Microsoft Fabric
Azure Data Factory
組織では、通常、さまざまな形式の複数のソースからデータを収集し、1 つ以上のデータ ストアに移動する必要があります。 変換先がソースと同じ種類のデータ ストアではない可能性があり、多くの場合、読み込む前にデータを整形、クリーンアップ、または変換する必要があります。
これらの課題には、さまざまなツール、サービス、プロセスが役立ちます。 方法に関係なく、作業を調整し、データ パイプライン内でデータ変換を適用する必要があります。 以下のセクションでは、これらのタスクの一般的な方法とプラクティスについて説明します。
ETL (抽出、変換、読み込み) プロセス
抽出、変換、読み込み (ETL) は、さまざまなソースのデータを統合されたデータ ストアに統合するデータ統合プロセスです。 変換フェーズでは、特殊化されたエンジンを使用してビジネス ルールに従ってデータが変更されます。 これには多くの場合、データが処理され、最終的に変換先に読み込まれる際にデータを一時的に保持するステージング テーブルが含まれます。

通常、実行されるデータ変換には、フィルター処理、並べ替え、集計、データの結合、データのクリーニング、重複除去、データの検証などのさまざまな操作が含まれます。
多くの場合、3 つの ETL フェーズは、時間を節約するために並列で実行されます。 たとえば、データの抽出中に、変換プロセスは既に受信したデータに対して動作し、読み込み用に準備することができます。読み込みプロセスは、抽出プロセス全体が完了するのを待つのではなく、準備されたデータに対する作業を開始できます。 通常は、書き込みの競合を回避し、べき等の再試行を有効にするために、データ パーティションの境界 (日付、テナント、シャード キー) を中心に並列化を設計します。
関連するサービス:
その他のツール:
ELT (抽出、読み込み、変換)
ELT (抽出、読み込み、変換) が ETL と異なる点は、変換がどこで行われるかという点だけです。 ELT パイプラインでは、変換はターゲット データ ストアで行われます。 独立した変換エンジンを使用する代わりに、ターゲット データ ストアの処理機能がデータ変換に使用されます。 これにより、パイプラインから変換エンジンが除去されるためアーキテクチャがシンプルになります。 このアプローチのもう 1 つの利点は、ターゲット データ ストアをスケーリングすると ELT パイプラインのパフォーマンスもスケーリングされることです。 ただし、ELT が効果的に機能するのは、ターゲット システムが十分に強力でデータを効率的に変換できる場合だけです。

