ピボットテーブル API を使用して、データの集計、フィールドのグループ化、フィルター処理、ブック内の計算の適用を行います。
主な概念
- 4 つの階層カテゴリ: 行、列、データ、フィルター。
- 新しいカテゴリに階層を追加すると、古いカテゴリから削除されます。
-
PivotLayoutでは、出力範囲 (たとえば、getDataBodyRange) が表示されます。 - フィルター オプション: コード (PivotFilters) または UI (スライサー)。
- 複数の階層を追加し、
context.sync()を 1 回呼び出して速度を向上します。
エンド ユーザーとしてピボットテーブルに慣れていない場合は、「ピボットテーブルの作成」を参照 してワークシート データを分析します。
重要
OLAP で作成されたピボットテーブルは現在サポートされていません。 Power Pivot のサポートもありません。
オブジェクト モデル
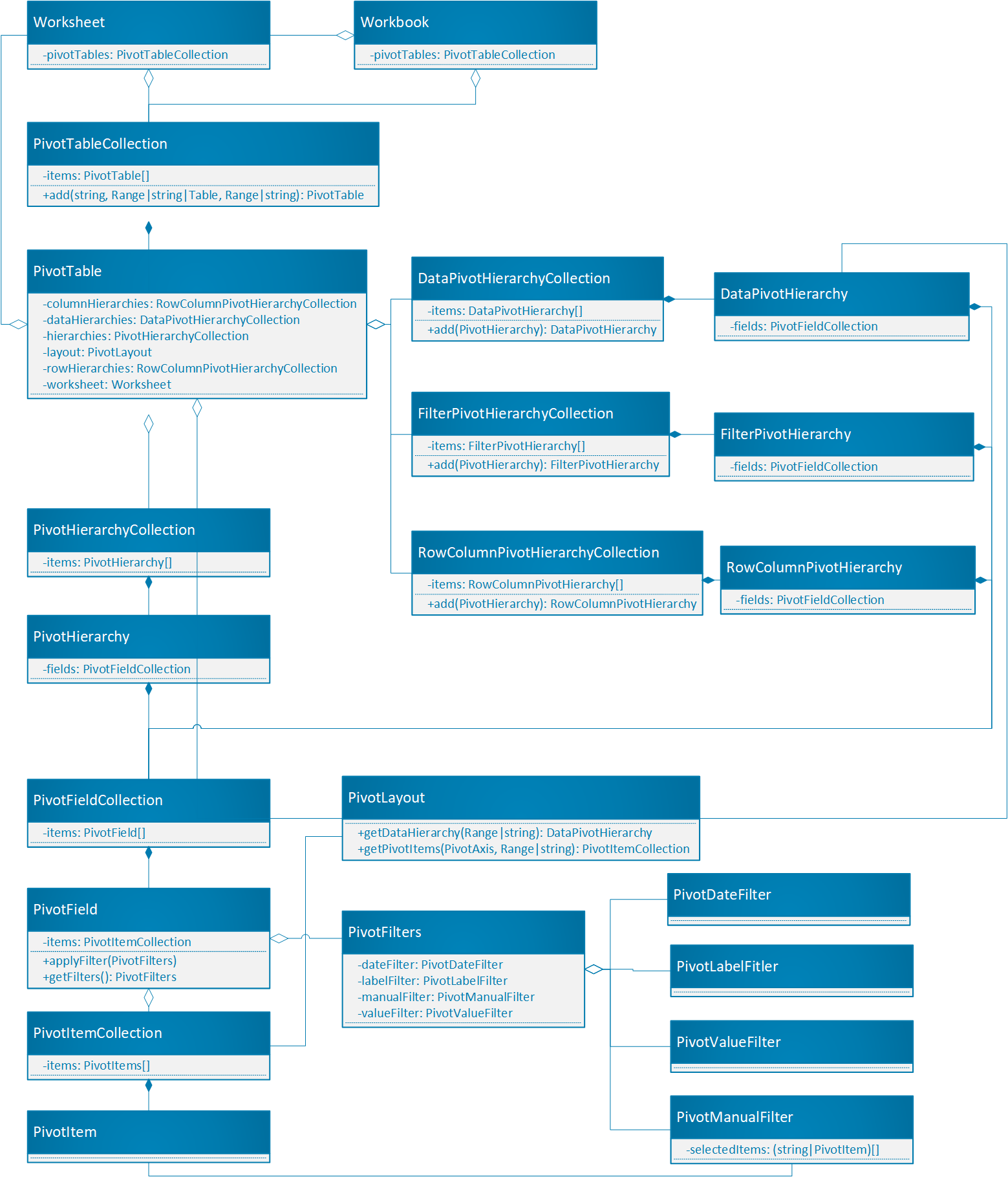
ピボットテーブルは、Office JavaScript API のピボットテーブルの中心的なオブジェクトです。
-
Workbook.pivotTablesとWorksheet.pivotTablesは、ブックとワークシートのピボットテーブルを含む PivotTableCollectionです 。 - ピボットテーブルには、複数の PivotHierarchies を含む PivotHierarchyCollectionがあります。
- PivotHierarchies を特定の階層コレクションに追加して、ピボットテーブルがデータをピボットする方法を定義できます。
- PivotHierarchy には、ピボットフィールドが 1 つだけ含まれる PivotFieldCollection が含まれています。 デザインが展開され、OLAP ピボットテーブルが含まれる場合、これは変更される可能性があります。
- ピボットフィールドには、フィールドの PivotHierarchy が階層カテゴリに割り当てられている限り、1 つ以上の PivotFilter を適用できます。
- PivotField には、複数の PivotItem を持つ PivotItemCollection が含まれています。
- ピボットテーブルには、ワークシートに PivotFields と PivotItems を表示する場所を定義するPivotLayout が含まれています。 レイアウトでは、ピボットテーブルの一部の表示設定も制御されます。
これらのリレーションシップがデータの例にどのように適用されるかを見てみましょう。 次のデータでは、さまざまな農場からの果物の売上について説明します。 この記事全体の例を示します。

このフルーツ ファームの売上データは、ピボットテーブルの作成に使用されます。
Types などの各列は、PivotHierarchyです。
