Azure AI Search は、企業の要件を満たすために、ネットワーク アクセス、データ アクセス、およびデータ保護全体にわたる包括的なセキュリティ制御を提供します。 ソリューション アーキテクトは、次の 3 つの主要なセキュリティ ドメインを理解する必要があります。
- ネットワーク トラフィック パターンとネットワーク セキュリティ: 受信、送信、内部トラフィック。
- アクセス制御メカニズム: ロールを含む API キーまたは Microsoft Entra ID。
- データ所在地と保護: 転送中の暗号化、オプションの機密コンピューティングで使用中の暗号化、オプションの二重暗号化による保存時の暗号化。
検索サービスでは、基本的な保護に関する IP ファイアウォールの制限から、完全なネットワーク分離のためのプライベート エンドポイントまで、複数のネットワーク セキュリティ トポロジがサポートされています。 必要に応じて、ネットワーク セキュリティ境界を使用して、Azure PaaS リソースの周囲に論理境界を作成します。 詳細なアクセス許可を必要とするエンタープライズ シナリオでは、ドキュメント レベルのアクセス制御を実装できます。 すべてのセキュリティ機能は Azure のコンプライアンス フレームワークと統合され、マネージド ID を使用したマルチテナント認証やクロスサービス認証などの一般的なエンタープライズ パターンがサポートされます。
この記事では、開発環境と運用環境に適したセキュリティ アーキテクチャを設計するのに役立つ、各セキュリティ層の実装オプションについて詳しく説明します。
ネットワーク トラフィック パターン
Azure AI Search サービスは、Azure パブリック クラウド、Azure プライベート クラウド、またはソブリン クラウド (Azure Government など) でホストできます。 既定では、すべてのクラウド ホストに対して、検索サービスは通常、パブリック ネットワーク接続経由でクライアント アプリケーションによってアクセスされます。 このようなパターンとなることが多いですが、他のトラフィック パターンにも注意する必要があります。 開発環境と運用環境をセキュリティ保護するには、すべてのエントリ ポイントと送信トラフィックについて理解しておく必要があります。
Azure AI Search には、3 つの基本的なネットワーク トラフィック パターンがあります。
- ユーザーまたはクライアントによって行われる、検索サービスへのインバウンド要求 (主要なパターン)
- 検索サービスによって発行される、Azure やそれ以外の場所の他のサービスへのアウトバウンド要求
- セキュリティ保護された Microsoft バックボーン ネットワークを介して行われる内部サービス間の要求
受信トラフィック
検索サービス エンドポイントを対象とする受信要求には、次が含まれます。
- 検索サービスでインデックスやその他のオブジェクトを作成、読み取り、更新、または削除する
- 検索ドキュメントのインデックスを読み込む
- インデックスのクエリ
- インデクサーまたはスキルセット ジョブを実行する
REST API のページで、検索サービスによって処理される受信要求の全範囲が説明されています。
少なくとも、すべての受信要求は、次のいずれかのオプションを使用して認証される必要があります。
- キーベースの認証 (デフォルト)。 受信要求が、有効な API キーを提供します。
- ロールベースのアクセス制御。 認可は、検索サービスの Microsoft Entra ID とロールの割り当て経由で行われます。
さらに、ネットワーク セキュリティ機能を追加して、エンドポイントへのアクセスをさらに制限できます。 IP ファイアウォールでの受信の規則、またはパブリック インターネットから検索サービスを完全に遮断するプライベート エンドポイントのいずれかを作成することができます。
アウトバウンド トラフィック
送信要求は、ユーザーがセキュリティで保護および管理できます。 送信要求は、検索サービスから他のアプリケーションに向けて発生します。 通常、これらの要求は、テキストベースおよびマルチモーダルインデックス作成、カスタムスキルベースのAIエンリッチメント、およびクエリ時のベクター化のためにインデクサーによって行われます。 送信要求には、読み取りと書き込みの両方の操作が含まれます。
次の一覧は、セキュリティで保護された接続を構成できる送信要求の完全な列挙です。 検索サービスは、検索自体のため、およびインデクサーまたはカスタム スキルのために要求を行います。
| Operation | Scenario |
|---|---|
| Indexers | 外部データ ソースに接続してデータを取得します (読み取りアクセス)。 詳細については、「Azure ネットワーク セキュリティで保護されたコンテンツへのインデクサー アクセス」を参照してください。 |
