このコンテンツの適用対象:![]() v2.1 | 最新バージョン:
v2.1 | 最新バージョン:![]() v4.0 (GA)
v4.0 (GA)
Document Intelligence 領収書モデルでは、強力な光学式文字認識 (OCR) 機能と、ディープ ラーニング モデルを組み合わせて、領収書を分析し、領収書から重要な情報を抽出します。 領収書には、印刷されたレシートや手書きの領収書など、さまざまな形式や品質のものが存在します。 API によって、業者名、業者の電話番号、取引日、税金、取引合計などの主要な情報が抽出されて、構造化された JSON データが返されます。 レシート モデル v4.0 (GA) では、一般的なホテルの領収書の VAT テーブル抽出と共に、ReceiptType、TaxDetails.NetAmount、TaxDetails.Description、TaxDetails.Rate、CountryRegion などのフィールドがサポートされています。
領収書データの抽出
領収書のデジタル化には、さまざまな種類の領収書 (スキャンされたもの、写真、印刷されたコピーなど) を、効率的なダウンストリーム処理用にデジタル形式に変換する作業が含まれます。 たとえば、経費管理、コンシューマーの行動分析、税の自動化などがあります。OCR (光学式文字認識) テクノロジを備えた Document Intelligence を使用すると、こうしたさまざまな形式の領収書からデータを抽出し解釈することができます。 Document Intelligence 処理により変換プロセスが簡素化されるだけでなく、必要な時間と作業量が大幅に少なくなるため、効率的なデータ管理と取得が促されます。
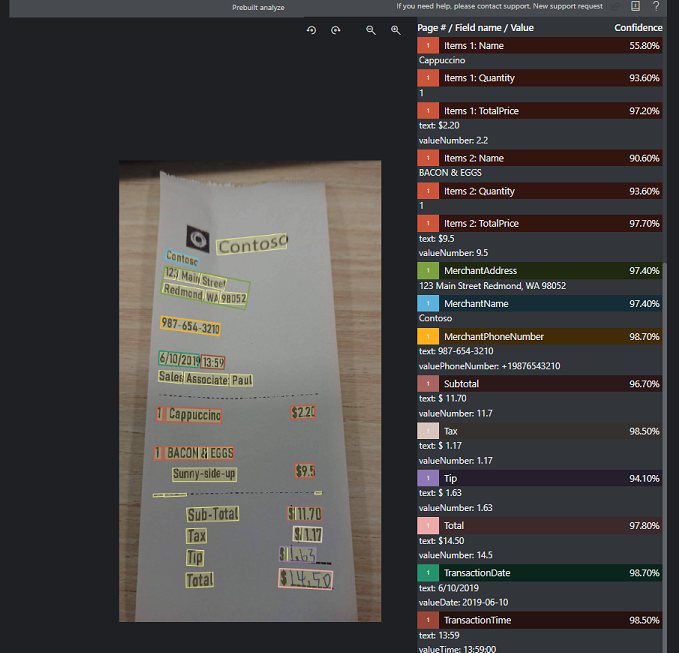
Document Intelligence Studio を使用して処理された領収書のサンプル:

Document Intelligence サンプル ラベル付けツールで処理された請求書のサンプル:
開発オプション
Document Intelligence v4.0: 2024-11-30 (GA) は、次のツール、アプリケーション、ライブラリをサポートします:
| 特徴量 | リソース | モデル ID |
|---|---|---|
| 領収書モデル | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-receipt |
ドキュメント インテリジェンス v3.1 では、次のツール、アプリケーション、およびライブラリがサポートされています:
| 特徴量 | リソース | モデル ID |
|---|---|---|
| 領収書モデル | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-receipt |
ドキュメント インテリジェンス v3.0 では、次のツール、アプリケーション、およびライブラリがサポートされています:
| 特徴量 | リソース | モデル ID |
|---|---|---|
| 領収書モデル | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-receipt |
ドキュメント インテリジェンス v2.1 では、次のツール、アプリケーション、およびライブラリがサポートされています:
| 特徴量 | リソース |
|---|---|
| 領収書モデル | • Document Intelligence ラベル付けツール • REST API • クライアント ライブラリ SDK • Document Intelligence Docker コンテナー |
入力の要件
次のファイル形式がサポートされています。
| モデル | 画像: JPEG/JPG、PNG、BMP、TIFF、HEIF |
Office: Word (DOCX)、Excel (XLSX)、PowerPoint (PPTX)、HTML |
|
|---|---|---|---|
| Read | ✔ | ✔ | ✔ |
| レイアウト | ✔ | ✔ | ✔ |
| 一般ドキュメント | ✔ | ✔ | |
| 事前構築済み | ✔ | ✔ | |
| カスタム抽出 | ✔ | ✔ | |
| カスタム分類 | ✔ | ✔ | ✔ |
- 写真とスキャン: 最適な結果を得るには、ドキュメントごとに 1 つの鮮明な写真または高品質のスキャンを用意します。
