Azure AI Search では、Azure Blob Storage に格納されている PDF ドキュメントからテキストと画像の両方を抽出し、インデックスを作成できます。 このチュートリアルでは、 ドキュメント構造に基づいてデータをチャンク し、 マルチモーダル埋め込みを使用 して同じドキュメントのテキストと画像をベクター化するマルチモーダル インデックス作成パイプラインを構築する方法について説明します。 トリミングされた画像はナレッジ ストアに格納され、テキストコンテンツとビジュアルコンテンツの両方がベクター化され、検索可能なインデックスに取り込まれます。 チャンク技術は、ドキュメント構造を認識するAzure AIのDocument Intelligence Layoutモデルに基づいています。
このチュートリアルでは、次を使用します。
グラフ、インフォグラフィック、スキャンしたページなどの豊富なビジュアル コンテンツと従来のテキストを組み合わせた 36 ページの PDF ドキュメント。
スキルを通じた AI エンリッチメントを含むインデックス作成パイプラインを作成するためのインデクサーとスキルセット。
ページ番号や境界領域など、さまざまなドキュメントからを使用してテキストと正規化された画像を抽出するための
locationMetadata。テキストと画像をベクター化 するための Azure AI Vision マルチモーダル埋め込みスキル 。
抽出されたテキストと画像の内容を格納するように構成された検索インデックス。 一部のコンテンツは、ベクターベースの類似性検索のためにベクター化されます。
Prerequisites
Azure AI サービスのマルチサービス アカウント。 このアカウントでは、Azure AI Vision マルチモーダル埋め込みモデルと、このチュートリアルのスキルで使用されるドキュメント インテリジェンス レイアウト モデルの両方にアクセスできます。 これらのリソースへのスキルセット アクセスには、Azure AI マルチサービス アカウントを使用する必要があります。
Azure AI 検索. ロールベースのアクセス制御とマネージド ID 用に検索サービスを構成します。 サービスは Basic レベル以上である必要があります。 このチュートリアルは Free レベルではサポートされていません。
Azure Storage。サンプル データの格納と ナレッジ ストアの作成に使用されます。
Limitations
ドキュメント レイアウト スキルでは、リージョンの可用性が制限されています。 マルチサービス アカウントをインストールするときに、マルチモーダル埋め込みを提供するリージョンを選択します。 サポートされているリージョンの一覧については、「 ドキュメント レイアウト スキル> サポートされているリージョン」を参照してください。
Azure AI Vision マルチモーダル 埋め込みスキルでは、リージョンの可用性も制限されています。 マルチモーダル埋め込みを提供するリージョンの更新された一覧については、 Azure AI Vision のドキュメントを参照してください。
データを準備する
次の手順は、サンプル データを提供し、ナレッジ ストアもホストする Azure Storage に適用されます。 検索サービス ID では、サンプル データを取得するために Azure Storage への読み取りアクセス権が必要であり、ナレッジ ストアを作成するには書き込みアクセス権が必要です。 検索サービスは、環境変数に指定した名前を使用して、スキルセットの処理中にトリミングされたイメージのコンテナーを作成します。
次のサンプル PDF をダウンロードします 。sustainable-ai-pdf
Azure Storage で、 sustainable-ai-pdf という名前の新しいコンテナーを作成します。
ロールの割り当てを作成し、接続文字列でマネージド ID を指定します。
インデクサーによるデータ取得のために ストレージ BLOB データ リーダー を割り当てます。 ナレッジ ストアを作成して読み込むには、 ストレージ BLOB データ共同作成者 と ストレージ テーブル データ共同作成者 を割り当てます。 検索サービス ロールの割り当てには、システム割り当てマネージド ID またはユーザー割り当てマネージド ID を使用できます。
システム割り当てマネージド ID を使用して行われた接続の場合は、アカウント キーまたはパスワードなしで ResourceId を含む接続文字列を取得します。 ResourceId には、ストレージ アカウントのサブスクリプション ID、ストレージ アカウントのリソース グループ、およびストレージ アカウント名を含める必要があります。 接続文字列は、次の例のような URL です:
"credentials" : { "connectionString" : "ResourceId=/subscriptions/00000000-0000-0000-0000-00000000/resourceGroups/MY-DEMO-RESOURCE-GROUP/providers/Microsoft.Storage/storageAccounts/MY-DEMO-STORAGE-ACCOUNT/;" }ユーザー割り当てマネージド ID を使用して行われた接続の場合は、アカウント キーまたはパスワードなしで ResourceId を含む接続文字列を取得します。 ResourceId には、ストレージ アカウントのサブスクリプション ID、ストレージ アカウントのリソース グループ、およびストレージ アカウント名を含める必要があります。 次の例に示す構文を使用して ID を指定します。 userAssignedIdentity をユーザー割り当てマネージド ID に設定します。 接続文字列は、次の例のような URL です:
