en-CA-") or "-" in self.voice: # Azure voice voice_config = AzureStandardVoice(name=self.voice) else: # OpenAI voice (alloy, echo, fable, onyx, nova, shimmer) voice_config = self.voice # Create turn detection configuration turn_detection_config = ServerVad( threshold=0.5, prefix_padding_ms=300, silence_duration_ms=500) # Create session configuration session_config = RequestSession( modalities=[Modality.TEXT, Modality.AUDIO], instructions=self.instructions, voice=voice_config, input_audio_format=InputAudioFormat.PCM16, output_audio_format=OutputAudioFormat.PCM16, turn_detection=turn_detection_config, input_audio_echo_cancellation=AudioEchoCancellation(), input_audio_noise_reduction=AudioNoiseReduction(type="azure_deep_noise_suppression"), ) conn = self.connection assert conn is not None, "Connection must be established before setting up session" await conn.session.update(session=session_config) logger.info("Session configuration sent") async def _process_events(self): """Process events from the VoiceLive connection.""" try: conn = self.connection assert conn is not None, "Connection must be established before processing events" async for event in conn: await self._handle_event(event) except Exception: logger.exception("Error processing events") raise async def _handle_event(self, event): """Handle different types of events from VoiceLive.""" logger.debug("Received event: %s", event.type) ap = self.audio_processor conn = self.connection assert ap is not None, "AudioProcessor must be initialized" assert conn is not None, "Connection must be established" if event.type == ServerEventType.SESSION_UPDATED: logger.info("Session ready: %s", event.session.id) self.session_ready = True # Start audio capture once session is ready ap.start_capture() elif event.type == ServerEventType.INPUT_AUDIO_BUFFER_SPEECH_STARTED: logger.info("User started speaking - stopping playback") print("🎤 Listening...") ap.skip_pending_audio() # Only cancel if response is active and not already done if self._active_response and not self._response_api_done: try: await conn.response.cancel() logger.debug("Cancelled in-progress response due to barge-in") except Exception as e: if "no active response" in str(e).lower(): logger.debug("Cancel ignored - response already completed") else: logger.warning("Cancel failed: %s", e) elif event.type == ServerEventType.INPUT_AUDIO_BUFFER_SPEECH_STOPPED: logger.info("🎤 User stopped speaking") print("🤔 Processing...") elif event.type == ServerEventType.RESPONSE_CREATED: logger.info("🤖 Assistant response created") self._active_response = True self._response_api_done = False elif event.type == ServerEventType.RESPONSE_AUDIO_DELTA: logger.debug("Received audio delta") ap.queue_audio(event.delta) elif event.type == ServerEventType.RESPONSE_AUDIO_DONE: logger.info("🤖 Assistant finished speaking") print("🎤 Ready for next input...") elif event.type == ServerEventType.RESPONSE_DONE: logger.info("✅ Response complete") self._active_response = False self._response_api_done = True elif event.type == ServerEventType.ERROR: msg = event.error.message if "Cancellation failed: no active response" in msg: logger.debug("Benign cancellation error: %s", msg) else: logger.error("❌ VoiceLive error: %s", msg) print(f"Error: {msg}") elif event.type == ServerEventType.CONVERSATION_ITEM_CREATED: logger.debug("Conversation item created: %s", event.item.id) else: logger.debug("Unhandled event type: %s", event.type) def parse_arguments(): """Parse command line arguments.""" parser = argparse.ArgumentParser( description="Basic Voice Assistant using Azure VoiceLive SDK", formatter_class=argparse.ArgumentDefaultsHelpFormatter, ) parser.add_argument( "--api-key", help="Azure VoiceLive API key. If not provided, will use AZURE_VOICELIVE_API_KEY environment variable.", type=str, default=os.environ.get("AZURE_VOICELIVE_API_KEY"), ) parser.add_argument( "--endpoint", help="Azure VoiceLive endpoint", type=str, default=os.environ.get("AZURE_VOICELIVE_ENDPOINT", "https://your-resource-name.services.ai.azure.com/"), ) parser.add_argument( "--model", help="VoiceLive model to use", type=str, default=os.environ.get("AZURE_VOICELIVE_MODEL", "gpt-realtime"), ) parser.add_argument( "--voice", help="Voice to use for the assistant. E.g. alloy, echo, fable, en-US-AvaNeural, en-US-GuyNeural", type=str, default=os.environ.get("AZURE_VOICELIVE_VOICE", "en-US-Ava:DragonHDLatestNeural"), ) parser.add_argument( "--instructions", help="System instructions for the AI assistant", type=str, default=os.environ.get( "AZURE_VOICELIVE_INSTRUCTIONS", "You are a helpful AI assistant. Respond naturally and conversationally. " "Keep your responses concise but engaging.", ), ) parser.add_argument( "--use-token-credential", help="Use Azure token credential instead of API key", action="store_true", default=False ) parser.add_argument("--verbose", help="Enable verbose logging", action="store_true") return parser.parse_args() def main(): """Main function.""" args = parse_arguments() # Set logging level if args.verbose: logging.getLogger().setLevel(logging.DEBUG) # Validate credentials if not args.api_key and not args.use_token_credential: print("❌ Error: No authentication provided") print("Please provide an API key using --api-key or set AZURE_VOICELIVE_API_KEY environment variable,") print("or use --use-token-credential for Azure authentication.") sys.exit(1) # Create client with appropriate credential credential: Union[AzureKeyCredential, AsyncTokenCredential] if args.use_token_credential: credential = AzureCliCredential() # or DefaultAzureCredential() if needed logger.info("Using Azure token credential") else: credential = AzureKeyCredential(args.api_key) logger.info("Using API key credential") # Create and start voice assistant assistant = BasicVoiceAssistant( endpoint=args.endpoint, credential=credential, model=args.model, voice=args.voice, instructions=args.instructions, ) # Setup signal handlers for graceful shutdown def signal_handler(_sig, _frame): logger.info("Received shutdown signal") raise KeyboardInterrupt() signal.signal(signal.SIGINT, signal_handler) signal.signal(signal.SIGTERM, signal_handler) # Start the assistant try: asyncio.run(assistant.start()) except KeyboardInterrupt: print("\n👋 Voice assistant shut down. Goodbye!") except Exception as e: print("Fatal Error: ", e) if __name__ == "__main__": # Check audio system try: p = pyaudio.PyAudio() # Check for input devices input_devices = [ i for i in range(p.get_device_count()) if cast(Union[int, float], p.get_device_info_by_index(i).get("maxInputChannels", 0) or 0) > 0 ] # Check for output devices output_devices = [ i for i in range(p.get_device_count()) if cast(Union[int, float], p.get_device_info_by_index(i).get("maxOutputChannels", 0) or 0) > 0 ] p.terminate() if not input_devices: print("❌ No audio input devices found. Please check your microphone.") sys.exit(1) if not output_devices: print("❌ No audio output devices found. Please check your speakers.") sys.exit(1) except Exception as e: print(f"❌ Audio system check failed: {e}") sys.exit(1) print("🎙️ Basic Voice Assistant with Azure VoiceLive SDK") print("=" * 50) # Run the assistant main()Sign in to Azure with the following command:
az loginRun the Python file.
