この記事では、大規模な言語モデル (LLM) が追加のデータを使用してより良い回答を提供する方法について説明します。 既定では、LLM はトレーニング中に学習した内容のみを認識します。 リアルタイムまたはプライベート データを追加して、より便利にすることができます。
この追加データを追加するには、主に次の 2 つの方法があります。
- 取得拡張生成 (RAG): セマンティック検索とコンテキスト プライミングを使用して、モデルが回答する前に役立つ情報を見つけて追加します。 詳細については、 生成型 AI ソリューションを構築するための主要な概念と考慮事項に関するページを参照してください。
- 微調整: 特定のタスクやトピックで適切になるように、より小さな特定のデータセットに LLM を再トレーニングします。
次のセクションでは、両方のメソッドについて説明します。
RAG について理解する
RAG を使用すると、"自分のデータに対するチャット" という重要なシナリオが可能になります。 このシナリオでは、ドキュメント、ドキュメント、その他の独自のデータなど、テキスト コンテンツの大規模なコーパスが組織に含まれる可能性があります。 このコーパスは、ユーザー プロンプトに対する回答の基礎として使用されます。
RAG を使用すると、独自のドキュメントを使用して質問に回答するチャットボットを作成できます。 ここでは、そのしくみを示します:
- ドキュメント (またはそれらの一部をチャンクと呼ばれる) をデータベースに格納する
- 各チャンクの 埋め込みを 作成します。それを説明する数値の一覧
- 誰かが質問をすると、システムは同様のチャンクを見つけます
- 関連するチャンクと質問を LLM に送信して回答を作成する
ベクトル化されたドキュメントのインデックスの作成
まず、ベクター データ ストアを構築します。 このストアは、各ドキュメントまたはチャンクの埋め込みを保持します。 次の図は、ドキュメントのベクター化インデックスを作成する主な手順を示しています。

この図は 、データ パイプラインを示しています。 このパイプラインは、データを取り込み、処理し、システム用に管理します。 また、ベクター データベース内のストレージ用にデータを準備し、LLM に適した形式であることを確認します。
埋め込みによってプロセス全体が駆動されます。 埋め込みは、単語、文、またはドキュメントの意味を表す数値のセットであり、機械学習モデルで使用できます。
埋め込みを作成する 1 つの方法は、コンテンツを Azure OpenAI Embeddings API に送信することです。 この API は、ベクトル (数値のリスト) を返します。 各数値は、トピック、意味、文法、スタイルなど、コンテンツに関する何かを表します。
- トピックの問題
- セマンティックの意味
- 構文と文法
- 単語と語句の使用法
- コンテキストリレーションシップ
- スタイルまたはトーン
これらの数値はすべて、コンテンツが多次元空間内のどこにあるかを示します。 3D グラフを想像してみてください。ただし、数百または数千のディメンションがあります。 コンピューターは、描画できない場合でも、この種の領域で動作します。
チュートリアル: Azure AI Foundry Models の埋め込みとドキュメント検索で Azure OpenAI を調べるには、Azure OpenAI Embeddings API を使用してドキュメントの埋め込みを作成する方法に関するガイドが用意されています。
ベクターとコンテンツの格納
次の手順では、ベクター とコンテンツ (またはコンテンツの場所へのポインター) とその他のメタデータをベクター データベースに格納します。 ベクター データベースは他の種類のデータベースと似ていますが、次の 2 つの主な違いがあります。
- ベクター データベースは、データを検索するためのインデックスとしてベクターを使用します
- ベクター データベースは、多くの場合、最も近い近隣アルゴリズムを使用します。このアルゴリズムでは、距離メトリックとして コサインの類似性 を使用して、検索条件に最も近いベクトルを検索できます。
ベクター データベースに格納されているドキュメントのコーパスを使用すると、開発者は、ユーザーのクエリに一致するドキュメントを取得する 取得コンポーネント を構築できます。 システムはこのデータを使用して、ユーザーのクエリに応答するために必要なものを LLM に提供します。
ドキュメントを使用してクエリに応答する
RAG システムでは、まずセマンティック検索を使用して、LLM が回答を作成するときに役立つ可能性のある記事を見つけます。 次の手順では、ユーザーの元のプロンプトと一致する記事を LLM に送信して回答を作成します。
次の図は、単純な RAG 実装 (単純な RAG と呼ばれることもあります) を示しています。
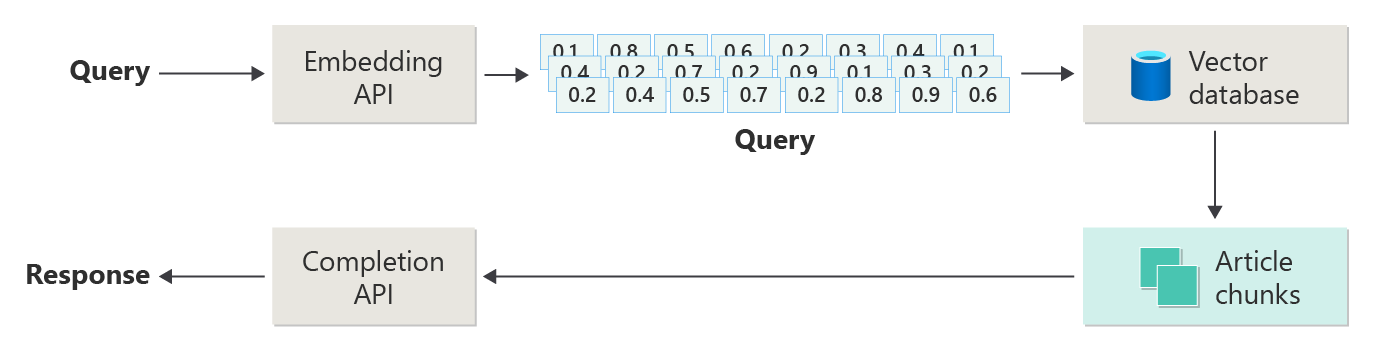
この図では、ユーザーがクエリを送信しています。 最初に、システムはユーザーのプロンプトを埋め込みに変換します。 次に、ベクター データベースを検索して、プロンプトに最も似たドキュメントまたはチャンクを検索します。
