責任ある AI を実際に実装するには、厳格なエンジニアリングが必要です。 ただし、厳格なエンジニアリングは、適切なツールとインフラストラクチャなしでは手作業であり、面倒で時間がかかる場合があります。
責任ある AI ダッシュボードには、実際に効果的かつ効率的に責任ある AI を実装するのに役立つ 1 つのインターフェイスが用意されています。 以下の領域で、成熟した責任ある AI ツールをいくつかまとめます。
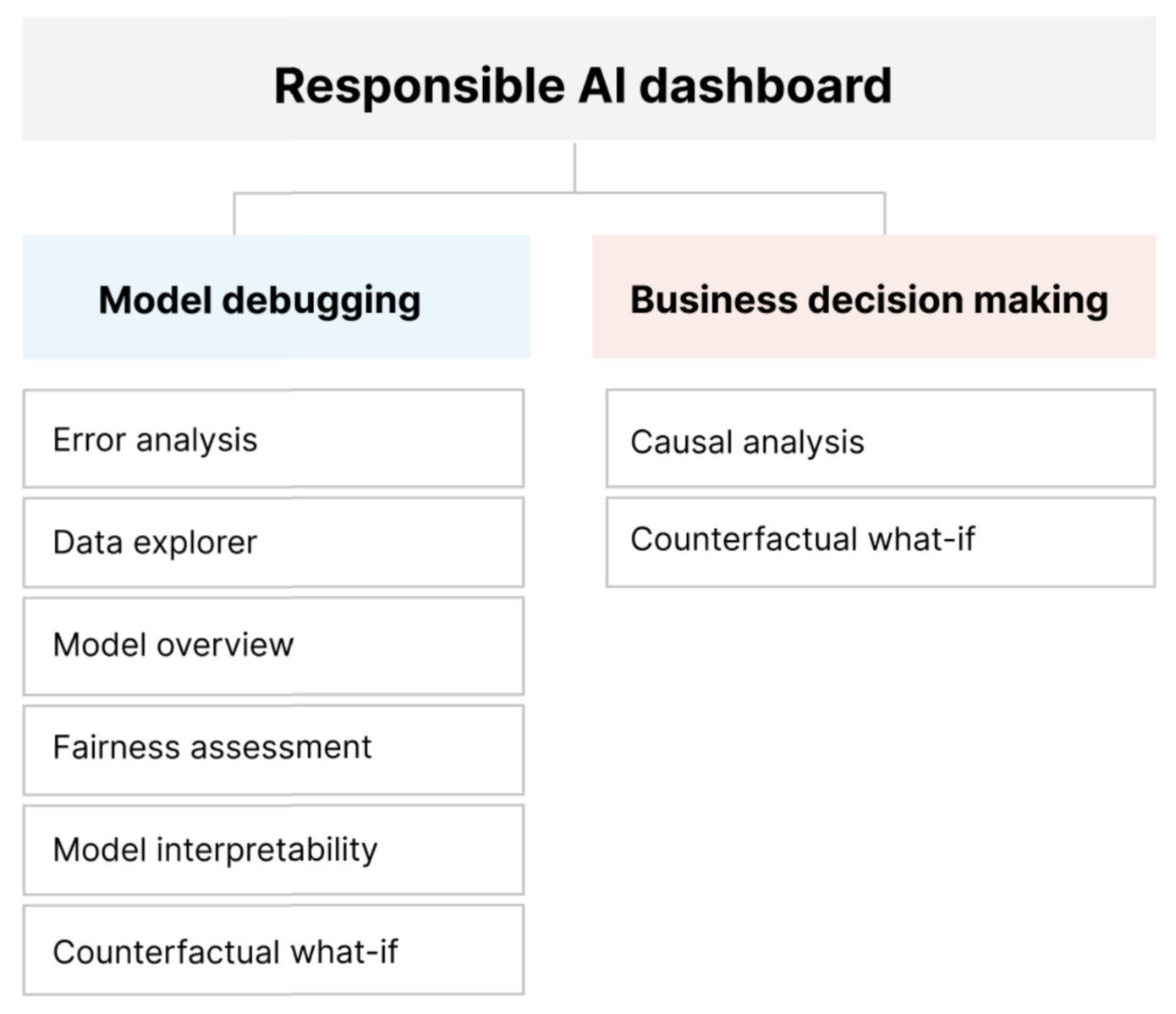
ダッシュボードには、モデルの包括的な評価とデバッグが用意されているため、情報に基づいたデータドリブンの意思決定を行うことができます。 1 つのインターフェイスでこれらのツールすべてにアクセスすることで、次のことが可能になります。
モデル エラーと公平性の問題を特定し、それらのエラーの発生原因を診断し、軽減手順を通知することで、機械学習モデルを評価してデバッグする。
次のような質問に対処して、データドリブンの意思決定能力を向上させます。
"モデルから異なる結果を得るためにユーザーが特徴に適用できる最小限の変更はどの程度ですか?"
