この記事では、Azure portal で正常性チェックを使用して Azure App Service インスタンスを監視する方法について説明します。 正常性チェックを行うと、異常なインスタンスを避けて要求を再ルーティングし、正常に戻らないインスタンスを置き換えることができるので、アプリケーションの可用性が向上します。 そのために、選択したパスを使用して Web アプリケーションに毎分 ping が送信されます。
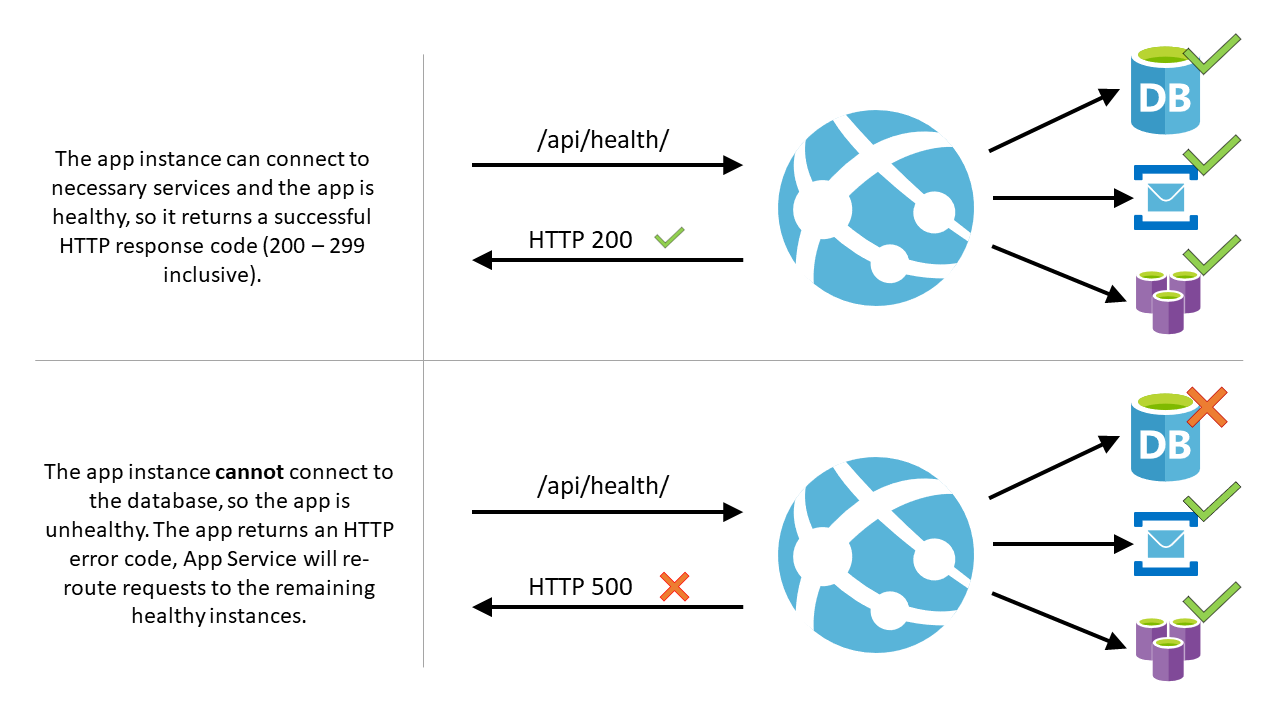
/api/health は単なる例であることに注意してください。 既定の正常性チェック パスはありません。 選択するパスが、アプリケーション内に存在する有効なパスであることを確認する必要があります。
正常性チェックのしくみ
- アプリでパスを指定すると、正常性チェックによって、App Service アプリのすべてのインスタンスで 1 分間隔でこのパスに対する ping が実行されます。
- 特定のインスタンスで実行されている Web アプリが、10 回要求しても 200 から 299 まで (両方を含む) の状態コードで応答しない場合、インスタンスは App Service によって異常と判断され、この Web アプリのロード バランサーから削除されます。 インスタンスが異常であると判断するために必要な失敗した要求の数は、少なくとも 2 つの要求で構成できます。
- インスタンスが削除された後も、正常性チェックはインスタンスへの ping 送信を継続します。 インスタンスが正常な状態コード (200 から 299) で応答を開始すると、インスタンスがロード バランサーに返されます。
- インスタンスで実行されている Web アプリが 1 時間異常なままの場合、そのインスタンスは新しいものに置き換えられます。
- スケールアウトする場合は、新しいインスタンスの準備ができていることを保証するために、App Service によって正常性チェック パスに対して ping が実行されます。
注
- 正常性チェックは 302 リダイレクトには従いません。
- 最大で 1 時間あたり 1 つのインスタンスが置き換えられ、App Service プランごとに 1 日あたり最大 3 つのインスタンスがあります。
- 正常性チェックが状態
Waiting for health check responseを送信した場合、HTTP 状態コード 307 が原因でチェックが失敗する可能性があります。 この状態は、HTTPS リダイレクトが有効になっていても、HTTPS Only無効になっている場合に発生する可能性があります。
正常性チェックを有効にする

- 正常性チェックを有効にするには、Azure portal に移動し、App Service アプリを選択します。
- 左側のウィンドウの [ 監視] で、[ 正常性チェック] を選択します。
-
[有効] を選択し、
/healthや/api/healthなど、ご利用のアプリケーションの有効な URL パスを指定します。 - [保存] を選択します。
注
- 正常性チェックを完全に利用するには、App Service プランを 2 つ以上のインスタンスにスケーリングする必要があります。
- 正常性チェック パスによって、ご利用のアプリケーションの重要なコンポーネントが確認されます。 たとえば、ご利用のアプリケーションがデータベースとメッセージング システムに依存している場合、正常性チェックのエンドポイントはそれらのコンポーネントに接続する必要があります。 アプリケーションが重要なコンポーネントに接続できない場合、パスは、アプリが異常であることを示す 500 レベルの応答コードを返す必要があります。 また、パスが 1 分以内に応答を返さない場合、正常性チェックの ping は異常と見なされます。