Types 階層には、[型] フィールドが含まれています。 [ 種類] フィールドには、 Apple、 Kiwi、 Lemon、 Lime、Orange の項目が含 まれています。
Hierarchies
ピボットテーブルには、 行、 列、 データ、 フィルターの 4 つの階層カテゴリがあります。
ファーム データには、 ファーム、 種類、 分類、 ファームで販売されたクレート、および クレート販売卸売の 5 つの階層があります。 各階層は、4 つのカテゴリのいずれかにのみ存在できます。 列階層に Type を追加した場合、行、データ、またはフィルター階層に含めることはできません。 その後 、Type が行階層に追加されると、列階層から削除されます。 この動作は、階層の割り当てが Excel UI または Excel JavaScript API を介して実行される場合でも同じです。
行階層と列階層は、データのグループ化方法を定義します。 たとえば、ファームの行階層は、同じ ファーム のすべてのデータ セットをグループ化します。 行と列の階層を選択すると、ピボットテーブルの向きが定義されます。
データ階層は、行階層と列階層に基づいて集計される値です。 ファームの行階層とクレート販売卸売のデータ階層を持つピボットテーブルには、各ファームのすべての異なる果物の合計 (既定) が表示されます。
フィルター階層には、そのフィルター処理された型内の値に基づいて、ピボットからデータが含まれるか除外されます。 [分類 ] の フィルター階層の種類 が [有機] が選択されている場合、有機フルーツのデータのみが表示されます。
ピボットテーブルと共に、もう一度ファーム データを次に示します。 ピボットテーブルでは、行階層として Farm と Type を使用し、データ階層として [ファームで販売されたクレート] と [ 販売されたクレート ] をデータ階層として使用し (合計の既定の集計関数を使用)、[ 分類 ] をフィルター階層として使用しています ( [有機] が選択されています)。

このピボットテーブルは、JavaScript API または Excel UI を使用して生成できます。 どちらのオプションでも、アドインを使用してさらに操作できます。
ピボットテーブルを作成する
名前、ソース、宛先を指定します。 ソースには、範囲アドレスまたはテーブル名を指定できます ( Range、 string、または Table 型として渡されます)。 宛先は範囲アドレスです ( Range または stringとして指定されます)。
次のサンプルは、さまざまなピボットテーブル作成手法を示しています。
範囲アドレスを使用してピボットテーブルを作成する
await Excel.run(async (context) => {
// Create a PivotTable named "Farm Sales" on the current worksheet at cell
// A22 with data from the range A1:E21.
