이 빠른 시작에서는 Azure OpenAI 모델과 함께 사용자 고유의 데이터를 사용하여 더 빠르고 정확한 통신을 가능하게 하는 강력하고 대화형 AI 플랫폼을 만듭니다.
중요합니다
사용자 고유의 데이터를 사용하여 대화형 솔루션을 빌드하는 새로운 방법이 있습니다. 권장되는 최신 방법은 빠른 시작을 참조하세요. Azure AI Search에서 에이전트 검색 사용
필수 조건
- 자체 데이터가 없으면 GitHub에서 데이터 예를 다운로드합니다.
Azure AI 파운드리 포털을 사용하여 데이터 추가
팁 (조언)
Azure 개발자 CLI를 사용하여 Azure OpenAI On Your Data에 필요한 리소스를 프로그래밍 방식으로 만들 수 있음
Azure AI 파운드리 포털로 이동하고 Azure OpenAI 리소스에 액세스할 수 있는 자격 증명으로 로그인합니다. Azure AI Foundry 리소스가 있는 경우 Azure AI Foundry 프로젝트를 만들 수 있습니다.
왼쪽 창의 플레이그라운드 아래에서 채팅을 선택하고 모델 배포를 선택합니다.
채팅 플레이그라운드에서 데이터 추가를 선택한 다음 데이터 원본 추가를 선택합니다.

표시되는 창의 데이터 원본 선택에서 파일 업로드(미리 보기)를 선택합니다. Azure OpenAI는 데이터에 액세스하고 인덱싱하기 위해 스토리지 리소스와 검색 리소스가 모두 필요합니다.
팁 (조언)
- 자세한 내용은 다음 리소스를 참조하세요.
- 긴 텍스트가 있는 문서 및 데이터 세트의 경우 사용 가능한 데이터 준비 스크립트를 사용하는 것이 좋습니다.
Azure OpenAI가 스토리지 계정에 액세스하려면 CORS(원본 간 리소스 공유)를 설정해야 합니다. Azure Blob Storage 리소스에 대해 CORS가 아직 켜져 있지 않은 경우 CORS 켜기를 선택합니다.
Azure AI 검색 리소스를 선택하고, 연결하면 계정에서 사용량이 발생한다는 데에 확인을 선택합니다. 그런 후 다음을 선택합니다.
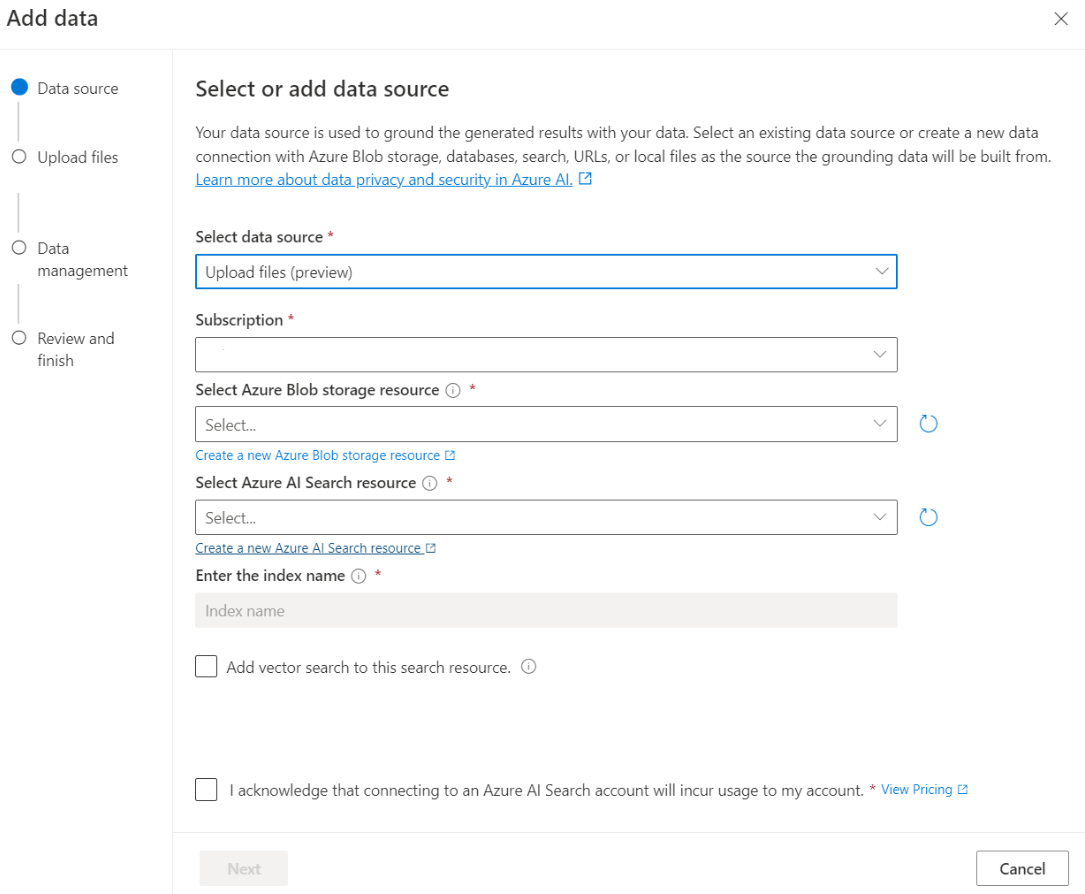
파일 업로드 창에서 파일 찾아보기를 선택하고 필수 조건 섹션에서 다운로드한 파일이나 자체 데이터를 선택합니다. 그런 다음 파일 업로드를 선택합니다. 그런 후 다음을 선택합니다.
데이터 관리 창에서 인덱스에 의미 체계 검색 또는 벡터 검색을 사용할지를 선택할 수 있습니다.
