Jupyter Notebook は、Microsoft Sentinel データ レイク内のデータを探索、分析、視覚化するための対話型環境を提供します。 ノートブックを使用すると、コードの記述と実行、ワークフローの文書化、結果の表示をすべて 1 か所で行うことができます。 これにより、データ探索の実行、高度な分析ソリューションの構築、他のユーザーとの分析情報の共有が簡単になります。 Visual Studio Code 内で Python と Apache Spark を活用することで、ノートブックは生のセキュリティ データを実用的なインテリジェンスに変換するのに役立ちます。
この記事では、Visual Studio Code で Jupyter Notebook を使用して Data Lake データを探索および操作する方法について説明します。
注
Microsoft Sentinel 拡張機能は現在プレビュー段階です。 一部の機能とパフォーマンスの制限は、新しいリリースが利用可能になった時点で変更される可能性があります。
[前提条件]
Microsoft Sentinel データ レイクに参加する
Microsoft Sentinel データ レイクでノートブックを使用するには、まず Data Lake にオンボードする必要があります。 Microsoft Sentinel データ レイクにオンボードしていない場合は、「 Microsoft Sentinel Data Lake へのオンボード」を参照してください。 Data Lake に最近オンボードした場合、ノートブックを使用して意味のある分析を作成するには、十分な量のデータが取り込まれるまで時間がかかる場合があります。
権限
Microsoft Entra ID ロールは、データ レイク内のすべてのワークスペースに広範なアクセスを提供します。 または、Azure RBAC ロールを使用して、個々のワークスペースへのアクセス権を付与することもできます。 Microsoft Sentinel ワークスペースに対する Azure RBAC アクセス許可を持つユーザーは、Data Lake レベルのワークスペースに対してノートブックを実行できます。 詳細については、「 Microsoft Sentinel のロールとアクセス許可」を参照してください。
分析レベルで新しいカスタム テーブルを作成するには、Data Lake マネージド ID に Log Analytics ワークスペースの Log Analytics 共同作成者 ロールを割り当てる必要があります。
ロールを割り当てるには、次の手順に従います。
- Azure portal で、ロールを割り当てる Log Analytics ワークスペースに移動します。
- 左側のナビゲーション ペインで [アクセス制御 (IAM)] を選択します。
- [ロールの割り当ての追加] を選択します。
- [ロール] テーブルで、[Log Analytics 共同作成者] を選択し、[次へ] を選択します。
- [ マネージド ID] を選択し、[ メンバーの選択] を選択します。
- あなたのデータレイクのマネージド ID は、
msg-resources-<guid>という名前のシステム割り当てマネージド ID です。 マネージド ID を選択し、[選択] をクリックします。 - 「Review and assign」を選択します。
マネージド ID へのロールの割り当ての詳細については、 Azure portal を使用した Azure ロールの割り当てに関するページを参照してください。
Visual Studio Code と Microsoft Sentinel 拡張機能をインストールする
Visual Studio Code をまだお持ちでない場合は、Visual Studio Code for Mac、 Linux、または Windows をダウンロードしてインストール します。
Visual Studio Code (VS Code) 用の Microsoft Sentinel 拡張機能は、拡張機能マーケットプレースからインストールされます。 拡張機能をインストールするには、次の手順に従います。
- 左側のツール バーで Extensions Marketplace を選択します。