context.workbook.worksheets.getActiveWorksheet().pivotTables.add(
"Farm Sales", "A1:E21", "A22");
await context.sync();
});
Range オブジェクトを使用してピボットテーブルを作成する
await Excel.run(async (context) => {
// Create a PivotTable named "Farm Sales" on a worksheet called "PivotWorksheet" at cell A2
// the data comes from the worksheet "DataWorksheet" across the range A1:E21.
let rangeToAnalyze = context.workbook.worksheets.getItem("DataWorksheet").getRange("A1:E21");
let rangeToPlacePivot = context.workbook.worksheets.getItem("PivotWorksheet").getRange("A2");
context.workbook.worksheets.getItem("PivotWorksheet").pivotTables.add(
"Farm Sales", rangeToAnalyze, rangeToPlacePivot);
await context.sync();
});
ブック レベルでピボットテーブルを作成する
await Excel.run(async (context) => {
// Create a PivotTable named "Farm Sales" on a worksheet called "PivotWorksheet" at cell A2
// the data is from the worksheet "DataWorksheet" across the range A1:E21.
context.workbook.pivotTables.add(
"Farm Sales", "DataWorksheet!A1:E21", "PivotWorksheet!A2");
await context.sync();
});
既存のピボットテーブルを使用する
手動で作成されたピボットテーブルには、ブックのピボットテーブル コレクションまたは個々のワークシートからアクセスすることもできます。 次のコードは、ブックから My Pivot という名前のピボット テーブルを取得します。
await Excel.run(async (context) => {
let pivotTable = context.workbook.pivotTables.getItem("My Pivot");
await context.sync();
});
ピボットテーブルに行と列を追加する
行と列は、データのグループ化方法を定義します。 [ファーム] 列を追加すると、各ファームの売上がすべてグループになります。 [種類] 行と [分類] 行を追加すると、販売された果物と有機性の有無に基づいてデータがさらに分割されます。
![[ファーム] 列と [種類] 行と [分類] 行を含むピボットテーブル。](../images/excel-pivots-table-rows-and-columns.png)
await Excel.run(async (context) => {
let pivotTable = context.workbook.worksheets.getActiveWorksheet().pivotTables.getItem("Farm Sales");
pivotTable.rowHierarchies.add(pivotTable.hierarchies.getItem("Type"));
pivotTable.rowHierarchies.add(pivotTable.hierarchies.getItem("Classification"));
pivotTable.columnHierarchies.add(pivotTable.hierarchies.getItem("Farm"));
await context.sync();
});
行または列のみを含むピボットテーブルを作成することもできます。
await Excel.run(async (context) => {
let pivotTable = context.workbook.worksheets.getActiveWorksheet().pivotTables.getItem("Farm Sales");
pivotTable.rowHierarchies.add(pivotTable.hierarchies.getItem("Farm"));
pivotTable.rowHierarchies.add(pivotTable.hierarchies.getItem("Type"));
pivotTable.rowHierarchies.add(pivotTable.hierarchies.getItem("Classification"));
await context.sync();
});
ピボットテーブルにデータ階層を追加する
データ階層は、ピボットテーブルに行と列に基づいて結合する情報を入力します。 ファームで販売されたクレートとクレート販売卸売のデータ階層を追加すると、行と列ごとにそれらの数値の合計が得られます。
この例では、 Farm と Type の両方が行であり、クレート売上がデータとして使用されています。

await Excel.run(async (context) => {
let pivotTable = context.workbook.worksheets.getActiveWorksheet().pivotTables.getItem("Farm Sales");
// "Farm" and "Type" are the hierarchies on which the aggregation is based.
pivotTable.rowHierarchies.add(pivotTable.hierarchies.getItem("Farm"));
pivotTable.rowHierarchies.add(pivotTable.hierarchies.getItem("Type"));
// "Crates Sold at Farm" and "Crates Sold Wholesale" are the hierarchies
// that will have their data aggregated (summed in this case).
