How to prepare for the unexpected (before an incident)
- 19 minutes
To ensure preparedness and minimize the impact of incidents, it's essential to follow the proactive recommendations outlined in this unit. These actions help you understand our incident communication process, locate pertinent information, and configure notifications to receive timely updates. Evaluating the resilience of your applications and implementing recommended measures creates more reliable workloads, which reduces the potential impact of an incident. Reviewing and implementing security best practices fortifies your environment and mitigates risks.
To stay informed, mitigate impact, and protect your investment, we recommend the following five actions:
Action #1: Familiarize yourself with Azure Service Health in the Azure portal
The public azure.status.microsoft page provides general status information on only broad outages.
Azure Service Health offers personalized details tailored to your specific resources. It helps you anticipate and prepare for planned maintenance and other changes that might affect resource availability. You can engage with service events and manage actions to maintain the business continuity of your impacted applications. It delivers crucial insights into platform vulnerabilities, security incidents, and privacy breaches at the Azure service level, which enables prompt action to safeguard your Azure workloads.
Here are some key features available in Azure Service Health to enhance your incident preparedness:
Resource Health pane (new experience covered)
Located in the Service Health page of the Azure portal, Azure Resource Health helps to diagnose and resolve service problems that affect your Azure resources. Resources, such as virtual machines, web apps, or SQL databases, are assessed for their health based on signals from different Azure services. If a resource is identified as unhealthy, Resource Health conducts a detailed analysis to determine the cause of the problem. It also provides information on Microsoft's actions to resolve problems related to incidents and suggests steps you can take to address the issue.
Services Issues pane (new experience covered)
The Services Issues pane displays ongoing service incidents that might affect your resources. It enables you to track when an issue began and identify the affected services and regions. Review the most recent updates to gain insights into Azure's efforts to resolve the incident.

Key Features of the Services Issues pane:
Real-Time Insight: The service issues dashboard offers real-time visibility into Azure service incidents that affect your subscriptions and tenants. If you're a Tenant Admin, you can see active incidents or advisories relevant to your subscriptions and tenants.
Resource Impact Assessment: The Impacted Resource tab in the incident details section shows which resources are confirmed or potentially affected. Select the resources for direct access to the Resource Health pane.
Links and Downloadable Explanations: Generate a link for the issue to use in your problem management system. Download PDF or CSV files to share comprehensive explanations with stakeholders who don't have access to the Azure portal. You can request a Post Incident Review (PIR) for any issues that affected your resources, previously known as Root Cause Analyses (RCAs).
Security advisories pane
The Security advisories pane focuses on urgent security-related information affecting the health of your subscriptions and tenants. It provides insights into platform vulnerabilities, security incidents, and privacy breaches.
Key Features of the Security advisories pane:
Real-Time Security Insights: Gain immediate visibility into Azure security incidents relevant to your subscriptions and tenants.
Resource Impact Assessment: The Impacted Resource tab in the incident details section highlights the resources that Azure confirmed that the incident affected.
Users authorized with the following roles can view security impacted resource information:
View Subscription Level Resources View Tenant Level Resources Subscription Owner Security Admin/Security Reader Subscription Admin Global Admin/Tenant Admin Service Health Security Reader Azure Service Health Privacy reader You can download explanatory PDF documents to share with stakeholders who don't have direct access to the Azure portal.
The following examples show a security incident with impacted resources from both the subscription and tenant scope.
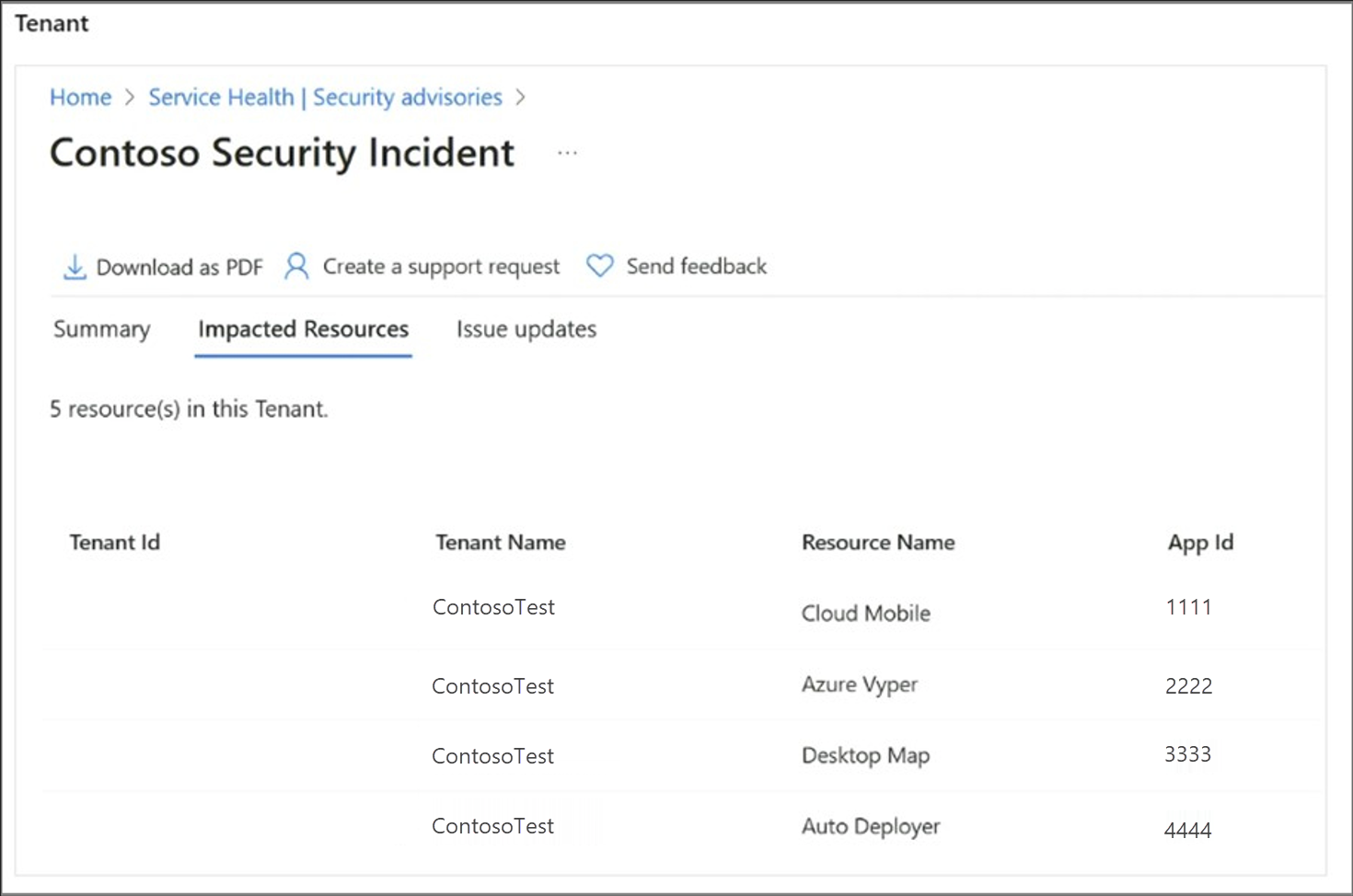
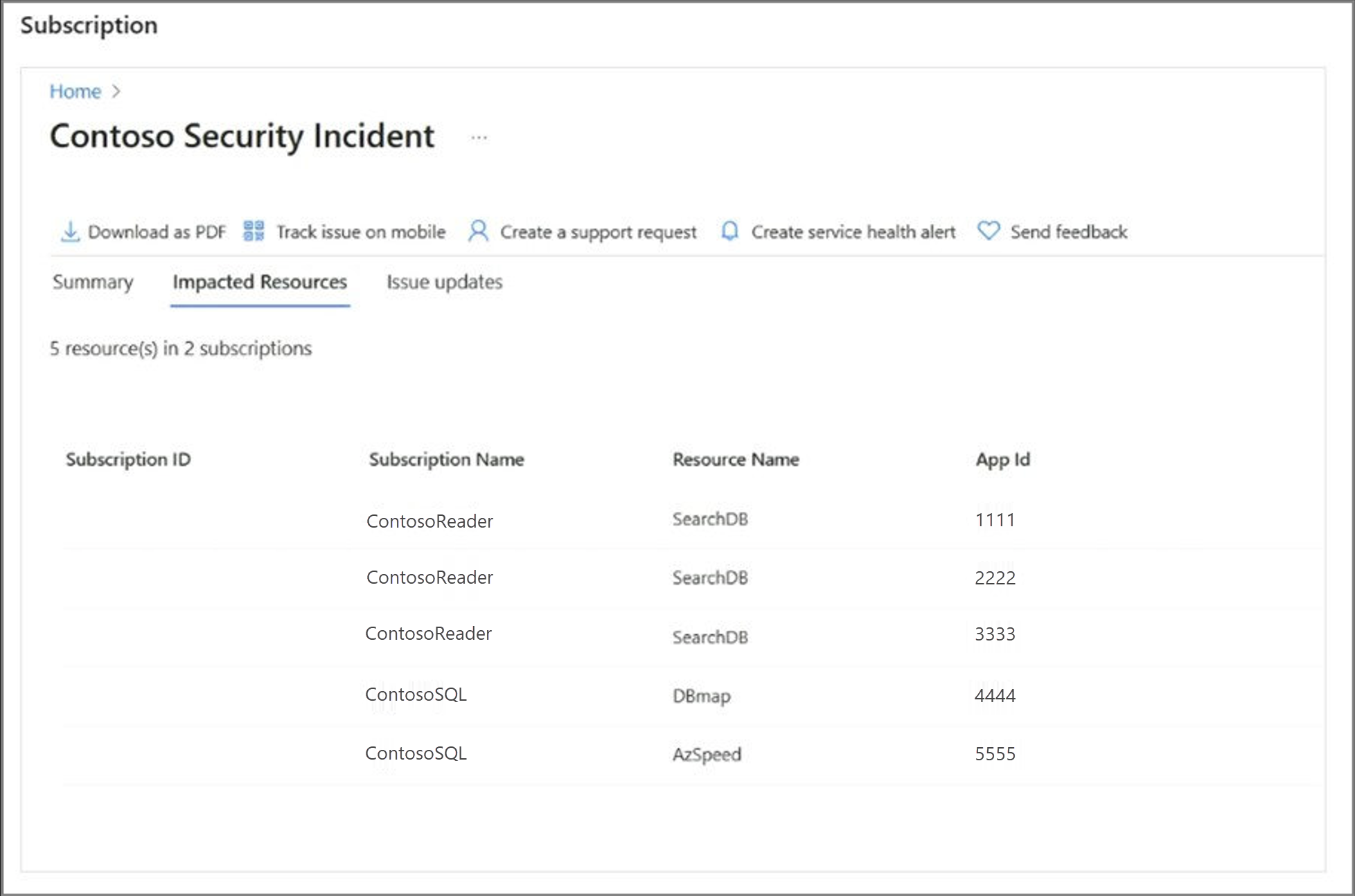
In addition to familiarizing yourself with Azure Service Health, another crucial step is to set up Service Health alerts. These alerts ensure timely notifications. They keep you informed about incidents and important information that might affect your workloads. The next section covers this issue in detail.