- Sentinel を検索します。
- Microsoft Sentinel 拡張機能を選択し、[インストール] を選択します。
- 拡張機能がインストールされると、Microsoft Sentinel のシールド アイコンが左側のツール バーに表示されます。

Visual Studio Code 用の GitHub Copilot 拡張機能をインストールして、ノートブックでのコード補完と提案を有効にします。
- Extensions Marketplace で GitHub Copilot を検索してインストールします。
- インストール後、GitHub アカウントを使用して GitHub Copilot にサインインします。
データ レイク レベル テーブルを探す
Microsoft Sentinel 拡張機能をインストールしたら、データ レイク層テーブルの探索と、データを分析するための Jupyter ノートブックの作成を開始できます。
Microsoft Sentinel 拡張機能にサインインする
左側のツール バーの Microsoft Sentinel シールド アイコンを選択します。
次のテキストを含むダイアログが表示されます 。拡張機能 "Microsoft Sentinel" は Microsoft を使用してサインインしたいと考えています。 [許可] を選択します。
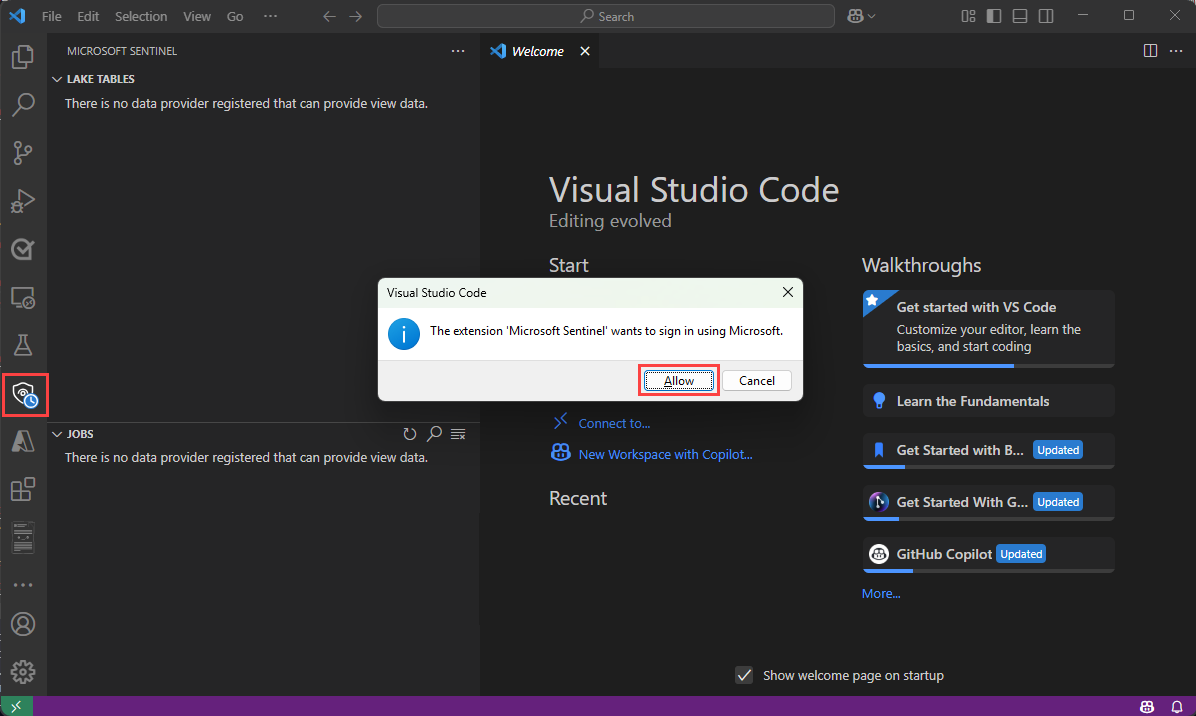
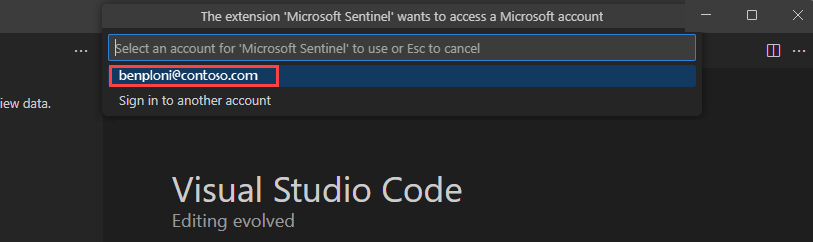
アカウント名を選択してサインインを完了します。


データ レイク テーブルとジョブを表示する
サインインすると、Microsoft Sentinel 拡張機能の左側のウィンドウに 、Lake テーブル と ジョブ の一覧が表示されます。 テーブルを選択すると、列の定義が表示されます。
ジョブの詳細については、「 ジョブとスケジュール」を参照してください。

新しいノートブックを作成する
新しいノートブックを作成するには、次のいずれかの方法を使用します。
検索ボックスに「 > 」と入力するか、 Ctrl + Shift + P キーを押して、「 Create New Jupyter Notebook」と入力します。

[ファイル] > [新しいファイル] を選択し、ドロップダウンから [Jupyter Notebook ] を選択します。

新しいノートブックで、次のコードを最初のセルに貼り付けます。
from sentinel_lake.providers import MicrosoftSentinelProvider data_provider = MicrosoftSentinelProvider(spark) table_name = "EntraGroups" df = data_provider.read_table(table_name) df.select("displayName", "groupTypes", "mail", "mailNickname", "description", "tenantId").show(100, truncate=False)実行 三角形を選択して、ノートブックでコードを実行します。 結果は、コード セルの下の出力ウィンドウに表示されます。

ランタイム プールの一覧の一覧から Microsoft Sentinel を選択します。

[中] を選択して、中規模のランタイム プールでノートブックを実行します。 さまざまなランタイムの詳細については、「 適切な Microsoft Sentinel ランタイムの選択」を参照してください。






注
カーネルを選択すると、Spark セッションが開始され、ノートブックでコードが実行されます。 プールを選択した後、セッションが開始されるまでに 3 ~ 5 分かかる場合があります。 セッションが既にアクティブになっているので、後続の実行時間が短縮されます。
セッションが開始されると、ノートブック内のコードが実行され、結果がコード セルの下の出力ウィンドウに表示されます。たとえば、 
Microsoft Sentinel データ レイクと対話する方法を示すサンプル ノートブックについては、 Microsoft Sentinel Data Lake のサンプル ノートブックを参照してください。
