Azure Cosmos DB のようなスキーマのないデータベースでは、非構造化データと半構造化データの格納とクエリを簡単に行うことができますが、パフォーマンス、スケーラビリティ、コストを最適化するためにデータ モデルについて検討してください。
データをどのように格納するか アプリケーションでは、どのようにしてデータを取得し、クエリを実行しますか? アプリケーションでは、読み取りと書き込みのどちらの負荷が高いですか?
この記事を読むと、次の質問に答えることができます。
- データのモデル化とは何か、なぜ考慮する必要があるか。
- Azure Cosmos DB でのデータのモデリングは、リレーショナル データベースとどのように異なるか。
- 非リレーショナル データベースでデータ リレーションシップをどのように表現するか。
- いつデータを埋め込み、いつデータにリンクするか。
JSON の数値
Azure Cosmos DB ではドキュメントが JSON 形式で保存されるため、JSON 形式で格納する前に数値を文字列に変換するかどうかを判断することが重要です。 数値が IEEE (Institute of Electrical and Electronics Engineers) 754 binary64 で定義されている倍精度数値の境界を超える可能性がある場合は、それらの数値をすべて String に変換します。
JSON 仕様では、この境界外の数値の使用は、相互運用性の問題を引き起こすために不適切な方法である理由が説明されています。 パーティション キー列は変更不可能であり、後で変更するにはデータ移行が必要になるため、これらの懸念は特にパーティション キー列に関係します。
データの埋め込み
Azure Cosmos DB でデータをモデル化する場合、エンティティを JSON ドキュメントとして表される 自己完結型の項目 として扱います。
比較のために、まずはリレーショナル データベースのデータをモデル化する方法を見てみましょう。 次の例は、ある個人がどのようにリレーショナル データベースに格納されるかを示しています。
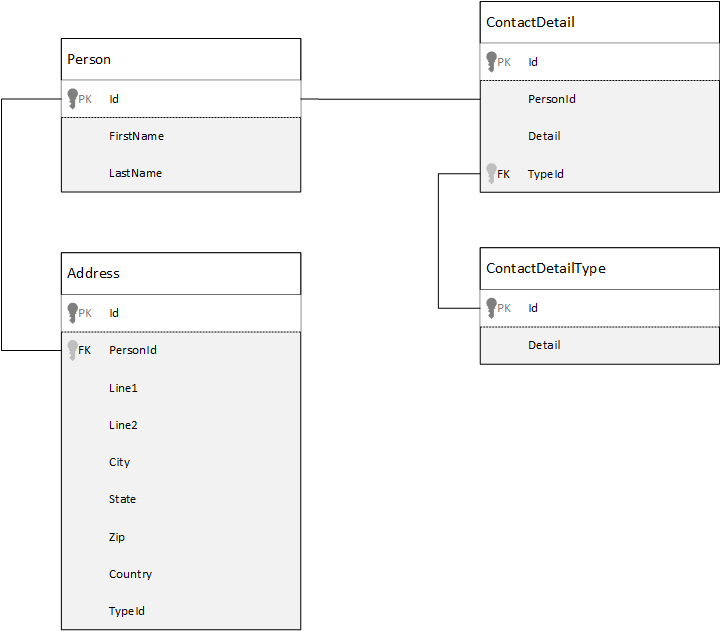
リレーショナル データベースを使用する場合の方法は、データをすべて正規化することです。 データの正規化には通常、個人などのエンティティを取得し、個別のコンポーネントに分解する操作が含まれます。 その例では、1 人に対して複数の連絡先詳細レコードと複数の住所レコードが存在する可能性があります。 種類などの共通フィールドを抽出すると、連絡先の詳細をさらに分割できます。 同じ方法が住所にも適用されます。 各レコードは、"自宅" または "職場" として分類できます。
データを正規化する際の指針となる前提は、各レコードに冗長なデータを保存することを避け、代わりにデータを参照することです。 この例で、すべての連絡先詳細と住所を含む個人のデータを読み取るには、JOIN を使用して実行時にデータを効率的に作成し直す (非正規化する) 必要があります。
SELECT p.FirstName, p.LastName, a.City, cd.Detail
FROM Person p
JOIN ContactDetail cd ON cd.PersonId = p.Id
JOIN ContactDetailType cdt ON cdt.Id = cd.TypeId
JOIN Address a ON a.PersonId = p.Id
1 人の人物の連絡先の詳細と住所を更新するには、多数の個別のテーブルに対する書き込み操作が必要です。
では、同じデータを Azure Cosmos DB 内の自己完結型エンティティとしてモデル化する方法を見ていきましょう。
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"addresses": [
{
"line1": "100 Some Street",
"line2": "Unit 1",
"city": "Seattle",
"state": "WA",
"zip": 98012
}
],
"contactDetails": [
{"email": "thomas@andersen.com"},
{"phone": "+1 555 555-5555", "extension": 5555}
]
}