Action #2: Set up Service Health alerts to stay informed
Configuring service health alert notifications is essential for proactive incident management. It's the most important call to action. Service Health alerts enable you to receive timely notifications through various channels such as email, SMS, and webhooks. These alerts provide updates on service incidents, planned maintenance activities, security incidents, and other critical information that might affect your workloads.
You can configure service health alerts from any of the 'active event' panes in the Service Health page of the Azure portal, selecting Health alerts from the Service Health pane, or by using Azure Resource Graph.
Here, you can find Azure Resource Graph sample queries for Azure Service Health.

Service Health tracks different types of health events that might affect your resources. These events include service issues, planned maintenance, health advisories, and security advisories. When you configure service health alerts, you have the flexibility to choose how and to whom these alerts are sent. You can customize the alerts based on the class of service health notification, affected subscriptions, services, and regions.
Class of Service Health notifications
| Service Health Event Type | Description |
|---|---|
| Service issue | Problems in the Azure services that affect you right now, also known as service incidents. |
| Planned maintenance | Upcoming maintenance that can affect the availability of your services in the future. |
| Health advisories | Changes in Azure services that require your attention. Examples include when you need to take an action, when Azure features are deprecated, upgrade requirements, or if you exceed a usage quota. |
| Security advisories | Security related notifications dealing with platform vulnerabilities and security and privacy breaches at the subscription and tenant level, also known as security or privacy incident. |
We know you need to be notified when there are issues that affect your services. Service health alerts give you the power to choose HOW and TO WHOM these alerts are sent. The alerts can be configured based on the class of service health notification, subscriptions affected, services affected, and regions affected. You can set up alerts to trigger emails, SMS messages, logic apps, functions, and more.
When an alert is triggered, you can define the actions to be taken by using action groups. Action groups are collections of notification preferences that determine how and to whom the alerts are sent.
Full list of available notification types
| Notification Type | Description | Fields |
|---|---|---|
| Email Azure Resource Manager role | Send an email to the subscription members, based on their role. A notification email is sent only to the primary email address configured for the Microsoft Entra user. The email is only sent to Microsoft Entra user members of the selected role, not to Microsoft Entra groups or service principals. |
Enter the primary email address configured for the Microsoft Entra user. See Email. |
| Ensure that your email filtering and any malware and spam prevention services are configured appropriately. Emails are sent from the following email addresses: - azure-noreply@microsoft.com - azureemail-noreply@microsoft.com - alerts-noreply@mail.windowsazure.com |
Enter the email where the notification should be sent. | |
| SMS | SMS notifications support bi-directional communication. The SMS contains the following information: - Shortname of the action group this alert was sent to - The title of the alert. A user can respond to an SMS to: - Unsubscribe from all SMS alerts for all action groups or a single action group. - Resubscribe to alerts - Request help. For more information about supported SMS replies, see SMS replies. |
Enter the Country code and the Phone number for the SMS recipient. If you can't select your country/region code in the Azure portal, SMS isn't supported for your country/region. If your country/region code isn't available, you can vote to have your country/region added at Share your ideas. As a workaround until your country/region is supported, configure the action group to call a webhook to a partner SMS provider that supports your country/region. |
| Azure app Push notifications | Send notifications to the Azure mobile app. To enable push notifications to the Azure mobile app, provide the For more information about the Azure mobile app, see Azure mobile app. | In the Azure account email field, enter the email address that you use as your account ID when you configure the Azure mobile app. |
| Voice | Voice notification. | Enter the Country code and the Phone number for the recipient of the notification. If you can't select your country/region code in the Azure portal, voice notifications aren't supported for your country/region. If your country/region code isn't available, you can vote to have your country/region added at Share your ideas. As a workaround until your country/region is supported, configure the action group to call a webhook to a partner voice call provider that supports your country/region. |
Full list of actions you can trigger
| Action Type | Details |
|---|---|
| Automation Runbook | For information about limits on Automation runbook payloads, see Automation limits. |