ノートブックで GitHub Copilot を使用する
GitHub Copilot を使用すると、ノートブックでコードを記述できます。 GitHub Copilot では、コードのコンテキストに基づいてコードの提案とオートコンプリートが提供されます。 GitHub Copilot を使用するには、Visual Studio Code に GitHub Copilot 拡張機能 がインストールされていることを確認します。
Microsoft Sentinel データ レイクのサンプル ノートブックからコードをコピーし、ノートブック フォルダーに保存して GitHub Copilot のコンテキストを提供します。 GitHub Copilot は、ノートブックのコンテキストに基づいてコード補完を提案できるようになります。
次の例は、コード レビューを生成する GitHub Copilot を示しています。

Microsoft Sentinel プロバイダー クラス
Microsoft Sentinel データ レイクに接続するには、 SentinelLakeProvider クラスを使用します。
このクラスは、 access_module.data_loader モジュールの一部であり、データ レイクと対話するメソッドを提供します。 このクラスを使用するには、それをインポートし、 spark セッションを使用してクラスのインスタンスを作成します。
from sentinel_lake.providers import MicrosoftSentinelProvider
data_provider = MicrosoftSentinelProvider(spark)
使用可能なメソッドの詳細については、「 Microsoft Sentinel プロバイダー クラス リファレンス」を参照してください。
適切なランタイム プールを選択する
Microsoft Sentinel 拡張機能で Jupyter ノートブックを実行するには、3 つのランタイム プールを使用できます。 各プールは、さまざまなワークロードとパフォーマンス要件に合わせて設計されています。 ランタイム プールの選択は、Spark ジョブのパフォーマンス、コスト、実行時間に影響します。
| ランタイム プール | 推奨されるユース ケース | 特性 |
|---|---|---|
| 小さい | 開発、テスト、簡易の調査分析。 単純な変換を使用する小規模なワークロード。 コスト効率が優先されます。 |
小規模なワークロードに適しています 単純な変換。 コストを削減し、実行時間を長くします。 |
| 中程度 | 結合、集計、ML モデル トレーニングを含む ETL ジョブ。 複雑な変換でワークロードをモデレートします。 |
Small よりパフォーマンスが向上しました。 並列処理と中程度のメモリ集中型操作を処理します。 |
| Large | ディープ ラーニングと ML ワークロード。 広範なデータ シャッフル、大規模な結合、またはリアルタイム処理。 クリティカルな実行時間 |
高いメモリとコンピューティング能力。 最小遅延。 大規模、複雑、または時間に依存するワークロードに最適です。 |
注
最初にアクセスすると、カーネル オプションの読み込みに約 30 秒かかる場合があります。
ランタイム プールを選択した後、セッションが開始されるまでに 3 ~ 5 分かかる場合があります。
ログの表示
ログは、Visual Studio Code の [出力 ] ウィンドウで表示できます。
- [出力] ウィンドウで、ドロップダウンから Microsoft Sentinel を選択します。
- 詳細なログ エントリを含めるには、[ デバッグ] を選択します。

ジョブとスケジュール
Visual Studio Code 用の Microsoft Sentinel 拡張機能を使用して、特定の時間または間隔でジョブを実行するようにスケジュールできます。 ジョブを使用すると、データ処理タスクを自動化して、Microsoft Sentinel データ レイク内のデータを集計、変換、または分析できます。 ジョブは、データを処理したり、データ レイク層または分析層のカスタム テーブルに結果を書き込んだりするためにも使用されます。 ジョブの作成と管理の詳細については、「 Jupyter Notebook ジョブの作成と管理」を参照してください。