| Indexers | ナレッジ ストア、キャッシュされたエンリッチメント、デバッグ セッションへの書き込み操作のために Azure Storage に接続します。 |
| カスタム スキル | サービス外でホストされている外部コードを実行している Azure Functions、Azure Web アプリ、またはその他のアプリに接続します。 スキルセットの実行中に、外部処理に対する要求が送信されます。 |
| インデクサーと垂直統合 | Azure OpenAI とデプロイされた埋め込みモデルに接続するか、カスタム スキルを経由して、指定する埋め込みモデルに接続します。 検索サービスは、インデックス作成中にベクター化のために埋め込みモデルにテキストを送信します。 |
| Vectorizers | クエリ時に Azure OpenAI またはその他の埋め込みモデルに接続して、ベクター検索のためにユーザー テキスト文字列をベクターに変換します。 |
| ナレッジ エージェント |
エージェント検索クエリの計画や、検索結果に根付いた回答の作成のために、チャット完了モデルに接続します。 基本的な RAG パターンを実装している場合、クエリ ロジックは外部チャット完了モデルを呼び出して、検索結果に基づいている回答を作成します。 このパターンでは、モデルへの接続でクライアントまたはユーザーの ID が使用されます。 検索サービス ID は、接続には使用されません。 これに対し、RAG 取得パターンで ナレッジ エージェント を使用する場合、送信要求は検索サービスのマネージド ID によって行われます。 |
| Search Service | 機密データの暗号化および復号化に使用されるカスタマー マネージド暗号化キーを取得するために、Azure Key Vault に接続します。 |
送信接続は、通常、キーまたはデータベース ログインを含むリソースのフル アクセス接続文字列を使用して行うことができます。Microsoft Entra ID とロールベースのアクセスを使用している場合は マネージド ID を使用します。
ファイアウォールの内側にある Azure リソースにアクセスするには、他の Azure リソースに検索サービス要求を許可する受信規則を作成します。
Azure Private Link によって保護された Azure リソースにアクセスするには、インデクサーが接続を確立するために使用する共有プライベート リンクを作成します。
同じリージョンの検索サービスとストレージ サービスの例外
Azure Storage と Azure AI Search が同じリージョンにある場合、ネットワーク トラフィックはプライベート IP アドレス経由でルーティングされ、Microsoft バックボーン ネットワークで発生します。 プライベート IP アドレスが使用されるため、ネットワーク セキュリティ用に IP ファイアウォールまたはプライベート エンドポイントを構成することはできません。
次のいずれかの方法を使用して、同じリージョンの接続を構成します。
内部トラフィック
内部要求は、Microsoft によってセキュリティで保護され、管理されます。 これらの接続を構成または制御することはできません。 ネットワーク アクセスをロックダウンしている場合、顧客が内部トラフィックを構成できないため、顧客からのアクションは必要ありません。
内部トラフィックは次で構成されます。
- タスク (Microsoft Entra ID 経由の認証と認可、Azure Monitor に送信されたリソース ログ、Azure Private Link を使用したプライベート エンドポイント接続など) のサービス間呼び出し。
- 組み込みのスキル処理の要求。同じリージョンの要求は、Azure AI Search による組み込みのスキル処理専用に使用される、内部でホストされている Azure AI マルチサービス リソースに送信されます。
- セマンティック ランク付けをサポートするさまざまなモデルに対して行われたリクエスト。
ネットワークのセキュリティ
ネットワーク セキュリティは、ネットワーク トラフィックに制御を適用することにより、未承認のアクセスや攻撃からリソースを保護します。 Azure AI Search は、未承認のアクセスに対する防御の前線になり得るネットワーク機能をサポートしています。
IP ファイアウォール経由の受信接続
検索サービスは、パブリック IP アドレスを使用して、アクセスを許可するパブリック エンドポイントによりプロビジョニングされます。 パブリック エンドポイントを経由するトラフィックを制限するには、特定の IP アドレスまたは IP アドレスの特定の範囲から要求を許可する受信ファイアウォール規則を作成します。 すべてのクライアント接続は、許可された IP アドレスを使用して行う必要があります。それ以外の場合、接続は拒否されます。