중요합니다
- 의미 체계 검색 및 벡터 검색에는 추가 가격이 적용됩니다. 의미 체계 검색 또는 벡터 검색을 사용하도록 설정하려면 기본 이상의 SKU를 선택해야 합니다. 자세한 내용은 가격 책정 계층 차이 및 서비스 제한을 참조하세요.
- 정보 검색 및 모델 응답의 품질을 향상하려면 영어, 프랑스어, 스페인어, 포르투갈어, 이탈리아어, 독일, 중국어(Zh), 일본어, 한국어, 러시아어 및 아랍어와 같은 데이터 원본 언어에 대해 의미 체계 검색을 사용하도록 설정하는 것이 좋습니다.
입력한 세부 정보를 검토하고 저장 및 닫기를 선택하세요. 이제 모델과 채팅할 수 있으며 모델은 데이터 정보를 사용하여 응답을 생성합니다.


채팅 플레이그라운드
채팅 플레이그라운드를 통해 코드 없는 접근 방식을 사용하여 Azure OpenAI 기능 탐색을 시작합니다. 플레이그라운드는 완료를 생성하는 프롬프트를 제출할 수 있는 간단한 텍스트 상자입니다. 이 페이지에서 쉽게 기능을 반복하고 실험해 볼 수 있습니다.

플레이그라운드에서는 채팅 환경을 맞춤화할 수 있는 옵션을 제공합니다. 위쪽 메뉴에서 배포를 선택하여 인덱스의 검색 결과를 사용하여 응답을 생성하는 모델을 결정할 수 있습니다. 향후 생성되는 응답에 대한 대화 기록으로 포함할 과거 메시지 수를 선택합니다. 대화 기록은 관련 응답을 생성하기 위한 컨텍스트를 제공하지만 토큰 사용량도 소비합니다. 입력 토큰 진행률 표시기는 제출한 질문의 토큰 수를 추적합니다.
왼쪽에 있는 고급 설정은 데이터 검색을 제어하고 관련 정보를 검색할 수 있는 런타임 매개 변수입니다. 좋은 사용 사례는 데이터를 기반으로만 응답이 생성되도록 하거나 모델이 데이터에 존재하는 정보를 기반으로 응답을 생성할 수 없는 경우입니다.
엄격성은 유사성 점수를 기반으로 검색 문서를 필터링하는 시스템의 공격성을 결정합니다. 엄격도를 5로 설정하면 시스템이 매우 높은 유사성 임계값을 적용하여 문서를 적극적으로 필터링한다는 의미입니다. 의미 체계 검색은 순위 모델이 쿼리의 의도를 더욱 효과적으로 유추하기 때문에 이 시나리오에서는 의미 체계 순위가 유용할 수 있습니다. 엄격성 수준이 낮을수록 자세한 답변이 생성되지만 인덱스에 없는 정보가 포함될 수도 있습니다. 기본적으로 3으로 설정되어 있습니다.
검색된 문서는 3, 5, 10 또는 20으로 설정할 수 있는 정수이며 최종 응답을 수식화하기 위해 대규모 언어 모델에 제공되는 문서 청크 수를 제어합니다. 기본적으로 5로 설정됩니다.
데이터에 대한 응답 제한이 사용하도록 설정되면 모델은 응답을 위해 문서에만 의존하려고 시도합니다. 이는 기본적으로 true로 설정됩니다.

첫 번째 쿼리를 전송합니다. 채팅 모델은 질문 및 답변 연습에서 가장 효과적으로 수행됩니다. 예를 들어, "사용 가능한 건강 보험은 무엇인가요?" 또는 "건강 플러스 옵션은 무엇인가요?"입니다.
"가장 자주 사용되는 건강 보험은 무엇인가요?"와 같이 데이터 분석이 필요한 쿼리는 실패할 수 있습니다. "내가 업로드한 문서 수는 몇 개인가요?"와 같이 모든 데이터에 대한 정보가 필요한 쿼리도 실패할 가능성이 높습니다. 검색 엔진은 쿼리에 정확한 용어나 유사한 용어, 구 또는 구성이 있는 청크를 찾는다는 점을 기억하세요. 모델이 질문을 이해할 수도 있지만 검색 결과가 데이터 세트의 일부인 경우 해당 질문에 답하는 데 적합한 정보가 아닙니다.
채팅은 응답에서 반환된 문서(청크)의 수에 의해 제한됩니다(Azure AI 파운드리 포털 플레이그라운드에서는 3~20개로 제한됨). 여러분이 상상할 수 있듯이 "모든 제목"에 대한 질문을 제기하려면 전체 벡터 저장소의 전체 검사가 필요합니다.
모델 배포
환경에 만족하면 배포 단추를 선택하여 포털에서 직접 웹앱을 배포할 수 있습니다.

이를 통해 모델에서 자체 데이터를 사용하는 경우 독립형 웹 애플리케이션에 배포하거나 Copilot Studio(미리 보기)의 Copilot에 배포할 수 있는 옵션이 제공됩니다.
예를 들어 웹앱을 배포하도록 선택하는 경우:
웹앱을 처음 배포할 때 새 웹앱 만들기를 선택해야 합니다. 앱 URL의 일부가 될 앱의 이름을 선택합니다. 예: https://<appname>.azurewebsites.net.
게시된 앱에 대한 구독, 리소스 그룹, 위치 및 가격 책정 계획을 선택합니다. 기존 앱을 업데이트하려면 기존 웹앱에 게시를 선택하고 드롭다운 메뉴에서 이전 앱의 이름을 선택합니다.
웹앱을 배포하도록 선택하는 경우 웹앱을 사용하기 위한 중요한 고려 사항을 참조하세요.