- PDF と TIFF: PDF とTIFF の場合、最大 2,000 ページを処理できます。 (Free レベルのサブスクリプションでは、最初の 2 ページのみが処理されます。)
- ファイル サイズ: ドキュメントを分析するためのファイル サイズは、有料 (S0) レベルでは 500 MB、Free (F0) レベルでは 4 MB です。
- 画像の寸法: 寸法は、50 ピクセル x 50 ピクセルから 10,000 ピクセル x 10,000 ピクセルの間である必要があります。
- パスワード ロック: PDF がパスワードでロックされている場合は、送信前にロックを解除する必要があります。
- テキストの高さ: 抽出するテキストの最小の高さは、1024 x 768 ピクセルの画像の場合で 12 ピクセルです。 この寸法は、150 DPI で約 8 ポイントのテキストに相当します。
- カスタム モデル トレーニング: トレーニング データの最大ページ数は、カスタム テンプレート モデルの場合は 500、カスタム ニューラル モデルの場合は 50,000 です。
- カスタム抽出モデル トレーニング: トレーニング データの合計サイズは、テンプレート モデルの場合は 50 MB、ニューラル モデルの場合は 1 GB です。
- カスタム分類モデル トレーニング: トレーニング データの合計サイズは 1 GB で、最大 10,000 ページです。 2024-11-30 (GA) の場合、トレーニング データの合計サイズは 2 GB で、最大 10,000 ページです。
- Office ファイルの種類 (DOCX、XLSX、PPTX): 文字列の最大長の制限は 800 万文字です。
- サポートされているファイル形式: JPEG、PNG、PDF、TIFF。
- PDF と TIFF でサポートされているページ許容量: Document Intelligence では、Standard レベルのサブスクライバーの場合は最大 2,000 ページ、Free レベルのサブスクライバーの場合は最初の 2 ページのみを処理できます。
- サポートされるファイル サイズ: 50 MB 未満、最小ピクセル数: 50 x 50 px、最大ピクセル数: 10,000 x 10,000 px。
領収書モデル データの抽出
Document Intelligence によって、データ (トランザクションの日時、マーチャント情報、合計金額など) を領収書から抽出する方法について確認します。 次のリソースが必要です。
Azure サブスクリプション - 無料で作成できます。
Azure portal の Document Intelligence インスタンス。 Free 価格レベル (
F0) を利用して、サービスを試用できます。 リソースがデプロイされたら、[リソースに移動] を選択してキーとエンドポイントを取得します。

Note
Document Intelligence Studio は、v3.1 および v3.0 API 以降のバージョンで使用できます。
Document Intelligence Studio ホーム ページで、[領収書] を選択します。
サンプル レシートを分析したり、独自のファイルをアップロードしたりできます。
[Run analysis] (解析の実行) ボタンを選択し、必要に応じて [Analyze options] (解析オプション) を構成します。
![Document Intelligence Studio の [Run analysis] (解析の実行) と [Analyze options] (解析オプション) のボタンのスクリーンショット。](../media/studio/run-analysis-analyze-options.png?view=doc-intel-4.0.0)
Document Intelligence サンプル ラベル付けツール
サンプル ツールのホーム ページで、[事前構築済みモデルを使用してデータを取得する] タイルを選択します。
ドロップダウン メニューから、分析する [フォームの種類] を選択します。
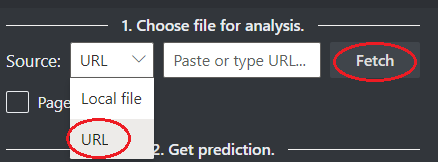
次のオプションを使用して、分析するファイルの URL を選択します。
[ソース] フィールドで、ドロップダウン メニューから [URL] を選択し、選択した URL を貼り付けて、[フェッチ] ボタンを選択します。