このアプローチを使用して、連絡先の詳細や住所など、その人物に関連するすべての情報を "単一の JSON" ドキュメントに埋め込むことで、人物レコードを非正規化しました。 また、固定スキーマに限定されているわけではないので、まったく別の形で連絡先詳細を含めるような柔軟性もあります。
データベースから完全な人物レコードを取得するのは、単一の項目の単一のコンテナーに対する 1 回の読み取り操作になりました。 個人レコードの連絡先詳細や住所を更新することも、1 つの項目に対する 1 回の書き込み操作です。
データを非正規化すると、アプリケーションで一般的な操作を完了するために必要なクエリと更新の回数が少なくなる可能性があります。
埋め込みをする場合
一般に、埋め込みデータ モデルを使用するのは次のような場合です。
- エンティティ間に 包含された リレーションシップがある場合。
- エンティティ間にone-to-fewの関係があります。
- データの変更頻度が低い。
- データは際限なく増加しない。
- データは頻繁にまとめて照会される。
注
通常、非正規化データ モデルでは 読み取り パフォーマンスが向上します。
埋め込みをすべきでない場合
Azure Cosmos DB での経験則では、すべてを非正規化し、すべてのデータを 1 つの項目に埋め込むことになりますが、この方法は、回避すべき状況を招く危険性があります。
この JSON スニペットを見てください。
{
"id": "1",
"name": "What's new in the coolest Cloud",
"summary": "A blog post by someone real famous",
"comments": [
{"id": 1, "author": "anon", "comment": "something useful, I'm sure"},
{"id": 2, "author": "bob", "comment": "wisdom from the interwebs"},
…
{"id": 100001, "author": "jane", "comment": "and on we go ..."},
…
{"id": 1000000001, "author": "angry", "comment": "blah angry blah angry"},
…
{"id": ∞ + 1, "author": "bored", "comment": "oh man, will this ever end?"},
]
}
この例は、一般的なブログやコンテンツ管理システム (CMS) をモデル化する場合に、コメントが埋め込まれた投稿エンティティがどのように見えるかを示したものです。 この例の問題点は、コメントの配列が無制限であること、つまり、1 つの投稿に付けることができるコメントの数に実質的な制限がないことです。 この設計では、項目のサイズが無限に大きくなる可能性があり、問題が発生する可能性があるため、回避する必要があります。
項目のサイズが大きくなると、大規模なデータの送信、読み取り、更新がより困難になります。
このような場合は、次のデータ モデルを検討することをお勧めします。
Post item:
{
"id": "1",
"name": "What's new in the coolest Cloud",
"summary": "A blog post by someone real famous",
"recentComments": [
{"id": 1, "author": "anon", "comment": "something useful, I'm sure"},
{"id": 2, "author": "bob", "comment": "wisdom from the interwebs"},
{"id": 3, "author": "jane", "comment": "....."}
]
}
Comment items:
[
{"id": 4, "postId": "1", "author": "anon", "comment": "more goodness"},
{"id": 5, "postId": "1", "author": "bob", "comment": "tails from the field"},
...
{"id": 99, "postId": "1", "author": "angry", "comment": "blah angry blah angry"},
{"id": 100, "postId": "2", "author": "anon", "comment": "yet more"},
...