"credentials" : { "connectionString" : "ResourceId=/subscriptions/00000000-0000-0000-0000-00000000/resourceGroups/MY-DEMO-RESOURCE-GROUP/providers/Microsoft.Storage/storageAccounts/MY-DEMO-STORAGE-ACCOUNT/;" }, "identity" : { "@odata.type": "#Microsoft.Azure.Search.DataUserAssignedIdentity", "userAssignedIdentity" : "/subscriptions/00000000-0000-0000-0000-00000000/resourcegroups/MY-DEMO-RESOURCE-GROUP/providers/Microsoft.ManagedIdentity/userAssignedIdentities/MY-DEMO-USER-MANAGED-IDENTITY" }
モデルを準備する
このチュートリアルでは、スキルが Azure AI Vision マルチモーダル 4.0 埋め込みモデルを呼び出す既存の Azure AI マルチサービス アカウントがあることを前提としています。 検索サービスは、マネージド ID を使用してスキルセットの処理中にモデルに接続します。 このセクションでは、承認されたアクセスのロールを割り当てるためのガイダンスとリンクを示します。
Azure AI マルチサービス アカウントを使用してドキュメント インテリジェンス レイアウト モデルにアクセスする場合にも、同じロールの割り当てが使用されます。
(Foundry ポータルではなく) Azure portal にサインインし、Azure AI マルチサービス アカウントを見つけます。 マルチモーダル 4.0 API とドキュメント インテリジェンス レイアウト モデルを提供するリージョンにあることを確認します。
[アクセス制御 (IAM)] を選択します。
[ 追加] を選択し、[ ロールの割り当ての追加] を選択します。
Cognitive Services のユーザーを検索し、それを選択します。
[ マネージド ID] を 選択し、 検索サービスのマネージド ID を割り当てます。
REST ファイルを設定する
このチュートリアルでは、Azure AI Search へのローカル REST クライアント接続にエンドポイントと API キーが必要です。 これらの値は Azure portal から取得できます。 別の接続方法については、「 検索サービスへの接続」を参照してください。
インデクサーとスキルセットの処理中に発生する認証済み接続の場合、検索サービスでは、前に定義したロールの割り当てが使用されます。
Visual Studio Code を起動して、新しいファイルを作成します。
要求で使用される変数の値を指定します。
@storageConnectionの場合は、接続文字列に末尾のセミコロンまたは引用符がないことを確認します。@imageProjectionContainerの場合は、BLOB ストレージで一意のコンテナー名を指定します。 Azure AI Search では、スキルの処理中にこのコンテナーが自動的に作成されます。@searchUrl = PUT-YOUR-SEARCH-SERVICE-ENDPOINT-HERE @searchApiKey = PUT-YOUR-ADMIN-API-KEY-HERE @storageConnection = PUT-YOUR-STORAGE-CONNECTION-STRING-HERE @cognitiveServicesUrl = PUT-YOUR-AZURE-AI-MULTI-SERVICE-ENDPOINT-HERE @modelVersion = 2023-04-15 @imageProjectionContainer=sustainable-ai-pdf-imagesファイル拡張子
.restまたは.httpを使用してファイルを保存します。 REST クライアントのヘルプについては、「 クイック スタート: REST を使用したフルテキスト検索」を参照してください。
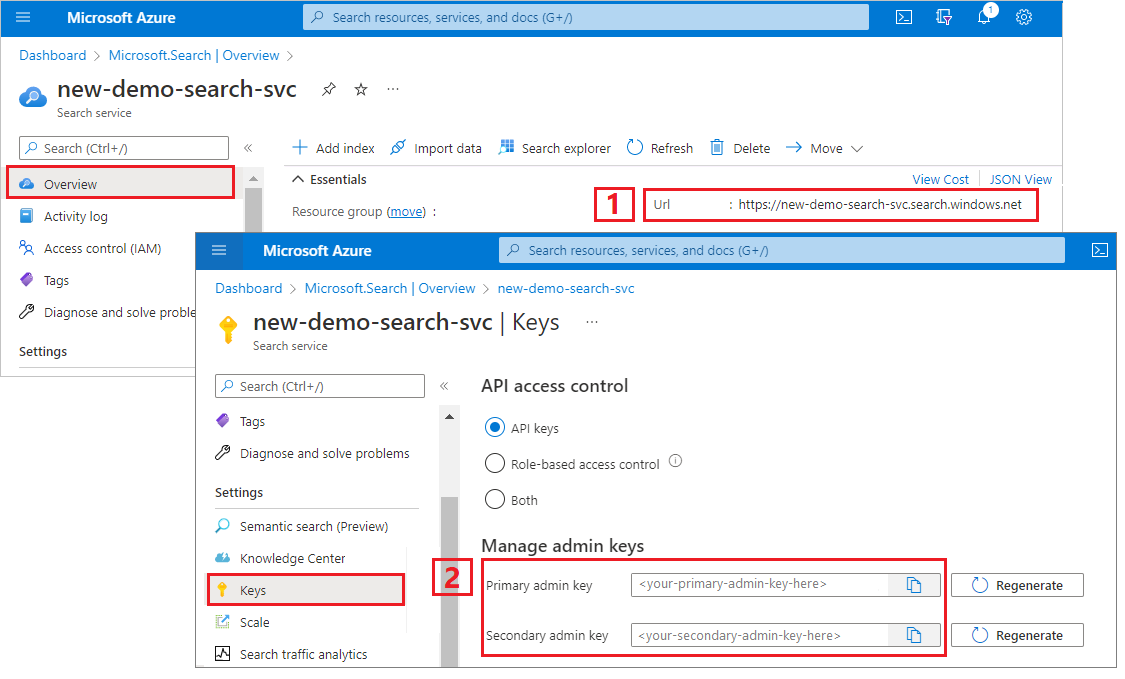
Azure AI Search エンドポイントと API キーを取得するには:
Azure portal にサインインし、検索サービスの [概要] ページに移動して URL をコピーします。 たとえば、エンドポイントは
https://mydemo.search.windows.netのようになります。[設定]>[キー] で管理者キーをコピーします。 管理者キーは、オブジェクトの追加、変更、削除で使用します。 2 つの交換可能な管理者キーがあります。 どちらかをコピーします。
データ ソースを作成する
データ ソースの作成 (REST) では、インデックスを付けるデータを指定するデータ ソース接続を作成します。
### Create a data source using system-assigned managed identities
POST {{searchUrl}}/datasources?api-version=2025-08-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{searchApiKey}}
{
"name": "doc-intelligence-multimodal-embedding-ds",
"description": "A data source to store multimodal documents",
"type": "azureblob",
"subtype": null,
"credentials":{
"connectionString":"{{storageConnection}}"
},
"container": {
"name": "sustainable-ai-pdf",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null,
"encryptionKey": null,
"identity": null
}
要求を送信します。 応答は次のようになります。
HTTP/1.1 201 Created