[Document Intelligence サービス エンドポイント] フィールドに、Document Intelligence サブスクリプションで取得したエンドポイントを貼り付けます。
[キー] フィールドに、Document Intelligence リソースから取得したキーを貼り付けます。

[Run analysis]\(解析の実行\) を選択します。 Document Intelligence サンプル ラベル付けツールは、Analyze Prebuilt API を呼び出してドキュメントを分析します。
結果を表示する - 抽出されたキーと値のペア、行項目、抽出された強調表示テキスト、および検出されたテーブルを確認します。

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Note
サンプル ラベル付けツールでは、BMP ファイル形式はサポートされていません。 これは、Document Intelligence サービスではなくツールの制限です。
サポートされている言語とロケール
サポートされている言語の全一覧については、事前構築済みモデルの言語サポートのページを参照してください。
フィールドの抽出
サポートされているドキュメント抽出フィールドについては、GitHub サンプル リポジトリの領収書モデル スキーマに関するページを参照してください
| 名前 | タイプ | 説明 | 標準化された出力 |
|---|---|---|---|
| ReceiptType | String | 販売レシートの種類 | Itemized |
| MerchantName | String | レシートを発行しているマーチャントの名前 | |
| MerchantPhoneNumber | phoneNumber | マーチャントの電話番号の一覧 | +1 xxx xxx xxxx |
| MerchantAddress | String | マーチャントの住所の一覧 | |
| TransactionDate | Date | レシートが発行された日付 | yyyy-mm-dd |
| TransactionTime | Time | レシートが発行された時刻 | hh-mm-ss (24 時間) |
| 合計 | 数値 (米国ドル) | レシートの取引合計額 | 小数点以下 2 桁の浮動小数点数 |
| 小計 | 数値 (米国ドル) | レシートの小計 (多くの場合、税金が適用される前) | 小数点以下 2 桁の浮動小数点数 |
| 税 | 数値 (米国ドル) | 領収書の税金合計 (多くの場合、消費税、またはそれに相当する税金) 2022-06-30 バージョンで "TotalTax" に名前が変更されました。 | 小数点以下 2 桁の浮動小数点数 |
| ヒント | 数値 (米国ドル) | 購入者によって追加されたチップ | 小数点以下 2 桁の浮動小数点数 |
| アイテム | オブジェクトの配列 | 抽出された品目 (名前、数量、単価、および合計価格) | |
| 名前 | String | 項目の説明。 2022-06-30 バージョンで "Description" に名前が変更されました。 | |
| Quantity | Number | 各品目の数量 | 小数点以下 2 桁の浮動小数点数 |
| Price | Number | 各品目単位の個別価格 | 小数点以下 2 桁の浮動小数点数 |
| TotalPrice | Number | 品目の合計価格 | 小数点以下 2 桁の浮動小数点数 |
移行ガイドと REST API v3.1
- アプリケーションとワークフローで v3.1 バージョンを使用する方法については、Document Intelligence v3.1 への移行ガイドを参照してください。
次のステップ
Document Intelligence Studio を使用して独自のフォームとドキュメントの処理を試す。
Document Intelligence クイックスタートを完了し、選択した開発言語でドキュメント処理アプリの作成を開始する。
Document Intelligence サンプル ラベル付けツールを使用して独自のフォームとドキュメントの処理を試す。
Document Intelligence クイックスタートを完了し、選択した開発言語でドキュメント処理アプリの作成を開始する。