필수 조건
- Azure 구독 – 무료로 만드세요.
- 자체 데이터가 없으면 GitHub에서 데이터 예를 다운로드합니다.
- .NET 8 SDK
Azure AI 파운드리 포털을 사용하여 데이터 추가
팁 (조언)
Azure 개발자 CLI를 사용하여 Azure OpenAI On Your Data에 필요한 리소스를 프로그래밍 방식으로 만들 수 있음
Azure AI 파운드리 포털로 이동하고 Azure OpenAI 리소스에 액세스할 수 있는 자격 증명으로 로그인합니다. Azure AI Foundry 리소스가 있는 경우 Azure AI Foundry 프로젝트를 만들 수 있습니다.
왼쪽 창의 플레이그라운드 아래에서 채팅을 선택하고 모델 배포를 선택합니다.
채팅 플레이그라운드에서 데이터 추가를 선택한 다음 데이터 원본 추가를 선택합니다.
표시되는 창의 데이터 원본 선택에서 파일 업로드(미리 보기)를 선택합니다. Azure OpenAI는 데이터에 액세스하고 인덱싱하기 위해 스토리지 리소스와 검색 리소스가 모두 필요합니다.
팁 (조언)
- 자세한 내용은 다음 리소스를 참조하세요.
- 긴 텍스트가 있는 문서 및 데이터 세트의 경우 사용 가능한 데이터 준비 스크립트를 사용하는 것이 좋습니다.
Azure OpenAI가 스토리지 계정에 액세스하려면 CORS(원본 간 리소스 공유)를 설정해야 합니다. Azure Blob Storage 리소스에 대해 CORS가 아직 켜져 있지 않은 경우 CORS 켜기를 선택합니다.
Azure AI 검색 리소스를 선택하고, 연결하면 계정에서 사용량이 발생한다는 데에 확인을 선택합니다. 그런 후 다음을 선택합니다.
파일 업로드 창에서 파일 찾아보기를 선택하고 필수 조건 섹션에서 다운로드한 파일이나 자체 데이터를 선택합니다. 그런 다음 파일 업로드를 선택합니다. 그런 후 다음을 선택합니다.
데이터 관리 창에서 인덱스에 의미 체계 검색 또는 벡터 검색을 사용할지를 선택할 수 있습니다.
중요합니다
- 의미 체계 검색 및 벡터 검색에는 추가 가격이 적용됩니다. 의미 체계 검색 또는 벡터 검색을 사용하도록 설정하려면 기본 이상의 SKU를 선택해야 합니다. 자세한 내용은 가격 책정 계층 차이 및 서비스 제한을 참조하세요.
- 정보 검색 및 모델 응답의 품질을 향상하려면 영어, 프랑스어, 스페인어, 포르투갈어, 이탈리아어, 독일, 중국어(Zh), 일본어, 한국어, 러시아어 및 아랍어와 같은 데이터 원본 언어에 대해 의미 체계 검색을 사용하도록 설정하는 것이 좋습니다.
입력한 세부 정보를 검토하고 저장 및 닫기를 선택하세요. 이제 모델과 채팅할 수 있으며 모델은 데이터 정보를 사용하여 응답을 생성합니다.
리소스 정보 검색
Azure OpenAI 리소스를 사용하여 애플리케이션을 인증하려면 다음 정보를 검색해야 합니다. 이 빠른 시작은 Azure Blob Storage 계정에 데이터를 업로드했으며 Azure AI 검색 인덱스를 만들었다고 가정합니다. Azure AI 파운드리 포털을 사용하여 데이터 추가를 참조하세요.
| 변수 이름 | 가치 |
|---|---|
AZURE_OPENAI_ENDPOINT |
이 값은 Azure Portal에서 Azure OpenAI 리소스를 검사할 때 키 엔드포인트 섹션에서 찾을 수 있습니다. 예제 엔드포인트는 https://my-resoruce.openai.azure.com입니다. |
AZURE_OPENAI_DEPLOYMENT_NAME |
이 값은 모델을 배포할 때 배포에 대해 선택한 사용자 지정 이름에 해당합니다. 이 값은 Azure Portal의 리소스 관리>배포에서 찾을 수 있습니다. |
AZURE_AI_SEARCH_ENDPOINT |
이 값은 Azure Portal에서 Azure AI 검색 리소스를 검사할 때 개요 섹션에서 찾을 수 있습니다. |
AZURE_AI_SEARCH_INDEX |
이 값은 데이터를 저장하기 위해 만든 인덱스의 이름에 해당합니다. 이 값은 Azure Portal에서 Azure AI 검색 리소스를 검사할 때 개요 섹션에서 찾을 수 있습니다. |
프로젝트 디렉터리에서 Program.cs 파일을 열고, 해당 내용을 다음 코드로 바꿉니다.
using System;
using Azure.AI.OpenAI;
using System.ClientModel;
using Azure.AI.OpenAI.Chat;
using OpenAI.Chat;
using static System.Environment;
string azureOpenAIEndpoint = GetEnvironmentVariable("AZURE_OPENAI_ENDPOINT");
string azureOpenAIKey = GetEnvironmentVariable("AZURE_OPENAI_API_KEY");
string deploymentName = GetEnvironmentVariable("AZURE_OPENAI_DEPLOYMENT_NAME");
string searchEndpoint = GetEnvironmentVariable("AZURE_AI_SEARCH_ENDPOINT");
string searchKey = GetEnvironmentVariable("AZURE_AI_SEARCH_API_KEY");
string searchIndex = GetEnvironmentVariable("AZURE_AI_SEARCH_INDEX");
AzureOpenAIClient openAIClient = new(
new Uri(azureOpenAIEndpoint),
new ApiKeyCredential(azureOpenAIKey));
ChatClient chatClient = openAIClient.GetChatClient(deploymentName);
// Extension methods to use data sources with options are subject to SDK surface changes. Suppress the
// warning to acknowledge and this and use the subject-to-change AddDataSource method.
#pragma warning disable AOAI001
ChatCompletionOptions options = new();
options.AddDataSource(new AzureSearchChatDataSource()
{
Endpoint = new Uri(searchEndpoint),
IndexName = searchIndex,
Authentication = DataSourceAuthentication.FromApiKey(searchKey),
});
ChatCompletion completion = chatClient.CompleteChat(
[
new UserChatMessage("What health plans are available?"),
],
options);
ChatMessageContext onYourDataContext = completion.GetMessageContext();
if (onYourDataContext?.Intent is not null)
{
Console.WriteLine($"Intent: {onYourDataContext.Intent}");
}
foreach (ChatCitation citation in onYourDataContext?.Citations ?? [])
{
Console.WriteLine($"Citation: {citation.Content}");
}
중요합니다
프로덕션의 경우 Azure Key Vault와 같은 자격 증명을 안전하게 저장하고 액세스하는 방법을 사용합니다. 자격 증명 보안에 대한 자세한 내용은 이 보안 문서를 참조하세요.
dotnet run Program.cs
출력
Contoso Electronics offers two health plans: Northwind Health Plus and Northwind Standard [doc1]. Northwind Health Plus is a comprehensive plan that provides coverage for medical, vision, and dental services, prescription drug coverage, mental health and substance abuse coverage, and coverage for preventive care services. It also offers coverage for emergency services, both in-network and out-of-network. On the other hand, Northwind Standard is a basic plan that provides coverage for medical, vision, and dental services, prescription drug coverage, and coverage for preventive care services. However, it does not offer coverage for emergency services, mental health and substance abuse coverage, or out-of-network services [doc1].
Intent: ["What are the available health plans?", "List of health plans available", "Health insurance options", "Types of health plans offered"]
Citation:
Contoso Electronics plan and benefit packages
Thank you for your interest in the Contoso electronics plan and benefit packages. Use this document to
learn more about the various options available to you...// Omitted for brevity
결과를 인쇄하기 전에 모델이 전체 응답을 생성할 때까지 기다립니다.
필수 조건
- Azure OpenAI
- Azure Blob Storage
- Azure AI 검색
-
Azure OpenAI 또는 지원되는 지역에서 지원되는 모델을 사용하여 배포됩니다.
- 적어도 Azure OpenAI 리소스에 대한 Cognitive Services 기여자 역할이 할당되어야 합니다.
- 자체 데이터가 없으면 GitHub에서 데이터 예를 다운로드합니다.
Azure AI 파운드리 포털을 사용하여 데이터 추가
팁 (조언)
Azure 개발자 CLI를 사용하여 Azure OpenAI On Your Data에 필요한 리소스를 프로그래밍 방식으로 만들 수 있음
Azure AI 파운드리 포털로 이동하고 Azure OpenAI 리소스에 액세스할 수 있는 자격 증명으로 로그인합니다. Azure AI Foundry 리소스가 있는 경우 Azure AI Foundry 프로젝트를 만들 수 있습니다.
왼쪽 창의 플레이그라운드 아래에서 채팅을 선택하고 모델 배포를 선택합니다.
채팅 플레이그라운드에서 데이터 추가를 선택한 다음 데이터 원본 추가를 선택합니다.
표시되는 창의 데이터 원본 선택에서 파일 업로드(미리 보기)를 선택합니다. Azure OpenAI는 데이터에 액세스하고 인덱싱하기 위해 스토리지 리소스와 검색 리소스가 모두 필요합니다.
팁 (조언)
- 자세한 내용은 다음 리소스를 참조하세요.
- 긴 텍스트가 있는 문서 및 데이터 세트의 경우 사용 가능한 데이터 준비 스크립트를 사용하는 것이 좋습니다.
Azure OpenAI가 스토리지 계정에 액세스하려면 CORS(원본 간 리소스 공유)를 설정해야 합니다. Azure Blob Storage 리소스에 대해 CORS가 아직 켜져 있지 않은 경우 CORS 켜기를 선택합니다.
Azure AI 검색 리소스를 선택하고, 연결하면 계정에서 사용량이 발생한다는 데에 확인을 선택합니다. 그런 후 다음을 선택합니다.
파일 업로드 창에서 파일 찾아보기를 선택하고 필수 조건 섹션에서 다운로드한 파일이나 자체 데이터를 선택합니다. 그런 다음 파일 업로드를 선택합니다. 그런 후 다음을 선택합니다.
데이터 관리 창에서 인덱스에 의미 체계 검색 또는 벡터 검색을 사용할지를 선택할 수 있습니다.
중요합니다
- 의미 체계 검색 및 벡터 검색에는 추가 가격이 적용됩니다. 의미 체계 검색 또는 벡터 검색을 사용하도록 설정하려면 기본 이상의 SKU를 선택해야 합니다. 자세한 내용은 가격 책정 계층 차이 및 서비스 제한을 참조하세요.
- 정보 검색 및 모델 응답의 품질을 향상하려면 영어, 프랑스어, 스페인어, 포르투갈어, 이탈리아어, 독일, 중국어(Zh), 일본어, 한국어, 러시아어 및 아랍어와 같은 데이터 원본 언어에 대해 의미 체계 검색을 사용하도록 설정하는 것이 좋습니다.
입력한 세부 정보를 검토하고 저장 및 닫기를 선택하세요. 이제 모델과 채팅할 수 있으며 모델은 데이터 정보를 사용하여 응답을 생성합니다.
