最新のビジョン モデルを理解する
CNN は、長年にわたってコンピューター ビジョン ソリューションの中核をなしてきました。 これらは、前に説明したように画像分類の問題を解決するために一般的に使用されますが、より複雑なコンピューター ビジョン モデルの基礎でもあります。 たとえば、 物体検出 モデルは、CNN 特徴抽出レイヤーと画像 内の関心領域の 識別を組み合わせて、同じ画像内の複数のクラスのオブジェクトを見つけます。
トランスフォーマー
数十年にわたるコンピューター ビジョンのほとんどの進歩は、CNN ベースのモデルの改善によって推進されてきました。 しかし、別の AI 規範である 自然言語処理 (NLP) では、 トランスフォーマー と呼ばれる別の種類のニューラル ネットワーク アーキテクチャによって、言語の高度なモデルの開発が可能になりました。 トランスフォーマーは、膨大な量のデータを処理し、言語 トークン (個々の単語またはフレーズを表す) をベクターベースの 埋め込み (数値の配列) としてエンコードすることによって機能します。 埋め込みとは、それぞれがトークンのセマンティック属性を表す一連のディメンションを表すものと考えることができます。 埋め込みは、同じコンテキストで一般的に使用されるトークンが、関連のない単語よりも密接に配置されたベクトルを定義するように作成されます。
簡単な例として、次の図は、3 次元ベクトルとしてエンコードされ、3D 空間にプロットされたいくつかの単語を示しています。
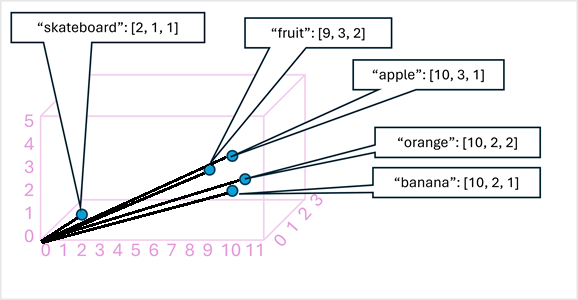
意味的に似たトークンは、同様の方向にエンコードされ、テキスト分析、翻訳、言語生成などのタスク用の高度な NLP ソリューションを構築できるセマンティック言語モデルが作成されます。
注
視覚化が簡単なため、使用したディメンションは 3 つだけです。 実際には、トランスフォーマー ネットワークのエンコーダーは、より多くの次元を持つベクトルを作成し、線形代数計算に基づいてトークン間の複雑なセマンティック 関係を定義します。 関係する数学は、トランスフォーマー モデルのアーキテクチャと同様に複雑です。 ここでの目標は、エンティティ間のリレーションシップをカプセル化するモデルをエンコードによって作成する方法の 概念的 な理解を提供することです。
マルチモーダル モデル
言語モデルを構築する方法としてのトランスフォーマーの成功により、AI 研究者は、画像データに対して同じアプローチが有効かどうかを検討しました。 結果として、固定ラベルのない大量のキャプション付き画像を使用してモデルをトレーニングする マルチモーダル モデルの開発が行 われます。 イメージ エンコーダーは、ピクセル値に基づいて画像から特徴を抽出し、それらを言語エンコーダーによって作成されたテキスト埋め込みと組み合わせます。 モデル全体では、次に示すように、自然言語トークンの埋め込みと画像機能の間の関係がカプセル化されます。
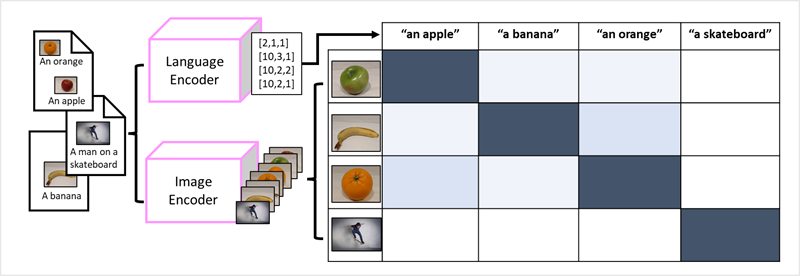
すべてをまとめる
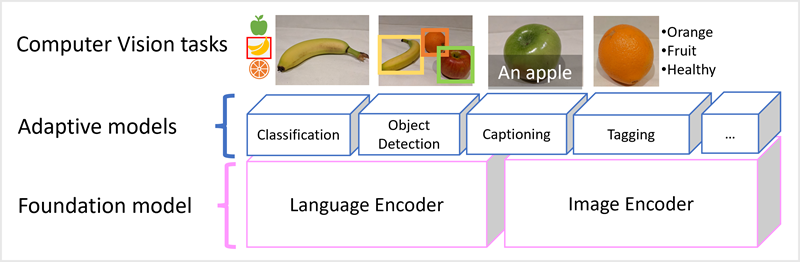
最新のビジョン モデルは、インターネットからの膨大な量のキャプション付き画像でトレーニングされ、言語エンコーダーと画像エンコーダーの両方が含まれています。 多くの場合、ユーザーは 基本 モデルと対話し、適合させます。 基盤モデルは事前トレーニング済みの一般的なモデルであり、専門家のタスク用に複数の アダプティブ モデルを構築できます。 たとえば、以下を実行するように基礎モデルを調整できます。
- 画像分類: 画像がどのカテゴリに属するかを識別します。
- オブジェクト検出: 画像内の個々のオブジェクトを検索します。
- キャプション: 画像の適切な説明を生成します。
- タグ付け: 画像に関連するテキスト タグの一覧をコンパイルします。
マルチモーダル モデルは、コンピューター ビジョンと AI 全般の最先端にあり、AI が可能にするソリューションの種類の進歩を促進することが期待されます。