python voice-live-quickstart.py --use-token-credentialThe Voice Live API starts to return audio with the model's initial response. You can interrupt the model by speaking. Enter "Ctrl+C" to quit the conversation.
Output
The output of the script is printed to the console. You see messages indicating the status of system. The audio is played back through your speakers or headphones.
============================================================
🎤 VOICE ASSISTANT READY
Start speaking to begin conversation
Press Ctrl+C to exit
============================================================
🎤 Listening...
🤔 Processing...
🎤 Ready for next input...
🎤 Listening...
🤔 Processing...
🎤 Ready for next input...
🎤 Listening...
🤔 Processing...
🎤 Ready for next input...
🎤 Listening...
🤔 Processing...
🎤 Listening...
🎤 Ready for next input...
🤔 Processing...
🎤 Ready for next input...
The script that you ran creates a log file named <timestamp>_voicelive.log in the logs folder.
The default loglevel is set to INFO but you can change it by running the quickstart with the command line parameter --verbose or by changing the logging config within the code as follows:
logging.basicConfig(
filename=f'logs/{timestamp}_voicelive.log',
filemode="w",
format='%(asctime)s:%(name)s:%(levelname)s:%(message)s',
level=logging.INFO
)
The log file contains information about the connection to the Voice Live API, including the request and response data. You can view the log file to see the details of the conversation.
2025-10-02 14:47:37,901:__main__:INFO:Using Azure token credential
2025-10-02 14:47:37,901:__main__:INFO:Connecting to VoiceLive API with model gpt-realtime
2025-10-02 14:47:37,901:azure.core.pipeline.policies.http_logging_policy:INFO:Request URL: 'https://login.microsoftonline.com/organizations/v2.0/.well-known/openid-configuration'
Request method: 'GET'
Request headers:
'User-Agent': 'azsdk-python-identity/1.22.0 Python/3.11.9 (Windows-10-10.0.26200-SP0)'
No body was attached to the request
2025-10-02 14:47:38,057:azure.core.pipeline.policies.http_logging_policy:INFO:Response status: 200
Response headers:
'Date': 'Thu, 02 Oct 2025 21:47:37 GMT'
'Content-Type': 'application/json; charset=utf-8'
'Content-Length': '1641'
'Connection': 'keep-alive'
'Cache-Control': 'max-age=86400, private'
'Strict-Transport-Security': 'REDACTED'
'X-Content-Type-Options': 'REDACTED'
'Access-Control-Allow-Origin': 'REDACTED'
'Access-Control-Allow-Methods': 'REDACTED'
'P3P': 'REDACTED'
'x-ms-request-id': 'f81adfa1-8aa3-4ab6-a7b8-908f411e0d00'
'x-ms-ests-server': 'REDACTED'
'x-ms-srs': 'REDACTED'
'Content-Security-Policy-Report-Only': 'REDACTED'
'Cross-Origin-Opener-Policy-Report-Only': 'REDACTED'
'Reporting-Endpoints': 'REDACTED'
'X-XSS-Protection': 'REDACTED'
'Set-Cookie': 'REDACTED'
'X-Cache': 'REDACTED'
2025-10-02 14:47:42,105:azure.core.pipeline.policies.http_logging_policy:INFO:Request URL: 'https://login.microsoftonline.com/organizations/oauth2/v2.0/token'
Request method: 'POST'
Request headers:
'Accept': 'application/json'
'x-client-sku': 'REDACTED'
'x-client-ver': 'REDACTED'
'x-client-os': 'REDACTED'
'x-ms-lib-capability': 'REDACTED'
'client-request-id': 'REDACTED'
'x-client-current-telemetry': 'REDACTED'
'x-client-last-telemetry': 'REDACTED'
'X-AnchorMailbox': 'REDACTED'
'User-Agent': 'azsdk-python-identity/1.22.0 Python/3.11.9 (Windows-10-10.0.26200-SP0)'
A body is sent with the request
2025-10-02 14:47:42,466:azure.core.pipeline.policies.http_logging_policy:INFO:Response status: 200
Response headers:
'Date': 'Thu, 02 Oct 2025 21:47:42 GMT'
'Content-Type': 'application/json; charset=utf-8'
'Content-Length': '6587'
'Connection': 'keep-alive'
'Cache-Control': 'no-store, no-cache'
'Pragma': 'no-cache'
'Expires': '-1'
'Strict-Transport-Security': 'REDACTED'
'X-Content-Type-Options': 'REDACTED'
'P3P': 'REDACTED'
'client-request-id': 'REDACTED'
'x-ms-request-id': '2e82e728-22c0-4568-b3ed-f00ec79a2500'
'x-ms-ests-server': 'REDACTED'
'x-ms-clitelem': 'REDACTED'
'x-ms-srs': 'REDACTED'
'Content-Security-Policy-Report-Only': 'REDACTED'
'Cross-Origin-Opener-Policy-Report-Only': 'REDACTED'
'Reporting-Endpoints': 'REDACTED'
'X-XSS-Protection': 'REDACTED'
'Set-Cookie': 'REDACTED'
'X-Cache': 'REDACTED'
2025-10-02 14:47:42,467:azure.identity._internal.interactive:INFO:InteractiveBrowserCredential.get_token succeeded
2025-10-02 14:47:42,884:__main__:INFO:AudioProcessor initialized with 24kHz PCM16 mono audio
2025-10-02 14:47:42,884:__main__:INFO:Setting up voice conversation session...
2025-10-02 14:47:42,887:__main__:INFO:Session configuration sent
2025-10-02 14:47:42,943:__main__:INFO:Audio playback system ready
2025-10-02 14:47:42,943:__main__:INFO:Voice assistant ready! Start speaking...
2025-10-02 14:47:42,975:__main__:INFO:Session ready: sess_CMLRGjWnakODcHn583fXf
2025-10-02 14:47:42,994:__main__:INFO:Started audio capture
2025-10-02 14:47:47,513:__main__:INFO:\U0001f3a4 User started speaking - stopping playback
2025-10-02 14:47:47,593:__main__:INFO:Stopped audio playback
2025-10-02 14:47:51,757:__main__:INFO:\U0001f3a4 User stopped speaking
2025-10-02 14:47:51,813:__main__:INFO:Audio playback system ready
2025-10-02 14:47:51,816:__main__:INFO:\U0001f916 Assistant response created
2025-10-02 14:47:58,009:__main__:INFO:\U0001f916 Assistant finished speaking
2025-10-02 14:47:58,009:__main__:INFO:\u2705 Response complete
2025-10-02 14:48:07,309:__main__:INFO:Received shutdown signal
In this article, you learn how to use Azure AI Speech voice live with Azure AI Foundry models using the VoiceLive SDK for C#.
Reference documentation | Package (NuGet) | Additional samples on GitHub
You create and run an application to use voice live directly with generative AI models for real-time voice agents.
Using models directly allows specifying custom instructions (prompts) for each session, offering more flexibility for dynamic or experimental use cases.
Models may be preferable when you want fine-grained control over session parameters or need to frequently adjust the prompt or configuration without updating an agent in the portal.
The code for model-based sessions is simpler in some respects, as it does not require managing agent IDs or agent-specific setup.
Direct model use is suitable for scenarios where agent-level abstraction or built-in logic is unnecessary.
To instead use the Voice live API with agents, see the Voice live API agents quickstart.
Prerequisites
- An Azure subscription. Create one for free.
- An Azure AI Foundry resource created in one of the supported regions. For more information about region availability, see the voice live overview documentation.
- .NET SDK version 6.0 or later installed.
Start a voice conversation
Follow these steps to create a console application and install the Speech SDK.
Open a command prompt window in the folder where you want the new project. Run this command to create a console application with the .NET CLI.
dotnet new consoleThis command creates the Program.cs file in your project directory.
Install the Voice Live SDK, Azure Identity, and NAudio in your new project with the .NET CLI.
dotnet add package Azure.AI.VoiceLive dotnet add package Azure.Identity dotnet add package NAudio dotnet add package System.CommandLine --version 2.0.0-beta4.22272.1 dotnet add package Microsoft.Extensions.Configuration.Json dotnet add package Microsoft.Extensions.Configuration.EnvironmentVariables dotnet add package Microsoft.Extensions.Logging.ConsoleCreate a new file named
appsettings.jsonin the folder where you want to run the code. In that file, add the following JSON content:{ "VoiceLive": { "ApiKey": "your-api-key-here", "Endpoint": "https://your-resource-name.services.ai.azure.com/", "Model": "gpt-realtime", "Voice": "en-US-Ava:DragonHDLatestNeural", "Instructions": "You are a helpful AI assistant. Respond naturally and conversationally. Keep your responses concise but engaging." }, "Logging": { "LogLevel": { "Default": "Information", "Azure.AI.VoiceLive": "Debug" } } }The sample code in this quickstart uses either Microsoft Entra ID or an API key for authentication. You can set the script argument to be either your API key or your access token. We recommend using Microsoft Entra ID authentication instead of setting the
ApiKeyvalue and running the quickstart with the--use-token-credentialargument.Replace the
ApiKeyvalue (optional) with your AI Foundry API key, and replace theEndpointvalue with your resource endpoint. You can also change the Model, Voice, and Instructions values as needed.Learn more about keyless authentication and setting environment variables.
In the file
csharp.csprojadd the following information to connect the appsettings.json:<ItemGroup> <None Update="appsettings.json"> <CopyToOutputDirectory>PreserveNewest</CopyToOutputDirectory> </None> </ItemGroup>Replace the contents of
Program.cswith the following code. This code creates a basic voice agent using one of the built-in models. For a more detailed version, see sample on GitHub.// Copyright (c) Microsoft Corporation. All rights reserved. // Licensed under the MIT License. using System; using System.CommandLine; using System.Threading; using System.Threading.Tasks; using System.Threading.Channels; using System.Collections.Generic; using Azure.AI.VoiceLive; using Azure.Core; using Azure.Core.Pipeline; using Azure.Identity; using Microsoft.Extensions.Configuration; using Microsoft.Extensions.Logging; using NAudio.Wave; namespace Azure.AI.VoiceLive.Samples { /// <summary> /// FILE: Program.cs (Consolidated) /// </summary> /// <remarks> /// DESCRIPTION: /// This consolidated sample demonstrates the fundamental capabilities of the VoiceLive SDK by creating /// a basic voice assistant that can engage in natural conversation with proper interruption /// handling. This serves as the foundational example that showcases the core value /// proposition of unified speech-to-speech interaction. /// /// All necessary code has been consolidated into this single file for easy distribution and execution. /// /// USAGE: /// dotnet run /// /// Set the environment variables with your own values before running the sample: /// 1) AZURE_VOICELIVE_API_KEY - The Azure VoiceLive API key /// 2) AZURE_VOICELIVE_ENDPOINT - The Azure VoiceLive endpoint /// /// Or update appsettings.json with your values. /// /// REQUIREMENTS: /// - Azure.AI.VoiceLive /// - Azure.Identity /// - NAudio (for audio capture and playback) /// - Microsoft.Extensions.Configuration /// - System.CommandLine /// - System.Threading.Channels /// </remarks> public class Program { /// <summary> /// Main entry point for the Voice Assistant sample. /// </summary> /// <param name="args"></param> /// <returns></returns> public static async Task<int> Main(string[] args) { // Create command line interface var rootCommand = CreateRootCommand(); return await rootCommand.InvokeAsync(args).ConfigureAwait(false); } private static RootCommand CreateRootCommand() { var rootCommand = new RootCommand("Basic Voice Assistant using Azure VoiceLive SDK"); var apiKeyOption = new Option<string?>( "--api-key", "Azure VoiceLive API key. If not provided, will use AZURE_VOICELIVE_API_KEY environment variable."); var endpointOption = new Option<string>( "--endpoint", () => "wss://api.voicelive.com/v1", "Azure VoiceLive endpoint"); var modelOption = new Option<string>( "--model", () => "gpt-4o", "VoiceLive model to use"); var voiceOption = new Option<string>( "--voice", () => "en-US-AvaNeural", "Voice to use for the assistant"); var instructionsOption = new Option<string>( "--instructions", () => "You are a helpful AI assistant. Respond naturally and conversationally. Keep your responses concise but engaging.", "System instructions for the AI assistant"); var useTokenCredentialOption = new Option<bool>( "--use-token-credential", "Use Azure token credential instead of API key"); var verboseOption = new Option<bool>( "--verbose", "Enable verbose logging"); rootCommand.AddOption(apiKeyOption); rootCommand.AddOption(endpointOption); rootCommand.AddOption(modelOption); rootCommand.AddOption(voiceOption); rootCommand.AddOption(instructionsOption); rootCommand.AddOption(useTokenCredentialOption); rootCommand.AddOption(verboseOption); rootCommand.SetHandler(async ( string? apiKey, string endpoint, string model, string voice, string instructions, bool useTokenCredential, bool verbose) => { await RunVoiceAssistantAsync(apiKey, endpoint, model, voice, instructions, useTokenCredential, verbose).ConfigureAwait(false); }, apiKeyOption, endpointOption, modelOption, voiceOption, instructionsOption, useTokenCredentialOption, verboseOption); return rootCommand; } private static async Task RunVoiceAssistantAsync( string? apiKey, string endpoint, string model, string voice, string instructions, bool useTokenCredential, bool verbose) { // Setup configuration var configuration = new ConfigurationBuilder() .AddJsonFile("appsettings.json", optional: true) .AddEnvironmentVariables() .Build(); // Override with command line values if provided apiKey ??= configuration["VoiceLive:ApiKey"] ?? Environment.GetEnvironmentVariable("AZURE_VOICELIVE_API_KEY"); endpoint = configuration["VoiceLive:Endpoint"] ?? endpoint; model = configuration["VoiceLive:Model"] ?? model; voice = configuration["VoiceLive:Voice"] ?? voice; instructions = configuration["VoiceLive:Instructions"] ?? instructions; // Setup logging using var loggerFactory = LoggerFactory.Create(builder => { builder.AddConsole(); if (verbose) { builder.SetMinimumLevel(LogLevel.Debug); } else { builder.SetMinimumLevel(LogLevel.Information); } }); var logger = loggerFactory.CreateLogger<Program>(); // Validate credentials if (string.IsNullOrEmpty(apiKey) && !useTokenCredential) { Console.WriteLine("❌ Error: No authentication provided"); Console.WriteLine("Please provide an API key using --api-key or set AZURE_VOICELIVE_API_KEY environment variable,"); Console.WriteLine("or use --use-token-credential for Azure authentication."); return; } // Check audio system before starting if (!CheckAudioSystem(logger)) { return; } try { // Create client with appropriate credential VoiceLiveClient client; if (useTokenCredential) { var tokenCredential = new DefaultAzureCredential(); client = new VoiceLiveClient(new Uri(endpoint), tokenCredential, new VoiceLiveClientOptions()); logger.LogInformation("Using Azure token credential"); } else { var keyCredential = new Azure.AzureKeyCredential(apiKey!); client = new VoiceLiveClient(new Uri(endpoint), keyCredential, new VoiceLiveClientOptions()); logger.LogInformation("Using API key