Spark クラスターを作成する
Azure Databricks ワークスペース UI を使用して、Azure Databricks ワークスペースに 1 つ以上のクラスターを作成できます。
![Azure Databricks ワークスペース UI の [クラスターの作成] インターフェイスのスクリーンショット。](../../wwl-data-ai/use-apache-spark-azure-databricks/media/create-cluster.png)
クラスターを作成するときに、次のような構成設定を指定できます。
- クラスターの名前。
-
クラスター モード。次の場合があります。
- Standard: 複数のワーカー ノードを必要とするシングル ユーザー ワークロードに適しています。
- 高コンカレンシー: 複数のユーザーがクラスターを同時に使用するワークロードに適しています。
- 単一ノード: 1 つのワーカー ノードのみが必要な小規模なワークロードまたはテストに適しています。
- クラスターで使用される Databricks ランタイム のバージョン。これは、Spark のバージョンと、インストールされる Python、Scala などの個々のコンポーネントを示します。
- クラスター内のワーカー ノードに使用される仮想マシン (VM) の種類。
- クラスター内のワーカー ノードの最小数と最大数。
- クラスター内のドライバー ノードに使用される VM の種類。
- クラスターがクラスターの動的なサイズ変更 自動スケールをサポートしているかどうか。
- クラスターが自動的にシャットダウンされるまでのアイドル状態を維持できる期間。
Azure でクラスター リソースを管理する方法
Azure Databricks ワークスペースを作成すると、 Databricks アプライアンス がサブスクリプション内の Azure リソースとしてデプロイされます。 ワークスペースにクラスターを作成するときは、ドライバー ノードとワーカー ノードの両方に使用する仮想マシン (VM) の種類とサイズ、およびその他の構成オプションを指定しますが、Azure Databricks はクラスターの他のすべての側面を管理します。
Databricks アプライアンスは、サブスクリプション内の マネージド リソース グループ として Azure にデプロイされます。 このリソース グループには、クラスターのドライバー VM とワーカー VM と、仮想ネットワーク、セキュリティ グループ、ストレージ アカウントなどの他の必要なリソースが含まれます。 スケジュールされたジョブなど、クラスターのすべてのメタデータは、フォールト トレランスのために geo レプリケーションを使用して Azure Database に格納されます。
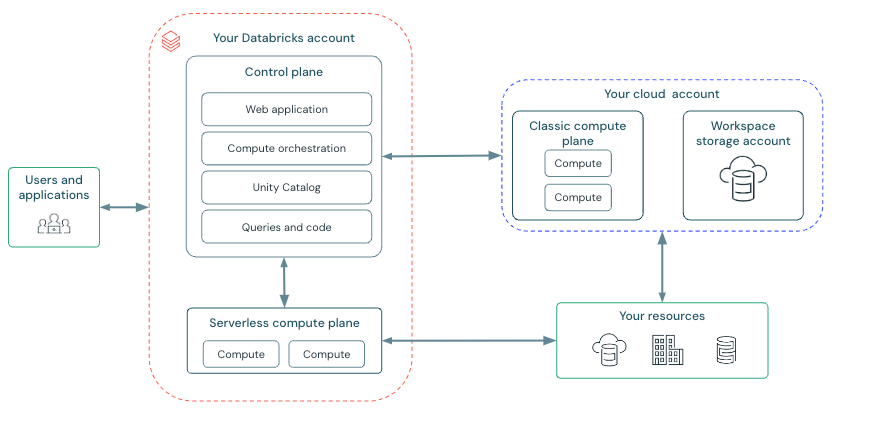
Azure Databricks は、Microsoft によって管理されるバックエンド サービス (Web UI など) と、データ ワークロードが実行されるコンピューティング プレーンで構成される コントロール プレーンという 2 つの主要 なプレーンに分割されます。 コンピューティングには、独自の Azure サブスクリプションと仮想ネットワーク (サブスクリプション内で分離を提供する) を使用するクラシック コンピューティングと、Databricks のマネージド環境内で実行されるが、ワークスペースと同じ Azure リージョン内で実行されるサーバーレス コンピューティングと、顧客間で分離するためのネットワークとセキュリティの制御の 2 つのバリエーションがあります。 すべてのワークスペースには、システム データ (ノートブック、ログ、ジョブ メタデータ)、分散ファイル システム (DBFS)、カタログ資産 (Unity カタログが有効な場合) を保持するストレージ アカウントがあり、セキュリティと適切な分離を確保するためのネットワーク、ファイアウォール、アクセスに関する追加の制御が含まれます。
注
また、クラスターの起動時間を短縮するために、アイドル 状態のノード プールにクラスターをアタッチすることもできます。 詳細については、Azure Databricks ドキュメントの プール を参照してください。