VS Code Notebook のサービス パラメーターと制限
次のセクションでは、VS Code Notebooks を使用する場合の Microsoft Sentinel Data Lake (プレビュー) のサービス パラメーターと制限の一覧を示します。
| カテゴリ | パラメーター/制限 |
|---|---|
| 分析層のカスタム テーブル | 分析レベルのカスタム テーブルをノートブックから削除することはできません。Log Analytics を使用してこれらのテーブルを削除します。 詳細については、「Azure Monitor ログのテーブルと列の追加または削除」を参照してください。 |
| ゲートウェイ Web ソケットのタイムアウト | 2 時間 |
| 対話型クエリのタイムアウト | 2 時間 |
| 対話型セッションの非活動タイムアウト | 20 分 |
| Language | Python |
| 同時実行ノートブック ジョブの最大数 | 3、以降のジョブは順次キューに登録されます |
| 対話型クエリでの同時ユーザーの最大数 | 大規模プールでの8から10 |
| セッションの起動時間 | Spark コンピューティング セッションの開始には約 5 ~ 6 分かかります。 VS Code Notebook の下部にあるセッションの状態を表示できます。 |
| サポートされているライブラリ | データ レイクのクエリでは、抽象化された関数用の Azure Synapse ライブラリ 3.4 と Microsoft Sentinel プロバイダー ライブラリのみがサポートされています。 Pip のインストールまたはカスタム ライブラリはサポートされていません。 |
| レコードを表示するための VS Code UX の制限 | 100,000 行 |
トラブルシューティング
次の表に、ノートブックを操作するときに発生する可能性がある一般的なエラー、その根本原因、およびそれらを解決するための推奨されるアクションを示します。
Spark コンピューティング
| エラーメッセージ | 表示面 | メッセージの説明 | 根本原因 | 推奨されるアクション |
|---|---|---|---|---|
| LIVY_JOB_TIMED_OUT: Livy セッションが失敗しました。 セッション状態: 終了。 エラー コード: LIVY_JOB_TIMED_OUT。 state=[dead] の実行時にジョブが失敗しました。 ソース: 不明。 | インライン。 | セッションがタイムアウトしたか、ユーザーがセッションを停止しました。 | セッションがタイムアウトしたか、ユーザーがセッションを停止しました。 | セルをもう一度実行します。 |
| 十分な容量がありません。 ユーザーは X vCores を要求しましたが、利用可能なのは {number-of-cores} vCores のみです。 | 出力チャネル – "ウィンドウ"。 | Spark コンピューティング プールは使用できません。 | コンピューティング プールが開始されていないか、他のユーザーまたはジョブによって使用されています。 | 小さいプールで再試行するか、アクティブなノートブックをローカルで停止するか、アクティブなノートブック ジョブの実行を停止します。 |
| Spark プールにアクセスできません – 403 禁止。 | 出力チャネル – "ウィンドウ"。 | Spark プールは表示されません。 | ユーザーには、対話型ノートブックまたはスケジュール ジョブを実行するために必要なロールがありません。 | 対話型ノートブックまたはノートブック ジョブに必要なロールがあるかどうかを確認します。 |
| Spark プール - <name> - はアップグレード中です。 | トースト アラート。 | いずれかの Spark プールは使用できません。 | Spark プールは、最新バージョンの Microsoft Sentinel プロバイダーにアップグレードされています。 | プールが利用可能になるまで約 20 ~ 30 分待ちます。 |