ファイアウォール アクセスを構成するには、Azure portal を使用します。
または、管理 REST API を使用します。 API バージョン 2020-03-13 以降では、IpRule パラメーターを指定することで、検索サービスへのアクセスを付与する IP アドレスを個別に、あるいは範囲で特定することで、サービスへのアクセスを制限できます。
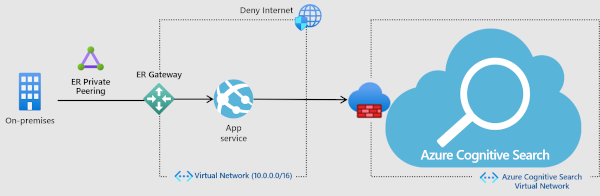
プライベート エンドポイントへの受信接続 (ネットワーク分離、インターネット トラフィックなし)
より強力なセキュリティには、Azure AI Search のプライベート エンドポイントを確立して、仮想ネットワーク上のクライアントが Private Link を介して、検索インデックス内のデータに安全にアクセスできるようにします。
プライベート エンドポイントでは、検索サービスに接続するために仮想ネットワークのアドレス空間の IP アドレスが使用されます。 クライアントと検索サービス間のネットワーク トラフィックは、仮想ネットワークおよび Microsoft バックボーン ネットワーク上のプライベートリンクを経由することで、パブリック インターネット上での露出を排除します。 仮想ネットワークを使用すると、オンプレミス ネットワークやインターネットで、リソース間の安全な通信が可能になります。

このソリューションは最も安全ですが、追加のサービスを使用すると、さらなるコストがかかります。そのため、使用の前に利点の詳細を明確に理解しておく必要があります。 コストの詳細については、価格に関するページを参照してください。 これらのコンポーネントを連携させる方法の詳細については、こちらのビデオをご覧ください。 プライベート エンドポイント オプションの説明は、ビデオの 5:48 から始まります。 エンドポイントを設定する方法については、Azure AI Search でのプライベート エンドポイントの作成に関するページを参照してください。
ネットワーク セキュリティ境界
ネットワーク セキュリティ境界は、仮想ネットワークの外部にデプロイされるサービスとしてのプラットフォーム (PaaS) リソースを囲む論理ネットワーク境界です。 Azure AI Search、Azure Storage、Azure OpenAI などのリソースへのパブリック ネットワーク アクセスを制御するための境界が確立されます。 受信トラフィックと送信トラフィックの明示的なアクセス規則を使用して例外を付与できます。 このアプローチは、アプリケーションに必要な接続を維持しながら、データ流出を防ぐのに役立ちます。
受信クライアント接続とサービス間接続は境界内で行われるため、承認されていないアクセスに対する防御が簡素化され、強化されます。 Azure AI Search ソリューションでは、複数の Azure リソースを使用するのが一般的です。 次のリソースはすべて、 既存のネットワーク セキュリティ境界に参加させることができます。
対象となるサービスの完全な一覧については、「 オンボードされたプライベート リンク リソース」を参照してください。
Authentication
検索サービス宛ての要求が承認された後も、要求が許可されているかどうかを判断する認証と認可を受ける必要があります。 Azure AI Search は、2 つの方法をサポートします。
Microsoft Entra 認証では、認証された ID として (要求ではなく) 呼び出し元が確立されます。 Azure ロールの割り当てが認可を決定します。
キーベースの認証は、API キーにより (呼び出し元のアプリやユーザーではなく) 要求に対して行われます。このキーは、要求が信頼できるソースからの要求であることを証明する、ランダムに生成された数字と文字で構成される文字列です。 キーは要求ごとに必要です。 有効なキーの送信は、要求が信頼されたエンティティのものであることの証明と見なされます。
API キーベースの認証に依存するということは、Azure のセキュリティのベスト プラクティスに従って、定期的に管理者キーを再生成するための計画を立てる必要があることを意味します。 Search サービスごとに最大 2 個の管理キーがあります。 API キーのセキュリティと管理の詳細については、API キーの作成と管理に関する記事を参照してください。
キーベースの認証は、データ プレーン操作 (検索サービスでのオブジェクトの作成と使用) の既定値です。 両方の認証方法を使用することも、検索サービスで使用可能にしない方法を無効にすることもできます。
Authorization
Azure AI Search には、サービス管理とコンテンツ管理のためのさまざまな認可モデルが用意されています。
特権アクセス
