概要
| アイテム | 説明 |
|---|---|
| リリース状況 | 一般提供 |
| プロダクツ | エクセル Power BI (セマンティック モデル) Power BI (データフロー) ファブリック (データフロー Gen2) Power Apps (データフロー) Dynamics 365 Customer Insights Analysis Services |
| 関数リファレンス ドキュメント |
File.Contents Lines.FromBinary Csv.Document |
注
一部の機能は 1 つの製品に存在する可能性がありますが、展開スケジュールとホスト固有の機能のため、他の製品には存在しない場合があります。
サポートされている機能
- 輸入
Power Query Desktop からローカル テキスト/CSV ファイルに接続する
ローカル テキストまたは CSV ファイルを読み込むには:
[データの取得 ] で [テキスト/CSV ] オプションを選択 します。 この操作により、テキスト ファイルを選択できるローカル ファイル ブラウザーが起動します。

[開く] を選択して、ファイルを開きます。
ナビゲーターから、Power Query エディターで [データの変換] を選択してデータを変換するか、[読み込み] を選択してデータを読み込むことができます。

Power Query Online からテキスト/CSV ファイルに接続する
ローカル テキストまたは CSV ファイルを読み込むには:
[ データ ソース ] ページで、[ テキスト/CSV] を選択します。
[接続設定] で、ファイルをアップロードするか、必要なローカル テキストまたは CSV ファイルへのファイル パスを入力します。

データ ゲートウェイからオンプレミス データ ゲートウェイを選択します。
ユーザー名とパスワードを入力します。
[次へ] を選択します。
ナビゲーターから [データの変換] を選択して、Power Query エディターでデータの変換を開始します。
![[データの変換] を選択したオンライン ナビゲーター ウィンドウのスクリーンショット。](media/text-csv/csv-navigator-online.png)
![[データの変換] を選択したオンライン ナビゲーター ウィンドウのスクリーンショット。](media/text-csv/csv-navigator-online.png#lightbox)
Web から読み込む
Web からテキストまたは CSV ファイルを読み込むには、 Web コネクタを選択し、ファイルの Web アドレスを入力して、資格情報のプロンプトに従います。
テキスト/CSV 区切り記号
Power Query では、CSV を区切り記号としてコンマで構成されたファイルとして扱います。テキスト ファイルの特殊なケースです。 テキスト ファイルを選択すると、区切り記号で区切られた値が含まれるかどうか、およびその区切り記号が何であるかが Power Query によって自動的に判断されます。 区切り記号を推論できる場合は、自動的に構造化データ ソースとして扱われます。
非構造化テキスト
テキスト ファイルに構造がない場合は、ソース テキストでエンコードされた行ごとに新しい行を含む 1 つの列を取得します。 非構造化テキストのサンプルとして、次の内容を含むメモ帳ファイルを検討できます。
Hello world.
This is sample data.
読み込むと、これらの各行を独自の行に読み込むナビゲーション画面が表示されます。

このダイアログで構成できることは 1 つだけです。これは、[ ファイルの配信元 ] ドロップダウン選択です。 このドロップダウンでは、ファイルの生成に使用された 文字セット を選択できます。 現在、文字セットは推論されず、UTF-8 は UTF-8 BOM で始まる場合にのみ推論されます。

