このコンテンツの適用対象:![]() v4.0 | 以前のバージョン:
v4.0 | 以前のバージョン:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA) ::: moniker-end
v3.0 (GA) ::: moniker-end
Document Intelligence 医療保険カード モデルでは、強力な光学式文字認識 (OCR) 機能と、ディープ ラーニング モデルの組み合わせにより、米国の医療保険カードが分析されて、重要な情報が抽出されます。 医療保険証は、医療処理の重要なドキュメントです。 患者のオンボーディング、財務カバレッジ情報、キャッシュレス支払い、保険金請求処理についてデジタル分析することができます。 医療保険カード モデルは、医療カードの画像を分析します。保険者、メンバー、処方箋、グループ番号などの重要な情報を抽出します。構造化された JSON 表現を返します。 医療保険カードは、電話でキャプチャされた画像、スキャンされたドキュメント、デジタル PDF など、さまざまな形式や品質の請求書で表示できます。
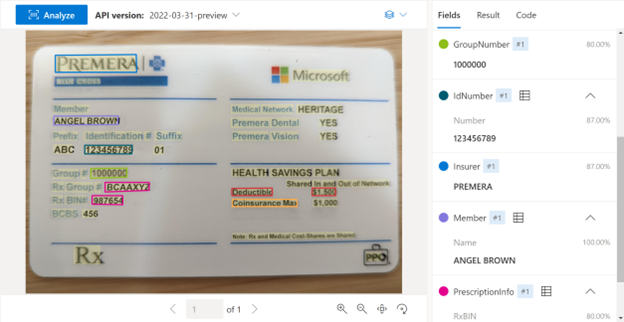
Document Intelligence Studio を使用して処理された医療保険カードのサンプル
開発オプション
Document Intelligence v4.0: 2024-11-30 (GA) は、次のツール、アプリケーション、ライブラリをサポートします:
| 機能 | リソース | モデル ID |
|---|---|---|
| 医療保険カード モデル | • ドキュメントインテリジェンススタジオ • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-healthInsuranceCard.us |
Document Intelligence v3.1 では、次のツール、アプリケーション、ライブラリがサポートされています。
| 機能 | リソース | モデル ID |
|---|---|---|
| 医療保険カード モデル | • ドキュメントインテリジェンススタジオ • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-healthInsuranceCard.us |
ドキュメント インテリジェンス v3.0 では、次のツール、アプリケーション、およびライブラリがサポートされています:
| 機能 | リソース | モデル ID |
|---|---|---|
| 医療保険カード モデル | • ドキュメントインテリジェンススタジオ • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-healthInsuranceCard.us |
入力の要件
次のファイル形式がサポートされています。
| モデル | 画像: JPEG/JPG、PNG、BMP、TIFF、HEIF |
Office: Word (DOCX)、Excel (XLSX)、PowerPoint (PPTX)、HTML |
|
|---|---|---|---|
| 読み込み | ✔ | ✔ | ✔ |
| レイアウト | ✔ | ✔ | ✔ |
| 一般的なドキュメント | ✔ | ✔ | |
| 事前構築済み | ✔ | ✔ | |
| カスタム抽出 | ✔ | ✔ | |
| カスタム分類 | ✔ | ✔ | ✔ |
- 写真とスキャン: 最良の結果を得るには、ドキュメントごとに 1 つの明確な写真または高品質のスキャンを提供します。
- PDF とTIFF: PDF とTIFF の場合、最大 2,000 ページを処理できます。 (Free レベルのサブスクリプションでは、最初の 2 ページのみが処理されます)。
- ファイル サイズ: ドキュメントを分析するためのファイル サイズは、有料 (S0) レベルでは 500 MB、Free (F0) レベルでは 4 MB です。
- 画像の寸法: 寸法は、50 ピクセル x 50 ピクセルから 10,000 ピクセル x 10,000 ピクセルの間である必要があります。
- パスワード ロック: PDF がパスワードロックされている場合は、提出前にロックを解除する必要があります。
- テキストの高さ: 抽出するテキストの最小高さは、1024 x 768 ピクセルの画像で 12 ピクセルです。 このディメンションは、1 インチあたり 150 ドットの約 8 ポイントのテキストに対応します。
- カスタム モデル トレーニング: トレーニング データの最大ページ数は、カスタム テンプレート モデルの場合は 500 ページ、カスタム ニューラル モデルの場合は 50,000 ページです。
- カスタム抽出モデルトレーニング: トレーニング データの合計サイズは、テンプレート モデルの場合は 50 MB、ニューラル モデルの場合は 1 GB です。
- カスタム分類モデル トレーニング: トレーニング データの合計サイズは 1 GB で、最大 10,000 ページです。 2024-11-30 (GA) の場合、トレーニング データの合計サイズは 2 GB で、最大 10,000 ページです。
- Office ファイルの種類 (DOCX、XLSX、PPTX): 文字列の最大長の制限は 800 万文字です。
Document Intelligence Studio を試す
Document Intelligence Studio を使って、医療保険カードからデータを抽出する様子を確認できます。 以下のリソースが必要です。
Azure サブスクリプション—無料で作成できます。
Azure portal の Document Intelligence Studio インスタンス。 Free 価格レベル (
F0) を利用して、サービスを試用できます。 リソースがデプロイされたら、[リソースに移動] を選択してキーとエンドポイントを取得します。

Note
Document Intelligence Studio は、API バージョン v3.0 で使用できます。
Document Intelligence Studio のホーム ページで、[医療保険カード] を選択します。
サンプル保険カード ドキュメントを分析するか、[➕追加] ボタンを選択して、独自のサンプルをアップロードできます。
[分析の実行] ボタンを選択し、必要に応じて [分析オプション] を構成します。
![Document Intelligence Studio の [分析の実行] と [分析オプション] ボタンのスクリーンショット。](../media/studio/run-analysis-analyze-options.png?view=doc-intel-4.0.0)
サポートされている言語とロケール
サポートされている言語の完全な一覧については、事前構築済みモデルの言語サポートに関するページを "参照" してください。
フィールドの抽出
サポートされているドキュメント抽出フィールドについては、GitHub サンプル リポジトリの健康保険カード モデル スキーマに関するページを参照してください。
移行ガイドと REST API v3.1
アプリケーションとワークフローで v3.1 バージョンを使用する方法については、Document Intelligence v3.1 への移行ガイドの説明を参照してください。
v3.1 バージョンと新機能の詳細については、REST API に関する記事を参照してください。
次のステップ
Document Intelligence Studio を使用して独自のフォームとドキュメントの処理を試す。
Document Intelligence クイックスタートを完了し、選択した開発言語でドキュメント処理アプリの作成を開始します。