"実際の結果 (例: 糖尿病の進行) に対する特徴量の減少または増加 (例: 赤肉の消費) には、どのような因果関係がありますか?"
ダッシュボードをカスタマイズして、ユース ケースに関連するツールのサブセットのみを含めることができます。
責任ある AI ダッシュボードには PDF スコアカードが添付されています。 スコアカードを使用すると、責任ある AI メタデータと分析情報をデータとモデルにエクスポートできます。 その後、製品とコンプライアンスの利害関係者とオフラインで共有できます。
注
責任ある AI イメージとテキスト ダッシュボードの使用については、オープン ソースの 責任ある AI ツールボックスを参照してください。
責任ある AI ダッシュボードのコンポーネント
責任ある AI ダッシュボードでは、さまざまな新しいツールや既存のツールが包括的なビューにまとめられています。 ダッシュボードでは、これらのツールが Azure Machine Learning CLI v2、Azure Machine Learning Python SDK v2、および Azure Machine Learning スタジオと統合されています。 ツールには次のものが含まれます。
- データ分析を使用すると、データセットの分布と統計を把握し、調査できます。
- モデル概要と公平性評価: これを使用すると、モデルのパフォーマンスを評価でき、またモデルのグループ公平性問題 (モデルの予測が人々の多様なグループにどのように影響するか) を評価できます。
- エラー分析: これを使用すると、データセット内でエラーがどのように分散されているかを表示および理解できます。
- モデルの解釈可能性 (集計/個々の特徴の重要度値): これを使用すると、モデルの予測、およびそれらの全体的な予測と個々の予測がどのように行われたかを理解できます。
- 反事実条件 What-If: これを使用すると、特徴の摂動がモデル予測にどのように影響したかを観察できる一方で、反対または異なるモデル予測を使用して最も近いデータポイントを取得できます。
- 因果分析: これを使用すると、履歴データを使用して、実際の結果への処理特徴の因果効果を確認できます。
これらのツールを組み合わせることで、機械学習モデルをデバッグし、データドリブンおよびモデル駆動型のビジネス上の決定を通知できます。 次の図は、それらを AI ライフサイクルに組み込んでモデルを改善し、確かなデータ分析情報を得る方法を示しています。
モデルのデバッグ
機械学習モデルの評価とデバッグは、モデルの信頼性、解釈可能性、公平性、コンプライアンスのために不可欠です。 これは、AI システムの動作方法と動作理由を判断するのに役立ちます。 その後、この知識を使用してモデルのパフォーマンスを向上させることができます。 概念的には、モデルのデバッグは次の 3 つのステージで構成されます。
特定: 次の質問に対処することで、モデルのエラーや公平性の問題を理解して認識します。
"モデルにはどのような種類のエラーがありますか?"
"どの領域でエラーが最も頻繁に発生しますか?"
次の質問に対処して、特定されたエラーの背後にある理由を調べるために診断します。
"これらのエラーの原因は何ですか?"
"モデルを改善するためにリソースをどこに集中させる必要がありますか?"
軽減: 前段階の特定と診断の分析情報を使用して、対象を絞った軽減手順を実行し、次のような質問に対処します。
"どのようにモデルを改善できますか?"