CSV
サンプルの CSV ファイル については、こちらをご覧ください。
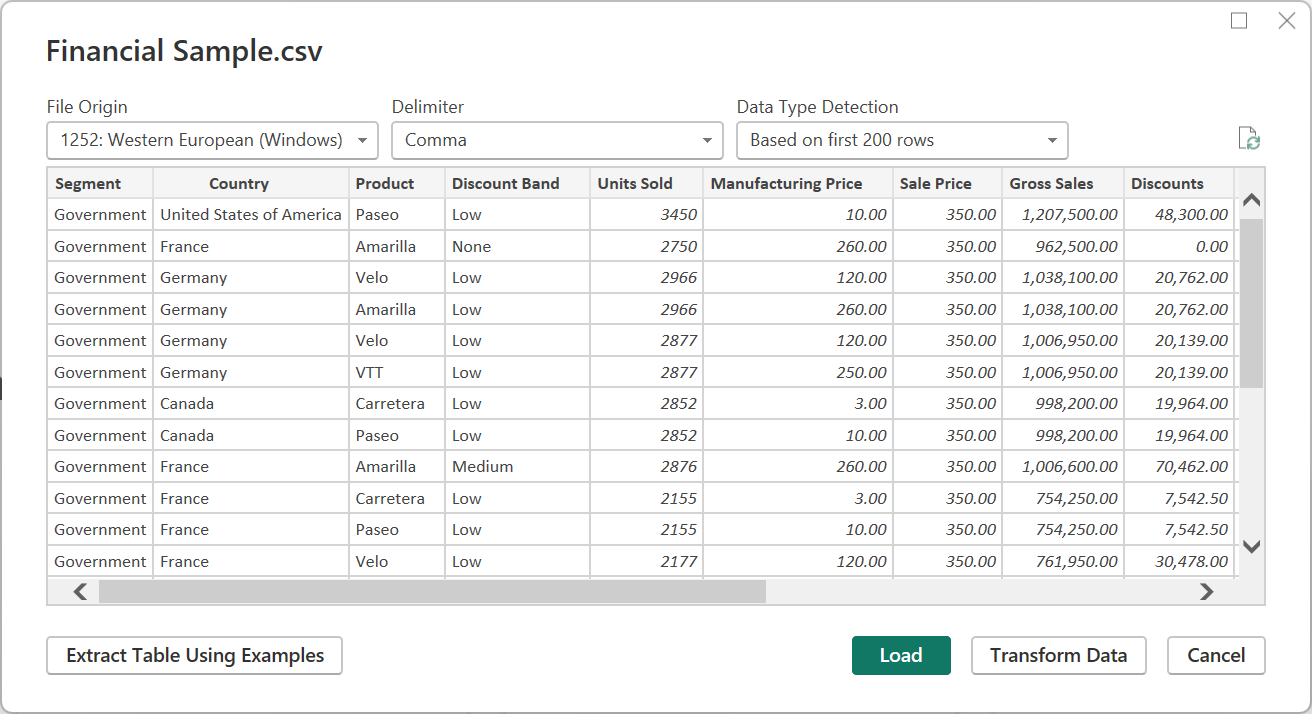
CSV では、ファイルの配信元に加えて、区切り記号とデータ型検出の処理方法の指定もサポートされています。

使用できる区切り記号には、コロン、コンマ、等号、セミコロン、スペース、タブ、カスタム区切り記号 (任意の文字列を指定できます)、固定幅 (標準の文字数でテキストを分割する) があります。

最後のドロップダウンでは、データ型検出の処理方法を選択できます。 これは、最初の 200 行またはデータ セット全体に基づいて行うことができます。 また、データ型の自動検出を行わず、代わりにすべての列を既定の "テキスト" にすることもできます。 警告: データ セット全体で行うと、エディター内のデータの初期読み込みが遅くなる可能性があります。

推論が正しくない可能性があるため、読み込む前に設定を再確認する必要があります。
構造化テキスト
Power Query は、テキスト ファイルの構造を検出できる場合、テキスト ファイルを区切り記号で区切られた値ファイルとして扱い、CSV を開くときに使用できるのと同じオプションを提供します。これは基本的に、区切り記号の種類を示す拡張子を持つファイルです。
たとえば、次の例をテキスト ファイルとして保存すると、非構造化テキストではなくタブ区切り記号を持つものとして読み取られます。
Column 1 Column 2 Column 3
This is a string. 1 ABC123
This is also a string. 2 DEF456