{"id": 199, "postId": "2", "author": "bored", "comment": "will this ever end?"}
]
このモデルには、コメントごとに、投稿識別子を含むプロパティを持つ項目があります。 このモデルを使用すると、投稿に任意の数のコメントを含めることができ、効率的に増大させることができます。 最新のコメント以外も見たいというユーザーは、このコンテナーに対して、コメント コンテナーのパーティション キーとなる postId を渡してクエリを実行することになります。
データの埋め込みが適切ではないもう 1 つのケースは、埋め込まれたデータが複数の項目間で頻繁に使用され、変更頻度が高い場合です。
この JSON スニペットを見てください。
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"holdings": [
{
"numberHeld": 100,
"stock": { "symbol": "zbzb", "open": 1, "high": 2, "low": 0.5 }
},
{
"numberHeld": 50,
"stock": { "symbol": "xcxc", "open": 89, "high": 93.24, "low": 88.87 }
}
]
}
この例は、ある個人の株式ポートフォリオを表したものです。 各ポートフォリオ ドキュメントに株式情報を埋め込むことにしました。 関連データが頻繁に変更される環境では、頻繁に変更されるデータを埋め込むということは、各ポートフォリオを常に更新することを意味します。 株式取引アプリケーションの例を使用すると、株式が取引されるたびに各ポートフォリオ項目を更新することになります。
株式 zbzb は 1 日に何百回も取引される可能性があり、何千人ものユーザーがポートフォリオに zbzb を保有する可能性があります。 この例のようなデータ モデルでは、システムは何千ものポートフォリオ ドキュメントを毎日何度も更新する必要があり、うまくスケーリングされません。
参照データ
データの埋め込みは、多くの場合うまく機能しますが、データを非正規化すると、価値よりも問題の方が多くなるシナリオがあります。 では、どうすればよいでしょうか?
リレーショナル データベースだけでなくドキュメント データベースでも、エンティティ間のリレーションシップを作成できます。 ドキュメント データベースでは、1 つの項目に、他の複数のドキュメント内のデータに関連付ける情報を含めることができます。 Azure Cosmos DB は、リレーショナル データベースのような複雑なリレーションシップ用に設計されていませんが、項目間の単純なリンクが可能であり、役立つ場合があります。
JSON では、先ほどの株式ポートフォリオの例を使用しますが、今回はポートフォリオ内の株式項目を埋め込むのではなく参照します。 これにより、株式項目が終日頻繁に変更される場合でも、更新する必要がある項目は 1 つの株式ドキュメントのみです。
Person document:
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"holdings": [
{ "numberHeld": 100, "stockId": 1},
{ "numberHeld": 50, "stockId": 2}
]
}
Stock documents:
{
"id": "1",
"symbol": "zbzb",
"open": 1,
"high": 2,
"low": 0.5,
"vol": 11970000,
"mkt-cap": 42000000,
"pe": 5.89
},
{
"id": "2",
"symbol": "xcxc",
"open": 89,
"high": 93.24,
"low": 88.87,
"vol": 2970200,
"mkt-cap": 1005000,
"pe": 75.82
}
このアプローチの欠点の 1 つは、個人のポートフォリオ内の各株式に関する情報を取得するために、アプリケーションで複数のデータベース要求を実行する必要があることです。 この設計により、更新が頻繁に行われるため、データの書き込みが高速化されます。 ただし、データの読み取りやクエリの速度は低下しますが、このシステムではそれほど重要ではありません。
注
正規化されたデータ モデルは、サーバーに より多くのラウンド トリップを要求する可能性があります 。
外国キーについてはどうですか?
外部キーなどの制約の概念がないため、データベースはドキュメント内のドキュメント間のリレーションシップを検証しません。これらのリンクは実質的に "弱い" ものになります。項目が参照しているデータが実際に存在することを確認する場合は、この手順をアプリケーションで実行するか、または Azure Cosmos DB でサーバー側トリガーまたはストアド プロシージャを使用して実行する必要があります。
参照を使用する場合
一般に、次のような場合に正規化されたデータ モデルを使用します。
- 一対多 リレーションシップを表している。
- 多対多 リレーションシップを表している。
- 関連するデータが 頻繁に変更される。
- 参照されるデータに 制限がない可能性がある。
注
通常は、正規化により 書き込み パフォーマンスが向上します。
リレーションシップの場所
リレーションシップの増加は、どの項目に参照を格納するかを決定するのに役立ちます。
発行元と書籍をモデル化する、JSON を見てみましょう。
Publisher document:
{
"id": "mspress",
"name": "Microsoft Press",
"books": [ 1, 2, 3, ..., 100, ..., 1000]
}
Book documents:
{"id": "1", "name": "Azure Cosmos DB 101" }
{"id": "2", "name": "Azure Cosmos DB for RDBMS Users" }
{"id": "3", "name": "Taking over the world one JSON doc at a time" }
...