credential"); } // Create and start voice assistant using var assistant = new BasicVoiceAssistant( client, model, voice, instructions, loggerFactory); // Setup cancellation token for graceful shutdown using var cancellationTokenSource = new CancellationTokenSource(); Console.CancelKeyPress += (sender, e) => { e.Cancel = true; logger.LogInformation("Received shutdown signal"); cancellationTokenSource.Cancel(); }; // Start the assistant await assistant.StartAsync(cancellationTokenSource.Token).ConfigureAwait(false); } catch (OperationCanceledException) { Console.WriteLine("\n👋 Voice assistant shut down. Goodbye!"); } catch (Exception ex) { logger.LogError(ex, "Fatal error"); Console.WriteLine($"❌ Error: {ex.Message}"); } } private static bool CheckAudioSystem(ILogger logger) { try { // Try input (default device) using (var waveIn = new WaveInEvent { WaveFormat = new WaveFormat(24000, 16, 1), BufferMilliseconds = 50 }) { // Start/Stop to force initialization and surface any device errors waveIn.DataAvailable += (_, __) => { }; waveIn.StartRecording(); waveIn.StopRecording(); } // Try output (default device) var buffer = new BufferedWaveProvider(new WaveFormat(24000, 16, 1)) { BufferDuration = TimeSpan.FromMilliseconds(200) }; using (var waveOut = new WaveOutEvent { DesiredLatency = 100 }) { waveOut.Init(buffer); // Playing isn't strictly required to validate a device, but it's safe waveOut.Play(); waveOut.Stop(); } logger.LogInformation("Audio system check passed (default input/output initialized)."); return true; } catch (Exception ex) { Console.WriteLine($"❌ Audio system check failed: {ex.Message}"); return false; } } } /// <summary> /// Basic voice assistant implementing the VoiceLive SDK patterns. ///</summary> /// <remarks> /// This sample now demonstrates some of the new convenience methods added to the VoiceLive SDK: /// - ClearStreamingAudioAsync() - Clears all input audio currently being streamed /// - CancelResponseAsync() - Cancels the current response generation (existing method) /// - ConfigureSessionAsync() - Configures session options (existing method) /// /// Additional convenience methods available but not shown in this sample: /// - StartAudioTurnAsync() / EndAudioTurnAsync() / CancelAudioTurnAsync() - Audio turn management /// - AppendAudioToTurnAsync() - Append audio data to an ongoing turn /// - ConnectAvatarAsync() - Connect avatar with SDP for media negotiation /// /// These methods provide a more developer-friendly API similar to the OpenAI SDK, /// eliminating the need to manually construct and populate ClientEvent classes. /// </remarks> public class BasicVoiceAssistant : IDisposable { private readonly VoiceLiveClient _client; private readonly string _model; private readonly string _voice; private readonly string _instructions; private readonly ILogger<BasicVoiceAssistant> _logger; private readonly ILoggerFactory _loggerFactory; private VoiceLiveSession? _session; private AudioProcessor? _audioProcessor; private bool _disposed; // Tracks whether an assistant response is currently active (created and not yet completed) private bool _responseActive; // Tracks whether the assistant can still cancel the current response (between ResponseCreated and ResponseDone) private bool _canCancelResponse; /// <summary> /// Initializes a new instance of the BasicVoiceAssistant class. /// </summary> /// <param name="client">The VoiceLive client.</param> /// <param name="model">The model to use.</param> /// <param name="voice">The voice to use.</param> /// <param name="instructions">The system instructions.</param> /// <param name="loggerFactory">Logger factory for creating loggers.</param> public BasicVoiceAssistant( VoiceLiveClient client, string model, string voice, string instructions, ILoggerFactory loggerFactory) { _client = client ?? throw new ArgumentNullException(nameof(client)); _model = model ?? throw new ArgumentNullException(nameof(model)); _voice = voice ?? throw new ArgumentNullException(nameof(voice)); _instructions = instructions ?? throw new ArgumentNullException(nameof(instructions)); _loggerFactory = loggerFactory ?? throw new ArgumentNullException(nameof(loggerFactory)); _logger = loggerFactory.CreateLogger<BasicVoiceAssistant>(); } /// <summary> /// Start the voice assistant session. /// </summary> /// <param name="cancellationToken">Cancellation token for stopping the session.</param> public async Task StartAsync(CancellationToken cancellationToken = default) { try { _logger.LogInformation("Connecting to VoiceLive API with model {Model}", _model); // Start VoiceLive session _session = await _client.StartSessionAsync(_model, cancellationToken).ConfigureAwait(false); // Initialize audio processor _audioProcessor = new AudioProcessor(_session, _loggerFactory.CreateLogger<AudioProcessor>()); // Configure session for voice conversation await SetupSessionAsync(cancellationToken).ConfigureAwait(false); // Start audio systems await _audioProcessor.StartPlaybackAsync().ConfigureAwait(false); await _audioProcessor.StartCaptureAsync().ConfigureAwait(false); _logger.LogInformation("Voice assistant ready! Start speaking..."); Console.WriteLine(); Console.WriteLine("=" + new string('=', 59)); Console.WriteLine("🎤 VOICE ASSISTANT READY"); Console.WriteLine("Start speaking to begin conversation"); Console.WriteLine("Press Ctrl+C to exit"); Console.WriteLine("=" + new string('=', 59)); Console.WriteLine(); // Process events await ProcessEventsAsync(cancellationToken).ConfigureAwait(false); } catch (OperationCanceledException) { _logger.LogInformation("Received cancellation signal, shutting down..."); } catch (Exception ex) { _logger.LogError(ex, "Connection error"); throw; } finally { // Cleanup if (_audioProcessor != null) { await _audioProcessor.CleanupAsync().ConfigureAwait(false); } } } /// <summary> /// Configure the VoiceLive session for audio conversation. /// </summary> private async Task SetupSessionAsync(CancellationToken