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Location: https://<YOUR-SEARCH-SERVICE-NAME>.search.windows-int.net:443/datasources('doc-extraction-multimodal-embedding-ds')?api-version=2025-08-01-preview -Preview
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 4eb8bcc3-27b5-44af-834e-295ed078e8ed
elapsed-time: 346
Date: Sat, 26 Apr 2025 21:25:24 GMT
Connection: close
{
"name": "doc-extraction-multimodal-embedding-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"indexerPermissionOptions": [],
"credentials": {
"connectionString": null
},
"container": {
"name": "sustainable-ai-pdf",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null,
"encryptionKey": null,
"identity": null
}
インデックスを作成する
インデックスの作成 (REST) では、検索サービスに検索インデックスを作成します。 インデックスでは、すべてのパラメーターとその属性を指定します。
入れ子になった JSON の場合、インデックス フィールドはソース フィールドと同じである必要があります。 現在、Azure AI Search では入れ子になった JSON へのフィールド マッピングはサポートされていないため、フィールド名とデータ型は完全に一致する必要があります。 次のインデックスは、生コンテンツの JSON 要素に合わせて配置されます。
### Create an index
POST {{searchUrl}}/indexes?api-version=2025-08-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{searchApiKey}}
{
"name": "doc-intelligence-multimodal-embedding-index",
"fields": [
{
"name": "content_id",
"type": "Edm.String",
"retrievable": true,
"key": true,
"analyzer": "keyword"
},
{
"name": "text_document_id",
"type": "Edm.String",
"searchable": false,
"filterable": true,
"retrievable": true,
"stored": true,
"sortable": false,
"facetable": false
},
{
"name": "document_title",
"type": "Edm.String",
"searchable": true
},
{
"name": "image_document_id",
"type": "Edm.String",
"filterable": true,
"retrievable": true
},
{
"name": "content_text",
"type": "Edm.String",
"searchable": true,
"retrievable": true
},
{
"name": "content_embedding",
"type": "Collection(Edm.Single)",
"dimensions": 1024,
"searchable": true,
"retrievable": true,
"vectorSearchProfile": "hnsw"
},
{
"name": "content_path",
"type": "Edm.String",
"searchable": false,
"retrievable": true
},
{
"name": "offset",
"type": "Edm.String",
"searchable": false,
"retrievable": true
},
{
"name": "location_metadata",
"type": "Edm.ComplexType",
"fields": [
{
"name": "page_number",
"type": "Edm.Int32",
"searchable": false,
"retrievable": true
},
{
"name": "bounding_polygons",
"type": "Edm.String",
"searchable": false,
"retrievable": true,
"filterable": false,
"sortable": false,
"facetable": false
}
]
}
],
"vectorSearch": {
"profiles": [
{
"name": "hnsw",
"algorithm": "defaulthnsw",
"vectorizer": "demo-vectorizer"
}
],
"algorithms": [
{
"name": "defaulthnsw",
"kind": "hnsw",
"hnswParameters": {
"m": 4,
"efConstruction": 400,
"metric": "cosine"
}
}
],
"vectorizers": [
{
"name": "demo-vectorizer",
"kind": "aiServicesVision",
"aiServicesVisionParameters": {
