この記事では、Azure Storage (ADLS Gen2 コンテナー、BLOB コンテナー、または個々の BLOB) からデータを取得する方法について説明します。 データは、継続的に、または 1 回限りのインジェストとしてテーブルに取り込むことができます。 取り込まれると、データはクエリで使用できるようになります。
継続的インジェスト (プレビュー): 継続的インジェストには、Eventhouse が Azure Storage イベントをリッスンできるようにするインジェスト パイプラインの設定が含まれます。 パイプラインは、サブスクライブされたイベントが発生したときに情報を引き出すようにイベントハウスに知らせます。 イベントは BlobCreated と BlobRenamed です。
Von Bedeutung
この機能は プレビュー段階です。
手記
継続的インジェスト ストリームは、課金に影響する可能性があります。 詳細については、「 Eventhouse と KQL Database の使用」を参照してください。
1 回限りインジェスト: このメソッドを使用して、1 回限りの操作として Azure Storage からデータを取得します。
前提 条件
- Microsoft Fabric 対応の 容量を持つ ワークスペース。
- 編集アクセス許可を持つ KQL データベース 。
- ストレージ アカウント。
継続的な取り込みには、次のものも必要です。
ワークスペースのアイデンティティ。 マイ ワークスペース はサポートされていません。 必要に応じて、 新しいワークスペースを作成します。
ストレージ アカウントで 階層型名前空間 を有効にします。
![Azure ポータルの [概要] ウィンドウを開いたスクリーンショットです。](media/get-data-azure-storage/storage-heirarchical-namespace-enabled.png)
ワークスペース ID に割り当てられたストレージ BLOB データ閲覧者ロールのアクセス許可。
データ ファイルを保持する コンテナー 。
コンテナーにアップロードされたデータ ファイル。 データ ファイル構造は、テーブル スキーマの定義に使用されます。 詳細については、「Real-Time Intelligence でサポートされるデータ形式の」を参照してください。
手記
データ ファイルをアップロードする必要があります。
- セットアップ中にテーブル スキーマを定義する 構成 の前。
- 継続的インジェストをトリガーする構成の後、データをプレビューし、接続を確認します。
ワークスペース ID ロールの割り当てをストレージ アカウントに追加する
Fabric のワークスペース設定から、ワークスペース ID をコピーします。

Azure portalでAzure Storage アカウントに移動し、アクセス制御 (IAM)を選択します。>追加>ロール割り当ての追加を選択します。
[ストレージ BLOB データ リーダー] を選択します。
[ ロールの割り当ての追加 ] ダイアログで、[ + メンバーの選択] を選択します。
ワークスペース ID を貼り付け、アプリケーションを選択し、 Select>Review + assign を選択します。
データ ファイルを使用してコンテナーを作成する
ストレージ アカウントで、[コンテナー] を選択 します。
[+ コンテナー] を選択し、コンテナーの名前を入力して [保存] を選択します。
コンテナーを入力し、[ アップロード] を選択して、前に準備したデータ ファイルをアップロードします。
詳細については、 サポートされている形式 と サポートされている圧縮を参照してください。
コンテキスト メニュー [...] から[コンテナーのプロパティ] を選択し、構成中に入力する URL をコピーします。