필요한 변수 검색
Azure OpenAI 호출을 성공적으로 수행하려면 다음 변수가 필요합니다. 이 빠른 시작은 Azure Blob Storage 계정에 데이터를 업로드했으며 Azure AI 검색 인덱스를 만들었다고 가정합니다. 자세한 내용은 Azure AI 파운드리를 사용하여 데이터 추가를 참조하세요.
| 변수 이름 | 가치 |
|---|---|
AZURE_OPENAI_ENDPOINT |
이 값은 Azure Portal에서 Azure OpenAI 리소스를 검사할 때 키 엔드포인트 섹션에서 찾을 수 있습니다. 또는 Azure AI 파운드리>채팅 플레이그라운드>코드 보기에서 값을 찾을 수 있습니다. 예제 엔드포인트는 https://my-resource.openai.azure.com입니다. |
AZURE_OPENAI_API_KEY |
이 값은 Azure Portal에서 Azure OpenAI 리소스를 검사할 때 리소스 관리>키 엔드포인트 섹션에서 찾을 수 있습니다.
KEY1 또는 KEY2를 사용할 수 있습니다. 항상 두 개의 키를 사용하면 서비스 중단 없이 키를 안전하게 회전하고 다시 생성할 수 있습니다. |
AZURE_OPEN_AI_DEPLOYMENT_ID |
이 값은 모델을 배포할 때 배포에 대해 선택한 사용자 지정 이름에 해당합니다. 이 값은 Azure Portal의 리소스 관리>배포에서 또는 Azure AI 파운드리 포털의 관리>배포에서 찾을 수 있습니다. |
AZURE_AI_SEARCH_ENDPOINT |
이 값은 Azure Portal에서 Azure AI 검색 리소스를 검사할 때 개요 섹션에서 찾을 수 있습니다. |
AZURE_AI_SEARCH_API_KEY |
이 값은 Azure Portal에서 Azure AI 검색 리소스를 검사할 때 설정>키 섹션에서 찾을 수 있습니다. 기본 관리 키 또는 보조 관리 키를 사용할 수 있습니다. 항상 두 개의 키를 사용하면 서비스 중단 없이 키를 안전하게 회전하고 다시 생성할 수 있습니다. |
AZURE_AI_SEARCH_INDEX |
이 값은 데이터를 저장하기 위해 만든 인덱스의 이름에 해당합니다. 이 값은 Azure Portal에서 Azure AI 검색 리소스를 검사할 때 개요 섹션에서 찾을 수 있습니다. |
환경 변수
키 및 엔드포인트에 대한 영구 환경 변수를 만들고 할당합니다.
중요합니다
주의해서 API 키를 사용합니다. API 키를 코드에 직접 포함하지 말고, 공개적으로 게시하지 마세요. API 키를 사용하는 경우 Azure Key Vault에 안전하게 저장합니다. 앱에서 API 키를 안전하게 사용하는 방법에 대한 자세한 내용은 Azure Key Vault를 사용하여 API 키를 참조하세요.
AI 서비스 보안에 대한 자세한 내용은 Azure AI 서비스에 대한 요청 인증을 참조하세요.
비고
Spring AI는 기본적으로 모델 이름을 gpt-35-turbo로 지정합니다. 다른 이름으로 모델을 배포한 경우에만 SPRING_AI_AZURE_OPENAI_MODEL 값을 제공하면 됩니다.
export SPRING_AI_AZURE_OPENAI_ENDPOINT=REPLACE_WITH_YOUR_AOAI_ENDPOINT_VALUE_HERE
export SPRING_AI_AZURE_OPENAI_API_KEY=REPLACE_WITH_YOUR_AOAI_KEY_VALUE_HERE
export SPRING_AI_AZURE_COGNITIVE_SEARCH_ENDPOINT=REPLACE_WITH_YOUR_AZURE_SEARCH_RESOURCE_VALUE_HERE
export SPRING_AI_AZURE_COGNITIVE_SEARCH_API_KEY=REPLACE_WITH_YOUR_AZURE_SEARCH_RESOURCE_KEY_VALUE_HERE
export SPRING_AI_AZURE_COGNITIVE_SEARCH_INDEX=REPLACE_WITH_YOUR_INDEX_NAME_HERE
export SPRING_AI_AZURE_OPENAI_MODEL=REPLACE_WITH_YOUR_MODEL_NAME_HERE
새로운 Spring 애플리케이션 만들기
Spring AI는 현재 Azure AI 쿼리가 RAG(AzureCognitiveSearchChatExtensionConfiguration) 메서드를 캡슐화하고 사용자로부터 세부 정보를 숨길 수 있는 옵션을 지원하지 않습니다. 또는 애플리케이션에서 직접 RAG 메서드를 호출하여 Azure AI 검색 인덱스에서 데이터를 쿼리하고 검색된 문서를 사용하여 쿼리를 보강할 수 있습니다.
Spring AI는 VectorStore 추상화 기능을 지원하며, 사용자 지정 데이터를 쿼리하기 위해 Spring AI VectorStore 구현에 Azure AI 검색을 래핑할 수 있습니다. 다음 프로젝트는 Azure AI 검색에서 지원되는 사용자 지정 VectorStore를 구현하고 직접 RAG 작업을 실행합니다.
Bash 창에서 앱에 대한 새 디렉터리를 만들고 해당 디렉터리로 이동합니다.
mkdir ai-custom-data-demo && cd ai-custom-data-demo
작업 디렉터리에서 spring init 명령을 실행합니다. 이 명령은 기본 Java 클래스 원본 파일과 Maven 기반 프로젝트 관리에 사용되는 pom.xml 파일을 포함하여 Spring 프로젝트에 대한 표준 디렉터리 구조를 만듭니다.
spring init -a ai-custom-data-demo -n AICustomData --force --build maven -x
생성된 파일 및 폴더는 다음 구조와 유사합니다.
ai-custom-data-demo/
|-- pom.xml
|-- mvn
|-- mvn.cmd
|-- HELP.md
|-- src/
|-- main/
| |-- resources/
| | |-- application.properties
| |-- java/
| |-- com/
| |-- example/
| |-- aicustomdatademo/
| |-- AiCustomDataApplication.java
|-- test/
|-- java/
|-- com/
|-- example/
|-- aicustomdatademo/
|-- AiCustomDataApplicationTests.java
Spring 애플리케이션 편집
pom.xml 파일을 편집합니다.
프로젝트 디렉터리의 루트에서 원하는 편집기나 IDE로 pom.xml 파일을 열고 다음 콘텐츠로 파일을 덮어씁니다.
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>3.2.0</version> <relativePath/> <!-- lookup parent from repository --> </parent> <groupId>com.example</groupId> <artifactId>ai-custom-data-demo</artifactId> <version>0.0.1-SNAPSHOT</version> <name>AICustomData</name> <description>Demo project for Spring Boot</description> <properties> <java.version>17</java.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> </dependency> <dependency> <groupId>org.springframework.experimental.ai</groupId> <artifactId>spring-ai-azure-openai-spring-boot-starter</artifactId> <version>0.7.0-SNAPSHOT</version> </dependency> <dependency> <groupId>com.azure</groupId> <artifactId>azure-search-documents</artifactId> <version>11.6.0-beta.10</version> <exclusions> <!-- exclude this to avoid changing the default serializer and the null-value behavior --> <exclusion> <groupId>com.azure</groupId> <artifactId>azure-core-serializer-json-jackson</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins> </build> <repositories> <repository> <id>spring-snapshots</id> <name>Spring Snapshots</name> <url>https://repo.spring.io/snapshot</url> <releases> <enabled>false</enabled> </releases> </repository> </repositories> </project>src/main/java/com/example/aicustomdatademo 폴더에서 원하는 편집기나 IDE로 AiCustomDataApplication.java를 열고 다음 코드를 붙여넣습니다.
package com.example.aicustomdatademo; import java.util.Collections; import java.util.List; import java.util.Map; import java.util.Optional; import java.util.stream.Collectors; import org.springframework.ai.client.AiClient; import org.springframework.ai.document.Document; import org.springframework.ai.embedding.EmbeddingClient; import org.springframework.ai.prompt.Prompt; import org.springframework.ai.prompt.SystemPromptTemplate; import org.springframework.ai.prompt.messages.MessageType; import org.springframework.ai.prompt.messages.UserMessage; import org.springframework.ai.vectorstore.VectorStore; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.beans.factory.annotation.Value; import org.springframework.boot.CommandLineRunner; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.context.annotation.Bean; import com.azure.core.credential.AzureKeyCredential; import com.azure.core.util.Context; import com.azure.search.documents.SearchClient; import com.azure.search.documents.SearchClientBuilder; import com.azure.search.documents.models.IndexingResult; import com.azure.search.documents.models.SearchOptions; import com.azure.search.documents.models.RawVectorQuery; import lombok.AllArgsConstructor; import lombok.NoArgsConstructor; import lombok.Builder; import lombok.Data; import lombok.extern.jackson.Jacksonized; @SpringBootApplication public class AiCustomDataApplication implements CommandLineRunner { private static final String ROLE_INFO_KEY = "role"; private static final String template = """ You are a helpful assistant. Use the information from the DOCUMENTS section to augment answers. DOCUMENTS: {documents} """; @Value("${spring.ai.azure.cognitive-search.endpoint}") private String acsEndpoint; @Value("${spring.ai.azure.cognitive-search.api-key}") private String acsApiKey; @Value("${spring.ai.azure.cognitive-search.index}") private String acsIndexName; @Autowired private AiClient aiClient; @Autowired private EmbeddingClient embeddingClient; public static void main(String[] args) { SpringApplication.run(AiCustomDataApplication.class, args); } @Override public void run(String... args) throws Exception { System.out.println(String.format("Sending custom data prompt to AI service. One moment please...\r\n")); final var store = vectorStore(embeddingClient); final String question = "What are my available health plans?"; final var candidateDocs = store.similaritySearch(question); final var userMessage = new UserMessage(question); final String docPrompts = candidateDocs.stream().map(entry -> entry.getContent()).collect(Collectors.joining("\n")); final SystemPromptTemplate promptTemplate = new SystemPromptTemplate(template); final var systemMessage = promptTemplate.createMessage(Map.of("documents", docPrompts)); final var prompt = new Prompt(List.of(systemMessage, userMessage)); final var resps = aiClient.generate(prompt); System.out.println(String.format("Prompt created %d generated response(s).", resps.getGenerations().size())); resps.getGenerations().stream() .forEach(gen -> { final var role = gen.getInfo().getOrDefault(ROLE_INFO_KEY, MessageType.ASSISTANT.getValue()); System.out.println(String.format("Generated respose from \"%s\": %s", role, gen.getText())); }); } @Bean public VectorStore vectorStore(EmbeddingClient embeddingClient) { final SearchClient searchClient = new SearchClientBuilder() .endpoint(acsEndpoint) .credential(new