"resourceUri": "{{cognitiveServicesUrl}}",
"authIdentity": null,
"modelVersion": "{{modelVersion}}"
}
}
]
},
"semantic": {
"defaultConfiguration": "semanticconfig",
"configurations": [
{
"name": "semanticconfig",
"prioritizedFields": {
"titleField": {
"fieldName": "document_title"
},
"prioritizedContentFields": [
],
"prioritizedKeywordsFields": []
}
}
]
}
}
重要なポイント:
テキストと画像の埋め込みは、
content_embeddingフィールドに格納され、1024 などの適切な次元とベクター検索プロファイルで構成する必要があります。location_metadataは、各テキスト チャンクと正規化された画像の境界ポリゴンとページ番号のメタデータをキャプチャし、正確な空間検索または UI オーバーレイを可能にします。ベクター検索の詳細については、「 Azure AI Search のベクター」を参照してください。
セマンティック ランク付けの詳細については、「 Azure AI Search でのセマンティックランク付け」を参照してください。
スキルセットを作成する
スキルセット (REST) を作成 すると、検索サービスにスキルセットが作成されます。 スキルセットは、インデックス作成の前にコンテンツをチャンクして埋め込む操作を定義します。 このスキルセットでは、Document Layout スキルを使用してテキストと画像を抽出し、RAG アプリケーションでの引用に役立つ場所のメタデータを保持します。 Azure AI Vision マルチモーダル埋め込みスキルを使用して、画像とテキストのコンテンツをベクター化します。
### Create a skillset
POST {{searchUrl}}/skillsets?api-version=2025-08-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{searchApiKey}}
{
"name": "doc-intelligence-multimodal-embedding-skillset",
"description": "A sample skillset for multimodal using multimodal embedding",
"skills": [
{
"@odata.type": "#Microsoft.Skills.Util.DocumentIntelligenceLayoutSkill",
"name": "document-layout-skill",
"description": "Document Intelligence skill for document cracking",
"context": "/document",
"outputMode": "oneToMany",
"outputFormat": "text",
"extractionOptions": ["images", "locationMetadata"],
"chunkingProperties": {
"unit": "characters",
"maximumLength": 2000,
"overlapLength": 200
},
"inputs": [
{
"name": "file_data",
"source": "/document/file_data"
}
],
"outputs": [
{
"name": "text_sections",
"targetName": "text_sections"
},
{
"name": "normalized_images",
"targetName": "normalized_images"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Vision.VectorizeSkill",
"name": "text-embedding-skill",
"description": "Vision Vectorization skill for text",
"context": "/document/text_sections/*",
"modelVersion": "2023-04-15",
"inputs": [
{
"name": "text",
"source": "/document/text_sections/*/content"
}
],
"outputs": [
{
"name": "vector",
"targetName": "text_vector"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Vision.VectorizeSkill",
"name": "image-embedding-skill",
"description": "Vision Vectorization skill for images",
"context": "/document/normalized_images/*",
"modelVersion": "2023-04-15",
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "vector",
"targetName": "image_vector"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Util.ShaperSkill",
"name": "shaper-skill",
"context": "/document/normalized_images/*",
"inputs": [
{
"name": "normalized_images",
"source": "/document/normalized_images/*",
