Data Factory for Microsoft Fabric の Azure Databricks アクティビティでは、次のような Azure Databricks ジョブを調整できます。
- Notebook
- Jar
- Python
- Job
この記事では、Data Factory インターフェイスを使用して Azure Databricks アクティビティを作成するステップバイステップのチュートリアルを提供します。
前提条件
開始するには、次の前提条件を満たしている必要があります。
- アクティブなサブスクリプションが含まれるテナント アカウント。 無料でアカウントを作成できます。
- ワークスペースが作成されている。
Azure Databricks アクティビティの構成
パイプライン内で Azure Databricks アクティビティを使用するには、次の手順を実行します。
接続の構成
ワークスペースに新しいパイプラインを作成します。
[ パイプライン アクティビティの追加] を選択し、Azure Databricks を検索します。

または、パイプラインの [アクティビティ] ペイン内で Azure Databricks を検索し、それを選択してパイプライン キャンバスに追加することもできます。
![[アクティビティ] ウィンドウと Azure Databricks アクティビティが強調表示されている Fabric UI のスクリーンショット。](media/azure-databricks-activity/pick-databricks-activity-from-pane.png)
まだ選ばれていない場合は、キャンバスで新しい Azure Databricks アクティビティを選びます。
![Azure Databricks アクティビティの [全般] 設定タブを示すスクリーンショット。](media/azure-databricks-activity/databricks-activity-general.png)
[全般設定] タブを構成するには、全般設定のガイダンスを参照してください。
クラスターの構成
[クラスター] タブを選択します。次に、既存の Azure Databricks 接続を選択するか新規作成し、新しいジョブ クラスター、既存の対話型クラスター、または既存のインスタンス プールを選択します。
選択したクラスターに応じて、対応するフィールドに入力します。
- 新しいジョブ クラスターと既存のインスタンス プールの下に、worker の数を構成し、スポット インスタンスを有効にする機能もあります。
接続するクラスターに必要に応じて、 クラスター ポリシー、 Spark 構成、 Spark 環境変数、 カスタム タグなどの他のクラスター設定を指定することもできます。 Databricks の init スクリプトとクラスター ログの宛先パスもクラスターの追加設定で追加できます。
注
Azure Data Factory Azure Databricks のリンクされたサービスでサポートされているすべての高度なクラスター プロパティと動的式が、UI の [追加クラスター構成] セクションの下の Microsoft Fabric の Azure Databricks アクティビティでもサポートされるようになりました。 これらのプロパティはアクティビティ UI に含まれるようになったため、高度な JSON 仕様を必要とせずに式 (動的コンテンツ) と共に使用できます。
![Azure Databricks アクティビティの [クラスター設定] タブを示すスクリーンショット。](media/azure-databricks-activity/databricks-activity-cluster.png)
Azure Databricks アクティビティでは、クラスター ポリシーと Unity カタログのサポートもサポートされるようになりました。
- [詳細設定] で、 クラスター ポリシー を選択して、許可するクラスター構成を指定できます。
- また、詳細設定では、セキュリティを強化するために Unity カタログ アクセス モード を構成できます。 使用可能な アクセス モードの種類 は次のとおりです:
- シングル ユーザー アクセス モード このモードは、各クラスターが単独のユーザーによって使用されるシナリオ向けに設計されています。 これにより、クラスター内のデータ アクセスがそのユーザーのみに制限されます。 このモードは、分離と個々のデータ処理を必要とするタスクに役立ちます。
- 共有アクセス モード このモードでは、複数のユーザーが同じクラスターにアクセスできます。 Unity Catalog のデータ ガバナンスと、レガシ テーブルのアクセス制御リスト (ACL) を組み合わせたものになります。 このモードでは、ガバナンスとセキュリティ プロトコルを維持しながら、共同作業によるデータ アクセスが可能になります。 ただし、Databricks Runtime ML のサポート、Spark 送信ジョブ、特定の Spark API と UDF のサポートなど、特定の制限があります。
- アクセス モードなし このモードでは、Unity カタログとの対話が無効になります。つまり、クラスターは Unity カタログによって管理されるデータにアクセスできません。 このモードは、Unity カタログのガバナンス機能を必要としないワークロードに役立ちます。
![Azure Databricks アクティビティの [クラスター設定] タブのポリシー ID と Unity カタログのサポートを示すスクリーンショット。](media/azure-databricks-activity/databricks-activity-policy-uc-support.png)
設定の構成
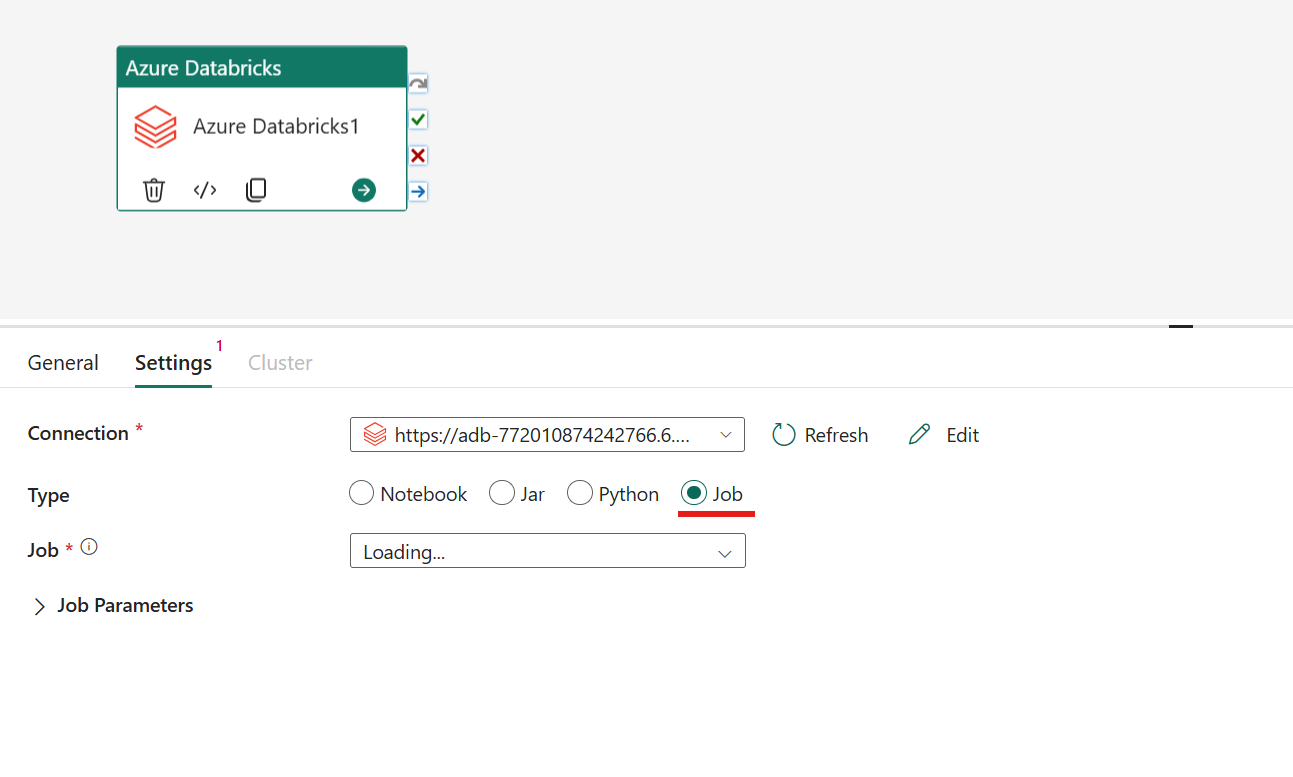
[ 設定] タブを選択すると、調整する Azure Databricks の種類 を 4 つのオプションから選択できます。
![Azure Databricks アクティビティの [設定] タブを示すスクリーンショット。](media/azure-databricks-activity/databricks-activity-settings.png)
次の Azure Databricks アクティビティで Notebook の種類を調整します。
[設定] タブで [Notebook] ラジオ ボタンを選択して Notebook を実行できます。 Azure Databricks で実行するノートブック パス、ノートブックに渡す省略可能な基本パラメーター、およびジョブを実行するためにクラスターにインストールする追加のライブラリを指定する必要があります。