pivotTable.dataHierarchies.add(pivotTable.hierarchies.getItem("Crates Sold at Farm"));
pivotTable.dataHierarchies.add(pivotTable.hierarchies.getItem("Crates Sold Wholesale"));
await context.sync();
});
ピボットテーブル レイアウトとピボットデータの取得
PivotLayout は、階層とそのデータの配置を定義します。 レイアウトにアクセスして、データを格納する範囲を決定します。
次の図は、ピボットテーブルの範囲に対応するレイアウト関数呼び出しを示しています。

ピボットテーブルからデータを取得する
レイアウトは、ワークシートにピボットテーブルを表示する方法を定義します。 つまり、 PivotLayout オブジェクトはピボットテーブル要素に使用される範囲を制御します。 レイアウトで提供される範囲を使用して、ピボットテーブルによって収集および集計されたデータを取得します。 特に、 PivotLayout.getDataBodyRange を使用して、ピボットテーブルによって生成されたデータにアクセスします。
次のコードは、レイアウトを実行してピボットテーブル データの最後の行を取得する方法を示しています (前の例の [ファームで販売されたクレートの合計] 列と [販売されたクレートの合計] 列の総計)。 その後、これらの値が合計され、最終的な合計が合計され、セル E30 (ピボットテーブルの外部) に表示されます。
await Excel.run(async (context) => {
let pivotTable = context.workbook.worksheets.getActiveWorksheet().pivotTables.getItem("Farm Sales");
// Get the totals for each data hierarchy from the layout.
let range = pivotTable.layout.getDataBodyRange();
let grandTotalRange = range.getLastRow();
grandTotalRange.load("address");
await context.sync();
// Sum the totals from the PivotTable data hierarchies and place them in a new range, outside of the PivotTable.
let masterTotalRange = context.workbook.worksheets.getActiveWorksheet().getRange("E30");
masterTotalRange.formulas = [["=SUM(" + grandTotalRange.address + ")"]];
await context.sync();
});
レイアウトの種類
ピボットテーブルには、コンパクト、アウトライン、表形式の 3 つのレイアウト スタイルがあります。 前の例では、コンパクト なスタイルを見てきました。
次の例では、それぞれアウトラインスタイルと表形式スタイルを使用しています。 コード サンプルは、異なるレイアウト間を循環する方法を示しています。
アウトライン レイアウト

表形式レイアウト

PivotLayout 型スイッチのコード サンプル
await Excel.run(async (context) => {
// Change the PivotLayout.type to a new type.
let pivotTable = context.workbook.worksheets.getActiveWorksheet().pivotTables.getItem("Farm Sales");
pivotTable.layout.load("layoutType");
await context.sync();
// Cycle between the three layout types.
if (pivotTable.layout.layoutType === "Compact") {
pivotTable.layout.layoutType = "Outline";
} else if (pivotTable.layout.layoutType === "Outline") {
pivotTable.layout.layoutType = "Tabular";
} else {
pivotTable.layout.layoutType = "Compact";
}
await context.sync();
});
その他の PivotLayout 関数
既定では、ピボットテーブルは必要に応じて行と列のサイズを調整します。 これは、ピボットテーブルが更新されたときに発生します。
PivotLayout.autoFormat は、その動作を指定します。 アドインによって行われた行または列のサイズの変更は、 autoFormat が falseされたときに保持されます。 さらに、ピボットテーブルの既定の設定では、ピボットテーブルにカスタム書式が保持されます (塗りつぶしやフォントの変更など)。
PivotLayout.preserveFormattingを false に設定して、更新時に既定の形式を適用します。
PivotLayoutでは、ヘッダーと行の合計の設定、空のデータ セルの表示方法、代替テキスト オプションも制御されます。
PivotLayout リファレンスには、これらの機能の完全な一覧が用意されています。
次のコード サンプルでは、空のデータ セルに文字列 "--"が表示され、本文の範囲が一貫した水平方向の配置に書式設定され、ピボットテーブルが更新された後も書式設定の変更が確実に維持されます。
await Excel.run(async (context) => {
let pivotTable = context.workbook.pivotTables.getItem("Farm Sales");
let pivotLayout = pivotTable.layout;
// Set a default value for an empty cell in the PivotTable. This doesn't include cells left blank by the layout.
pivotLayout.emptyCellText = "--";
// Set the text alignment to match the rest of the PivotTable.