新しい検索サービスでは、サブスクリプション レベルの既存のロールの割り当てが検索サービスによって継承され、所有者とユーザー アクセス管理者のみがアクセス権を付与できます。
コントロール プレーン操作 (サービスまたはリソースの作成と管理) タスクは 、ロールの割り当てによって排他的に承認され、サービス管理にキーベースの認証を使用することはできません。
コントロール プレーンの操作には、サービスの作成、構成、削除、およびセキュリティの管理が含まれます。 そのため、ポータル、PowerShell、Management REST API のどれを使用しているかにかかわらず、Azure で割り当てられているロールによって、これらのタスクを実行できるユーザーが決定されます。
3 つの基本ロール (所有者、共同作成者、閲覧者) が検索サービスの管理に適用されます。
Note
Azure 全体のメカニズムを使用して、サブスクリプションまたはリソースをロックし、管理者権限を持つユーザーが検索サービスを誤って、または許可なく削除しないようにすることができます。 詳細については、リソースのロックによる予期せぬ削除の防止に関するページを参照してください。
コンテンツへのアクセスを承認する
データ プレーン操作は、検索サービスで作成および使用されるオブジェクトを指します。
ロールベースの認可の場合、Azure のロールの割り当てを使用して、操作に対する読み書きアクセスを確立します。
キーベースの認可の場合、API キーと修飾されたエンドポイントによってアクセスが決定されます。 エンドポイントはサービス自体、インデックス コレクション、特定のインデックス、ドキュメント コレクション、特定のドキュメントなどである場合があります。 連結されている場合、エンドポイント、操作 (作成要求など)、キーの種類 (管理者またはクエリ) によってコンテンツへのアクセスと操作が承認されます。
インデックスへのアクセスの制限
Azure ロールを使用している場合は、プログラムによって実行される限り、個々のインデックスに対するアクセス許可を設定できます。
キーを使用すると、サービスに対する管理者キーを持っている人は誰でも、そのサービスのインデックスの読み取り、変更、削除を行えます。 インデックスが誤って削除されたり、悪意によって削除されたりすることを防止するうえで、コード資産の社内ソース管理は、望ましくないインデックスの削除または変更を元に戻すための解決策になります。 Azure AI Search は可用性を確保するためにクラスター内のフェールオーバーを備えていますが、インデックスの作成または読み込みに使用される専用コードを格納したり実行したりしません。
インデックス レベルでセキュリティ境界を必要とするマルチテナント ソリューションの場合、通常、アプリケーション コードの中間層でインデックス分離を処理します。 マルチテナントのユース ケースの詳細については、「マルチテナント SaaS アプリケーションと Azure AI Search の設計パターン」を参照してください。
ドキュメントへのアクセスの制限
ドキュメント レベルのユーザーアクセス許可 ( 行レベルのセキュリティとも呼ばれます) は、プレビュー機能として使用でき、データ ソースによって異なります。 コンテンツが Azure Data Lake Storage (ADLS) Gen2 または Azure BLOB から生成された場合、Azure Storage に由来するユーザーアクセス許可メタデータはインデクサーによって生成されたインデックスに保持され、クエリ時に適用されるため、承認されたコンテンツのみが検索結果に含まれます。
他のデータ ソースの場合は、 ユーザーまたはグループのアクセス許可メタデータを含むドキュメント ペイロードをプッシュできます。これらのアクセス許可はインデックス付きコンテンツに保持され、クエリ時にも適用されます。 この機能もプレビュー段階にあります。
プレビュー機能を使用できない場合に、検索結果のコンテンツに対するアクセス許可が必要な場合は、ユーザー ID に基づいてドキュメントを含めたり除外したりするフィルターを適用する手法があります。 この回避策では、グループまたはユーザー ID を表す文字列フィールドをデータ ソースに追加します。このフィールドは、インデックスでフィルター可能にできます。 このパターンの詳細については、「ID フィルターに基づくセキュリティ トリミング」を参照してください。 ドキュメント アクセスの詳細については、「 ドキュメント レベルのアクセス制御」を参照してください。
データの保存場所