"これらの問題に対して、どのような社会的または技術的な解決策が存在しますか?"

次の表では、責任ある AI ダッシュボード コンポーネントを使用してモデルのデバッグをサポートする場面について説明します。
| 段階 | コンポーネント | 説明 |
|---|---|---|
| 識別 | エラー分析 | エラー分析コンポーネントは、モデルのエラー分布をより深く理解し、データの誤ったコーホート (サブグループ) をすばやく特定するのに役立ちます。 ダッシュボードのこのコンポーネントの機能は、エラー分析パッケージから提供されます。 |
| 識別 | 公平性分析 | 公平性コンポーネントは、性別、人種、年齢などの機密性の高い属性の観点からグループを定義します。 次に、モデル予測がこれらのグループに与える影響と、差異を軽減する方法を評価します。 グループ全体での予測値とモデル パフォーマンス メトリックの値の分布が調べられ、モデルのパフォーマンスが評価されます。 ダッシュボードのこのコンポーネントの機能は、Fairlearn パッケージから提供されます。 |
| 識別 | モデルの概要 | モデル概要コンポーネントは、モデルのパフォーマンスを調査しやすくするために、モデル予測分布の概要ビューでモデル評価メトリックを集計します。 このコンポーネントでは、センシティブ グループに対するモデル パフォーマンスの詳細を強調することで、グループの公平性評価を行うこともできます。 |
| 診断 | データ分析 | データ分析では、予測と実際のそれぞれの結果、エラー グループ、特定の特徴に基づいてデータセットが視覚化されます。 その後、過剰表示と過小表示の問題を特定し、データセット内でデータがどのようにクラスター化されているかを確認できます。 |
| 診断 | モデルの解釈可能性 | 解釈可能性コンポーネントは、人間が理解可能な機械学習モデルの予測の説明を生成します。 これによって、モデルの動作に複数の認識が与えられます。 - グローバルな説明 (たとえば、ローン配賦モデルの全体的な動作に影響する特徴量は何ですか?) - 現地の説明 (申請者のローン申請が承認または却下された理由など) ダッシュボードのこのコンポーネントの機能は、InterpretML パッケージから提供されます。 |
| 診断 | 反事実分析と What-If | このコンポーネントは、エラー診断を改善するための 2 つの機能で構成されています。 - 特定のポイントへの最小限の変更によってモデルの予測が変更される一連の例を生成する。 つまり、この例では、反対のモデル予測を提供する最も近いデータ ポイントを示しています。 - モデルが特徴の変化にどのように反応するかを把握するために、個々のデータ ポイントに対して対話型のカスタム What-If 摂動を有効にする。 ダッシュボードのこのコンポーネントの機能は、DiCE パッケージから提供されます。 |
軽減手順は、Fairlearn などのスタンドアロン ツールを通じて利用できます。 詳細については、 不公平軽減アルゴリズムに関する記事を参照してください。
責任ある意思決定
意思決定は、機械学習の最大の約束の 1 つです。 責任ある AI ダッシュボードは、次の方法により情報に基づいたビジネス上の意思決定を行うのに役立ちます。
結果に対する因果関係処理効果を理解するのに役立つ、履歴データのみを使用したデータ駆動型分析情報。 次に例を示します。
"薬は患者の血圧にどのように影響しますか?"
"特定の顧客にプロモーション価値を提供することは、収益にどのような影響を与えますか?"