この構造体は、他の任意の種類の区切り記号ベースのファイルに使用できます。
ソースの編集
ソース ステップ (Power Query Desktop の [ 適用されたステップ ] ウィンドウ) を編集すると、最初の読み込み時とは少し異なるダイアログが表示されます。 現在ファイルを扱っている内容 (つまり、テキストまたは csv) に応じて、さまざまなドロップダウンが表示された画面が表示されます。
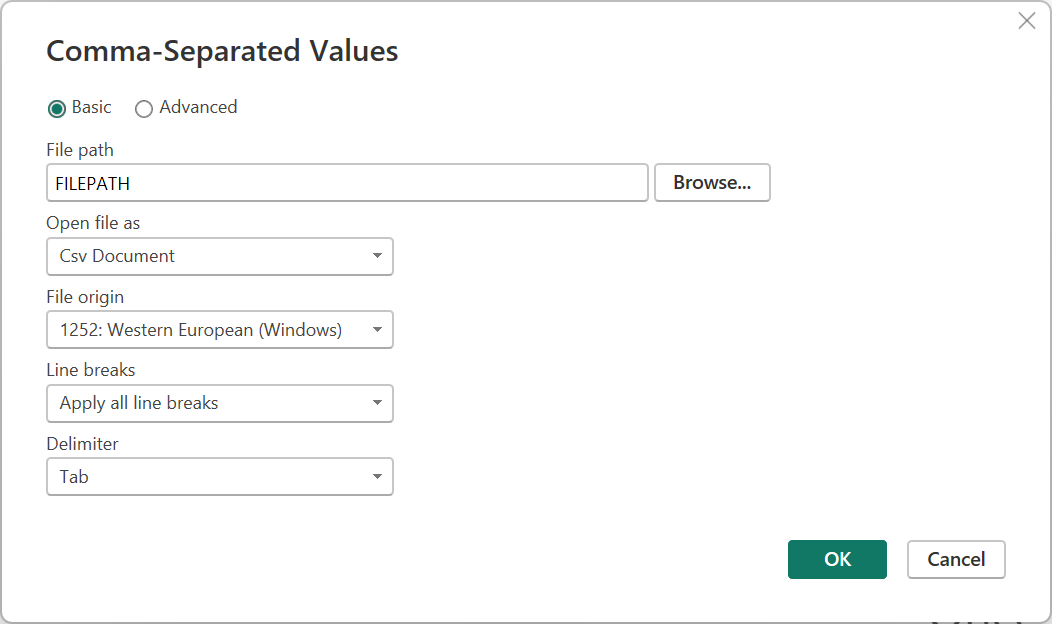
[ 改行 ] ドロップダウンでは、引用符内の改行を適用するかどうかを選択できます。
たとえば、前に指定した '構造化' サンプルを編集する場合は、改行を追加できます。
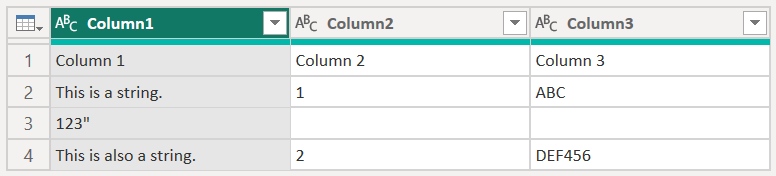
Column 1 Column 2 Column 3
This is a string. 1 "ABC
123"
This is also a string. 2 "DEF456"
[改行] が [引用符で囲まれた改行を無視する] に設定されている場合、このサンプルでは、同じ列の前半の下に文字列の後半が読み込まれます。
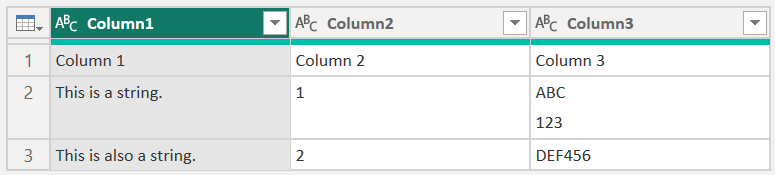
改行が [すべての改行を適用する] に設定されている場合、このサンプルでは追加の行が読み込まれます。改行の後のコンテンツがその行の唯一のコンテンツになります (正確な出力はファイルの内容の構造によって異なります)。