{"id": "100", "name": "Learn about Azure Cosmos DB" }
...
{"id": "1000", "name": "Deep Dive into Azure Cosmos DB" }
出版社あたりの書籍数が少なく、増加が限られている場合は、出版社項目内に書籍参照を格納すると有用な場合があります。 ただし、発行元あたりの書籍数に制限がない場合は、このデータ モデルは発行元ドキュメントに示すような、拡大し続ける可変配列になります。
構造を切り替えると、同じデータを表すモデルが生成されますが、大規模の変更可能なコレクションは回避されます。
Publisher document:
{
"id": "mspress",
"name": "Microsoft Press"
}
Book documents:
{"id": "1","name": "Azure Cosmos DB 101", "pub-id": "mspress"}
{"id": "2","name": "Azure Cosmos DB for RDBMS Users", "pub-id": "mspress"}
{"id": "3","name": "Taking over the world one JSON doc at a time", "pub-id": "mspress"}
...
{"id": "100","name": "Learn about Azure Cosmos DB", "pub-id": "mspress"}
...
{"id": "1000","name": "Deep Dive into Azure Cosmos DB", "pub-id": "mspress"}
この例では、出版社ドキュメントに無制限のコレクションが含まれなくなりました。 代わりに、各書籍ドキュメントには、その出版社への参照が含まれます。
多対多のリレーションシップはどのようにモデル化しますか?
リレーショナル データベースでは、多くの場合、多対多リレーションシップは結合テーブルを使用してモデル化されます。 これらのリレーションシップは、他のテーブルのレコードを結合するだけです。

ドキュメントを使用して同じ内容を複製し、次の例のようなデータ モデルを作成したくなるかもしれません。
Author documents:
{"id": "a1", "name": "Thomas Andersen" }
{"id": "a2", "name": "William Wakefield" }
Book documents:
{"id": "b1", "name": "Azure Cosmos DB 101" }
{"id": "b2", "name": "Azure Cosmos DB for RDBMS Users" }
{"id": "b3", "name": "Taking over the world one JSON doc at a time" }
{"id": "b4", "name": "Learn about Azure Cosmos DB" }
{"id": "b5", "name": "Deep Dive into Azure Cosmos DB" }
Joining documents:
{"authorId": "a1", "bookId": "b1" }
{"authorId": "a2", "bookId": "b1" }
{"authorId": "a1", "bookId": "b2" }
{"authorId": "a1", "bookId": "b3" }
このアプローチは機能しますが、著者とその書籍、または書籍とその著者を読み込むには、常に少なくとも 2 つの追加のデータベース クエリが必要になります。 1 つは、結合している項目に対するクエリで、もう 1 つは、結合されている実際の項目をフェッチするクエリです。
この結合による処理が 2 つのデータ要素を結合することだけであれば、これを完全になくしたらどうでしょうか。 下記の例を検討してください。
Author documents:
{"id": "a1", "name": "Thomas Andersen", "books": ["b1", "b2", "b3"]}
{"id": "a2", "name": "William Wakefield", "books": ["b1", "b4"]}
Book documents:
{"id": "b1", "name": "Azure Cosmos DB 101", "authors": ["a1", "a2"]}
{"id": "b2", "name": "Azure Cosmos DB for RDBMS Users", "authors": ["a1"]}
{"id": "b3", "name": "Learn about Azure Cosmos DB", "authors": ["a1"]}
{"id": "b4", "name": "Deep Dive into Azure Cosmos DB", "authors": ["a2"]}