ソース
データを取得するようにソースを設定します。
ワークスペースから EventHouse を開き、データベースを選択します。
KQL データベース リボンで、[データの 取得] を選択します。
使用可能な一覧からデータ ソースを選択します。 この例では Azure ストレージからデータを取り込もうとしています。
![ソース タブが選択されている [データの取得] ウィンドウのスクリーンショット。](media/get-data-kql/select-data-source.png)
![ソース タブが選択されている [データの取得] ウィンドウのスクリーンショット。](media/get-data-kql/select-data-source.png#lightbox)
構成
変換先テーブルを選択します。 新しいテーブルにデータを取り込む場合は、+ 新しいテーブル を選択し、テーブル名を入力します。
手記
テーブル名には、スペース、英数字、ハイフン、アンダースコアを含む、最大 1024 文字を使用できます。 特殊文字はサポートされていません。
[ Azure Blob Storage 接続の構成] で、 継続的インジェスト が有効になっていることを確認します。 既定ではオンになっています。
新しい接続を作成するか、既存の接続を使用して接続を構成します。
新しい接続の作成:
[ ストレージ アカウントに接続] を選択します。
![[継続的インジェストとアカウントへの接続] が選択されている [構成] タブのスクリーンショット。](media/get-data-azure-storage/configure-tab-continuous.png)
フィールドの入力に次の説明を使用してください。
設定 フィールドの説明 サブスクリプション ストレージ アカウント サブスクリプション。 BLOB ストレージ アカウント ストレージ アカウント名。 コンテナ 取り込むファイルを含むストレージ コンテナー。 [接続] フィールドでドロップダウンを開き、[+ 新しい接続] を選択し、[>閉じる] を選択します。 接続設定が事前に設定されています。
手記
新しい接続を作成すると、新しい Eventstream が生成されます。 名前は<storate_account_name>_eventstreamとして定義されます。 ワークスペースから継続的インジェスト イベントストリームを削除しないようにしてください。
既存の接続を使用するには:
[ 既存のストレージ アカウントの選択] を選択します。
![[継続的インジェストと既存のアカウントへの接続] が選択されている [構成] タブのスクリーンショット。](media/get-data-azure-storage/configure-tab-continuous-rth.png)
フィールドの入力に次の説明を使用してください。
設定 フィールドの説明 RTAストレージアカウント Fabric からストレージ アカウントに接続されているイベント ストリーム。 コンテナ 取り込むファイルを含むストレージ コンテナー。 接続 これは接続文字列で事前に設定されています [ 接続 ] フィールドでドロップダウンを開き、一覧から既存の接続文字列を選択します。 [ 保存]>[閉じる]を選択します。
必要に応じて、[ ファイル フィルター] を 展開し、次のフィルターを指定します。
設定 フィールドの説明 フォルダー パス 特定のフォルダー パスを使用してファイルを取り込むためのデータをフィルター処理します。 ファイル拡張子 特定のファイル拡張子のみを持つファイルを取り込むためのデータをフィルター処理します。 [ Eventstearm settings]\(Eventstearm 設定 \) セクションで、監視するイベントを [詳細設定>イベントの種類] で選択できます。 既定では、Blob 作成が選択されています。 名前が変更された BLOB を選択することもできます。
![[イベントの種類] ドロップダウンが展開された [詳細設定] のスクリーンショット。](media/get-data-azure-storage/configure-tab-advanced-settings.png)
[ 次へ ] を選択してデータをプレビューします。
![[継続的インジェストとアカウントへの接続] が選択されている [構成] タブのスクリーンショット。](media/get-data-azure-storage/configure-tab-continuous.png#lightbox)
![[継続的インジェストと既存のアカウントへの接続] が選択されている [構成] タブのスクリーンショット。](media/get-data-azure-storage/configure-tab-continuous-rth.png#lightbox)
![継続的インジェストがオフになっている [構成] タブのスクリーンショット。アカウントへの接続が選択されています。](media/get-data-azure-storage/configure-one-time-select-account.png)
![新しいテーブルが入力され、1 つのサンプル データ ファイルが選択されている [構成] タブのスクリーンショット。](media/get-data-azure-storage/configure-tab.png#lightbox)
検査する
[検査] タブが開き、データのプレビューが表示されます。
インジェスト プロセスを完了するには、[完了]を選択します。

手記
継続的インジェストとプレビュー データを呼び出すには、構成後に新しいストレージ BLOB をアップロードしたことを確認します。
必要 に応じて:
スキーマ定義ファイルのドロップダウンを使用して、スキーマが推論されるファイルを変更します。
[ファイルの種類] ドロップダウンを使用して、 データ型に基づいて詳細オプションを確認します。
Table_mapping ドロップダウンを使用して、新しいマッピングを定義します。
</>を選択してコマンド ビューアーを開き、入力から生成された自動コマンドを表示およびコピーします。 クエリセットでコマンドを開くこともできます。
鉛筆アイコンを選択して 列を編集します。
列の編集
手記
- 表形式 (CSV、TSV、PSV) の場合、列を 2 回マップすることはできません。 既存の列にマップするには、最初に新しい列を削除します。
- 既存の列の種類を変更することはできません。 別の形式の列にマップしようとすると、最終的に空の列になる可能性があります。
テーブルで行うことができる変更は、次のパラメーターによって異なります。
- テーブル の種類 は新規または既存です。
- マッピングの種類が新規かまたは既存か
| テーブルの種類 | マッピングの種類 | 使用可能な調整 |
|---|---|---|
| 新しいテーブル | 新しいマッピング | 列の名前変更、データ型の変更、データ ソースの変更、マッピング変換 、列の追加、列の削除 |
| 既存のテーブル | 新しいマッピング | 列の追加 (データ型の変更、名前の変更、更新が可能) |
| 既存のテーブル | 既存のマッピング | 何一つ |