[ ファイルを開く ] ドロップダウンでは、ファイルを読み込む内容を編集できます。トラブルシューティングに重要です。 技術的に CSV ではない構造化ファイル (テキスト ファイルとして保存されたタブ区切り値ファイルなど) の場合は、[ ファイルを開く ] が CSV に設定されている必要があります。 この設定により、ダイアログの残りの部分で使用できるドロップダウンも決定されます。
例によるテキスト/CSV
Power Query の Text/CSV By Example は、Power BI Desktop と Power Query Online で一般公開されている機能です。 Text/CSV コネクタを使用すると、ナビゲーターの左下隅に [例を使用してテーブルを抽出 する] オプションが表示されます。
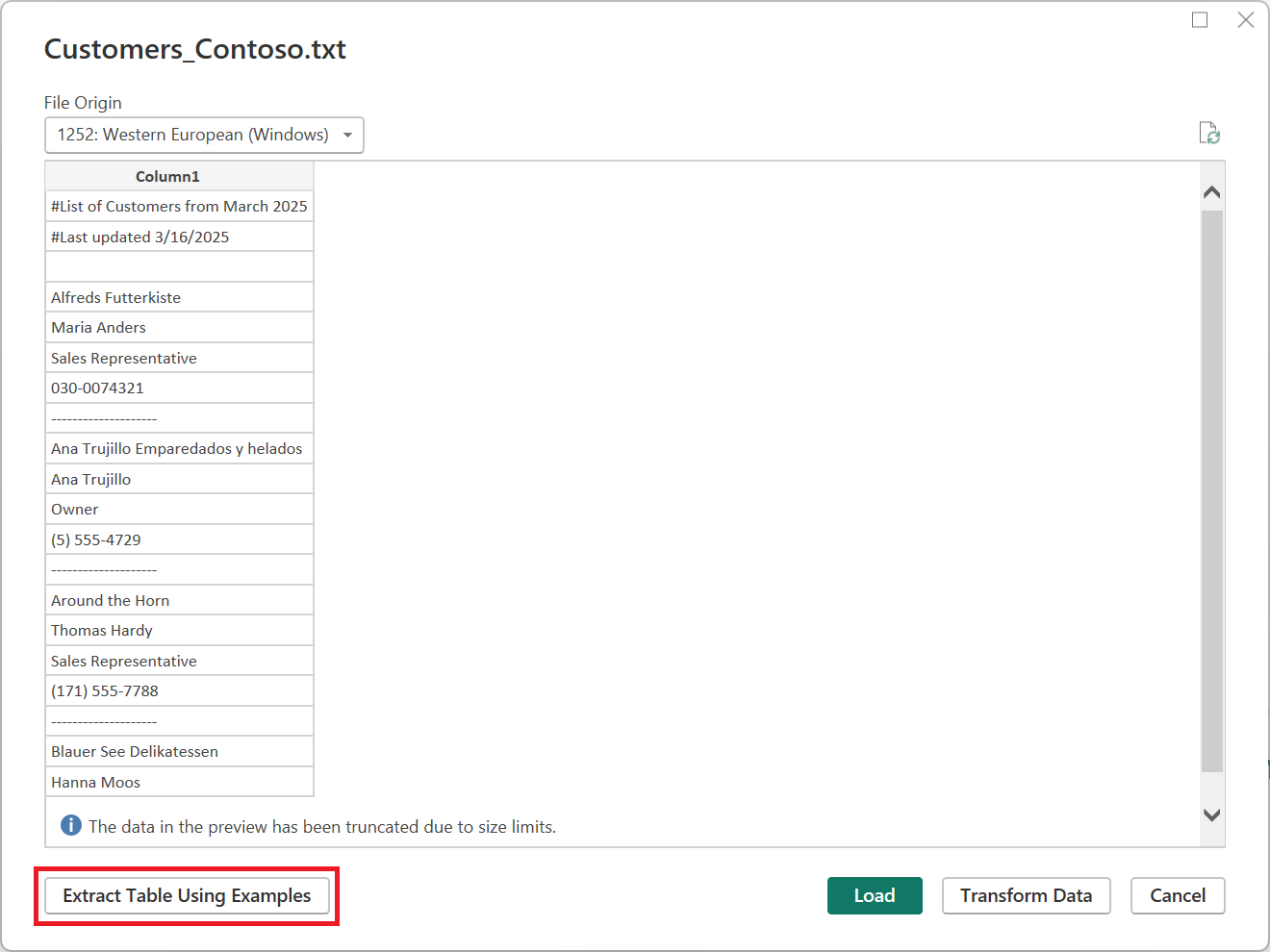
そのボタンを選択すると、[ サンプルを使用したテーブルの抽出 ] ページが表示されます。 このページでは、テキスト/CSV ファイルから抽出するデータのサンプル出力値を指定します。 列の最初のセルを入力すると、列内の他のセルが入力されます。データを正しく抽出するには、列に複数のセルを入力する必要がある場合があります。 列の一部のセルが正しくない場合は、最初に正しくないセルを修正すると、データが再び抽出されます。 データが正常に抽出されたことを確認するには、最初のいくつかのセルのデータを確認します。
注
列の順序で例を入力することをお勧めします。 列が正常に入力されたら、新しい列を作成し、新しい列に例の入力を開始します。