"inputs": []
},
{
"name": "imagePath",
"source": "='my_container_name/'+$(/document/normalized_images/*/imagePath)",
"inputs": []
}
],
"outputs": [
{
"name": "output",
"targetName": "new_normalized_images"
}
]
}
],
"indexProjections": {
"selectors": [
{
"targetIndexName": "doc-intelligence-multimodal-embedding-index",
"parentKeyFieldName": "text_document_id",
"sourceContext": "/document/text_sections/*",
"mappings": [
{
"name": "content_embedding",
"source": "/document/text_sections/*/text_vector"
},
{
"name": "content_text",
"source": "/document/text_sections/*/content"
},
{
"name": "location_metadata",
"source": "/document/text_sections/*/locationMetadata"
},
{
"name": "document_title",
"source": "/document/document_title"
}
]
},
{
"targetIndexName": "{{index}}",
"parentKeyFieldName": "image_document_id",
"sourceContext": "/document/normalized_images/*",
"mappings": [
{
"name": "content_embedding",
"source": "/document/normalized_images/*/image_vector"
},
{
"name": "content_path",
"source": "/document/normalized_images/*/new_normalized_images/imagePath"
},
{
"name": "document_title",
"source": "/document/document_title"
},
{
"name": "location_metadata",
"source": "/document/normalized_images/*/locationMetadata"
}
]
}
],
"parameters": {
"projectionMode": "skipIndexingParentDocuments"
}
},
"cognitiveServices": {
"@odata.type": "#Microsoft.Azure.Search.AIServicesByIdentity",
"subdomainUrl": "{{cognitiveServicesUrl}}",
"identity": null
},
"knowledgeStore": {
"storageConnectionString": "",
"identity": null,
"projections": [
{
"files": [
{
"storageContainer": "{{imageProjectionContainer}}",
"source": "/document/normalized_images/*"
}
]
}
]
}
}
このスキルセットは、テキストと画像を抽出し、両方をベクター化し、インデックスに投影するための画像メタデータを図形化します。
重要なポイント:
content_textフィールドには、ドキュメント レイアウト スキルを使用して抽出およびチャンクされたテキストが入力されます。content_pathには、指定されたイメージ プロジェクション コンテナー内のイメージ ファイルへの相対パスが含まれています。 このフィールドは、extractOptionが["images", "locationMetadata"]または["images"]に設定されている場合にドキュメントから抽出されたイメージに対してのみ生成され、ソース フィールド/document/normalized_images/*/imagePathからエンリッチメントされたドキュメントからマップできます。Azure AI Vision マルチモーダル埋め込みスキルを使用すると、入力 (テキストと画像) で区別される同じスキルの種類を使用して、テキストデータとビジュアル データの両方を埋め込めます。 詳細については、 Azure AI Vision のマルチモーダル 埋め込みスキルに関するページを参照してください。
インデクサーの作成と実行
インデクサーの作成では、検索サービスにインデクサーを作成します。 インデクサーは、データ ソースに接続し、データを読み込み、スキルセットを実行し、エンリッチされたデータのインデックスを作成します。
### Create and run an indexer
POST {{searchUrl}}/indexers?api-version=2025-08-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{searchApiKey}}
{
"dataSourceName": "doc-intelligence-multimodal-embedding-ds",
"targetIndexName": "doc-intelligence-multimodal-embedding-index",
"skillsetName": "doc-intelligence-multimodal-embedding-skillset",
"parameters": {
"maxFailedItems": -1,
"maxFailedItemsPerBatch": 0,