このモデルを使用すると、著者のドキュメントを見て、著者がどの書籍を書いたかを簡単に知ることができます。 また、書籍ドキュメントをチェックして、書籍をどの著者が書いたかを確認することもできます。 個別の結合テーブルを使用したり、追加のクエリを実行したりする必要はありません。 このモデルを使用すると、アプリケーションで必要なデータを迅速かつ簡単に取得できます。
ハイブリッド データ モデル
データの埋め込み (または非正規化) と参照 (または正規化) について調べてみましょう。 各アプローチには利点がありますが、トレードオフも伴います。
必ずしもどちらか一方を選ぶ必要はありません。 ためらわずに、少しずつ混在させてみましょう。
アプリケーション固有の使用パターンとワークロードに基づいて、埋め込みデータと参照データを混在させることが合理的な場合があります。 このアプローチを使用すると、アプリケーション ロジックを簡略化し、サーバーのラウンド トリップを削減し、優れたパフォーマンスを維持することができます。
以下の JSON を検討してみてください。
Author documents:
{
"id": "a1",
"firstName": "Thomas",
"lastName": "Andersen",
"countOfBooks": 3,
"books": ["b1", "b2", "b3"],
"images": [
{"thumbnail": "https://....png"}
{"profile": "https://....png"}
{"large": "https://....png"}
]
},
{
"id": "a2",
"firstName": "William",
"lastName": "Wakefield",
"countOfBooks": 1,
"books": ["b1"],
"images": [
{"thumbnail": "https://....png"}
]
}
Book documents:
{
"id": "b1",
"name": "Azure Cosmos DB 101",
"authors": [
{"id": "a1", "name": "Thomas Andersen", "thumbnailUrl": "https://....png"},
{"id": "a2", "name": "William Wakefield", "thumbnailUrl": "https://....png"}
]
},
{
"id": "b2",
"name": "Azure Cosmos DB for RDBMS Users",
"authors": [
{"id": "a1", "name": "Thomas Andersen", "thumbnailUrl": "https://....png"},
]
}
ここでは、(主に) 埋め込みモデルに従っています。この埋め込みモデルでは、他のエンティティのデータは最上位のドキュメントに埋め込まれていますが、その他のデータは参照されています。
書籍ドキュメントを見ると、作者の配列にいくつか興味深いフィールドがあります。 正規化されるモデルでの標準的な手法として、戻って作者ドキュメントを参照するために使用するフィールドである id フィールドがありますが、name と thumbnailUrl もあります。
id のみを使用し、アプリケーションで "リンク" を使用して、対応する著者項目から必要な追加情報を取得することができます。ただし、アプリケーションでは、書籍ごとに著者の名前とサムネイルが表示されるため、著者の一部のデータを非正規化すると、リスト内の書籍あたりのサーバー ラウンド トリップの数が削減されます。
著者の名前が変更された場合、または著者の写真が更新された場合、その著者が出版したすべての書籍を更新する必要があります。 ただし、このアプリケーションの場合、著者が名前を変更することはほとんどないと仮定すると、この妥協は、許容できる設計上の決定です。
この例では、読み取り操作中にコストのかかる処理を節約するために、事前に計算された集計の値があります。 この例では、著者項目に埋め込まれるデータの一部は、実行時に算出されるデータです。 新しい書籍が出版されるたびに、書籍項目が作成され、かつcountOfBooks フィールドは、特定の著者用に存在する書籍ドキュメントの数に基づいて算出値に設定されます。 この最適化は、読み取りの負荷が高く、読み取りを最適化するために書き込み時に計算を実行する余裕のあるシステムに適しています。
モデルに事前計算フィールドを含める機能は、Azure Cosmos DB がマルチドキュメント トランザクションをサポートしていることにより実現されています。 多くの NoSQL ストアでは、ドキュメント間でトランザクションを実行できないため、この制限のために "常にすべてを埋め込む" などの設計上の決定が推奨されます。 Azure Cosmos DB では、ACID トランザクション内で書籍の挿入や作者の更新をすべて実行する、サーバー側トリガー、またはストアド プロシージャを使用できます。 これで、データの整合性を確実に維持するために、すべてを 1 つの項目に埋め込む必要はなくなります。
