Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Windows Machine Learning (ML) enables C#, C++, and Python developers to run ONNX AI models locally on Windows PCs via the ONNX Runtime, with automatic execution provider management for different hardware (CPUs, GPUs, NPUs). ONNX Runtime can be used with models from PyTorch, Tensorflow/Keras, TFLite, scikit-learn, and other frameworks.
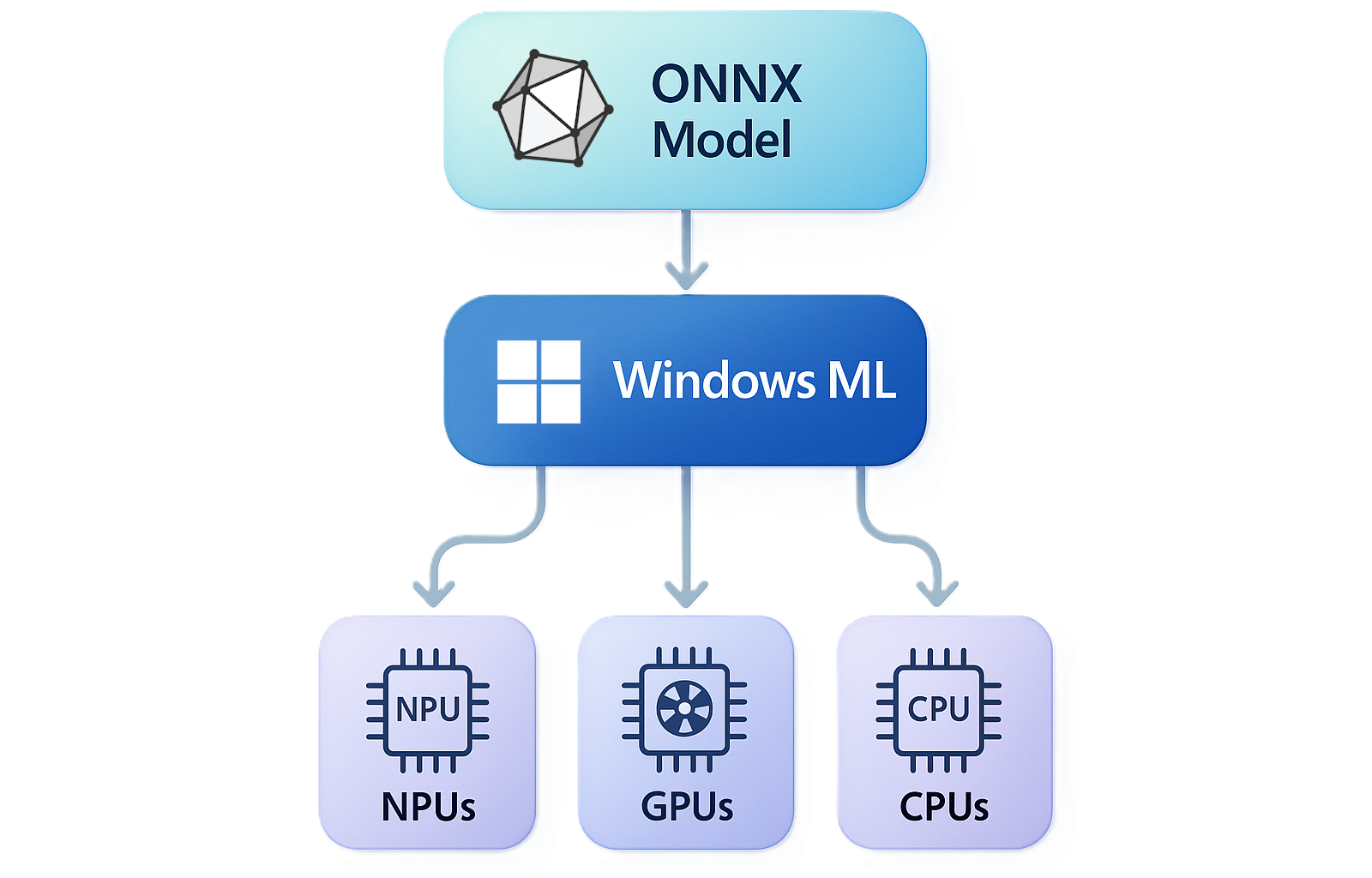
If you're not already familiar with the ONNX Runtime, we suggest reading the ONNX Runtime docs. In short, Windows ML provides a shared Windows-wide copy of the ONNX Runtime, plus the ability to dynamically download execution providers (EPs).