cancellationToken) { _logger.LogInformation("Setting up voice conversation session..."); // Azure voice var azureVoice = new AzureStandardVoice(_voice); // Create strongly typed turn detection configuration var turnDetectionConfig = new ServerVadTurnDetection { Threshold = 0.5f, PrefixPadding = TimeSpan.FromMilliseconds(300), SilenceDuration = TimeSpan.FromMilliseconds(500) }; // Create conversation session options var sessionOptions = new VoiceLiveSessionOptions { InputAudioEchoCancellation = new AudioEchoCancellation(), Model = _model, Instructions = _instructions, Voice = azureVoice, InputAudioFormat = InputAudioFormat.Pcm16, OutputAudioFormat = OutputAudioFormat.Pcm16, TurnDetection = turnDetectionConfig }; // Ensure modalities include audio sessionOptions.Modalities.Clear(); sessionOptions.Modalities.Add(InteractionModality.Text); sessionOptions.Modalities.Add(InteractionModality.Audio); await _session!.ConfigureSessionAsync(sessionOptions, cancellationToken).ConfigureAwait(false); _logger.LogInformation("Session configuration sent"); } /// <summary> /// Process events from the VoiceLive session. /// </summary> private async Task ProcessEventsAsync(CancellationToken cancellationToken) { try { await foreach (SessionUpdate serverEvent in _session!.GetUpdatesAsync(cancellationToken).ConfigureAwait(false)) { await HandleSessionUpdateAsync(serverEvent, cancellationToken).ConfigureAwait(false); } } catch (OperationCanceledException) { _logger.LogInformation("Event processing cancelled"); } catch (Exception ex) { _logger.LogError(ex, "Error processing events"); throw; } } /// <summary> /// Handle different types of server events from VoiceLive. /// </summary> private async Task HandleSessionUpdateAsync(SessionUpdate serverEvent, CancellationToken cancellationToken) { _logger.LogDebug("Received event: {EventType}", serverEvent.GetType().Name); switch (serverEvent) { case SessionUpdateSessionCreated sessionCreated: await HandleSessionCreatedAsync(sessionCreated, cancellationToken).ConfigureAwait(false); break; case SessionUpdateSessionUpdated sessionUpdated: _logger.LogInformation("Session updated successfully"); // Start audio capture once session is ready if (_audioProcessor != null) { await _audioProcessor.StartCaptureAsync().ConfigureAwait(false); } break; case SessionUpdateInputAudioBufferSpeechStarted speechStarted: _logger.LogInformation("🎤 User started speaking - stopping playback"); Console.WriteLine("🎤 Listening..."); // Stop current assistant audio playback (interruption handling) if (_audioProcessor != null) { await _audioProcessor.StopPlaybackAsync().ConfigureAwait(false); } // Only attempt cancellation / clearing if a response is active and cancellable if (_responseActive && _canCancelResponse) { // Cancel any ongoing response try { await _session!.CancelResponseAsync(cancellationToken).ConfigureAwait(false); _logger.LogInformation("🛑 Active response cancelled due to user barge-in"); } catch (Exception ex) { if (ex.Message.Contains("no active response", StringComparison.OrdinalIgnoreCase)) { _logger.LogDebug("Cancellation benign: response already completed"); } else { _logger.LogWarning(ex, "Response cancellation failed during barge-in"); } } // Clear any streaming audio still in transit try { await _session!.ClearStreamingAudioAsync(cancellationToken).ConfigureAwait(false); _logger.LogInformation("✨ Cleared streaming audio after cancellation"); } catch (Exception ex) { _logger.LogDebug(ex, "ClearStreamingAudio call failed (may not be supported in all scenarios)"); } } else { _logger.LogDebug("No active/cancellable response during barge-in; skipping cancellation"); } break; case SessionUpdateInputAudioBufferSpeechStopped speechStopped: _logger.LogInformation("🎤 User stopped speaking"); Console.WriteLine("🤔 Processing..."); // Restart playback system for response if (_audioProcessor != null) { await _audioProcessor.StartPlaybackAsync().ConfigureAwait(false); } break; case SessionUpdateResponseCreated responseCreated: _logger.LogInformation("🤖 Assistant response created"); _responseActive = true; _canCancelResponse = true; break; case SessionUpdateResponseAudioDelta audioDelta: // Stream audio response to speakers _logger.LogDebug("Received audio delta"); if (audioDelta.Delta != null && _audioProcessor != null) { byte[] audioData = audioDelta.Delta.ToArray(); await _audioProcessor.QueueAudioAsync(audioData).ConfigureAwait(false); } break; case SessionUpdateResponseAudioDone audioDone: _logger.LogInformation("🤖 Assistant finished speaking"); Console.WriteLine("🎤 Ready for next input..."); break; case SessionUpdateResponseDone responseDone: _logger.LogInformation("✅ Response complete"); _responseActive = false; _canCancelResponse = false; break; case SessionUpdateError errorEvent: _logger.LogError("❌ VoiceLive error: {ErrorMessage}", errorEvent.Error?.Message); Console.WriteLine($"Error: {errorEvent.Error?.Message}"); _responseActive = false; _canCancelResponse = false; break; default: _logger.LogDebug("Unhandled event type: {EventType}", serverEvent.GetType().Name); break; } } /// <summary> /// Handle session created event. /// </summary> private async Task HandleSessionCreatedAsync(SessionUpdateSessionCreated sessionCreated, CancellationToken cancellationToken) { _logger.LogInformation("Session ready: {SessionId}", sessionCreated.Session?.Id); // Start audio capture once session is ready if (_audioProcessor != null) { await _audioProcessor.StartCaptureAsync().ConfigureAwait(false); } } /// <summary> /// Dispose of resources. /// </summary> public void Dispose() { if (_disposed) return; _audioProcessor?.Dispose(); _session?.Dispose(); _disposed = true; } } /// <summary> /// Handles real-time audio capture and playback for the voice assistant. /// /// This processor demonstrates some of the new VoiceLive SDK convenience methods: /// - Uses existing SendInputAudioAsync() method for audio streaming /// - Shows how convenience methods simplify audio operations /// /// Additional