AzureKeyCredential(acsApiKey)) .indexName(acsIndexName) .buildClient(); return new AzureCognitiveSearchVectorStore(searchClient, embeddingClient); } public static class AzureCognitiveSearchVectorStore implements VectorStore { private static final int DEFAULT_TOP_K = 4; private static final Double DEFAULT_SIMILARITY_THRESHOLD = 0.0; private SearchClient searchClient; private final EmbeddingClient embeddingClient; public AzureCognitiveSearchVectorStore(SearchClient searchClient, EmbeddingClient embeddingClient) { this.searchClient = searchClient; this.embeddingClient = embeddingClient; } @Override public void add(List<Document> documents) { final var docs = documents.stream().map(document -> { final var embeddings = embeddingClient.embed(document); return new DocEntry(document.getId(), "", document.getContent(), embeddings); }).toList(); searchClient.uploadDocuments(docs); } @Override public Optional<Boolean> delete(List<String> idList) { final List<DocEntry> docIds = idList.stream().map(id -> DocEntry.builder().id(id).build()) .toList(); var results = searchClient.deleteDocuments(docIds); boolean resSuccess = true; for (IndexingResult result : results.getResults()) if (!result.isSucceeded()) { resSuccess = false; break; } return Optional.of(resSuccess); } @Override public List<Document> similaritySearch(String query) { return similaritySearch(query, DEFAULT_TOP_K); } @Override public List<Document> similaritySearch(String query, int k) { return similaritySearch(query, k, DEFAULT_SIMILARITY_THRESHOLD); } @Override public List<Document> similaritySearch(String query, int k, double threshold) { final var searchQueryVector = new RawVectorQuery() .setVector(toFloatList(embeddingClient.embed(query))) .setKNearestNeighborsCount(k) .setFields("contentVector"); final var searchResults = searchClient.search(null, new SearchOptions().setVectorQueries(searchQueryVector), Context.NONE); return searchResults.stream() .filter(r -> r.getScore() >= threshold) .map(r -> { final DocEntry entry = r.getDocument(DocEntry.class); final Document doc = new Document(entry.getId(), entry.getContent(), Collections.emptyMap()); doc.setEmbedding(entry.getContentVector()); return doc; }) .collect(Collectors.toList()); } private List<Float> toFloatList(List<Double> doubleList) { return doubleList.stream().map(Double::floatValue).toList(); } } @Data @Builder @Jacksonized @AllArgsConstructor @NoArgsConstructor static class DocEntry { private String id; private String hash; private String content; private List<Double> contentVector; } }중요합니다
프로덕션의 경우 Azure Key Vault와 같은 자격 증명을 안전하게 저장하고 액세스하는 방법을 사용합니다. 자격 증명 보안에 대한 자세한 내용은 이 보안 문서를 참조하세요.
프로젝트 루트 폴더로 다시 이동하고 다음 명령을 사용하여 앱을 실행합니다.
./mvnw spring-boot:run
출력
. ____ _ __ _ _
/\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \
( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \
\\/ ___)| |_)| | | | | || (_| | ) ) ) )
' |____| .__|_| |_|_| |_\__, | / / / /
=========|_|==============|___/=/_/_/_/
:: Spring Boot :: (v3.1.5)
2023-11-07T14:40:45.250-06:00 INFO 18557 --- [ main] c.e.a.AiCustomDataApplication : No active profile set, falling back to 1 default profile: "default"
2023-11-07T14:40:46.035-06:00 INFO 18557 --- [ main] c.e.a.AiCustomDataApplication : Started AiCustomDataApplication in 1.095 seconds (process running for 1.397)
Sending custom data prompt to AI service. One moment please...
Prompt created 1 generated response(s).
Generated response from "assistant": The available health plans in the Contoso Electronics plan and benefit packages are the Northwind Health Plus and Northwind Standard plans.
참조 설명서 | 소스 코드 | 패키지(npm) | 샘플
필수 조건
Azure 구독 – 무료로 만드세요.
로컬 개발 환경에서 암호 없는 인증에 사용되는 Azure CLI는 Azure CLI로 로그인하여 필요한 컨텍스트를 만듭니다.
지원되는 모델을 사용하여 지원되는 지역에 배포된 Azure OpenAI 리소스.
적어도 Azure OpenAI 리소스에 대한 Cognitive Services 기여자 역할이 할당되어야 합니다.
자체 데이터가 없으면 GitHub에서 데이터 예를 다운로드합니다.
Microsoft Entra ID 필수 구성 요소
Microsoft Entra ID를 사용하는 권장 키 없는 인증의 경우 다음을 수행해야 합니다.
- Microsoft Entra ID를 사용하여 키 없는 인증에 사용되는 Azure CLI 를 설치합니다.
- 사용자 계정에
Cognitive Services User역할을 할당합니다. Azure Portal의 액세스 제어(IAM)할 수 있습니다.
Azure AI 파운드리 포털을 사용하여 데이터 추가
팁 (조언)
Azure 개발자 CLI를 사용하여 Azure OpenAI On Your Data에 필요한 리소스를 프로그래밍 방식으로 만들 수 있음
Azure AI 파운드리 포털로 이동하고 Azure OpenAI 리소스에 액세스할 수 있는 자격 증명으로 로그인합니다. Azure AI Foundry 리소스가 있는 경우 Azure AI Foundry 프로젝트를 만들 수 있습니다.
왼쪽 창의 플레이그라운드 아래에서 채팅을 선택하고 모델 배포를 선택합니다.
채팅 플레이그라운드에서 데이터 추가를 선택한 다음 데이터 원본 추가를 선택합니다.
표시되는 창의 데이터 원본 선택에서 파일 업로드(미리 보기)를 선택합니다. Azure OpenAI는 데이터에 액세스하고 인덱싱하기 위해 스토리지 리소스와 검색 리소스가 모두 필요합니다.
팁 (조언)
- 자세한 내용은 다음 리소스를 참조하세요.
- 긴 텍스트가 있는 문서 및 데이터 세트의 경우 사용 가능한 데이터 준비 스크립트를 사용하는 것이 좋습니다.
Azure OpenAI가 스토리지 계정에 액세스하려면 CORS(원본 간 리소스 공유)를 설정해야 합니다. Azure Blob Storage 리소스에 대해 CORS가 아직 켜져 있지 않은 경우 CORS 켜기를 선택합니다.