| Event hubs | An Event Hubs action publishes notifications to Event Hubs. For more information about Event Hubs, see Azure Event Hubs - A big data streaming platform and event ingestion service. You can subscribe to the alert notification stream from your event receiver. |
| Functions | Calls an existing HTTP trigger endpoint in functions. For more information, see Azure Functions. When you define the function action, the function's HTTP trigger endpoint and access key are saved in the action definition, for example, https://azfunctionurl.azurewebsites.net/api/httptrigger?code=<access_key>. If you change the access key for the function, you must remove and re-create the function action in the action group.Your endpoint must support the HTTP POST method. The function must have access to the storage account. If it doesn't have access, keys aren't available and the function URI isn't accessible. Learn about restoring access to the storage account. |
| IT Service Management (ITSM) | An ITSM action requires an ITSM connection. To learn how to create an ITSM connection, see ITSM integration. |
| Logic apps | You can use Azure Logic Apps to build and customize workflows for integration and to customize your alert notifications. |
| Secure webhook | When you use a secure webhook action, you must use Microsoft Entra ID to secure the connection between your action group and your endpoint, which is a protected web API. See Configure authentication for Secure webhook. Secure webhook doesn't support basic authentication. If you're using basic authentication, use the Webhook action. |
| Webhook | If you use the webhook action, your target webhook endpoint must be able to process the various JSON payloads that different alert sources emit. You can't pass security certificates through a webhook action. To use basic authentication, you must pass your credentials through the URI. If the webhook endpoint expects a specific schema, for example, the Microsoft Teams schema, use the Logic Apps action type to manipulate the alert schema to meet the target webhook's expectations. For information about the rules used for retrying webhook actions, see Webhook. |
Most service incidents affect a few subscriptions, so these incidents don't show up on places like status.azure.com. Service health alerts can be configured from the portal. If you want to automate creation, you can configure them by using PowerShell or ARM templates.
By configuring Service Health alerts and action groups effectively, you can ensure that you receive timely notifications and take appropriate actions to mitigate the impact of incidents on your Azure resources.
Note
Looking for assistance in what to monitor and which alerts you should configure for what? Look no further than the Azure Monitor Baseline Alerts solution. It provides comprehensive guidance and code for implementing a baseline of platform alerts and service health alerts by using policies and initiatives in Azure environments. It offers options for automated or manual deployment.
The solution includes predefined policies to automatically create alerts for all service health event types (service issue, planned maintenance, health advisories, & security advisories), action groups, and alert processing rules for various Azure resource types. While the focus is on monitoring Azure Landing Zones (ALZ) architected environments, it also offers guidance for brownfield customers who aren't currently aligned to the ALZ architecture brownfield.
Action #3: Consider Resource Health alerts or Scheduled Events to inform you of resource-specific issues
After you have setup service health alerts, consider also adopting resource health alerts. Azure Resource Health alerts can notify you in near real-time when these resources have a change in their health status, regardless of why.
There's a key distinction between 'service health' alerts and 'resource health' alerts. The former is triggered during a known platform issue that is under investigation by Microsoft. An example is an ongoing outage or service incident. The latter is triggered when a specific resource is deemed unhealthy, irrespective of the underlying cause.
You can configure resource health alerts from the Resource Health pane in the Service Health page of the Azure portal.

You can also create resource health alerts programmatically using Azure Resource Manager templates and Azure PowerShell. Creating resource health alerts programmatically allows you to create and customize alerts in bulk.
Scheduled events for virtual machines, avoiding impact
Scheduled events is another great tool. Both alerts types described previously notify people or systems, but scheduled events notify the resources themselves. This approach can give your application time to prepare for virtual machine maintenance or one of our automated service healing events. It provides a signal about an imminent maintenance event, for example, an upcoming reboot, so that your application can know that and then act to limit disruption. Your application might drop itself out of the pool or otherwise degrade gracefully. Scheduled events are available for all Azure Virtual Machine types including PaaS and IaaS on both Windows and Linux.