これらの分析情報は、ダッシュボードの因果関係推論コンポーネントを通じて提供されます。
"次に AI から異なる結果を得るためにどうすればよいのか?" などのユーザーの質問に回答し、対応できるようにするためのモデル駆動型分析情報。 これらの分析情報は、反事実条件 What-If コンポーネントを介してデータ サイエンティストに提供されます。

探索的データ分析、因果関係推論機能、反事実分析の支援により、情報に基づきモデル ドリブンおよびデータ ドリブンの意思決定を責任を持って行うことができます。
責任ある AI ダッシュボードの次のコンポーネントでは、責任ある意思決定がサポートされます。
データ分析。 ここでデータ分析コンポーネントを再利用して、データ分布を理解し、過剰表示と過小表示を識別できます。 データ探索は意思決定の重要な部分です。これは、データ探索により、データ内で過小表現されているコーホートに関して、情報に基づき意思決定を行うことができないためです。
因果関係の推論。 因果推論コンポーネントは、介入が存在する場合に実際の結果がどのように変化するかを推定します。 また、さまざまな介入に対する特徴反応をシミュレートし、特定の介入の恩恵を受ける母集団コーホートを判断するルールを作成することで、有望な介入を構築するのにも役立ちます。 これらの機能を集合的に使用することで、新しいポリシーを適用し、実際の変化に影響を与えることができます。
このコンポーネントの機能は、EconML パッケージから提供されます。このパッケージは、機械学習を通じて観測データから異種処理効果を推定します。
反事実分析。 ここでは、反正面分析コンポーネントを再利用して、反対のモデル予測につながるデータ ポイントの特徴に適用される最小限の変更を生成できます。 たとえば、Taylor は、年収が 10,000 ドル増え、クレジット カードが 2 枚少なかったら、AI からローン承認を受けた可能性があります。
この情報をユーザーに提供すると、ユーザーの視点が通知されます。 これにより、今後 AI から目的の結果を得るためにどのようなアクションを実行できるかが教育されます。
このコンポーネントの機能は DiCE パッケージから提供されます。
責任ある AI ダッシュボードを使用する理由
責任ある AI の特定領域では個々のツールが進歩していますが、データ サイエンティストは、多くの場合、モデルとデータを総合的に評価するために、さまざまなツールを使用する必要があります。 たとえば、モデルの解釈可能性と公平性の評価を一緒に使用する必要がある場合があります。
データ サイエンティストは、1 つのツールを使用して公平性の問題を発見した場合、軽減策の手順を実行する前に、別のツールを使用して、問題の根本にあるデータまたはモデルの要因を理解する必要があります。 次の要因により、この困難なプロセスがさらに複雑になります。
- ツールを発見して学習するための中心的な場所はなく、新しい手法の研究と学習にかかる時間が長くなります。
- 異なるツールが相互通信できない。 データ サイエンティストは、データセット、モデル、その他のメタデータをツール間で渡す場合に、それらをラングリングする必要があります。
- メトリックと視覚化は簡単には比較できず、結果を共有するのが困難である。
責任ある AI ダッシュボードは、この現状に挑戦します。 これは、断片化されたエクスペリエンスを 1 か所にまとめる、包括的でありながらカスタマイズ可能なツールです。 これにより、モデルのデバッグとデータドリブンの意思決定のための単一のカスタマイズ可能なフレームワークにシームレスにオンボードできます。
責任ある AI ダッシュボードを使用すると、データセット コーホートを作成し、それらのコホートをサポートされているすべてのコンポーネントに渡し、特定されたコホートのモデルの正常性を確認できます。 さらに、さまざまな事前構築済みのコーホートでサポートされているすべてのコンポーネントの分析情報を比較して、非集計分析を実行し、モデルの盲点を見つけることができます。
これらの分析情報を他の利害関係者と共有する準備ができたら、責任ある AI PDF スコアカードを使用して情報を簡単に抽出できます。 PDF レポートをコンプライアンス レポートに添付するか、同僚と共有して信頼を築き、承認を得ます。
責任ある AI ダッシュボードをカスタマイズする方法
責任ある AI ダッシュボードの強みは、そのカスタマイズ性にあります。 これにより、特定のニーズに対応する、カスタマイズされたエンドツーエンドのモデル デバッグと意思決定ワークフローを設計できます。
制作のヒントや ダッシュボードのコンポーネントを組み合わせて、さまざまな方法でシナリオを分析する方法の例を次に示します。
| 責任ある AI ダッシュボードのフロー | 使用事例 |