ELT の一般的なユース ケースは、ビッグ データ領域に分類されます。 たとえば、Hadoop 分散ファイル システム (HDFS)、Azure BLOB ストレージ、Azure Data Lake Storage Gen2 などのスケーラブルなストレージ内のフラット ファイルにソース データを抽出することから始めます。 その後、Spark、Hive、PolyBase などのテクノロジを使用して、ソース データのクエリを実行できます。 ELT で重要な点は、変換を実行するために使用するデータ ストアと、データが最終的に使用されるデータ ストアが同じであることです。 このデータ ストアは、データを独自の個別のストレージに読み込むのではなく、スケーラブルなストレージから直接読み取ります。 この方法では、ETL に存在するデータ コピー手順がスキップされます。多くの場合、大規模なデータ セットでは時間がかかる場合があります。 一部のワークロードでは、変換されたテーブルまたはビューを具体化してクエリのパフォーマンスを向上させたり、ガバナンス ルールを適用したりします。ELT は、必ずしも純粋に仮想化された変換を意味するとは限りません。
通常、ELT パイプラインの最終フェーズでは、サポートする必要があるクエリの種類に対してより効率的な形式にソース データが変換されます。 たとえば、データは、一般的にフィルター処理されるキーによってパーティション分割される場合があります。 ELT では、Parquet などの最適化されたストレージ形式を使用することもできます。これは、圧縮、 述語のプッシュダウン、効率的な分析スキャンを有効にするために列ごとにデータを整理する列形式です。
関連する Microsoft サービス:
ETL または ELT の選択
これらの方法の選択は、要件によって異なります。
次の場合に ETL を選択します。
- 制約付きターゲット システムから大量の変換をオフロードする必要がある
- 複雑なビジネス ルールには、特殊な変換エンジンが必要です
- 規制またはコンプライアンス要件では、読み込み前にキュレーションされたステージング監査が義務付けられています
次の場合に ELT を選択します。
- ターゲット システムは、エラスティック コンピューティング スケーリングを備えた最新のデータ ウェアハウスまたはレイクハウスです
- 探索的分析または将来のスキーマの進化のために生データを保持する必要がある
- 変換ロジックは、ターゲット システムのネイティブ機能からメリットを得る
データ フローと制御フロー
データ パイプラインのコンテキストでは、制御フローは一連のタスクが適切な順序で処理されるようにします。 これらのタスクの適切な処理順序を適用するために、優先順位制約が使用されます。 次のイメージに示すように、これらの制約はワークフロー図のコネクタとして考えることができます。 各タスクには、成功、失敗、完了などの結果があります。 後続のタスクは、先行タスクがこれらの結果の 1 つで完了するまで処理を開始しません。
制御フローは、データ フローをタスクとして実行します。 データ フロー タスクでは、データはソースから抽出、変換、またはデータ ストアに読み込まれます。 1 つのデータ フロー タスクの出力を次のデータ フロー タスクへの入力にすることができ、データ フローを並列で実行できます。 制御フローとは異なり、データ フロー内のタスク間に制約を追加することはできません。 ただし、データ ビューアーを追加して、各タスクによって処理されるデータを監視できます。
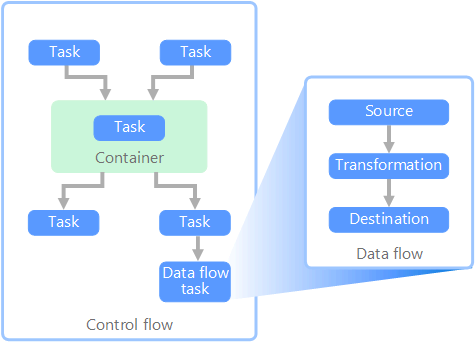
この図では、制御フロー内にいくつかのタスクがあり、そのうちの 1 つはデータ フロー タスクです。 タスクの 1 つはコンテナー内で入れ子になっています。 コンテナーを使用してタスクに構造体を提供し、作業ユニットを提供できます。 このような例の 1 つは、フォルダー内のファイルやデータベース ステートメントなど、コレクション内の要素を繰り返す場合です。
関連するサービス:
リバース ETL
逆 ETL は、変換されたモデル化されたデータを分析システムから運用ツールやアプリケーションに移動するプロセスです。 運用システムから分析にデータを流す従来の ETL とは異なり、逆 ETL では、ビジネス ユーザーが操作できる場所にキュレーションされたデータをプッシュすることで分析情報がアクティブ化されます。 逆 ETL パイプラインでは、データ ウェアハウス、レイクハウス、またはその他の分析ストアから、次のような運用システムにデータが流れます。
- 顧客関係管理 (CRM) プラットフォーム
- マーケティング自動化ツール
- カスタマー サポート システム
- ワークロード データベース
このアプローチは、引き続き抽出、変換、読み込みプロセスに従います。 変換手順では、データ ウェアハウスまたは他の分析システムで使用される特定の形式から変換して、ターゲット システムに合わせます。
例については、 Azure Cosmos DB for NoSQL を使用した逆抽出、変換、および読み込み (ETL) に関 するページを参照してください。
ストリーミング データとホット パスのアーキテクチャ
Lambda ホット パスまたは Kappa アーキテクチャが必要な場合は、データの生成時にデータ ソースをサブスクライブできます。 スケジュールされたバッチ内のデータセットに対して動作する ETL や ELT とは異なり、リアルタイム ストリーミングでは、到着したデータが処理され、すぐに分析情報とアクションが可能になります。

ストリーミング アーキテクチャでは、データはイベント ソースからメッセージ ブローカーまたはイベント ハブ (Azure Event Hubs や Kafka など) に取り込まれた後、ストリーム プロセッサ (Fabric Real-Time Intelligence、Azure Stream Analytics、Apache Flink など) によって処理されます。 プロセッサは、ダッシュボード、アラート、データベースなどのダウンストリーム システムに結果をルーティングする前に、フィルター処理、集計、エンリッチメント、参照データとの結合などの変換を適用します。
このアプローチは、待機時間が短く、継続的な更新が重要なシナリオに最適です。次に例を示します。
- 異常に対する製造設備の監視
- 金融取引における不正行為の検出
- 物流や運用のためのリアルタイム ダッシュボードの活用
- センサーのしきい値に基づいてアラートをトリガーする
ストリーミングの信頼性に関する考慮事項
- チェックポイント処理を使用して、少なくとも 1 回の処理を保証し、障害から復旧する
- 重複する可能性のある処理を処理するべき等の変換を設計する
- 到着遅延イベントと順序外処理の 透かし を実装する
- 処理できないメッセージに配信不能キューを使用する
テクノロジの選択
データ ストア:
パイプラインとオーケストレーション:
- パイプライン オーケストレーション
- Microsoft Fabric Data Factory (モダン オーケストレーション)
- Azure Data Factory (ハイブリッドシナリオと非ファブリック シナリオ)
Lakehouse と最新の分析: