ノートブックで Spark を使用する
Python または Scala スクリプトのコード、Java アーカイブ (JAR) としてコンパイルされた Java コードなど、さまざまな種類のアプリケーションを Spark で実行できます。 Spark は、一般的に次の 2 種類のワークロードで使用されます。
- データの取り込み、クリーニング、変換を行うバッチ処理ジョブまたはストリーム処理ジョブ。多くの場合、自動化されたパイプラインの一部として実行されます。
- データの探索、分析、視覚化を行う対話型分析セッション。
ノートブックの編集とコードの基本
Databricks ノートブックは、データ サイエンス、エンジニアリング、分析の主要なワークスペースです。 これらは、コードまたは書式設定されたテキスト (Markdown) を含むことができるセルを中心に構築されています。 このセルベースのアプローチにより、作業を 1 か所で簡単に実験、テスト、説明できます。 1 つのセル、セルのグループ、またはノートブック全体を実行できます。テーブル、グラフ、プレーン テキストなどの出力は、実行されたセルのすぐ下に表示されます。 セルを並べ替えたり、折りたたんだり、クリアしたりして、ノートブックを整理して読みやすくすることができます。

Databricks ノートブックの主な強みは、多言語サポートです。 多くの場合、既定値は Python ですが、%sql や %scalaなどのマジック コマンドを使用して、同じノートブック内で SQL、Scala、または R に切り替えることができます。 この柔軟性は、SQL で ETL ロジックを記述し、Python で機械学習コードを記述し、R を使用して結果を視覚化できることを意味します。すべて 1 つのワークフローで行うことができます。 Databricks にはオートコンプリートと構文の強調表示も用意されているため、間違いを簡単にキャッチし、コーディングを高速化できます。
コードを実行する前に、ノートブックをクラスターにアタッチする必要があります。 クラスターがアタッチされていないと、コード セルを実行できません。 ノートブック ツール バーから既存のクラスターを選択するか、新しいクラスターを作成できます。また、必要に応じてノートブックを簡単にデタッチして再アタッチできます。 この接続により、ノートブックは Azure Databricks の分散処理能力を活用できます。
Databricks Assistant の使用
Databricks Assistant は、ノートブックに直接組み込まれた AI を利用したコーディング コンパニオンです。 その目的は、ノートブックとワークスペースのコンテキストを活用して、コードをより効率的に記述、理解、改善できるように支援することです。 自然言語プロンプトから新しいコードを生成したり、複雑なロジックを説明したり、エラーの修正を提案したり、パフォーマンスを最適化したり、読みやすくするためにコードをリファクタリングまたは書式設定したりできます。 これにより、Spark や SQL を初めて学習する場合だけでなく、開発を高速化し、反復作業を減らしたい経験豊富なユーザーにも価値があります。
アシスタントは コンテキスト対応です。つまり、ノートブック、クラスター、データ環境に関する情報を使用して、調整された提案を提供できます。 たとえば、ワークスペースで Unity カタログが有効になっている場合、SQL クエリの作成時にテーブル名、列名、スキーマなどのメタデータを取得できます。 これにより、"売上テーブルからリージョン別の平均売上金額を選択する" などの質問を行い、実際のデータ モデルに合った SQL コードを動作させることができます。 同様に、Python では、メモリからすべての関数シグネチャを呼び出すことなく、データ変換または Spark ジョブを作成するように要求できます。
あなたは主に次の2つの方法でアシスタントと対話します。
自然言語プロンプト - チャットのようなインターフェイスにプレーンな英語の命令を入力すると、ノートブックにコードが挿入されます。
スラッシュ コマンド - 選択したコードに対して操作できる
/explain、/fix、/optimizeなどのクイック コマンド。 たとえば、/explain複雑な関数を簡単な手順に分解/fix、構文エラーやランタイム エラーの解決を試みることができ、/optimizeは再パーティション分割や効率的な Spark 関数の使用などのパフォーマンスの向上を提案します。
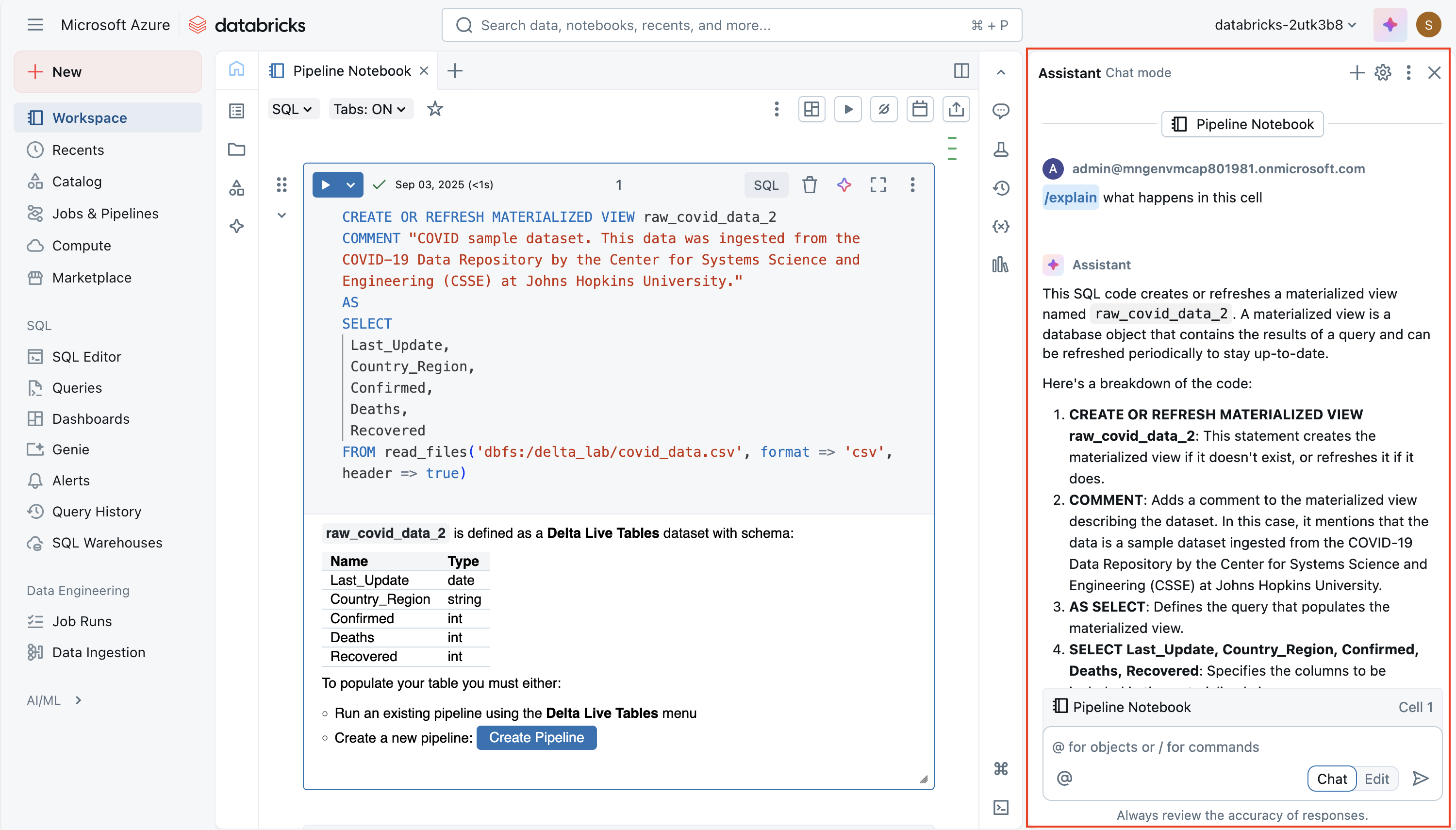
強力な機能は編集モードであり、アシスタントは複数のセルにわたってより大きな構造変更を提案できます。 たとえば、繰り返しのロジックを 1 つの再利用可能な関数にリファクタリングしたり、ワークフローを再構築して読みやすくすることができます。 常に制御できます。提案は非破壊的です。つまり、ノートブックに変更を適用する前に、提案を確認して承諾または拒否できます。
コードの共有とモジュール化
重複を回避し、保守容易性を向上させるために、Databricks では、ノートブックをインポートできるワークスペース内のファイル (.py モジュールなど) への再利用可能なコードの配置がサポートされています。 ノートブックを調整するメカニズム (つまり、他のノートブックからノートブックを実行する、または複数のタスクを含むジョブ) があるため、共有関数またはモジュールを使用するワークフローを構築できます。
%runを使用すると、いくつかの制限がありますが、別のノートブックを含める方が簡単です。
デバッグ、バージョン履歴、誤操作のやり直し
Databricks には、Python ノートブック用の対話型 デバッガー が組み込まれています。ブレークポイントの設定、実行のステップ 実行、変数の検査、コード実行のステップ バイ ステップでの移動を行うことができます。 これにより、印刷/ログ デバッグよりも効率的にバグを分離できます。

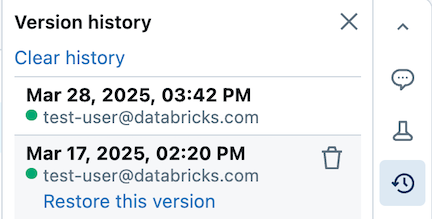
ノートブックでは、バージョン履歴も自動的に保持されます。過去のスナップショットの表示、バージョンの説明の提供、古いバージョンの復元、履歴の削除/クリアを行うことができます。 Git 統合を使用している場合は、リポジトリ内のノートブック/ファイルの同期とバージョン管理を行うことができます。
ヒント
Azure Databricks でのノートブックの操作の詳細については、Azure Databricks ドキュメントの Notebooks 記事を参照してください。