このページでは、Azure Databricks が Lakeguard を使用して共有コンピューティング環境でユーザー分離を適用し、専用コンピューティングできめ細かなアクセス制御を適用する方法について説明します。
Lakeguard とは
Lakeguard は Databricks 上の一連のテクノロジであり、コードの分離とデータ フィルター処理を適用することで、複数のユーザーが同じコンピューティング リソースを安全かつコスト効率よく共有し、特権を持つマシン アクセスを提供するコンピューティング上できめ細かなアクセス制御を行ってデータにアクセスできます。
Lakeguard のしくみ
標準のクラシック コンピューティング、サーバーレス コンピューティング、SQL ウェアハウスなどの共有コンピューティング環境では、Lakeguard は Spark エンジンや他のユーザーからユーザー コードを分離します。 この設計により、多くのユーザーが同じコンピューティング リソースを共有しながら、ユーザー、Spark ドライバー、Executor の間で厳密な境界を維持できます。
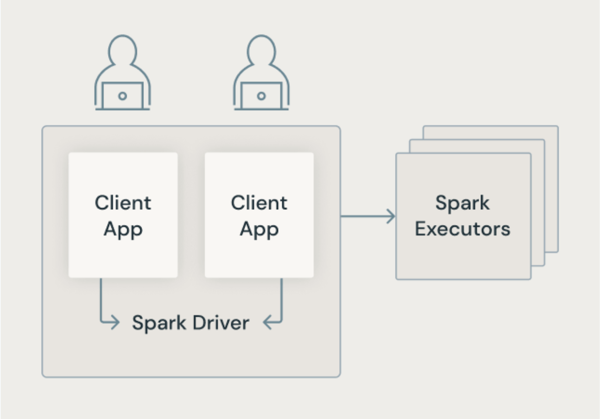
クラシック Spark アーキテクチャ
次の図は、従来の Spark アーキテクチャで、ユーザー アプリケーションが基になるマシンへの特権アクセスを持つ JVM を共有する方法を示しています。
Lakeguard アーキテクチャ
Lakeguard は、セキュリティで保護されたコンテナーを使用して、すべてのユーザー コードを分離します。 これにより、ユーザー間の厳密な分離を維持しながら、複数のワークロードを同じコンピューティング リソースで実行できます。
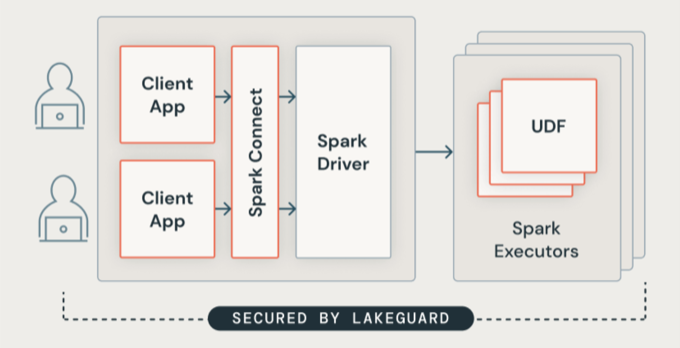
Spark クライアントの分離
Lakeguard は、次の 2 つの主要コンポーネントを使用して、クライアント アプリケーションを Spark ドライバーから分離し、互いに分離します。
Spark Connect: Lakeguard では、Spark Connect (Apache Spark 3.4 で導入) を使用して、クライアント アプリケーションをドライバーから切り離します。 クライアント アプリケーションとドライバーが同じ JVM またはクラスパスを共有しなくなりました。 この分離により、未承認のデータ アクセスが防止されます。 この設計では、クエリに行レベルまたは列レベルのフィルターが含まれている場合に、ユーザーが過剰フェッチの結果として得られるデータにアクセスすることもできなくなります。
コンテナーのサンドボックス化: 各クライアント アプリケーションは、独自の分離されたコンテナー環境で実行されます。 これにより、ユーザー コードが他のユーザーのデータや基になるコンピューターにアクセスできなくなります。 サンドボックスでは、コンテナーベースの分離手法を使用して、ユーザー間にセキュリティで保護された境界を作成します。
UDF の分離
既定では、Spark Executor は UDF を分離しません。 この分離の欠如により、UDF がファイルを書き込んだり、基になるマシンにアクセスしたりできるようになります。
Lakeguard は、ユーザー定義コード (UDF を含む) を Spark Executor 上で次の方法で分離します。
- Spark Executor での実行環境のサンドボックス化。
- UDF からエグレス ネットワーク トラフィックを分離して、承認されていない外部アクセスを防ぎます。
- ユーザーが必要なライブラリにアクセスできるように、UDF サンドボックスにクライアント環境をレプリケートする。
この分離は、標準コンピューティング上の UDF と、サーバーレス コンピューティングおよび SQL ウェアハウス上の Python UDF に適用されます。