異なる種類の項目を区別する
一部のシナリオでは、同じコレクション内に異なる種類の項目を混在させることが必要な場合があります。この設計上の選択は、通常、複数の関連ドキュメントを同じパーティションに配置する場合に当てはまります。 たとえば、書籍とブック レビューを同じコレクションに入れて、bookId でパーティション分割することができます。 このような状況では、通常、ドキュメントを区別するために、その種類を識別するフィールドをドキュメントに追加します。
Book documents:
{
"id": "b1",
"name": "Azure Cosmos DB 101",
"bookId": "b1",
"type": "book"
}
Review documents:
{
"id": "r1",
"content": "This book is awesome",
"bookId": "b1",
"type": "review"
}
{
"id": "r2",
"content": "Best book ever!",
"bookId": "b1",
"type": "review"
}
Azure Synapse Link と Azure Cosmos DB 分析ストアのためのデータ モデリング
Azure Synapse Link for Azure Cosmos DB は、クラウド ネイティブのハイブリッド トランザクションと分析処理 (HTAP) の機能です。これを使用すると、Azure Cosmos DB のオペレーショナル データに対してリアルタイムに近い分析を実行できます。 Azure Synapse Link によって、Azure Cosmos DB と Azure Synapse Analytics の間にシームレスな統合が作成されます。
この統合は、Azure Cosmos DB 分析ストアを通じて行われます。これは、トランザクション データの列形式の表現であり、トランザクション ワークロードに影響を与えることなく大規模な分析を可能にします。 この分析ストアを使用すると、大規模なデータ セットに対して迅速かつ低コストでクエリを実行できます。 データをコピーしたり、メイン データベースの速度低下を心配したりする必要はありません。 コンテナーの分析ストアを有効にすると、データに加えたすべての変更が、ほぼすぐに分析ストアにコピーされます。 変更フィードを設定したり、抽出、変換、読み込み (ETL) ジョブを実行したりする必要はありません。 システムは両方のストアの同期状態を保ちます。
Azure Synapse Link の使用時には、Azure Synapse Analytics からお使いの Azure Cosmos DB コンテナーに直接接続し、要求ユニット コストなしで分析ストアにアクセスできるようになりました。 Azure Synapse Analytics では、現在、Synapse Apache Spark およびサーバーレス SQL プールとの Azure Synapse Link がサポートされています。 グローバルに分散された Azure Cosmos DB アカウントがある場合、コンテナーの分析ストアを有効にした後、そのアカウントのすべてのリージョンでそれを使用できるようになります。
分析ストアの自動スキーマ推論
Azure Cosmos DB トランザクション ストアは行指向の半構造化データですが、分析ストアでは列形式の構造化形式が使用されます。 この変換は、分析ストアのスキーマ推論規則を使用して、ユーザーのために自動的に行われます。 この変換プロセスには、入れ子になったレベルの最大数、プロパティの最大数、サポートされないデータ型などの制限があります。
注
分析ストアのコンテキストでは、次の構造がプロパティと見なされます。
- JSON の "要素" または "
:で区切られた文字列と値のペア" -
{と}で区切られた JSON オブジェクト -
[と]で区切られた JSON 配列
以下の手法を使用して、スキーマ推論変換の影響を最小限に抑え、分析機能を最大限に活用することができます。
正規化
Azure Synapse Link では T-SQL または Spark SQL を使用してコンテナーを結合できるため、正規化はあまり関係ありません。 正規化の期待される利点は以下のとおりです。
- トランザクション ストアと分析ストアの両方でデータ フットプリントがより小さくなる。
- トランザクションがより小さくなる。
- ドキュメントあたりのプロパティを少なくする。
- データ構造で、入れ子になったレベルがより少なくなる。
プロパティが少なく、データのレベルが少ないほど、分析クエリは高速になります。 また、データのすべての部分が確実に分析ストアに含まれるようにするためにも役立ちます。 自動スキーマ推論規則に関する記事で説明したように、分析ストアで表現されるレベルとプロパティの数には制限があります。