| z:org.apache.spark.api.python.PythonRDD.collectAndServe の呼び出し中にエラーが発生しました。 : org.apache.spark.SparkException: ステージエラーが原因でジョブが中止されました: シリアル化された結果の合計サイズ (4.0 GB) が spark.driver.maxResultSize (4.0 GB) より大きい | インライン。 | ドライバー のメモリを超えたか、Executor エラーが発生しました。 | ジョブがドライバー メモリを使い果たしたか、1 つ以上の Executor が失敗しました。 | ジョブ実行ログを表示するか、クエリを最適化します。 大規模なデータセットでは toPandas() を使用しないでください。 必要に応じて、 spark.conf.set("spark.sql.execution.arrow.pyspark.enabled", "true") を設定することを検討してください。 |
| リモート Jupyter Server 'https://api.securityplatform.microsoft.com/spark-notebook/interactive' に接続できませんでした。 サーバーが実行中で到達可能であることを確認します。 | トースト アラート | ユーザーがセッションを停止し、サーバーへの接続に失敗しました。 | ユーザーがセッションを停止しました。 | セルをもう一度実行して、セッションを再接続します。 |
VS Code Runtime
| エラーメッセージ | 表示面 | メッセージの説明 | 根本原因 | 推奨されるアクション |
|---|---|---|---|---|
| id を持つカーネル - k1 - が破棄されました。 | 出力チャネル – "Jupyter"。 | カーネルが接続されていません。 | VS Code がコンピューティング カーネルへの接続を失いました。 | Spark プールを再選択し、セルを実行します。 |
| ModuleNotFoundError: 'MicrosoftSentinelProvider' という名前のモジュールがありません。 | インライン。 | モジュールが見つかりません。 | 例えば、Microsoft Sentinel Library のインポートが見つからない | setup/init セルをもう一度実行します。 |
| Cell In[{cell number}], line 1 if: ^ SyntaxError: 無効な構文です。 | インライン。 | 構文が無効です。 | Python または PySpark 構文エラー。 | コード構文を確認する。コロン、かっこ、または引用符が見つからないかどうかを確認します。 |
| NameError Traceback (最新の呼び出しの最後) [{セル番号}] 内のセル、行 1 ----> 1 data_loader12 NameError: 名前 'data_loader' が定義されていません。 | インライン。 | バインドされていない変数。 | 代入前に使用される変数。 | 必要なすべてのセットアップ セルが順番に実行されていることを確認します。 |
対話型ノートブック
| エラーメッセージ | 表示面 | メッセージの説明 | 根本原因 | 推奨されるアクション |
|---|---|---|---|---|
| {"level": "エラー", "run_id": "...", "message": "テーブル {table-name} の読み込みエラー: テーブル '...|{table-name}' に対して 'DeltaParquet' 種類のコンテナが見つかりません。"} | インライン。 | 指定したソース テーブルが存在しません。 | 特定のワークスペースに 1 つ以上のソース テーブルが存在しません。 テーブルがワークスペースから最近削除された可能性があります | ソース テーブルがワークスペースに存在するかどうかを確認します。 |