そのテーブルの作成が完了したら、データの読み込みまたは変換を選択できます。 結果のクエリに、データ抽出のために推論されたすべてのステップの詳細な内訳が含まれていることに注意してください。 これらの手順は、必要に応じてカスタマイズできる通常のクエリステップです。

トラブルシューティング
Web からのファイルの読み込み
Web からテキスト/csv ファイルを要求してヘッダーを強調し、潜在的なスロットリングに注意が必要なほど十分なファイルを取得している場合は、Web.Contents 呼び出しを Binary.Buffer() でラップすることを検討する必要があります。 この場合、ヘッダーを昇格させる前にファイルをバッファリングすると、ファイルは 1 回だけ要求されます。
大きな CSV ファイルの操作
Power Query Online エディターで大きな CSV ファイルを処理している場合は、内部エラーが発生する可能性があります。 小さいサイズの CSV ファイルを最初に操作し、エディターで手順を適用し、完了したら、大きな CSV ファイルへのパスを変更することをお勧めします。 この方法を使用すると、より効率的に作業でき、オンライン エディターでタイムアウトが発生する可能性を減らすことができます。 タイムアウト期間が長くなることが予想されるため、更新中にこのエラーが発生することは想定されていません。
構造化されていないテキストが構造化として解釈される
まれに、段落間で類似のコンマ番号を持つドキュメントが CSV と解釈される場合があります。 この問題が発生した場合は、Power Query エディターでソース ステップを編集し、[ファイルを開く] ドロップダウンで CSV ではなく [テキスト] を選択します。
Power BI Desktop の中の列
CSV ファイルをインポートすると、Power BI Desktop は Power Query エディターの手順として列 =x (最初のインポート時の CSV ファイル内の列数) を生成します。 後で列を追加し、データ ソースを更新するように設定した場合、最初の x 列数を超える列は更新されません。
エラー: ホストによって接続が閉じられました
Web ソースからテキスト/CSV ファイルを読み込み、ヘッダーを昇格するときに、次のエラーが発生する場合があります。 "An existing connection was forcibly closed by the remote host" または "Received an unexpected EOF or 0 bytes from the transport stream." ホストは、保護対策を採用し、一時的に一時停止される可能性のある接続を閉じることによって、これらのエラーを引き起こす可能性があります(たとえば、結合または追加操作のために別のデータ ソース接続を待機しているとき)。 これらのエラーを回避するには、 Binary.Buffer (推奨) または Table.Buffer 呼び出しを追加してみてください。これにより、ファイルがダウンロードされ、メモリに読み込まれ、すぐに接続が閉じられます。 このアクションにより、ダウンロード中の一時停止を防ぎ、コンテンツが取得される前にホストが強制的に接続を閉じないようにする必要があります。
次の例は、この回避策を示しています。 このバッファリングは、結果のテーブルが Table.PromoteHeaders に渡される前に行う必要があります。
- 元のコード:
Csv.Document(Web.Contents("https://.../MyFile.csv"))
-
Binary.Bufferを使用する場合:
Csv.Document(Binary.Buffer(Web.Contents("https://.../MyFile.csv")))
-
Table.Bufferを使用する場合:
Table.Buffer(Csv.Document(Web.Contents("https://.../MyFile.csv")))