Note
Although both resource health alerts and scheduled events are helpful tools, the most important call to action is to configure service health alerts. This feature is critical to ensure that you understand what's happening with your resources, what we're doing about it, and when it's mitigated.
Action #4: Increase the security of your investment to protect your environment
Ensure the protection of your data, applications, and other assets in Azure by reviewing and implementing the Operational Security Best Practices. These best practices are derived from the collective knowledge and experience of the people who work with the current capabilities and features of the Azure platform. The article is regularly updated to reflect evolving opinions and technologies.
As a starting point, consider these top recommendations for implementation:
Require two-step verification for all your users. This requirement includes administrators and others in your organization who can have a significant impact if their account is compromised. An example is financial officers. Enforce multifactor authentication to alleviate concerns of this exposure.
Configure and enable risk policies on your tenant. You're alerted if 'anyone' is in your environment. This approach creates an alert for risky events such as anonymous IP address use, atypical travel, and unfamiliar sign-in properties. It further triggers remediation efforts such as multifactor authentication and resetting passwords, to ensure that customers remain secure.
Control the movement of subscriptions from and into directories as a proactive measure to be prepared and aware for 'anyone' in your environment. This approach ensures your organization has full visibility into the subscriptions that are used and prevents the movement of subscriptions that could go to an unknown directory.
Rotate credentials for all global and subscription admins regularly to help protect against potential security breaches, compromised accounts, or unauthorized use of privileged permissions. Regularly rotating credentials adds an extra layer of security to your environment and helps maintain the integrity and confidentiality of your data and resources.
Review and regularly update all global admin users email and phone numbers within your tenant.
Action #5: Increase the resiliency of your key Azure workloads to potentially avoid or minimize impact
To ensure the reliability of your workloads, it's crucial to assess them using the tenets of the Microsoft Azure Well-Architected Framework (WAF) through the Microsoft Azure Well-Architected Review. The WAF also provides recommendations for resiliency testing, including adopting a chaos engineering methodology.
Applications should undergo testing to ensure both availability and resiliency. Availability refers to the duration in which an application operates without significant downtime. Resiliency measures how quickly an application can recover from failures.
To complement your work with the WAF, consider implementing the following top recommendations and using the provided tools to help you check and build resiliency into your applications:
Use the integrated Reliability workbook in the Azure portal under the Azure Advisor page to assess the reliability posture of your applications, identify potential risks, and plan and implement improvements.
Enhance business continuity and disaster recovery (BCDR) by deploying your workloads and resources across multiple regions. For optimal cross-region deployment options, see the comprehensive list of Azure region pairs.
Maximize availability within a region by distributing workload/resource deployments across Availability Zones.
Consider using isolated virtual machine sizes in Azure for your business-critical workloads that require a high level of isolation. These sizes guarantee that your virtual machine is dedicated to a specific hardware type and operates independently. For more information, see Virtual machine isolation in Azure.
Consider using Maintenance Configurations to have better control and management over updates for your Azure virtual machines. This feature allows you to schedule and manage updates, which ensure minimal disruption to sensitive workloads that can't tolerate downtime during maintenance activities.
Enhance redundancy by implementing inter or intra-region redundancy. For guidance, see the example of a Highly available zone-redundant web application.
Enhance the resilience of your applications by using Azure Chaos Studio. With this tool, you can deliberately introduce controlled faults to your Azure applications. This tool allows you to assess their resilience and observe how they respond to various disruptions such as network latency, storage outages, expiring secrets, and datacenter failures.
Use the Service Retirement workbook available in the Azure portal under the Azure Advisor page. This integrated tool helps you stay informed about any service retirements that might affect your critical workloads, which enable you to effectively plan and execute necessary migrations.
Note
Customers who have a Premier/Unified Support agreement can use the Customer Success team to strategize and implement a Well-Architected Framework assessment (WAF).