| {"level": "ERROR", "run_id": "...", "message": "データベース名 {table-name} は存在しません。"} | インライン。 | クエリで指定されたワークスペースまたはデータベース名が無効であるか、アクセスできません。 | 参照先データベースが存在しません。 | データベース名が正しいことを確認します。 |
| 401 未承認。 | 出力チャネル – "ウィンドウ"。 | ゲートウェイ 401 エラー。 | ゲートウェイの 1 時間のタイムアウトが発動しました。 | セルをもう一度実行して、新しい接続を確立します。 |
図書館
| エラーメッセージ | 表示面 | メッセージの説明 | 根本原因 | 推奨されるアクション |
|---|---|---|---|---|
| 403 禁止。 | インライン。 | アクセスが拒否されました。 | ユーザーには、指定したテーブルの読み取り/書き込み/削除のアクセス許可がありません。 | ユーザーに必要なロールがあることを確認します。 |
| TableOperationException: DataFrame をテーブル {table-name}_SPRK: 'schema' に保存中にエラーが発生しました。 | インライン。 | 書き込み時のスキーマの不一致。 | save_as_table() は、既存のスキーマと一致しないデータを書き込みます。 | データフレーム スキーマを確認し、コピー先テーブルに合わせます。 |
| {"level": "ERROR", "run_id": "...", "message": "DataFrame をテーブル {table-name} に保存する際のエラー: MSG データベースで作成されたテーブルにはサフィックス '_SPRK' が必要です。"}。 | インライン。 | テーブルを Data Lake に書き込むためのサフィックス _SPRKがありません。 | save_as_table() は、_SPRKを必要とするテーブルにデータを書き込みます。 | データ レイク内のカスタム テーブルに書き込むためのサフィックスとして_SPRKを追加します。 |
| {"level": "ERROR", "run_id": "...", "message": "DataFrameをテーブルsiva_test_0624_1に保存する際のエラー: LAデータベースに作成されたテーブルにはサフィックス'_SPRK_CL'が必要です"} | インライン。 | 分析層にテーブルを書き込むためのサフィックス_SPRK_CLがありません | save_as_table() は、_SPRK_CLを必要とするテーブルにデータを書き込みます。 | 分析層のカスタム テーブルに書き込むためのサフィックスとして_SPRK_CLを追加します。 |
| {"level": "ERROR", "run_id": "...", "message": "テーブル EntraUsers に DataFrame を保存中にエラーが発生しました: MSG データベースで作成されたテーブルにはサフィックス '_SPRK'" が必要です。}。 | インライン。 | 書き込みが無効です。 | システム テーブルに書き込もうとすると、このアクションは許可されません。 | 書き込むカスタム テーブルを指定します。 |
| TypeError: DataProviderImpl.save_as_table() に必要な位置引数 'table_name' が 1 つありません。 | インライン。 | ノートブックが無効です。 | ライブラリ メソッドに渡された引数が正しくありません (たとえば、save_as_tableで 'mode' が見つかりません)。 | パラメーターの名前と値を検証します。 メソッドのドキュメントを参照してください。 |
仕事
| エラーメッセージ | 表示面 | メッセージの説明 | 根本原因 | 推奨されるアクション |
|---|---|---|---|---|
| [ジョブの実行] 状態に [失敗] と表示されます。 | インライン。 | ジョブ実行エラー。 | ノートブックが破損しているか、スケジュールされた実行のサポートされていない構文が含まれています。 | ノートブックの実行スナップショットを開き、すべてのセルが手動入力なしで順番に実行されることを検証します。 |