検索サービスを設定するときに、顧客データがどこで格納および処理されるかを決定するリージョンを選びます。 各リージョンは、多くの場合、複数のリージョンを含む地理的な場所 (Geo) 内に存在します (たとえば、スイスはスイス北部とスイス西部を含む Geo です)。 Azure AI 検索では、持続性と高可用性のために、同じ Geo 内の別のリージョンにデータをレプリケートする場合があります。 構成した機能が別の Azure リソースに依存し、そのリソースが別のリージョンにプロビジョニングされている場合を除き、指定した Geo の外部で顧客データがサービスによって格納されたり、処理されることはありません。
現在、検索サービスが書き込む唯一の外部リソースは Azure Storage です。 ストレージ アカウントは、お客様が指定したストレージ アカウントであり、任意のリージョンに存在する可能性があります。 次のいずれかの機能を使用する場合、検索サービスによって Azure Storage への書き込みが行われます。
データ所在地の詳細については、「Azure でのデータ所在地」を参照してください。
データ所在地のコミットメントに対する例外
オブジェクト名は、Microsoft がサービスのサポートを提供するために使うテレメトリ ログに表示されます。 オブジェクト名は、選択されたリージョンまたは場所以外で格納され、処理されます。 オブジェクト名には、インデックスとインデックス フィールド、エイリアス、インデクサー、データ ソース、スキルセット、シノニム マップ、リソース、コンテナー、キー コンテナー ストアの名前が含まれます。 お客様は、名前のフィールドに機密データを配置することや、これらのフィールドに機密データが格納されるように設計したアプリケーションを作成することはできません。
テレメトリ ログは 1 年半保持されます。 その間、Microsoft は次の条件下でオブジェクト名にアクセスして参照する場合があります。
問題の診断、機能の改善、バグの修正を行います。 このシナリオでは、データ アクセスは内部のみであり、サード パーティがアクセスすることはありません。
サポート中、問題への迅速な解決策を提供し、必要に応じて製品チームを昇格させるために、この情報が使用される場合があります
データ保護
ストレージ層には、インデックスやシノニム マップ、およびインデクサー、データ ソース、スキルセットの定義など、ディスクに保存されるすべてのサービス マネージド コンテンツに対するデータ暗号化が組み込まれています。 サービス マネージド暗号化は、長期データ ストレージと一時データ ストレージの両方に適用されます。
必要に応じて、インデックス付きコンテンツの補足暗号化用にカスタマー マネージド キー (CMK) を追加し、保存データの二重暗号化を行うことができます。 2020 年 8 月 1 日以降に作成されたサービスでは、CMK 暗号化は一時ディスクの短期データにも拡張されています。
転送中のデータ
パブリック インターネット経由の検索サービス接続の場合、Azure AI 検索では HTTPS ポート 443 がリッスンされます。
Azure AI 検索では、クライアントからサービスへのチャネル暗号化のために TLS 1.2 と 1.3 がサポートされています。
- TLS 1.3 は、新しいクライアント オペレーティング システムおよびバージョンの .NET の既定値です。
- 古いシステムでは TLS 1.2 が既定値ですが、クライアント要求で TLS 1.3 を明示的に設定できます。
以前のバージョン (1.0 または 1.1) の TLS はサポートされていません。
詳細については、「.NET Framework での TLS サポート」を参照してください。
使用中のデータ
既定では、Azure AI Search は標準の Azure インフラストラクチャに検索サービスをデプロイします。 このインフラストラクチャでは、保存中および転送中のデータが暗号化されますが、メモリ内でアクティブに処理されている間はデータは保護されません。
必要に応じて、 Azure portal または サービス - 作成または更新 (REST API) を使用して、サービスの作成時にコンフィデンシャル コンピューティングを構成できます。 コンフィデンシャル コンピューティングは、ハードウェア構成証明と暗号化を通じて、Microsoft を含む未承認のアクセスから使用中のデータを保護します。 詳細については、「 コンフィデンシャル コンピューティングのユース ケース」を参照してください。
次の表では、両方のコンピューティングの種類を比較します。
| コンピューティングの種類 | Description | 制限事項 | 費用 | 可用性 |
|---|---|---|---|---|
| 既定値 | 保存データと転送中データの暗号化が組み込まれた標準 VM 上のデータを処理します。 使用中のデータに対するハードウェア ベースの分離はありません。 | 制限事項なし。 | Free レベルまたは課金対象レベルの基本コストは変更されません。 | すべてのリージョンで使用できます。 |