- 正常性チェック パスを選択するときは、アプリが完全にウォームアップされている場合にのみ、状態コード 200 を返すパスを選択していることを確認します。
- 関数アプリで正常性チェックを使用するには、 Premium または専用のホスティング プランを使用する必要があります。
- 関数アプリの正常性チェックの詳細については、「正常性 チェックを使用して関数アプリを監視する」を参照してください。
注意事項
正常性チェックの構成変更によって、アプリが再起動します。 運用アプリへの影響を最小限に抑えるために、 ステージング スロットを構成 し、運用環境にスワップすることをお勧めします。
構成
正常性チェックのオプションを構成するだけでなく、次のアプリ設定を構成することもできます。
| アプリ設定の名前 | 使用できる値 | 説明 |
|---|---|---|
WEBSITE_HEALTHCHECK_MAXPINGFAILURES |
2 ~ 10 | インスタンスが異常と見なされ、ロード バランサーから削除するために必要な失敗した要求の数。 たとえば、この設定を 2 に設定すると、ping が 2 つ失敗した後にインスタンスが削除されます。 (既定値は 10 です)。 |
WEBSITE_HEALTHCHECK_MAXUNHEALTHYWORKERPERCENT |
1 から 100 | 既定では、残りの正常なインスタンスに負荷がかかりすぎないように、一度にロード バランサーから除外されるインスタンスの数は半分以下です。 たとえば、App Service プランが 4 つのインスタンスにスケーリングされ、3 つに異常が発生した場合、2 つが除外されます。 他の 2 つのインスタンス (1 つは正常、1 つは異常) は、引き続き要求を受信します。 すべてのインスタンスが異常であるというシナリオでは、何も除外されません。 この動作をオーバーライドするには、このアプリ設定を 1 から 100 の値に設定します。 値を大きくすると、異常なインスタンスがより多く削除されます。 (既定値は 50 です)。 |
認証とセキュリティ
正常性チェックは、App Service の認証および認可機能と統合されます。 これらのセキュリティ機能が有効になっている場合、他の設定は必要ありません。
独自の認証システムを使用する場合は、正常性チェック パスで匿名アクセスを許可する必要があります。 正常性チェック エンドポイントのセキュリティを提供するには、まず 、IP 制限、 クライアント証明書、仮想ネットワークなどの機能を使用して、アプリケーションのアクセスを制限する必要があります。 これらの機能を設定したら、ヘッダー x-ms-auth-internal-token を検査し、環境変数 WEBSITE_AUTH_ENCRYPTION_KEYの SHA256 ハッシュと一致することを検証することで、正常性チェック要求を認証できます。 一致する場合、正常性チェック要求は有効であり、App Service から送信されます。
注
Azure Functions 認証の場合、正常性チェック エンドポイントとして機能する関数は、匿名アクセスを許可する必要があります。
using System;
using System.Security.Cryptography;
using System.Text;
/// <summary>
/// Method <c>HeaderMatchesEnvVar</c> returns true if <c>headerValue</c> matches WEBSITE_AUTH_ENCRYPTION_KEY.