次の Azure Databricks アクティビティで Jar の種類を調整します。
[設定] タブで [Jar] ラジオ ボタンを選択して Jar を実行できます。 Azure Databricks で実行するクラス名、Jar に渡す省略可能な基本パラメーター、およびジョブを実行するためにクラスターにインストールする追加のライブラリを指定する必要があります。

次の Azure Databricks アクティビティで Python の種類を調整します。
[設定] タブで [Python] ラジオ ボタンを選択して Python ファイルを実行できます。 実行する Python ファイルへの Azure Databricks 内のパス、渡す省略可能な基本パラメーター、およびジョブを実行するためにクラスターにインストールする追加のライブラリを指定する必要があります。

Azure Databricks アクティビティにおけるジョブタイプのオーケストレーション:
[ 設定] タブで、[ ジョブ ] ラジオ ボタンを選択して Databricks ジョブを実行できます。 Azure Databricks で実行するジョブをドロップダウンから指定し、渡す任意のジョブ パラメーターを入力する必要があります。 このオプションを使用して、サーバーレス ジョブを実行できます。
Azure Databricks アクティビティでサポートされるライブラリ
前述の Databricks アクティビティ定義では、jar、egg、whl、maven、pypi、cran というライブラリの種類を指定できます。
ライブラリの種類の詳細については、Databricks のドキュメントを参照してください。
Azure Databricks アクティビティとパイプラインの間のパラメーターの受け渡し
Databricks アクティビティの baseParameters プロパティを使用して、ノートブックにパラメーターを渡すことができます。

場合によっては、制御フローのためにノートブックからサービスに値を返したり、ダウンストリーム アクティビティで使用したりする必要があります (サイズ制限は 2 MB)。
たとえば、ノートブックで dbutils.notebook.exit("returnValue") を呼び出すと、対応する "returnValue" がサービスに返されます。
@{activity('databricks activity name').output.runOutput}などの式を使用して、サービスで出力を使用できます。
パイプラインを保存して実行またはスケジュールする
パイプラインに必要なその他のアクティビティを構成したら、パイプライン エディターの上部にある [ホーム] タブに切り替え、[保存] ボタンを選択してパイプラインを保存します。 [実行] を選択して直接実行するか、[スケジュール] を選択してスケジュールを設定します。 ここで実行履歴を表示したり、他の設定を構成したりすることもできます。