正規化についての別の重要な要因は、Azure Synapse の SQL サーバーレス プールでは最大 1,000 列の結果セットがサポートされており、入れ子になった列の公開時にも、その制限に向けてカウントが進むという点です。 言い換えると、分析ストアと Synapse SQL サーバーレス プールの両方に、プロパティ数は 1,000 個という制限があります。
しかし、非正規化は Azure Cosmos DB の重要なデータ モデリング手法であるのに、どうすべきなのでしょうか。 実際のトランザクション ワークロードと分析ワークロードに適したバランスを見つける必要がある、というのがその答えです。
パーティション キー
Azure Cosmos DB のパーティション キー (PK) は分析ストアでは使用されません。 そして、分析ストアのカスタム パーティション分割を利用し、必要な任意の PK を使用して分析ストアのコピーを作成できるようになっています。 この分離により、データ インジェストとポイント読み取りに重点を置いてトランザクション データの PK を選択できます。その一方、クロス パーティション クエリは、Azure Synapse Link を使用して実行できます。 例を見てみましょう。
架空のグローバル IoT シナリオでは、すべてのデバイスで同様の量のデータが生成されるため、device id は適切なパーティション キーとして機能し、ホット パーティションの問題を防ぎます。 ただし、"昨日のすべてのデータ" や "都市ごとの合計" など、複数のデバイスのデータを分析する場合、これらのクエリはクロスパーティション クエリであるため、問題が発生する可能性があります。 それらのクエリは、実行のために要求ユニットのスループットの一部を使用するので、トランザクションのパフォーマンスを低下させるおそれがあります。 しかし Azure Synapse Link の利用時には、これらの分析クエリを要求ユニット コストなしで実行できます。 分析ストアの列形式は分析クエリ用に最適化されており、Azure Synapse Link は Azure Synapse Analytics ランタイムで優れたパフォーマンスをサポートします。
データ型とプロパティ名
自動スキーマ推論規則に関する記事に、サポートされているデータ型の一覧が記載されています。 Azure Synapse ランタイムでは、サポートされているデータ型が異なる方法で処理される場合があり、サポートされていないデータ型は分析ストアでの表現を妨げます。 1 つの例を示します。ISO 8601 UTC 標準に従う DateTime 文字列を使用する場合、Azure Synapse の Spark プールはこれらの列を string として表し、Azure Synapse の SQL サーバーレス プールはこれらの列を varchar(8000)として表します。
もう 1 つの課題は、すべての文字が Azure Synapse Spark で受け入れられるわけではないということです。 空白は受け付けられますが、コロン、グレーブ アクセント、コンマのような文字は受け付けられません。 たとえば、項目に "First Name, Last Name" という名前のプロパティがあるとします。 このプロパティは分析ストアでは表現されて、Synapse SQL サーバーレス プールでは問題なく読み取ることができます。 しかし、それは分析ストア内にあるため、Azure Synapse Spark では、他のすべてのプロパティを含め、分析ストアからどのデータも読み取ることができません。 1 日の終わりに、サポートされていない文字が名前で使用されているプロパティが 1 つあると、Azure Synapse Spark を使用することができません。
データのフラット化
Azure Cosmos DB データの最上位レベルのすべてのプロパティは、分析ストア内の列になります。 入れ子になったオブジェクト内または配列内のプロパティは、JSON として分析ストアに格納され、構造が維持されます。 入れ子になった構造では、構造化されていない形式でデータをフラット化するために、Azure Synapse ランタイムによる追加の処理が必要になります。これは、ビッグ データ のシナリオで問題になる可能性があります。
分析ストアには、項目の 2 つの列 (id と contactDetails) しかありません。 その他のデータ (email と phone) は、SQL 関数を使用して個別に読み取るための追加の処理が必要です。
{
"id": "1",
"contactDetails": [
{"email": "thomas@andersen.com"},
{"phone": "+1 555 555-5555"}
]
}
分析ストアには、項目の 3 つの列 (id、email、phone) があります。 すべてのデータは、列として直接アクセスできます。