/// </summary>
public bool HeaderMatchesEnvVar(string headerValue)
{
var sha = SHA256.Create();
string envVar = Environment.GetEnvironmentVariable("WEBSITE_AUTH_ENCRYPTION_KEY");
string hash = Convert.ToBase64String(sha.ComputeHash(Encoding.UTF8.GetBytes(envVar)));
return string.Equals(hash, headerValue, StringComparison.Ordinal);
}
注
x-ms-auth-internal-token ヘッダーは、App Service for Windows でのみ使用できます。
インスタンス
正常性チェックが有効になった後、[ インスタンス ] タブからアプリケーション インスタンスの状態を再起動して監視できます。[ インスタンス] タブには、インスタンスの名前と、そのアプリケーションのインスタンスの状態が表示されます。 [再起動] ボタンを選択して、このタブから高度なアプリケーションの 再起動 を手動で行うこともできます。
アプリケーション インスタンスの状態が異常の場合は 、 テーブルの [再起動] ボタンを選択して、それぞれのアプリのワーカー プロセスを手動で 再起動 できます。 再起動は、同じ App Service プランでホストされている他のどのアプリケーションにも影響しません。 インスタンスと同じ App Service プランを使用している他のアプリケーションがある場合は、[ 再起動] を選択したときに開くウィンドウに表示されます。
インスタンスを再起動しても再起動プロセスが失敗した場合は、worker を置き換えるオプションが表示されます。 (1 時間に置き換えることができるインスタンスは 1 つだけです)。このアクションは、同じ App Service プランを使用するすべてのアプリケーションに影響します。
Windows アプリケーションの場合は、Process Explorer を使用してプロセスを表示することもできます。 これにより、スレッド数、プライベート メモリ、合計 CPU 時間など、インスタンスのプロセスに関する詳細な分析情報が得られます。
診断情報の収集
Windows アプリケーションの場合、[ 正常性チェック ] タブで診断情報を収集するオプションがあります。診断コレクションを有効にすると、異常なインスタンスのメモリ ダンプを作成し、指定されたストレージ アカウントに保存する自動修復規則が追加されます。 このオプションを有効にすると、自動修復の構成が変更されます。 既存の自動修復規則がある場合は、App Service の診断を使用して、これを設定することをお勧めします。
診断収集が有効になった後、ストレージ アカウントを作成するか、ファイルの既存のアカウントを選択できます。 アプリケーションと同じリージョンにあるストレージ アカウントのみを選択できます。 保存によってアプリケーションが再起動されることに注意してください。 保存の後、継続的に ping を実行してもサイト インスタンスが異常であることが検出された場合は、ストレージ アカウント リソースに移動してメモリ ダンプを表示できます。
監視
