大規模言語モデル (LLM) アプリの開発ライフサイクルを理解する
プロンプト フローの使用方法を理解する前に、大規模言語モデル (LLM) アプリケーションの開発ライフサイクルを調べてみましょう。
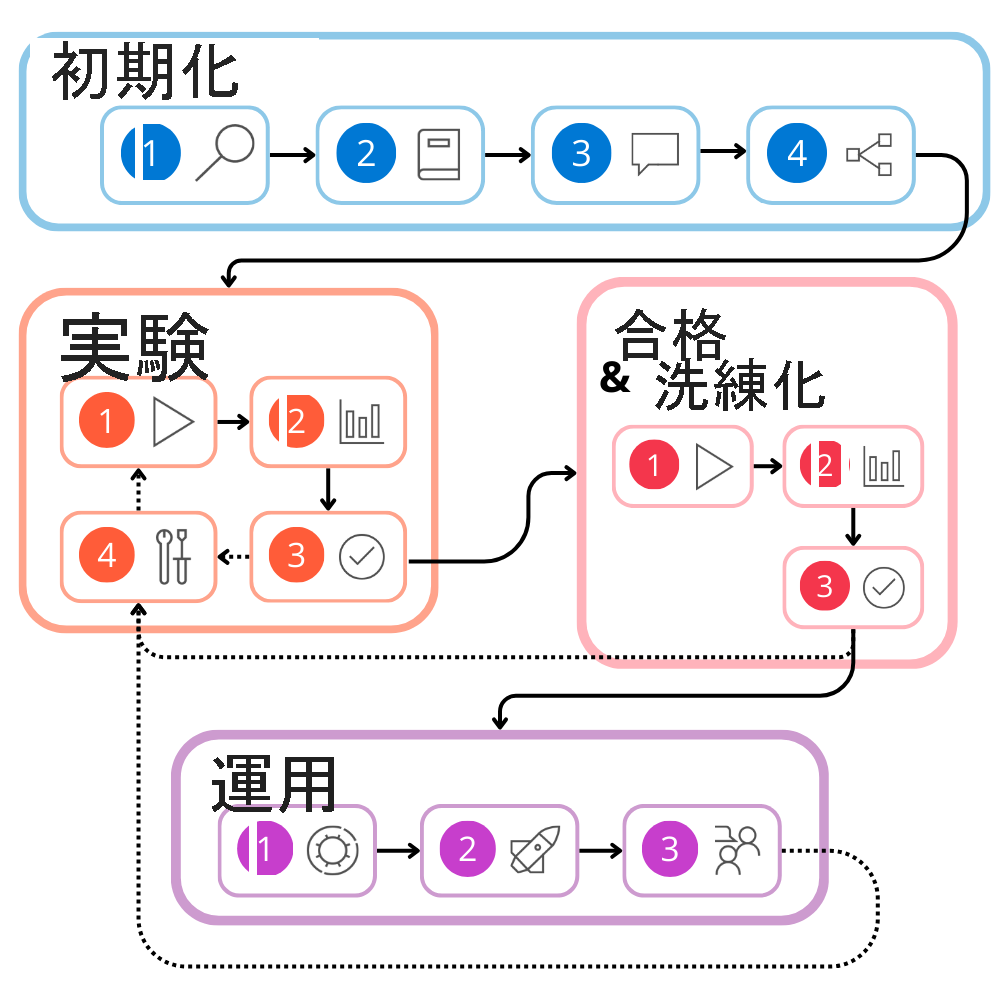
ライフサイクルは、次の段階で構成されます。
- 初期化: ユース ケースを定義し、ソリューションを設計します。
- 実験: フローを開発し、小さなデータセットでテストします。
- 評価と絞り込み: より大きなデータセットを使用してフローを評価します。
- 運用: フローとアプリケーションをデプロイして監視します。
評価と絞り込み、運用の両方で、ソリューションを改善する必要がある場合があります。 結果に満足するまで、フローを継続的に開発する実験に戻すことができます。
これらの各フェーズについて詳しく見てみましょう。
初期化
ニュース記事を分類する LLM アプリケーションを設計および開発したいとします。 何かを作成する前に、出力として必要なカテゴリを定義する必要があります。 一般的なニュース記事の外観、記事をアプリケーションへの入力として提示する方法、およびアプリケーションが目的の出力を生成する方法を理解する必要があります。
つまり、 初期化 中に次の処理が行われます。