"batchSize": 1,
"configuration": {
"allowSkillsetToReadFileData": true
}
},
"fieldMappings": [
{
"sourceFieldName": "metadata_storage_name",
"targetFieldName": "document_title"
}
],
"outputFieldMappings": []
}
クエリを実行する
最初のドキュメントが読み込まれたらすぐに、検索を始めることができます。
### Query the index
POST {{searchUrl}}/indexes/doc-intelligence-multimodal-embedding-index/docs/search?api-version=2025-08-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{searchApiKey}}
{
"search": "*",
"count": true
}
要求を送信します。 これは、インデックスで取得可能としてマークされているすべてのフィールドとドキュメント数を返す、指定されていないフルテキスト検索クエリです。 応答は次のようになります。
{
"@odata.count": 100,
"@search.nextPageParameters": {
"search": "*",
"count": true,
"skip": 50
},
"value": [
],
"@odata.nextLink": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes/doc-intelligence-multimodal-embedding-index/docs/search?api-version=2025-08-01-preview "
}
応答で 100 個のドキュメントが返されます。
フィルター処理のため、論理演算子 (and、or、not) と比較演算子 (eq、ne、gt、lt、ge、le) を使用することもできます。 文字列比較では大文字と小文字が区別されます。 詳細と例については、 単純な検索クエリの例を参照してください。
Note
$filter パラメーターは、インデックスの作成時にフィルター可能としてマークされたフィールドでのみ機能します。
### Query for only images
POST {{searchUrl}}/indexes/doc-intelligence-multimodal-embedding-index/docs/search?api-version=2025-08-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{searchApiKey}}
{
"search": "*",
"count": true,
"filter": "image_document_id ne null"
}
### Query for text or images with content related to energy, returning the id, parent document, and text (only populated for text chunks), and the content path where the image is saved in the knowledge store (only populated for images)
POST {{searchUrl}}/indexes/doc-intelligence-multimodal-embedding-index/docs/search?api-version=2025-08-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{searchApiKey}}
{
"search": "energy",
"count": true,
"select": "content_id, document_title, content_text, content_path"
}
リセットして再実行する
インデクサーをリセットして実行履歴をクリアすると、完全な再実行が可能になります。 次の POST 要求はリセット用であり、その後に再実行されます。
### Reset the indexer
POST {{searchUrl}}/indexers/doc-intelligence-multimodal-embedding-indexer/reset?api-version=2025-08-01-preview HTTP/1.1
api-key: {{searchApiKey}}
### Run the indexer
POST {{searchUrl}}/indexers/doc-intelligence-multimodal-embedding-indexer/run?api-version=2025-08-01-preview HTTP/1.1
api-key: {{searchApiKey}}
### Check indexer status
GET {{searchUrl}}/indexers/doc-intelligence-multimodal-embedding-indexer/status?api-version=2025-08-01-preview HTTP/1.1
api-key: {{searchApiKey}}
リソースをクリーンアップする
所有するサブスクリプションを使用している場合は、プロジェクトの終了時に、不要になったリソースを削除することをお勧めします。 リソースを稼働させたままにすると、費用がかかる場合があります。 リソースを個別に削除することも、リソース グループを削除してリソースのセット全体を削除することもできます。
Azure portal を使って、インデックス、インデクサー、データ ソースを削除できます。
こちらも参照ください
マルチモーダル インデックス作成シナリオのサンプル実装に慣れたので、次の点を確認してください。