pivotLayout.getDataBodyRange().format.horizontalAlignment = Excel.HorizontalAlignment.right;
// Ensure empty cells are filled with a default value.
pivotLayout.fillEmptyCells = true;
// Ensure that the format settings persist, even after the PivotTable is refreshed and recalculated.
pivotLayout.preserveFormatting = true;
await context.sync();
});
ピボットテーブルを削除する
ピボットテーブルは、その名前を使用して削除されます。
await Excel.run(async (context) => {
context.workbook.worksheets.getItem("Pivot").pivotTables.getItem("Farm Sales").delete();
await context.sync();
});
ピボットテーブルをフィルター処理する
ピボットテーブル データをフィルター処理するための主な方法は、PivotFilters を使用することです。 スライサーは、柔軟性の低い代替フィルター方法を提供します。
PivotFilters は、 ピボットテーブルの 4 つの 階層カテゴリ (フィルター、列、行、および値) に基づいてデータをフィルター処理します。 PivotFilters には 4 種類があり、カレンダーの日付ベースのフィルター処理、文字列解析、数値比較、およびカスタム入力に基づくフィルター処理が可能です。
スライサー は、ピボットテーブルと通常の Excel テーブルの両方に適用できます。 ピボットテーブルに適用すると、スライサーは PivotManualFilter のように機能し、カスタム入力に基づくフィルター処理を許可します。 PivotFilters とは異なり、スライサーには Excel UI コンポーネントがあります。
Slicer クラスを使用して、この UI コンポーネントを作成し、フィルター処理を管理し、視覚的な外観を制御します。
PivotFilters を使用したフィルター
ピボットフィルター を使用すると、4 つの 階層カテゴリ (フィルター、列、行、値) に基づいてピボットテーブル データをフィルター処理できます。 ピボットテーブル オブジェクト モデルでは、 PivotFilters が PivotField に適用され、各 PivotField には 1 つ以上の割り当て PivotFiltersを割り当てることができます。 PivotFilters を PivotField に適用するには、フィールドの対応する PivotHierarchy を階層カテゴリに割り当てる必要があります。
PivotFilters の種類
| フィルターの種類 | フィルターの目的 | Excel JavaScript API リファレンス |
|---|---|---|
| DateFilter | カレンダーの日付ベースのフィルター処理。 | PivotDateFilter |
| LabelFilter | テキスト比較フィルター処理。 | PivotLabelFilter |
| ManualFilter | カスタム入力フィルター処理。 | PivotManualFilter |
| ValueFilter | 数値比較フィルター処理。 | PivotValueFilter |
PivotFilter を作成する
Pivot*Filter (PivotDateFilterなど) を使用してピボットテーブル データをフィルター処理するには、ピボットフィールドにフィルターを適用します。 次の 4 つのコード サンプルは、4 種類の PivotFilters のそれぞれを使用する方法を示しています。
PivotDateFilter
最初のコード サンプルでは 、PivotDateFilter を Date Updated PivotField に適用し、 2020-08-01 より前のすべてのデータを非表示にします。
重要
Pivot*Filterは、そのフィールドの PivotHierarchy が階層カテゴリに割り当てられない限り、PivotField に適用できません。 次のコード サンプルでは、フィルター処理に使用する前に、 dateHierarchy をピボットテーブルの rowHierarchies カテゴリに追加する必要があります。
await Excel.run(async (context) => {
// Get the PivotTable and the date hierarchy.
let pivotTable = context.workbook.worksheets.getActiveWorksheet().pivotTables.getItem("Farm Sales");
let dateHierarchy = pivotTable.rowHierarchies.getItemOrNullObject("Date Updated");
await context.sync();
// PivotFilters can only be applied to PivotHierarchies that are being used for pivoting.