convenience methods available in the SDK: /// - StartAudioTurnAsync() / AppendAudioToTurnAsync() / EndAudioTurnAsync() - Audio turn management /// - ClearStreamingAudioAsync() - Clear all streaming audio /// - ConnectAvatarAsync() - Avatar connection with SDP /// /// Threading Architecture: /// - Main thread: Event loop and UI /// - Capture thread: NAudio input stream reading /// - Send thread: Async audio data transmission to VoiceLive /// - Playback thread: NAudio output stream writing /// </summary> public class AudioProcessor : IDisposable { private readonly VoiceLiveSession _session; private readonly ILogger<AudioProcessor> _logger; // Audio configuration - PCM16, 24kHz, mono as specified private const int SampleRate = 24000; private const int Channels = 1; private const int BitsPerSample = 16; // NAudio components private WaveInEvent? _waveIn; private WaveOutEvent? _waveOut; private BufferedWaveProvider? _playbackBuffer; // Audio capture and playback state private bool _isCapturing; private bool _isPlaying; // Audio streaming channels private readonly Channel<byte[]> _audioSendChannel; private readonly Channel<byte[]> _audioPlaybackChannel; private readonly ChannelWriter<byte[]> _audioSendWriter; private readonly ChannelReader<byte[]> _audioSendReader; private readonly ChannelWriter<byte[]> _audioPlaybackWriter; private readonly ChannelReader<byte[]> _audioPlaybackReader; // Background tasks private Task? _audioSendTask; private Task? _audioPlaybackTask; private readonly CancellationTokenSource _cancellationTokenSource; private CancellationTokenSource _playbackCancellationTokenSource; /// <summary> /// Initializes a new instance of the AudioProcessor class. /// </summary> /// <param name="session">The VoiceLive session for audio communication.</param> /// <param name="logger">Logger for diagnostic information.</param> public AudioProcessor(VoiceLiveSession session, ILogger<AudioProcessor> logger) { _session = session ?? throw new ArgumentNullException(nameof(session)); _logger = logger ?? throw new ArgumentNullException(nameof(logger)); // Create unbounded channels for audio data _audioSendChannel = Channel.CreateUnbounded<byte[]>(); _audioSendWriter = _audioSendChannel.Writer; _audioSendReader = _audioSendChannel.Reader; _audioPlaybackChannel = Channel.CreateUnbounded<byte[]>(); _audioPlaybackWriter = _audioPlaybackChannel.Writer; _audioPlaybackReader = _audioPlaybackChannel.Reader; _cancellationTokenSource = new CancellationTokenSource(); _playbackCancellationTokenSource = new CancellationTokenSource(); _logger.LogInformation("AudioProcessor initialized with {SampleRate}Hz PCM16 mono audio", SampleRate); } /// <summary> /// Start capturing audio from microphone. /// </summary> public Task StartCaptureAsync() { if (_isCapturing) return Task.CompletedTask; _isCapturing = true; try { _waveIn = new WaveInEvent { WaveFormat = new WaveFormat(SampleRate, BitsPerSample, Channels), BufferMilliseconds = 50 // 50ms buffer for low latency }; _waveIn.DataAvailable += OnAudioDataAvailable; _waveIn.RecordingStopped += OnRecordingStopped; _waveIn.DeviceNumber = 0; _waveIn.StartRecording(); // Start audio send task _audioSendTask = ProcessAudioSendAsync(_cancellationTokenSource.Token); _logger.LogInformation("Started audio capture"); return Task.CompletedTask; } catch (Exception ex) { _logger.LogError(ex, "Failed to start audio capture"); _isCapturing = false; throw; } } /// <summary> /// Stop capturing audio. /// </summary> public async Task StopCaptureAsync() { if (!_isCapturing) return; _isCapturing = false; if (_waveIn != null) { _waveIn.StopRecording(); _waveIn.DataAvailable -= OnAudioDataAvailable; _waveIn.RecordingStopped -= OnRecordingStopped; _waveIn.Dispose(); _waveIn = null; } // Complete the send channel and wait for the send task _audioSendWriter.TryComplete(); if (_audioSendTask != null) { await _audioSendTask.ConfigureAwait(false); _audioSendTask = null; } _logger.LogInformation("Stopped audio capture"); } /// <summary> /// Initialize audio playback system. /// </summary> public Task StartPlaybackAsync() { if (_isPlaying) return Task.CompletedTask; _isPlaying = true; try { _waveOut = new WaveOutEvent { DesiredLatency = 100 // 100ms latency }; _playbackBuffer = new BufferedWaveProvider(new WaveFormat(SampleRate, BitsPerSample, Channels)) { BufferDuration = TimeSpan.FromSeconds(10), // 10 second buffer DiscardOnBufferOverflow = true }; _waveOut.Init(_playbackBuffer); _waveOut.Play(); _playbackCancellationTokenSource = new CancellationTokenSource(); // Start audio playback task _audioPlaybackTask = ProcessAudioPlaybackAsync(); _logger.LogInformation("Audio playback system ready"); return Task.CompletedTask; } catch (Exception ex) { _logger.LogError(ex, "Failed to initialize audio playback"); _isPlaying = false; throw; } } /// <summary> /// Stop audio playback and clear buffer. /// </summary> public async Task StopPlaybackAsync() { if (!_isPlaying) return; _isPlaying = false; // Clear the playback channel while (_audioPlaybackReader.TryRead(out _)) { } if (_playbackBuffer != null) { _playbackBuffer.ClearBuffer(); } if (_waveOut != null) { _waveOut.Stop(); _waveOut.Dispose(); _waveOut = null; } _playbackBuffer = null; // Complete the playback channel and wait for the playback task _playbackCancellationTokenSource.Cancel(); if (_audioPlaybackTask != null) { await _audioPlaybackTask.ConfigureAwait(false); _audioPlaybackTask = null; } _logger.LogInformation("Stopped audio playback"); } /// <summary> /// Queue audio data for playback. /// </summary> /// <param name="audioData">The audio data to queue.</param> public async Task QueueAudioAsync(byte[] audioData) { if (_isPlaying && audioData.Length > 0) { await _audioPlaybackWriter.WriteAsync(audioData).ConfigureAwait(false); } } /// <summary> /// Event handler for audio data available from microphone. /// </summary> private void OnAudioDataAvailable(object? sender, WaveInEventArgs e) { if (_isCapturing && e.BytesRecorded > 0) { byte[] audioData = new byte[e.BytesRecorded]; Array.Copy(e.Buffer, 0, audioData, 0, e.BytesRecorded); // Queue audio data for sending (non-blocking) if (!