コサイン類似度 は、2 つのベクトルの間の角度を調べることによって、2 つのベクトルの近さを測定します。 1 に近い値は、ベクトルが非常に類似していることを意味します。-1 に近い値は、それらが非常に異なってことを意味します。 この方法は、システムが類似したコンテンツを含むドキュメントを見つけるのに役立ちます。
最近傍アルゴリズムは、 特定のポイントに最も近いベクトルを見つけます。 k ニアレスト ネイバー (KNN) アルゴリズムは、最も近い上位 k 個の一致を検索します。 レコメンデーション エンジンのようなシステムでは、多くの場合、KNN とコサインの類似性を組み合わせて使用して、ユーザーのニーズに最適な一致を見つけます。
検索の後、最適に一致するコンテンツとユーザーのプロンプトを LLM に送信して、より関連性の高い応答を生成できるようにします。
課題と考慮事項
RAG システムには、独自の課題があります。
- データプライバシー:特に外部ソースから情報を取得または処理する場合は、ユーザーデータを責任を持って処理します。
- 計算要件: 大量のコンピューティング リソースを使用するには、取得と生成の両方の手順が必要です。
- 精度と関連性: 正確で関連性の高い応答を提供することに重点を置き、データまたはモデルの偏りを監視します。
開発者は、効率的で倫理的で価値のある RAG システムを構築するために、これらの課題に対処する必要があります。
運用対応 RAG システムの構築の詳細については、 高度な検索拡張生成システムの構築に関するページを参照してください。
生成 AI ソリューションの構築を試してみたいですか? まず、 Python 用の独自のデータ サンプルを使用してチャットを開始します。 チュートリアルは、 .NET、 Java、 JavaScript でも使用できます。
モデルの微調整
微調整では、大規模な一般的なデータセットに対する最初のトレーニングの後、より小さなドメイン固有のデータセットで LLM を再トレーニングします。
事前トレーニング中に、LLM は広範なデータから言語構造、コンテキスト、および一般的なパターンを学習します。 微調整では、特定のタスクやトピックでより優れたパフォーマンスを発揮できるように、新しいデータに焦点を当てたモデルについて説明します。 学習すると、モデルは新しいデータの詳細を処理するように重みを更新します。
微調整の主な利点
- 特殊化: 微調整は、法的ドキュメントや医療ドキュメントの分析や顧客サービスの処理など、特定のタスクに対してモデルのパフォーマンスを向上するのに役立ちます。
- 効率: 微調整では、ゼロからモデルをトレーニングするよりも、使用するデータが少なく、リソースも少なくなります。
- 適応性: 微調整により、モデルは、元のトレーニングでカバーされていない新しいタスクまたはドメインを学習できます。
- パフォーマンスの向上: 微調整は、モデルが新しいドメインの言語、スタイル、または用語を理解するのに役立ちます。
- パーソナル化: 微調整により、モデルの応答がユーザーまたは組織のニーズや好みに合うようにすることができます。
制限事項と課題
微調整には、いくつかの課題もあります。
- データ要件: 特定のタスクまたはドメイン用の大規模で高品質なデータセットが必要です。
- オーバーフィットのリスク: データセットが小さい場合、モデルはトレーニング データには適していますが、新しいデータではうまくいっていない可能性があります。
- コストとリソース: 微調整にはコンピューティング能力が必要です。特に大規模なモデルやデータセットの場合は特に必要です。
- メンテナンスと更新: ドメインが変更されたら、微調整されたモデルを更新する必要があります。
- モデルの誤差: 特定のタスクの微調整により、一般的な言語タスクでモデルの効果が低下する可能性があります。
微調整を使用してモデルをカスタマイズ、モデルを微調整する方法について説明します。
微調整と RAG
微調整と RAG はどちらも、LLM の作業を改善するのに役立ちますが、それぞれ異なるニーズに適合します。 目標、持っているデータとコンピューティング、モデルを特殊化するか、一般的に維持するかを基に、適切なアプローチを選択します。
微調整を選択するタイミング
- タスク固有のパフォーマンス: 特定のタスクに上位の結果が必要で、オーバーフィットを回避するのに十分なドメイン データがある場合に、微調整を選択します。
- データの制御: 基本モデルの事前トレーニングとは大きく異なる一意または独自のデータがある場合は、微調整を使用します。
- 安定したコンテンツ: 最新の情報を使用してタスクに一定の更新が必要ない場合は、微調整を選択します。
RAG を選択するタイミング
- 動的または変化するコンテンツ: ニュースや最近のイベントなど、最新の情報が必要な場合は RAG を使用します。
- 幅広いトピックの対象範囲: 1 つの領域だけでなく、多くのトピックで強力な結果が必要な場合は、RAG を選択します。
- 限られたリソース: トレーニング用に大量のデータやコンピューティングがなく、基本モデルが既に適切なジョブを実行している場合は、RAG を使用します。
アプリケーション設計に関する最終的な考え
アプリに必要な内容に基づいて、微調整と RAG のどちらを行うかを決定します。 微調整は特殊なタスクに最適ですが、RAG を使用すると、動的なシナリオに対して柔軟性と up-to日付のコンテンツが提供されます。