// If it's not already there, add "Date Updated" to the hierarchies.
if (dateHierarchy.isNullObject) {
dateHierarchy = pivotTable.rowHierarchies.add(pivotTable.hierarchies.getItem("Date Updated"));
}
// Apply a date filter to filter out anything logged before August.
let filterField = dateHierarchy.fields.getItem("Date Updated");
let dateFilter = {
condition: Excel.DateFilterCondition.afterOrEqualTo,
comparator: {
date: "2020-08-01",
specificity: Excel.FilterDatetimeSpecificity.month
}
};
filterField.applyFilter({ dateFilter: dateFilter });
await context.sync();
});
注:
次の 3 つのコード スニペットでは、完全な Excel.run 呼び出しではなく、フィルター固有の抜粋のみが表示されます。
PivotLabelFilter
2 番目のコード スニペットは、LabelFilterCondition.beginsWith プロパティを使用して、文字 L で始まるラベルを除外するために、PivotLabelFilter を Type PivotField に適用する方法を示しています。
// Get the "Type" field.
let filterField = pivotTable.hierarchies.getItem("Type").fields.getItem("Type");
// Filter out any types that start with "L" ("Lemons" and "Limes" in this case).
let filter: Excel.PivotLabelFilter = {
condition: Excel.LabelFilterCondition.beginsWith,
substring: "L",
exclusive: true
};
// Apply the label filter to the field.
filterField.applyFilter({ labelFilter: filter });
PivotManualFilter
3 番目のコード スニペットでは、 PivotManualFilter を使用して手動フィルターを [分類 ] フィールドに適用し、分類 オーガニックを含まないデータをフィルター処理します。
// Apply a manual filter to include only a specific PivotItem (the string "Organic").
let filterField = classHierarchy.fields.getItem("Classification");
let manualFilter = { selectedItems: ["Organic"] };
filterField.applyFilter({ manualFilter: manualFilter });
PivotValueFilter
数値を比較するには、最後のコード スニペットに示すように、 PivotValueFilter で値フィルターを使用します。
PivotValueFilterは、Farm PivotField のデータと、販売されたクレートの合計が値 500 を超えるファームのみを含む、クレート販売卸売ピボットフィールド内のデータと比較します。
// Get the "Farm" field.
let filterField = pivotTable.hierarchies.getItem("Farm").fields.getItem("Farm");
// Filter to only include rows with more than 500 wholesale crates sold.
let filter: Excel.PivotValueFilter = {
condition: Excel.ValueFilterCondition.greaterThan,
comparator: 500,
value: "Sum of Crates Sold Wholesale"
};
// Apply the value filter to the field.
filterField.applyFilter({ valueFilter: filter });
ピボットフィルターを削除する
すべての PivotFilter を削除するには、次のコード サンプルに示すように、 clearAllFilters メソッドを各 PivotField に適用します。
await Excel.run(async (context) => {
// Get the PivotTable.
let pivotTable = context.workbook.worksheets.getActiveWorksheet().pivotTables.getItem("Farm Sales");
pivotTable.hierarchies.load("name");
await context.sync();
// Clear the filters on each PivotField.
pivotTable.hierarchies.items.forEach(function (hierarchy) {
hierarchy.fields.getItem(hierarchy.name).clearAllFilters();
});
await context.sync();
});
スライサーを使用したフィルター
スライサー を使用すると、Excel ピボットテーブルまたはテーブルからデータをフィルター処理できます。 スライサーは、指定された列または PivotField の値を使用して、対応する行をフィルター処理します。 これらの値は、Slicerに SlicerItem オブジェクトとして格納されます。 アドインでは、(Excel UI を使用して) ユーザーと同様に、これらのフィルターを調整できます。 スライサーは、次のスクリーンショットに示すように、描画レイヤーのワークシートの上に置かれます。

注:
このセクションで説明する手法では、ピボットテーブルに接続されているスライサーを使用する方法について説明します。 同じ手法は、テーブルに接続されたスライサーの使用にも適用されます。
スライサーを作成する
slicers.add メソッドを使用して、ブックまたはワークシートにスライサーを作成します。 これにより、指定した Workbook または Worksheet オブジェクトの SlicerCollection にスライサーが追加されます。
SlicerCollection.add メソッドには、次の 3 つのパラメーターがあります。
-