|---|---|
| [モデルの概要] -> [エラー分析] -> [データ分析] | モデルのエラーを特定し、基になるデータ分布を把握してそれらを診断する場合 |
| [モデルの概要] -> [公平性の評価] -> [データ分析] | モデルの公平性の問題を特定し、基になるデータ分布を把握してそれらを診断する場合 |
| [モデルの概要] -> [エラー分析] -> [反事実分析と What-If] | 反事実分析を使用して個々の事例でエラーを診断する場合 (最小限の変更により異なるモデル予測が導出されます) |
| [モデルの概要] -> [データ分析] | データの不均衡または特定のデータ コーホートの表現の欠如によって発生するエラーと公平性の問題の根本原因を把握する場合 |
| [モデルの概要] -> [解釈可能性] | モデルがどのように予測を行ったかを理解してモデル エラーを診断するには |
| [データ分析] -> [因果関係推論] | データ内の相関関係と因果関係を区別する場合、または肯定的な結果を得るために適用する最適な処理を決定する場合 |
| [解釈可能性] -> [因果関係推論] | モデルが予測作成に使用した要因が実際の結果に因果関係を持っているかどうかを学習するには |
| [データ分析] -> [反事実分析と What-If] | AI システムから異なる結果を得るために次に何ができるかという顧客の質問に対処する場合 |
責任ある AI ダッシュボードを使用するのに適しているロール
次のロールは、責任ある AI ダッシュボードとそれに対応する 責任ある AI スコアカードを使用して、AI システムとの信頼を構築できます。
- デプロイ前に機械学習モデルをデバッグして改善したい機械学習の専門家とデータ サイエンティスト
- モデルの正常性レコードを製品マネージャーやビジネス利害関係者と共有して信頼を構築し、デプロイのアクセス許可を受け取りたい機械学習の専門家とデータ サイエンティスト
- デプロイ前に機械学習モデルを確認する製品マネージャーとビジネス利害関係者
- 公平性と信頼性の問題を把握するために機械学習モデルを確認するリスク責任者
- モデルの決定をユーザーに説明したり、結果の改善を支援したりする AI ソリューションのプロバイダー
- 規制機関や監査者と共に機械学習モデルを確認する必要がある規制が厳しい分野のプロフェッショナル
サポートされているシナリオと制限事項
- 責任ある AI ダッシュボードでは、現在、表形式の構造化データでトレーニングされた回帰と分類 (バイナリおよびマルチクラス) モデルがサポートされています。
- 現在、責任ある AI ダッシュボードでは、sklearn (scikit-learn) の実装のみを使用して Azure Machine Learning に登録されている MLflow モデルがサポートされています。 scikit-learn モデルでは
predict()/predict_proba()メソッドを実装する必要があります。またはこのモデルは、predict()/predict_proba()メソッドを実行するクラス内にラップする必要があります。 モデルは、コンポーネント環境で読み込み可能で、pickleable である必要があります。 - 責任ある AI ダッシュボードは現在、ダッシュボード UI で最大 5,000 のデータ ポイントを視覚化しています。 ダッシュボードに渡す前に、データセットを 5,000 個以下のデータ ポイントにダウンサンプリングする必要があります。
- Responsible AI ダッシュボードへのデータセット入力は、Parquet 形式の pandas DataFrames である必要があります。 NumPy および SciPy スパース データは現在サポートされていません。
- 責任ある AI ダッシュボードは現在、数値またはカテゴリの特徴をサポートしています。 カテゴリの特徴の場合は、特徴名を明示的に指定する必要があります。
- 現在、責任ある AI ダッシュボードでは、10,000 を超える列を含むデータセットはサポートされていません。
- 現在、責任ある AI ダッシュボードでは、AutoML MLFlow モデルはサポートされていません。
- 責任ある AI ダッシュボードは現在、登録済みの AutoML MLFlow モデルを UI から使用できません。
次のステップ
- CLI と SDK または Azure Machine Learning スタジオ UI を使用して責任ある AI ダッシュボードを生成する方法について学習します。
- 責任ある AI ダッシュボードで観察された分析情報に基づいて責任ある AI スコアカードを生成する方法について学習します。