- 目的を定義する
- サンプル データセットを収集する
- 基本的なプロンプトを作成する
- フローを設計する
LLM アプリケーションを設計、開発、テストするには、入力として機能するサンプル データセットが必要です。 サンプル データセットは、最終的に LLM アプリケーションへの入力として解析することが予想されるデータの小さな代表的なサブセットです。
サンプル データセットを収集または作成するときは、さまざまなシナリオやエッジ ケースに対応するために、データの多様性を確保する必要があります。 また、脆弱性を回避するために、データセットからプライバシーの機密情報を削除する必要もあります。
実験
ニュース記事のサンプル データセットを収集し、記事を分類するカテゴリを決定しました。 ニュース記事を入力として受け取り、LLM を使用して記事を分類するフローを設計しました。 フローで予想される出力が生成されるかどうかをテストするには、サンプル データセットに対して実行します。

実験フェーズは反復的なプロセスであり、(1) サンプル データセットに対してフローを実行します。 (2) プロンプトのパフォーマンスを 評価 します。 (3) 結果に満足している場合は、評価と絞り込みに 進 むことができます。 改善の余地があると思う場合は、(4) プロンプトまたはフロー自体を変更してフローを 変更 できます。
評価と洗練
サンプル データセットに基づいてニュース記事を分類するフローの出力に満足したら、より大きなデータセットに対してフローのパフォーマンスを評価できます。
より大きなデータセットでフローをテストすることで、LLM アプリケーションが新しいデータにどの程度一般化しているかを評価できます。 評価中に、最適化または絞り込みの潜在的なボトルネックまたは領域を特定できます。
フローを編集するときは、大きなデータセットに対してもう一度実行する前に、まず小さなデータセットに対して実行する必要があります。 小さいデータセットを使用してフローをテストすると、問題にすばやく対応できます。
LLM アプリケーションが堅牢で信頼性が高く、さまざまなシナリオに対応できたら、LLM アプリケーションを運用環境に移行することができます。
生産
最後に、ニュース記事分類アプリケーションを 運用する準備ができました。

製造中において、あなたは:
- 効率と有効性のために受信記事を分類するフローを最適化します。
- フローをエンドポイントにデプロイします。 エンドポイントを呼び出すと、フローがトリガーされて実行され、目的の出力が生成されます。
- 使用状況データとエンドユーザーのフィードバックを収集して、ソリューションのパフォーマンスを監視します。 アプリケーションの実行方法を理解することで、必要に応じてフローを改善できます。
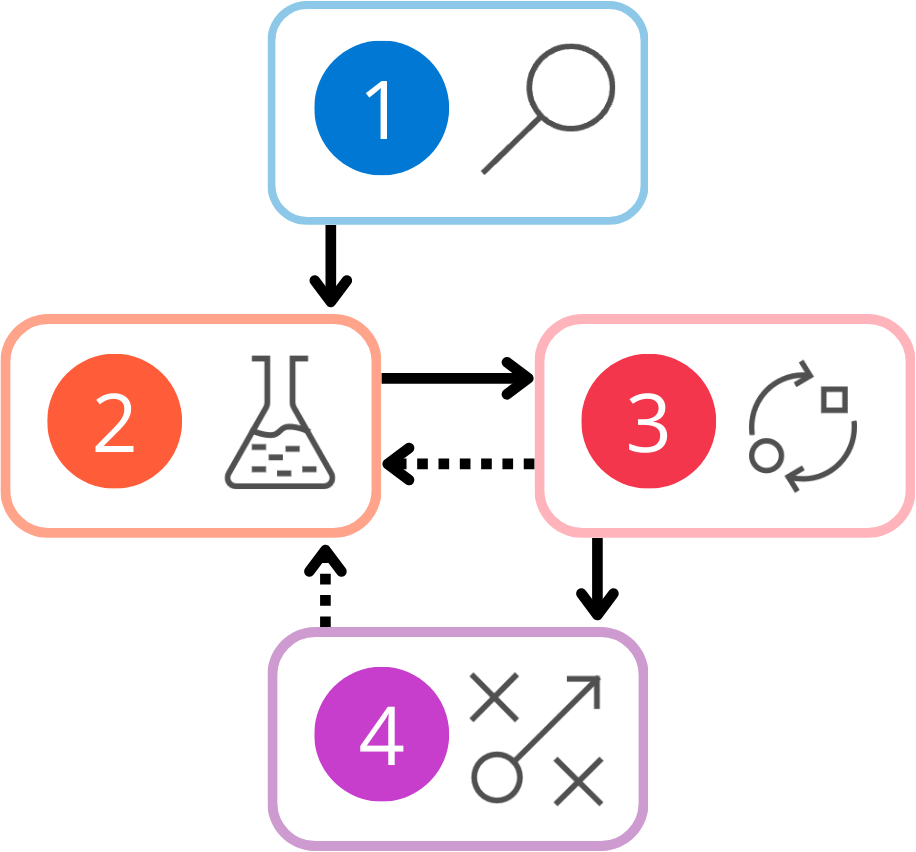
開発ライフサイクル全体を調べる
LLM アプリケーションの開発ライフサイクルの各ステージを理解したら、完全な概要を確認できます。