イベント ハブに送信されるデータが Azure ストレージ アカウントまたは Azure Data Lake Storage Gen 1 または Gen 2 にキャプチャされるように、イベント ハブを構成できます。 この記事では、イベント ハブにイベントを送信し、キャプチャされたデータを Azure Blob Storage から読み取る Python コードを記述する方法について説明します。 この機能の詳細については、「 Event Hubs Capture 機能の概要」を参照してください。
このクイック スタートでは、 Azure Python SDK を使用してキャプチャ機能を示します。 sender.py アプリは、シミュレートされた環境テレメトリを JSON 形式でイベント ハブに送信します。 イベント ハブは、キャプチャ機能を使用してこのデータを Blob Storage にバッチで書き込むように構成されています。 capturereader.py アプリは、これらの BLOB を読み取り、デバイスごとに追加ファイルを作成します。 その後、アプリはデータを CSV ファイルに書き込みます。
このクイック スタートでは次の作業を行います。
- Azure portal で Azure Blob Storage アカウントとコンテナーを作成します。
- Azure portal を使用して Event Hubs 名前空間を作成します。
- キャプチャ機能を有効にしてイベント ハブを作成し、ストレージ アカウントに接続します。
- Python スクリプトを使用してイベント ハブにデータを送信します。
- 別の Python スクリプトを使用して、Event Hubs Capture からファイルを読み取って処理します。
[前提条件]
pip がインストールおよび更新された Python 3.8 以降。
Azure サブスクリプション。 お持ちでない場合は、開始する前に無料アカウントを作成してください。
アクティブな Event Hubs 名前空間とイベント ハブ。 名前空間に Event Hubs 名前空間とイベント ハブを作成します。 Event Hubs 名前空間の名前、イベント ハブの名前、名前空間のプライマリ アクセス キーを記録します。 アクセス キーを取得するには、「 Event Hubs 接続文字列を取得する」を参照してください。 既定のキー名は RootManageSharedAccessKey です。 このクイック スタートでは、主キーのみが必要です。 接続文字列は必要ありません。
Azure ストレージ アカウント、ストレージ アカウント内の BLOB コンテナー、ストレージ アカウントへの接続文字列。 これらの項目がない場合は、次の手順を実行します。
このクイック スタートで後で使用するために、接続文字列とコンテナー名を必ず記録してください。
イベント ハブのキャプチャ機能を有効にする
イベント ハブのキャプチャ機能を有効にします。 これを行うには、「 Azure portal を使用して Event Hubs Capture を有効にする」の手順に従います。 前の手順で作成したストレージ アカウントと BLOB コンテナーを選択します。 出力イベントのシリアル化形式として Avro を選択します。
イベント ハブにイベントを送信する Python スクリプトを作成する
このセクションでは、200 イベント (10 デバイス * 20 イベント) をイベント ハブに送信する Python スクリプトを作成します。 これらのイベントは、JSON 形式で送信される環境読み取りのサンプルです。
Visual Studio Code など、お気に入りの Python エディターを開きます。
sender.py という名前のスクリプトを作成します。
次のコードを sender.py に貼り付けます。
import time import os import uuid import datetime import random import json from azure.eventhub import EventHubProducerClient, EventData # This script simulates the production of events for 10 devices. devices = [] for x in range(0, 10): devices.append(str(uuid.uuid4())) # Create a producer client to produce and publish events to the event