{
"id": "1",
"email": "thomas@andersen.com",
"phone": "+1 555 555-5555"
}
データの階層化
Azure Synapse Link を使用すると、以下の観点からコストを削減できます。
- トランザクション データベースで実行されるクエリの数が少なくなります。
- データ インジェストとポイント読み取りに最適化された PK により、データ フットプリント、ホット パーティション シナリオ、パーティション分割が減少します。
- 分析有効期限 (attl) がトランザクション有効期限 (tttl) とは独立しているためにデータが階層化されます。 トランザクション データはトランザクション ストアに数日、数週間、数か月保管し、データは分析ストアに何年もの間、または長い間保管することができます。 分析ストアの列形式では、自然なデータ圧縮が 50% から 90% までに達します。 また、GB あたりのそのコストは、トランザクション ストアの実際の価格の約 10% です。 現在のバックアップの制限事項の詳細については、分析ストアの概要に関するページを参照してください。
- 環境内で実行されている ETL ジョブはありません。つまり、要求ユニットを割り当てる必要はありません。
制御された冗長性
この手法は、データ モデルが既に存在しており、変更できない場合に最適な代替手段です。 現在のデータ モデルは、分析ストアではうまく機能しません。 この利点があるのは、分析ストアには、データを入れ子にできるレベルの数と、各ドキュメントに含めることができるプロパティの数を制限するルールがあるためです。 データが複雑すぎる場合、またはフィールドが多すぎる場合は、一部の重要な情報が分析ストアに含まれない可能性があります。 このシナリオに該当する場合、Azure Cosmos DB 変更フィード を使用してデータを別のコンテナーにレプリケートし、Azure Synapse Link の使いやすいデータ モデルに必要な変換を適用できます。 例を見てみましょう。
シナリオ
コンテナー CustomersOrdersAndItems は、顧客や商品の詳細 (請求先住所、配送先住所、配送方法、配送状況、商品価格など) を含むオンライン注文を格納するために使用されます。最初の 1,000 個のプロパティだけが表現されて、重要な情報が分析ストアに含まれていないので、Azure Synapse Link の使用が妨げられます。 コンテナーにはペタバイトのレコードがあり、アプリケーションを変更してデータを再モデル化することはできません。
問題のもう 1 つの側面は、大量のデータです。 何十億行もの行が絶えず分析部門によって使用され、それによって、古いデータの削除のために tttl を使用することができなくなっています。 分析ニーズのためにトランザクション データベースでデータ履歴全体を維持すると、絶えず要求ユニットのプロビジョニングを増やさなければならず、コストに影響します。 トランザクションと分析のワークロードが、同時に同じリソースを求めて競合しています。
何を実行できるか
変更フィードを使用したソリューション
- エンジニアリング チームは、変更フィードを使用して、3 つの新しいコンテナー
Customers、Orders、Itemsを作成することを決定しました。 変更フィードを使用すると、データは正規化され、フラット化されます。 不要な情報はデータ モデルから削除され、各コンテナーのプロパティ数は 100 近くとなり、自動スキーマ推論の制限によるデータ損失が回避されます。 - これらの新しいコンテナーでは分析ストアが有効になっており、分析部門は Synapse Analytics を使用してデータを読み取ります。 これにより、Synapse Apache Spark プールとサーバーレス SQL プールで分析クエリが実行されるため、要求ユニットの使用量が削減されます。
- コンテナー
CustomersOrdersAndItemsの有効期限 (TTL) が、データを 6 か月間のみ保持するように設定されるようになりました。これにより、Azure Cosmos DB には GB あたり少なくとも 1 つの要求ユニットがあるため、要求ユニットの使用量をさらに削減できます。 データが少なくなるほど、要求ユニットが少なくなります。
学んだこと
この記事の最も重要なポイントは、スキーマのないシナリオでのデータ モデリングがこれまでと同じくらい重要であるということです。
データの要素を画面で表現する方法が 1 つではないように、データをモデル化する方法も 1 つではありません。 アプリケーションと、アプリケーションでデータの生成、使用、処理を行う方法を理解する必要があります。 ここで示すガイドラインを適用すると、アプリケーションの当面のニーズに対応するモデルを作成できます。 アプリケーションが変更された場合、スキーマのないデータベースの柔軟性を使用して、データ モデルを簡単に適応および進化させることができます。