Key benefits
- Dynamically get latest EPs - Automatically downloads and manages the latest hardware-specific execution providers
- Shared ONNX Runtime - Uses system-wide runtime instead of bundling your own, reducing app size
- Smaller downloads/installs - No need to carry large EPs and the ONNX Runtime in your app
- Broad hardware support - Runs on all Windows 11 PCs (x64 and ARM64) with any hardware configuration
System requirements
- OS: Windows 11 version 24H2 (build 26100) or later
- Architecture: x64 or ARM64
- Hardware: Any PC configuration (CPUs, integrated/discrete GPUs, NPUs)
What is an execution provider?
An execution provider (EP) is a component that enables hardware-specific optimizations for machine learning (ML) operations. Execution providers abstract different compute backends (CPU, GPU, specialized accelerators) and provide a unified interface for graph partitioning, kernel registration, and operator execution. To learn more, see the ONNX Runtime docs.
You can see the list of EPs that Windows ML supports here.
How it works
Windows ML includes a copy of the ONNX Runtime and allows you to dynamically download vendor-specific execution providers (EPs), so your model inference can be optimized across the wide variety of CPUs, GPUs, and NPUs in the Windows ecosystem.
Automatic deployment
- App installation - Windows App SDK bootstrapper initializes Windows ML
- Hardware detection - Runtime identifies available processors
- EP download - Automatically downloads optimal execution providers
- Ready to run - Your app can immediately use AI models
This eliminates the need to:
- Bundle execution providers for specific hardware vendors
- Create separate app builds for different execution providers
- Handle execution provider updates manually
Note
You're still responsible for optimizing your models for different hardware. Windows ML handles execution provider distribution, not model optimization. See AI Toolkit and the ONNX Runtime Tutorials for more info on optimization.
Performance optimization
The latest version of Windows ML works directly with dedicated execution providers for GPUs and NPUs, delivering to-the-metal performance that's on par with dedicated SDKs of the past such as TensorRT for RTX, AI Engine Direct, and Intel's Extension for PyTorch. We've engineered Windows ML to have best-in-class GPU and NPU performance, while retaining the write-once-run-anywhere benefits that the previous DirectML-based solution offered.
Using execution providers with Windows ML
The Windows ML runtime provides a flexible way to access machine learning (ML) execution providers (EPs), which can optimize ML model inference on different hardware configurations. Those EPs are distributed as separate packages that can be updated independently from the operating system. See the initialize execution providers with Windows ML docs for more info about dynamically downloading and registering EPs.
Converting models to ONNX
You can convert models from other formats to ONNX so that you can use them with Windows ML. See the Visual Studio Code AI Toolkit's docs about how to convert models to the ONNX format to learn more. Also see the ONNX Runtime Tutorials for more info on converting PyTorch, TensorFlow, and Hugging Face models to ONNX.
Model management
Windows ML provides flexible options for managing AI models:
- Model Catalog - Dynamically download models from online catalogs without bundling large files
- Local models - Include model files directly in your application package
Integration with Windows AI ecosystem
Windows ML serves as the foundation for the broader Windows AI platform:
- Windows AI APIs - Built-in models for common tasks
- Foundry Local - Ready-to-use AI models
- Custom models - Direct Windows ML API access for advanced scenarios
Providing feedback
Found an issue or have suggestions? Search or create issues on the Windows App SDK GitHub.
Next steps
- Get started: Get started with Windows ML
- Model management: Model Catalog overview
- Learn more: ONNX Runtime documentation
- Convert models: VS Code AI Toolkit model conversion