マッピング変換
一部のデータ形式マッピング (Parquet、JSON、Avro) では、単純な取り込み時間変換がサポートされています。 マッピング変換を適用するには、[列の編集] ウィンドウで列 作成または更新します。
マッピング変換は、データ型が int または long のソースを使用して、文字列型または datetime 型の列に対して実行できます。 詳細については、サポートされている マッピング変換 の完全な一覧を参照してください。
データ型に基づく詳細オプション
表形式データ (CSV、TSV、PSV):
表形式を既存のテーブルに取り込もうとしている場合は、詳細、>テーブルスキーマを保持するを選択できます。 表形式データには、ソース データを既存の列にマップするために使用される列名が必ずしも含まれているわけではありません。 このオプションをオンにすると、マッピングは順番に行われ、テーブル スキーマは変わりません。 このオプションをオフにすると、データ構造に関係なく、受信データに対して新しい列が作成されます。
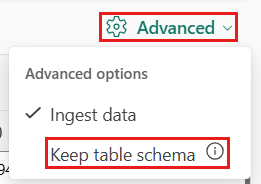
表形式データには、ソース データを既存の列にマップするために使用される列名が必ずしも含まれているわけではありません。 最初の行を列名として使用するには、[最初の行を列ヘッダーにする] を選択します。

表形式データ (CSV、TSV、PSV):
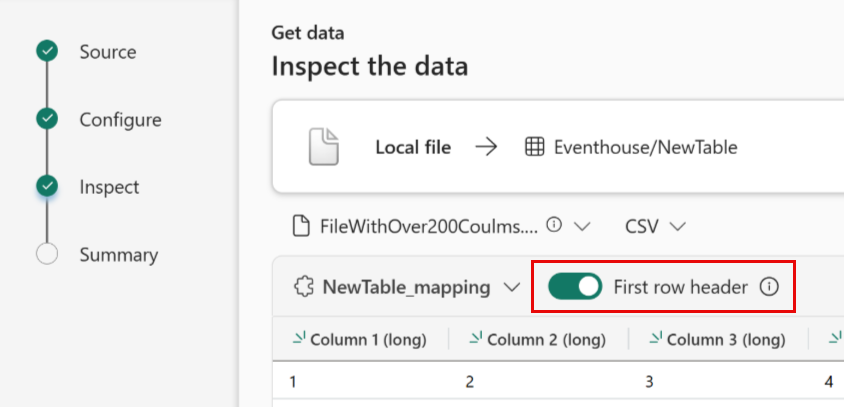
既存のテーブルに表形式を取り込む場合は、Table_mapping>既存のスキーマを使用するを選択できます。 表形式データには、ソース データを既存の列にマップするために使用される列名が必ずしも含まれているわけではありません。 このオプションをオンにすると、マッピングは順番に行われ、テーブル スキーマは変わりません。 このオプションをオフにすると、データ構造に関係なく、受信データに対して新しい列が作成されます。
最初の行を列名として使用するには、[ 先頭行ヘッダー] を選択します。
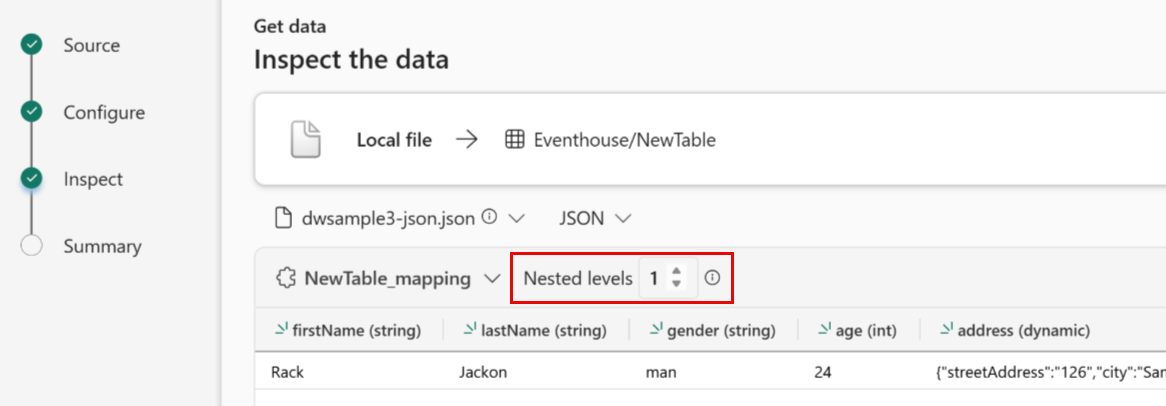
JSON:
JSON データの列分割を決定するには、 入れ子になったレベルを 1 から 100 まで選択します。
概要
[ 概要 ] ウィンドウでは、データ インジェストが正常に完了すると、すべての手順が緑色のチェック マークでマークされます。 カードを選択してデータを探索したり、取り込まれたデータを削除したり、主要なメトリックを含むダッシュボードを作成したりできます。

ウィンドウを閉じると、[エクスプローラー] タブの [ データ ストリーム] に接続が表示されます。 ここから、データ ストリームをフィルター処理し、データ ストリームを削除できます。