アプリケーションの正常性チェック パスを指定したら、Azure Monitor を使用してサイトの正常性を監視できます。 ポータルの [正常性チェック ] ページで、ツール バーの [メトリック] を選択します。 これにより、サイトの正常性チェックの状態履歴を確認し、新しいアラート ルールを作成できる新しいページが開きます。 正常性チェックの状態メトリックは、成功した ping を集計し、構成されている正常性チェック負荷分散 しきい 値に基づいてインスタンスが異常と見なされた場合にのみ失敗を表示します。 既定では、この値は 10 分に設定されているため、特定のインスタンスに対して 10 回の連続 ping (1 分あたり 1 回) が異常と見なされ、その場合にのみメトリックに反映されます。 サイトの監視の詳細については、 Azure App Service のクォータとメトリックに関するページを参照してください。
制限事項
- 正常性チェックは、Free および共有の App Service プランで有効にできるため、サイトの正常性に関するメトリックを取得し、アラートを設定できます。 ただし、 Free サイトと 共有 サイトではスケールアウトがサポートされていないため、異常なインスタンスは自動的に置き換えられません。 2 つ以上のインスタンスにスケールアウトし、正常性チェックの恩恵をすべて受けられるようにするには、Basic レベル以上にスケールアップする必要があります。 運用環境向けアプリケーションでは、アプリの可用性とパフォーマンスが向上するため、この構成をお勧めします。
- App Service プランでは、1 時間あたり最大 1 つの異常なインスタンスを置き換えることができ、最大で 1 日に 3 つのインスタンスを置き換えることができます。
- スケール ユニットごとに、正常性チェックに置き換えられるインスタンスの総数には、構成できる数に制限があります。 この制限に達した場合、異常なインスタンスは置き換えられません。 この値は 12 時間ごとにリセットされます。
よく寄せられる質問
アプリが 1 つのインスタンスで実行されている場合はどうなりますか?
アプリが 1 つのインスタンスだけにスケーリングされていて、異常になった場合、ロード バランサーから削除するとアプリケーションが完全にダウンするため、削除されません。 ただし、異常な ping が 1 時間続いた後、インスタンスは置き換えられます。 正常性チェックの再ルーティングのベネフィットを実現するには、2 つ以上のインスタンスにスケールアウトします。 アプリが 1 つのインスタンスで実行されている場合でも、正常性チェック 監視 機能を使用して、アプリケーションの正常性を追跡できます。
正常性チェック要求が Web サーバーのログに表示されないのはなぜですか?
正常性チェック要求はサイトに内部的に送信されるため、この要求は Web サーバーのログには表示されません。 正常性チェックのコードにログ ステートメントを追加して、正常性チェックのパスで ping が行われたときのログを保持できます。
正常性チェック要求は、HTTP または HTTPS のどちらで送信されますか?
App Service for Windows および Linux では、サイトで [HTTPS のみ] が有効になっている場合、正常性チェック要求は HTTPS 経由で送信されます。 それ以外の場合は、HTTP で送信されます。