| 機密 | ハードウェア ベースの信頼された実行環境の機密 VM (DCasv5 または DCesv5) 上のデータを処理します。 計算とメモリをホスト オペレーティング システムやその他の VM から分離します。 | マルチテナント環境1 で実行されるエージェントの取得、セマンティック ランカー、クエリの書き換え、スキルセットの実行、およびインデクサーを無効または制限します。 | 課金対象レベルの基本コストに 10% の追加料金を加算します。 詳細については、 価格に関するページを参照してください。 | 一部のリージョンで使用できます。 詳細については、 サポートされているリージョンの一覧を参照してください。 |
1 このコンピューティングの種類を有効にすると、インデクサーはプライベート実行環境でのみ実行できます。つまり、インデクサーはコンフィデンシャル コンピューティングでホストされている検索クラスターから実行されます。
Important
コンフィデンシャル コンピューティングは、コンプライアンスまたは規制の要件でデータの使用中の保護が必要な組織にのみお勧めします。 毎日の使用では、既定のコンピューティングの種類で十分です。
保存データ
検索サービスによって内部で処理されるデータについて、次の表でデータ暗号化モデルを説明しています。 ナレッジ ストア、インクリメンタル エンリッチメント、インデクサー ベースのインデックス作成などの一部の機能は、他の Azure サービスのデータ構造から読み書きされます。 Azure Storage に依存するサービスでは、そのテクノロジの暗号化機能を使用できます。
| Model | Keys | Requirements | Restrictions | 対象 |
|---|---|---|---|---|
| サーバー側暗号化 | Microsoft のマネージド キー | なし (組み込み) | なし。2018 年 1 月 24 日以降に作成されたコンテンツについては、すべてのリージョンのすべての階層で使用できます。 | データ ディスクと一時ディスク上のコンテンツ (インデックスとシノニム マップ) と定義 (インデクサー、データ ソース、スキルセット) |
| サーバー側暗号化 | カスタマー マネージド キー | Azure Key Vault | 2020 年 8 月 1 日以降に作成されたコンテンツについては、特定のリージョンの請求対象階層で使用できます。 | データ ディスク上のコンテンツ (インデックスとシノニム マップ) と定義 (インデクサー、データ ソース、スキルセット) |
| サーバー側の完全暗号化 | カスタマー マネージド キー | Azure Key Vault | 2021 年 5 月 13 日以降の検索サービスについては、すべてのリージョンの請求対象階層で使用できます。 | データ ディスクと一時ディスク上のコンテンツ (インデックスとシノニム マップ) と定義 (インデクサー、データ ソース、スキルセット) |
CMK 暗号化を導入すると、コンテンツが 2 回暗号化されます。 前のセクションで説明したオブジェクトとフィールドの場合、コンテンツは最初に CMK で暗号化され、次に Microsoft マネージド キーを使用して暗号化されます。 コンテンツは、長期ストレージ用のデータ ディスクと、短期ストレージに使用される一時ディスク上で二重に暗号化されます。
サービス マネージド キー
サービス マネージド暗号化とは、256 ビット AES 暗号化を使用する Microsoft 内部操作です。 (2018 年 1 月より前に作成された) 完全に暗号化されていないインデックスに対する増分更新を含む、すべてのインデックス作成で自動的に行われます。
サービス マネージド暗号化は、長期および短期ストレージ上のすべてのコンテンツに適用されます。
カスタマー マネージド キー (CMK)
お客様は、追加の保護とキーを取り消す機能の 2 つの理由で CMK を使用するため、コンテンツへのアクセスが妨げられます。
カスタマー マネージド キーには、別の課金対象サービスである Azure Key Vault が必要です。これは、Azure AI Search と同じ Azure テナントの下にある別のリージョンに存在する可能性があります。
CMK のサポートは、2 つのフェーズでロールアウトされました。 最初のフェーズで検索サービスを作成した場合、CMK 暗号化は長期ストレージと特定のリージョンに制限されていました。 2 番目のフェーズで作成されたサービスは、任意のリージョンで CMK 暗号化を使用できます。 2 番目のウェーブのロールアウトの一環として、コンテンツは長期ストレージと短期ストレージの両方で CMK 暗号化されます。
最初のロールアウトは 2020 年 8 月 1 日で、次の 5 つのリージョンが含まれていました。 次のリージョンで作成された検索サービスでは、データ ディスクの CMK がサポートされていましたが、一時ディスクはサポートされていませんでした。