hub. producer = EventHubProducerClient.from_connection_string(conn_str="EVENT HUBS NAMESPACE CONNECTION STRING", eventhub_name="EVENT HUB NAME") for y in range(0,20): # For each device, produce 20 events. event_data_batch = producer.create_batch() # Create a batch. You will add events to the batch later. for dev in devices: # Create a dummy reading. reading = { 'id': dev, 'timestamp': str(datetime.datetime.utcnow()), 'uv': random.random(), 'temperature': random.randint(70, 100), 'humidity': random.randint(70, 100) } s = json.dumps(reading) # Convert the reading into a JSON string. event_data_batch.add(EventData(s)) # Add event data to the batch. producer.send_batch(event_data_batch) # Send the batch of events to the event hub. # Close the producer. producer.close()スクリプト内の次の値を置き換えます。
-
EVENT HUBS NAMESPACE CONNECTION STRINGを Event Hubs 名前空間の接続文字列に置き換えます。 -
EVENT HUB NAMEをイベント ハブの名前に置き換えます。
-
イベント ハブにイベントを送信するスクリプトを実行します。
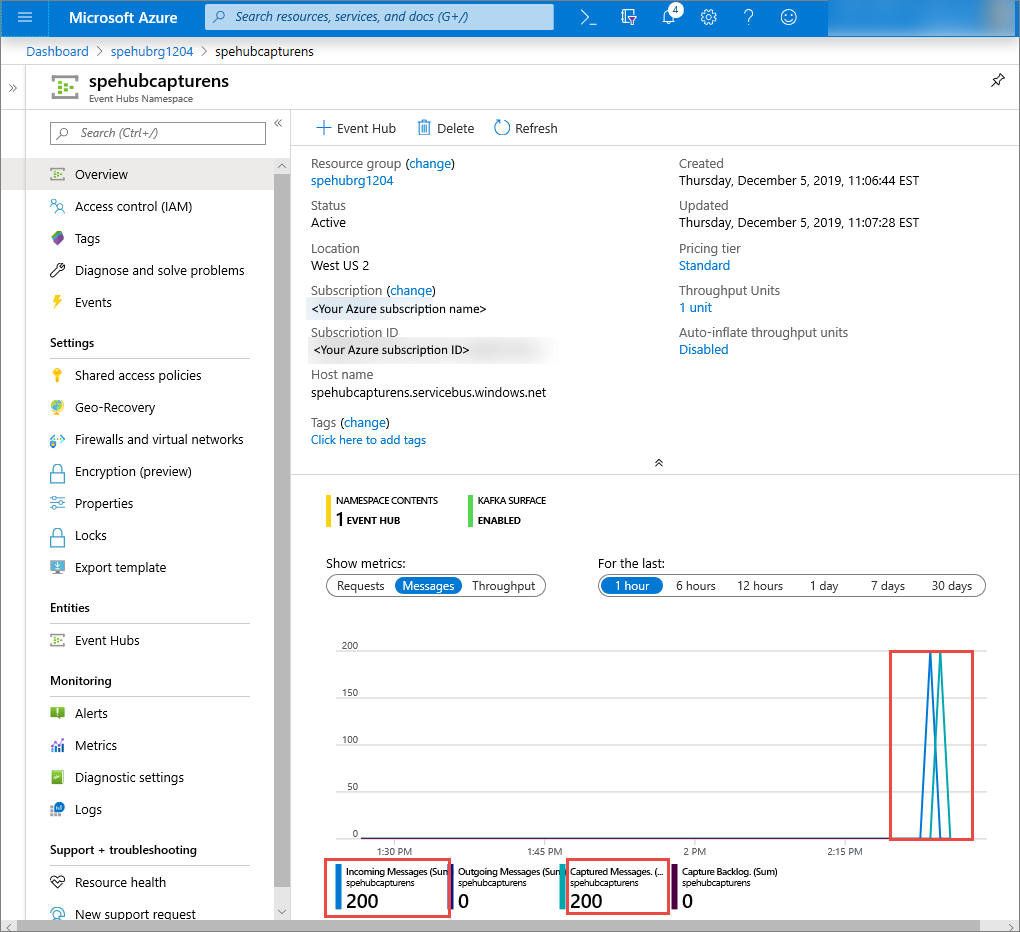
Azure portal で、イベント ハブがメッセージを受信したことを確認できます。 [メトリック] セクションの [メッセージ] ビューに切り替えます。 ページを更新してグラフを更新します。 メッセージが受信されたことがページに表示されるまでに数秒かかる場合があります。

キャプチャ ファイルを読み取る Python スクリプトを作成する
この例では、キャプチャされたデータは Azure Blob Storage に格納されます。 このセクションのスクリプトでは、Azure ストレージ アカウントからキャプチャされたデータ ファイルを読み取り、CSV ファイルを生成して、簡単に開いて表示できるようにします。 アプリケーションの現在の作業ディレクトリに 10 個のファイルが表示されます。 これらのファイルには、10 台のデバイスの環境測定値が含まれています。
Python エディターで、 capturereader.py という名前のスクリプトを作成します。 このスクリプトは、キャプチャされたファイルを読み取り、デバイスごとにファイルを作成して、そのデバイスのデータのみを書き込みます。
次のコードを capturereader.py に貼り付けます。
import os import string import json import uuid import avro.schema from azure.storage.blob import ContainerClient, BlobClient from avro.datafile import DataFileReader, DataFileWriter from avro.io import DatumReader, DatumWriter def processBlob2(filename): reader = DataFileReader(open(filename, 'rb'), DatumReader()) dict = {} for reading in reader: parsed_json = json.loads(reading["Body"]) if not 'id' in parsed_json: return if not parsed_json['id'] in dict: list = [] dict[parsed_json['id']] = list else: list = dict[parsed_json['id']] list.append(parsed_json) reader.close() for device in dict.keys(): filename = os.getcwd() + '\\' + str(device) + '.csv' deviceFile = open(filename, "a") for r in dict[device]: deviceFile.write(", ".join([str(r[x]) for x in r.keys()])+'\n') def startProcessing(): print('Processor started using path: ' + os.getcwd()) # Create a blob container client. container = ContainerClient.from_connection_string("AZURE STORAGE CONNECTION STRING", container_name="BLOB CONTAINER NAME") blob_list = container.list_blobs() # List all the blobs in the container. for blob in blob_list: # Content_length == 508 is an empty file, so process only content_length > 508 (skip empty files). if blob.size > 508: print('Downloaded a non empty blob: ' + blob.name) # Create a blob client for the blob. blob_client = ContainerClient.get_blob_client(container, blob=blob.name) # Construct a file name based on the blob name. cleanName = str.replace(blob.name, '/', '_') cleanName = os.getcwd() + '\\' + cleanName with open(cleanName, "wb+") as my_file: # Open the file to write. Create it if it doesn't exist. my_file.write(blob_client.download_blob().readall()) # Write blob contents into the file. processBlob2(cleanName) # Convert the file into a CSV file. os.remove(cleanName) # Remove the original downloaded file. # Delete the blob from the container after it's read. container.delete_blob(blob.name) startProcessing()AZURE STORAGE CONNECTION STRINGを Azure ストレージ アカウントの接続文字列に置き換えます。 このクイック スタートで作成したコンテナーの名前は キャプチャです。 コンテナーに別の名前を使用した場合は、 キャプチャ をストレージ アカウント内のコンテナーの名前に置き換えます。
スクリプトを実行する
パスに Python が含まれるコマンド プロンプトを開き、次のコマンドを実行して Python の前提条件パッケージをインストールします。
pip install azure-storage-blob pip install azure-eventhub pip install avro-python3sender.py と capturereader.py を保存したディレクトリにディレクトリを変更し、次のコマンドを実行します。
python sender.pyこのコマンドは、送信者を実行する新しい Python プロセスを開始します。
キャプチャが実行されるまで数分待ってから、元のコマンド ウィンドウに次のコマンドを入力します。
python capturereader.pyこのキャプチャ プロセッサは、ローカル ディレクトリを使用して、ストレージ アカウントとコンテナーからすべての BLOB をダウンロードします。 空ではないファイルを処理し、結果を CSV ファイルとしてローカル ディレクトリに書き込みます。