_audioSendWriter.TryWrite(audioData)) { _logger.LogWarning("Failed to queue audio data for sending - channel may be full"); } } } /// <summary> /// Event handler for recording stopped. /// </summary> private void OnRecordingStopped(object? sender, StoppedEventArgs e) { if (e.Exception != null) { _logger.LogError(e.Exception, "Audio recording stopped due to error"); } } /// <summary> /// Background task to process audio data and send to VoiceLive service. /// </summary> private async Task ProcessAudioSendAsync(CancellationToken cancellationToken) { try { await foreach (byte[] audioData in _audioSendReader.ReadAllAsync(cancellationToken).ConfigureAwait(false)) { if (cancellationToken.IsCancellationRequested) break; try { // Send audio data directly to the session using the convenience method // This demonstrates the existing SendInputAudioAsync convenience method // Other available methods: StartAudioTurnAsync, AppendAudioToTurnAsync, EndAudioTurnAsync await _session.SendInputAudioAsync(audioData, cancellationToken).ConfigureAwait(false); } catch (Exception ex) { _logger.LogError(ex, "Error sending audio data to VoiceLive"); // Continue processing other audio data } } } catch (OperationCanceledException) { // Expected when cancellation is requested } catch (Exception ex) { _logger.LogError(ex, "Error in audio send processing"); } } /// <summary> /// Background task to process audio playback. /// </summary> private async Task ProcessAudioPlaybackAsync() { try { CancellationTokenSource combinedTokenSource = CancellationTokenSource.CreateLinkedTokenSource(_playbackCancellationTokenSource.Token, _cancellationTokenSource.Token); var cancellationToken = combinedTokenSource.Token; await foreach (byte[] audioData in _audioPlaybackReader.ReadAllAsync(cancellationToken).ConfigureAwait(false)) { if (cancellationToken.IsCancellationRequested) break; try { if (_playbackBuffer != null && _isPlaying) { _playbackBuffer.AddSamples(audioData, 0, audioData.Length); } } catch (Exception ex) { _logger.LogError(ex, "Error in audio playback"); // Continue processing other audio data } } } catch (OperationCanceledException) { // Expected when cancellation is requested } catch (Exception ex) { _logger.LogError(ex, "Error in audio playback processing"); } } /// <summary> /// Clean up audio resources. /// </summary> public async Task CleanupAsync() { await StopCaptureAsync().ConfigureAwait(false); await StopPlaybackAsync().ConfigureAwait(false); _cancellationTokenSource.Cancel(); // Wait for background tasks to complete var tasks = new List<Task>(); if (_audioSendTask != null) tasks.Add(_audioSendTask); if (_audioPlaybackTask != null) tasks.Add(_audioPlaybackTask); if (tasks.Count > 0) { await Task.WhenAll(tasks).ConfigureAwait(false); } _logger.LogInformation("Audio processor cleaned up"); } /// <summary> /// Dispose of resources. /// </summary> public void Dispose() { CleanupAsync().Wait(); _cancellationTokenSource.Dispose(); } } }Run your console application to start the live conversation:
dotnet run --use-token-credential
Output
The output of the script is printed to the console. You see messages indicating the status of the connection, audio stream, and playback. The audio is played back through your speakers or headphones.
info: Azure.AI.VoiceLive.Samples.Program[0]
Audio system check passed (default input/output initialized).
info: Azure.AI.VoiceLive.Samples.Program[0]
Using Azure token credential
info: Azure.AI.VoiceLive.Samples.BasicVoiceAssistant[0]
Connecting to VoiceLive API with model gpt-realtime
info: Azure.AI.VoiceLive.Samples.AudioProcessor[0]
AudioProcessor initialized with 24000Hz PCM16 mono audio
info: Azure.AI.VoiceLive.Samples.BasicVoiceAssistant[0]
Setting up voice conversation session...
info: Azure.AI.VoiceLive.Samples.BasicVoiceAssistant[0]
Session configuration sent
info: Azure.AI.VoiceLive.Samples.AudioProcessor[0]
Audio playback system ready
info: Azure.AI.VoiceLive.Samples.AudioProcessor[0]
Started audio capture
info: Azure.AI.VoiceLive.Samples.BasicVoiceAssistant[0]
Voice assistant ready! Start speaking...
============================================================
🎤 VOICE ASSISTANT READY
Start speaking to begin conversation
Press Ctrl+C to exit
============================================================
info: Azure.AI.VoiceLive.Samples.BasicVoiceAssistant[0]
Session ready: sess_CVnpwfxxxxxACIzrrr7
info: Azure.AI.VoiceLive.Samples.BasicVoiceAssistant[0]
Session updated successfully
🎤 Listening...
info: Azure.AI.VoiceLive.Samples.BasicVoiceAssistant[0]
🎤 User started speaking - stopping playback
info: Azure.AI.VoiceLive.Samples.AudioProcessor[0]
Stopped audio playback
info: Azure.AI.VoiceLive.Samples.BasicVoiceAssistant[0]
✨ Used ClearStreamingAudioAsync convenience method
🤔 Processing...
info: Azure.AI.VoiceLive.Samples.BasicVoiceAssistant[0]
🎤 User stopped speaking
info: Azure.AI.VoiceLive.Samples.AudioProcessor[0]
Audio playback system ready
info: Azure.AI.VoiceLive.Samples.BasicVoiceAssistant[0]
🤖 Assistant response created
🎤 Ready for next input...
info: Azure.AI.VoiceLive.Samples.BasicVoiceAssistant[0]
🤖 Assistant finished speaking
info: Azure.AI.VoiceLive.Samples.BasicVoiceAssistant[0]
✅ Response complete
info: Azure.AI.VoiceLive.Samples.Program[0]
Received shutdown signal
info: Azure.AI.VoiceLive.Samples.BasicVoiceAssistant[0]
Event processing cancelled
info: Azure.AI.VoiceLive.Samples.AudioProcessor[0]
Stopped audio capture
info: Azure.AI.VoiceLive.Samples.AudioProcessor[0]
Stopped audio playback
info: Azure.AI.VoiceLive.Samples.AudioProcessor[0]
Audio processor cleaned up
info: Azure.AI.VoiceLive.Samples.AudioProcessor[0]
Audio processor cleaned up
Related content
- Try the Voice live agents quickstart
- Learn more about How to use the Voice live API
- See the Voice live API reference