- 米国西部 2
- 米国東部
- 米国中南部
- US Gov バージニア
- US Gov アリゾナ
2021 年 5 月 13 日の 2 回目のロールアウトでは、一時ディスクの暗号化が追加され、CMK 暗号化がすべてのサポートされているリージョンへ拡張されました。
最初のロールアウト中に作成されたサービスから CMK を使用していて、一時ディスクに対する CMK 暗号化も必要な場合は、選択したリージョンで新しい検索サービスを作成し、コンテンツを再デプロイする必要があります。 サービスの作成日を確認するには、「サービスの作成日またはアップグレード日を確認する」を参照してください。
CMK での暗号化を有効にすると、インデックスのサイズが増加し、クエリのパフォーマンスが低下します。 これまでの観測に基づくと、実際のパフォーマンスはインデックスの定義やクエリの種類によって異なりますが、クエリ時間が 30 から 60 パーセント増加することが予想されます。 パフォーマンスへの悪影響があるため、この機能を本当に必要とするインデックスでのみ有効にすることをお勧めします。 詳細については、Azure AI Search でのカスタマー マネージド暗号化キーの構成に関するページを参照してください。
ログ記録と監視
Azure AI Search では、ユーザー ID はログに記録されないため、特定のユーザーに関する情報のログを参照することはできません。 ただし、このサービスでは、ログの作成、読み取り、更新、削除の各操作がログに記録されるため、これらのログを他のログと関連付けて、特定のアクションの機関を理解できる場合があります。
Azure でアラートとログ記録インフラストラクチャを使用すると、クエリ ボリュームの急増や、予想されるワークロードから逸脱したその他のアクションを検出できます。 ログの設定の詳細については、ログ データの収集と分析およびクエリ要求の監視に関する記事を参照してください。
コンプライアンスとガバナンス
Azure AI Search は通常の監査に参加し、パブリック クラウドと Azure Government の両方について、グローバル、リージョン、および業界固有のさまざまな標準に対して認定を受けています。 完全な一覧については、公式の監査レポート ページから Microsoft Azure Compliance Offerings ホワイトペーパーをダウンロードしてください。
Azure AI Search のコンプライアンス認定とドキュメントを定期的に確認して、規制要件に確実に準拠することをお勧めします。
Azure Policy を使用する
コンプライアンスのために、Microsoft クラウド セキュリティ ベンチマークの安全性の高いベスト プラクティスを、Azure Policy を使用して実装できます。 Microsoft クラウド セキュリティ ベンチマークは、サービスやデータに対する脅威を軽減するために実行する必要のある主要なアクションにマップされる、セキュリティ コントロールに体系化された、セキュリティに関する推奨事項を集めたものです。 現在は、ネットワーク セキュリティ、ログ記録および監視、データ保護などを含む 12 のセキュリティ コントロールがあります。
Azure Policy は、Microsoft クラウド セキュリティ ベンチマークの標準を含む複数の標準に対するコンプライアンスの管理に役立つ、Azure に組み込まれた機能です。 広く知られたベンチマークについては、コンプライアンス非対応の場合に使用できる、基準と実施可能な対応の両方の組み込みの定義が、Azure Policy によって提供されています。
Azure AI Search には、現在 1 つの定義が組み込まれています。 これはリソース ログ用です。 リソース ログが欠落している検索サービスを識別するポリシーを割り当てて、有効にできます。 詳細については、「Azure AI Search 用の Azure Policy 規制コンプライアンス コントロール」を参照してください。
タグを使用する
メタデータ タグを適用して、データの機密性とコンプライアンスの要件に基づいて検索サービスを分類します。 これにより、適切なガバナンスとセキュリティ制御が容易になります。 詳細については、「 タグを使用して Azure リソースを整理する 」と 「一般的なガイダンス - タグを使用して Azure リソースを整理する」を参照してください。
関連コンテンツ
次のセキュリティ機能に関するビデオもお勧めします。 これは何年も前のものであり、新しい機能については説明していませんが、CMK、IP ファイアウォール、プライベート リンクなどの機能について説明しています。 これらの機能を使用する場合、このビデオが役立つ可能性があります。