正常性チェックは、アプリケーション コードで構成された既定のドメインとカスタム ドメイン間のリダイレクトに従いますか?
いいえ。正常性チェック機能は、Web アプリケーションの既定のドメインのパスに ping を実行します。 既定のドメインからカスタム ドメインへのリダイレクトがある場合、正常性チェックで返される状態コードは 200 になりません。 リダイレクト (301) になります。これはワーカーが異常であることを示します。
同じ App Service プランで複数のアプリがある場合はどうなりますか?
App Service プランに他のアプリがあるかどうかに関係なく、異常なインスタンスはロード バランサーのローテーションから常に削除されます (WEBSITE_HEALTHCHECK_MAXUNHEALTHYWORKERPERCENT で指定されている割合まで)。 インスタンス上のアプリが 1 時間以上異常なままの場合、インスタンスは、正常性チェックが有効になっている他のすべてのアプリも異常な場合にのみ置き換えられます。 正常性チェックが有効になっていないアプリは考慮されません。
例
正常性チェックが有効になっている 2 つのアプリケーション (またはスロットを持つ 1 つのアプリ) があるとします。 これらをアプリ A、アプリ B と呼びます。これらは同じ App Service プランにあり、プランは 4 つのインスタンスにスケールアウトされます。 2 つのインスタンスでアプリ A が異常になると、ロード バランサーによって、それら 2 つのインスタンス上のアプリ A への要求の送信は停止されます。 アプリ B が正常である場合、要求はそれらのインスタンス上のアプリ B にルーティングされます。 それら 2 つのインスタンス上でアプリ A が異常な状態になって 1 時間を超えると、それらのインスタンス上でアプリ B も異常である場合にのみ、それらのインスタンスは置き換えられます。 アプリ B が正常な場合は、インスタンスは置き換えられません。
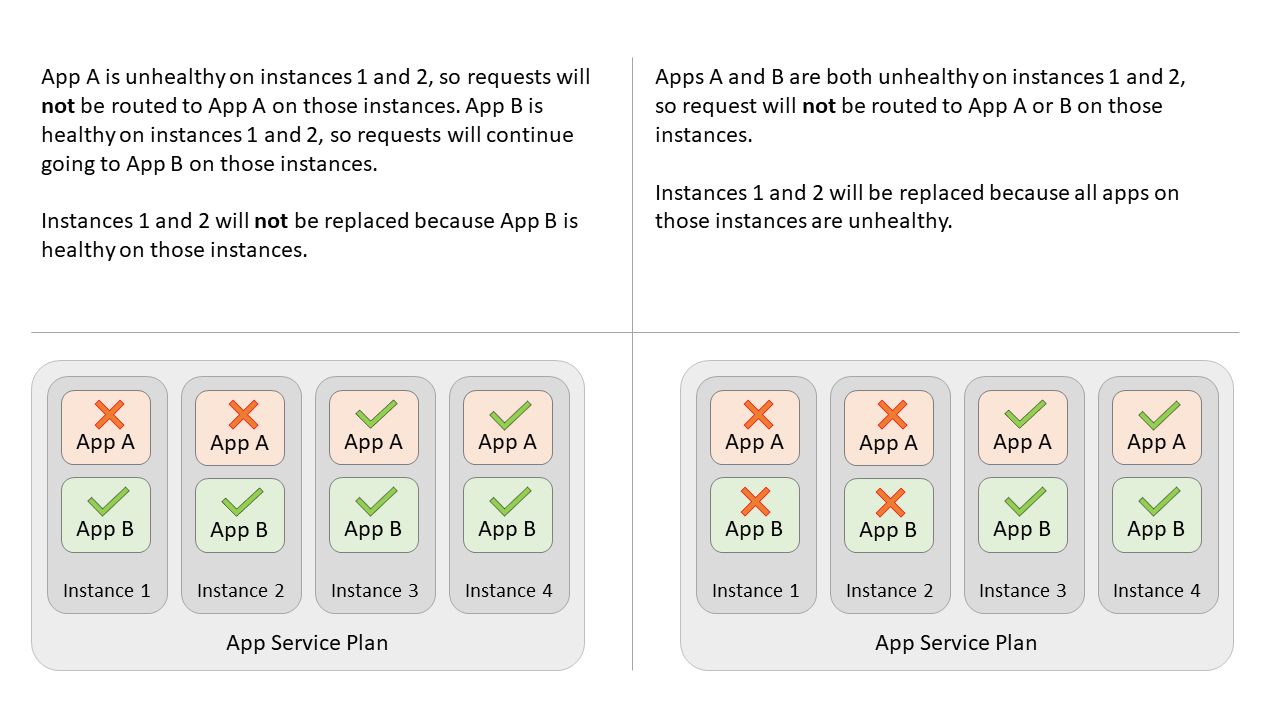
注
正常性チェックが有効になっていない別のサイトまたはスロットがプラン (App C) にある場合、インスタンスの交換については考慮されません。
すべてのインスタンスが異常になった場合はどうなりますか?
アプリケーションのすべてのインスタンスが異常な場合、App Service はロード バランサーからインスタンスを削除しません。 このシナリオでは、すべての異常なアプリ インスタンスがロード バランサーのローテーションから外されると、アプリケーションは実質的に停止します。 ただし、インスタンスの置換は引き続き発生します。
スロット スワップ中の動作
正常性チェックの構成はスロット固有ではないので、スワップ後、スワップされたスロットの正常性チェック構成が宛先スロットに適用されます。その逆も同様です。 たとえば、ステージング スロットの正常性チェックが有効になっている場合、構成されたエンドポイントはスワップ後に運用スロットに適用されます。 可能であれば、スワップ後の予期しない動作を防ぐために、運用スロットと非運用スロットの両方に一貫した構成を使用することをお勧めします。
App Service 環境では正常性チェックは機能しますか?
はい。App Service Environment v3 では正常性チェックを使用できます。