slicerSource: 新しいスライサーの基になるデータ ソース。PivotTableまたはTableの名前または ID を表すPivotTable、Table、または文字列を指定できます。 -
sourceField: フィルター処理するデータ ソースのフィールド。PivotFieldまたはTableColumnの名前または ID を表すPivotField、TableColumn、または文字列を指定できます。 -
slicerDestination: 新しいスライサーが作成されるワークシート。Worksheetオブジェクト、またはWorksheetの名前または ID を指定できます。 このパラメーターは、Worksheet.slicersを介してSlicerCollectionにアクセスする場合は不要です。 この場合、コレクションのワークシートがコピー先として使用されます。
次のコード サンプルでは、 ピボット ワークシートに新しいスライサーを追加します。 スライサーのソースは 、Farm Sales ピボットテーブルであり、 Type データを使用したフィルターです。 スライサーは、将来の参照のために Fruit Slicer とも呼ばれます。
await Excel.run(async (context) => {
let sheet = context.workbook.worksheets.getItem("Pivot");
let slicer = sheet.slicers.add(
"Farm Sales" /* The slicer data source. For PivotTables, this can be the PivotTable object reference or name. */,
"Type" /* The field in the data to filter by. For PivotTables, this can be a PivotField object reference or ID. */
);
slicer.name = "Fruit Slicer";
await context.sync();
});
スライサーを使用して項目をフィルター処理する
スライサーは、ピボットテーブルを sourceFieldの項目でフィルター処理します。
Slicer.selectItems メソッドは、スライサーに残っている項目を設定します。 これらの項目は、項目のキーを表す string[]として メソッドに渡されます。 これらの項目を含む行はすべて、ピボットテーブルの集計に残ります。 以降の 呼び出し selectItems 、それらの呼び出しで指定されたキーにリストを設定します。
注:
データ ソースにない項目 Slicer.selectItems 渡された場合は、 InvalidArgument エラーがスローされます。 内容は、slicerItemCollection である Slicer.slicerItems プロパティを使用して確認できます。
次のコード サンプルは、スライサーに対して選択されている 3 つの項目 ( レモン、 ライム、 オレンジ) を示しています。
await Excel.run(async (context) => {
let slicer = context.workbook.slicers.getItem("Fruit Slicer");
// Anything other than the following three values will be filtered out of the PivotTable for display and aggregation.
slicer.selectItems(["Lemon", "Lime", "Orange"]);
await context.sync();
});
スライサーからすべてのフィルターを削除するには、次のサンプルに示すように、 Slicer.clearFilters メソッドを使用します。
await Excel.run(async (context) => {
let slicer = context.workbook.slicers.getItem("Fruit Slicer");
slicer.clearFilters();
await context.sync();
});
スライサーのスタイル設定と書式設定
Slicerプロパティを使用してスライサーの表示設定を調整します。 次のコード サンプルでは、スタイルを SlicerStyleLight6 に設定し、スライサーの上部にあるテキストを Fruit Types に設定し、スライサーを描画レイヤー上の位置 (395、15) に配置し、スライサーのサイズを 135x150 ピクセルに設定します。
await Excel.run(async (context) => {
let slicer = context.workbook.slicers.getItem("Fruit Slicer");
slicer.caption = "Fruit Types";
slicer.left = 395;
slicer.top = 15;
slicer.height = 135;
slicer.width = 150;
slicer.style = "SlicerStyleLight6";
await context.sync();
});
スライサーを削除する
スライサーを削除するには、 Slicer.delete メソッドを呼び出します。 次のコード サンプルでは、現在のワークシートから最初のスライサーを削除します。
await Excel.run(async (context) => {
let sheet = context.workbook.worksheets.getActiveWorksheet();
sheet.slicers.getItemAt(0).delete();
await context.sync();
});
集計関数の変更
データ階層の値は集計されます。 数値のデータセットの場合、これは既定で合計です。
summarizeBy プロパティは、AggregationFunction 型に基づいてこの動作を定義します。
現在サポートされている集計関数の種類は、 Sum、 Count、 Average、 Max、 Min、 Product、 CountNumbers、 StandardDeviation、 StandardDeviationP、 Variance、 VarianceP、 Automatic (既定値) です。
次のコード サンプルでは、集計がデータの平均に変更されます。
await Excel.run(async (context) => {
let pivotTable = context.workbook.worksheets.getActiveWorksheet().pivotTables.getItem("Farm Sales");
pivotTable.dataHierarchies.load("no-properties-needed");
await context.sync();
// Change the aggregation from the default sum to an average of all the values in the hierarchy.
pivotTable.dataHierarchies.items[0].summarizeBy = Excel.AggregationFunction.average;
pivotTable.dataHierarchies.items[1].summarizeBy = Excel.AggregationFunction.average;
await context.sync();
});
ShowAsRule を使用して計算を変更する
ピボットテーブルは、既定では、行階層と列階層のデータを個別に集計します。 ShowAsRule は、ピボットテーブル内の他の項目に基づいてデータ階層を出力値に変更します。
ShowAsRule オブジェクトには、次の 3 つのプロパティがあります。
-
calculation: データ階層に適用する相対計算の種類 (既定値はnone)。 -
baseField: 計算が適用される前の基本データを含む階層内の PivotField 。 Excel ピボットテーブルには階層とフィールドの 1 対 1 のマッピングがあるため、同じ名前を使用して階層とフィールドの両方にアクセスします。 -
baseItem: 計算の種類に基づいて基本フィールドの値と比較された個々の PivotItem 。 すべての計算でこのフィールドが必要なわけではありません。
次の例では、Farm データ階層 で販売されたクレートの合計 に対する計算を、列の合計に対する割合に設定します。 細分性は引き続きフルーツの種類レベルに拡張する必要があるため、 Type 行階層とその基になるフィールドを使用します。 この例では、最初の行階層として Farm も含まれているため、ファームの合計エントリには、各ファームが生成を担当する割合が表示されます。

await Excel.run(async (context) => {
let pivotTable = context.workbook.worksheets.getActiveWorksheet().pivotTables.getItem("Farm Sales");
let farmDataHierarchy = pivotTable.dataHierarchies.getItem("Sum of Crates Sold at Farm");
farmDataHierarchy.load("showAs");
await context.sync();
// Show the crates of each fruit type sold at the farm as a percentage of the column's total.
let farmShowAs = farmDataHierarchy.showAs;
farmShowAs.calculation = Excel.ShowAsCalculation.percentOfColumnTotal;
farmShowAs.baseField = pivotTable.rowHierarchies.getItem("Type").fields.getItem("Type");
farmDataHierarchy.showAs = farmShowAs;
farmDataHierarchy.name = "Percentage of Total Farm Sales";
});
前の例では、個々の行階層のフィールドを基準にして、計算を列に設定します。 計算が個々のアイテムに関連する場合は、 baseItem プロパティを使用します。
次の例は、 differenceFrom 計算を示しています。 ファームのクレート売上データ階層エントリの差が 、A Farms のエントリに対して相対的に表示されます。
baseFieldは Farm であるため、他のファーム間の違いと、フルーツなどの種類ごとの内訳が表示されます (この例では、Type は行階層でもあります)。

await Excel.run(async (context) => {
let pivotTable = context.workbook.worksheets.getActiveWorksheet().pivotTables.getItem("Farm Sales");
let farmDataHierarchy = pivotTable.dataHierarchies.getItem("Sum of Crates Sold at Farm");
farmDataHierarchy.load("showAs");
await context.sync();
// Show the difference between crate sales of the "A Farms" and the other farms.
// This difference is both aggregated and shown for individual fruit types (where applicable).
let farmShowAs = farmDataHierarchy.showAs;
farmShowAs.calculation = Excel.ShowAsCalculation.differenceFrom;
farmShowAs.baseField = pivotTable.rowHierarchies.getItem("Farm").fields.getItem("Farm");
farmShowAs.baseItem = pivotTable.rowHierarchies.getItem("Farm").fields.getItem("Farm").items.getItem("A Farms");
farmDataHierarchy.showAs = farmShowAs;
farmDataHierarchy.name = "Difference from A Farms";
});
階層名を変更する
階層フィールドは編集可能です。 次のコードは、2 つのデータ階層の表示名を変更する方法を示しています。
await Excel.run(async (context) => {
let dataHierarchies = context.workbook.worksheets.getActiveWorksheet()
.pivotTables.getItem("Farm Sales").dataHierarchies;
dataHierarchies.load("no-properties-needed");
await context.sync();
// Changing the displayed names of these entries.
dataHierarchies.items[0].name = "Farm Sales";
dataHierarchies.items[1].name = "Wholesale";
});
関連項目
GitHub で Microsoft と共同作業する
このコンテンツのソースは GitHub にあります。そこで、issue や pull request を作成および確認することもできます。 詳細については、共同作成者ガイドを参照してください。
Office Add-ins