Azure AI 검색 리소스를 선택하고, 연결하면 계정에서 사용량이 발생한다는 데에 확인을 선택합니다. 그런 후 다음을 선택합니다.
파일 업로드 창에서 파일 찾아보기를 선택하고 필수 조건 섹션에서 다운로드한 파일이나 자체 데이터를 선택합니다. 그런 다음 파일 업로드를 선택합니다. 그런 후 다음을 선택합니다.
데이터 관리 창에서 인덱스에 의미 체계 검색 또는 벡터 검색을 사용할지를 선택할 수 있습니다.
중요합니다
- 의미 체계 검색 및 벡터 검색에는 추가 가격이 적용됩니다. 의미 체계 검색 또는 벡터 검색을 사용하도록 설정하려면 기본 이상의 SKU를 선택해야 합니다. 자세한 내용은 가격 책정 계층 차이 및 서비스 제한을 참조하세요.
- 정보 검색 및 모델 응답의 품질을 향상하려면 영어, 프랑스어, 스페인어, 포르투갈어, 이탈리아어, 독일, 중국어(Zh), 일본어, 한국어, 러시아어 및 아랍어와 같은 데이터 원본 언어에 대해 의미 체계 검색을 사용하도록 설정하는 것이 좋습니다.
입력한 세부 정보를 검토하고 저장 및 닫기를 선택하세요. 이제 모델과 채팅할 수 있으며 모델은 데이터 정보를 사용하여 응답을 생성합니다.
리소스 정보 검색
Azure OpenAI 리소스를 사용하여 애플리케이션을 인증하려면 다음 정보를 검색해야 합니다. 이 빠른 시작은 Azure Blob Storage 계정에 데이터를 업로드했으며 Azure AI 검색 인덱스를 만들었다고 가정합니다. Azure AI 파운드리 포털을 사용하여 데이터 추가를 참조하세요.
| 변수 이름 | 가치 |
|---|---|
AZURE_OPENAI_ENDPOINT |
이 값은 Azure Portal에서 Azure OpenAI 리소스를 검사할 때 키 엔드포인트 섹션에서 찾을 수 있습니다. 예제 엔드포인트는 https://my-resoruce.openai.azure.com입니다. |
AZURE_OPENAI_DEPLOYMENT_NAME |
이 값은 모델을 배포할 때 배포에 대해 선택한 사용자 지정 이름에 해당합니다. 이 값은 Azure Portal의 리소스 관리>배포에서 찾을 수 있습니다. |
AZURE_AI_SEARCH_ENDPOINT |
이 값은 Azure Portal에서 Azure AI 검색 리소스를 검사할 때 개요 섹션에서 찾을 수 있습니다. |
AZURE_AI_SEARCH_INDEX |
이 값은 데이터를 저장하기 위해 만든 인덱스의 이름에 해당합니다. 이 값은 Azure Portal에서 Azure AI 검색 리소스를 검사할 때 개요 섹션에서 찾을 수 있습니다. |
설정
새 폴더
use-data-quickstart를 만들고 다음 명령을 사용하여 빠른 시작 폴더로 이동합니다.mkdir use-data-quickstart && cd use-data-quickstart다음 명령을 사용하여
package.json만듭니다.npm init -y다음을 사용하여 JavaScript용 OpenAI 클라이언트 라이브러리를 설치합니다.
npm install openai권장하는 암호 없는 인증의 경우:
npm install @azure/identity
JavaScript 코드 추가
다음 코드를 사용하여
index.js파일을 만듭니다.const { DefaultAzureCredential, getBearerTokenProvider } = require("@azure/identity"); const { AzureOpenAI } = require("openai"); // Set the Azure and AI Search values from environment variables const endpoint = process.env.AZURE_OPENAI_ENDPOINT || "Your endpoint"; const searchEndpoint = process.env.AZURE_AI_SEARCH_ENDPOINT || "Your search endpoint"; const searchIndex = process.env.AZURE_AI_SEARCH_INDEX || "Your search index"; // keyless authentication const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); // Required Azure OpenAI deployment name and API version const deploymentName = process.env.AZURE_OPENAI_DEPLOYMENT_NAME || "gpt-4"; const apiVersion = process.env.OPENAI_API_VERSION || "2024-10-21"; function getClient() { return new AzureOpenAI({ endpoint, azureADTokenProvider, deployment: deploymentName, apiVersion, }); } async function main() { const client = getClient(); const messages = [ { role: "user", content: "What are my available health plans?" }, ]; console.log(`Message: ${messages.map((m) => m.content).join("\n")}`); const events = await client.chat.completions.create({ stream: true, messages: [ { role: "user", content: "What's the most common feedback we received from our customers about the product?", }, ], max_tokens: 128, model: "", data_sources: [ { type: "azure_search", parameters: { endpoint: searchEndpoint, index_name: searchIndex, authentication: { type: "api_key", key: searchKey, }, }, }, ], }); let response = ""; for await (const event of events) { for (const choice of event.choices) { const newText = choice.delta?.content; if (newText) { response += newText; // To see streaming results as they arrive, uncomment line below // console.log(newText); } } } console.log(response); } main().catch((err) => { console.error("The sample encountered an error:", err); });다음 명령을 사용하여 Azure에 로그인합니다.
az loginJavaScript 파일을 실행합니다.
node index.js
출력
Message: What are my available health plans?
The available health plans in the Contoso Electronics plan and benefit packages are the Northwind Health Plus and Northwind Standard plans.
참조 설명서 | 소스 코드 | 패키지(npm) | 샘플
필수 조건
Azure 구독 – 무료로 만드세요.
로컬 개발 환경에서 암호 없는 인증에 사용되는 Azure CLI는 Azure CLI로 로그인하여 필요한 컨텍스트를 만듭니다.
지원되는 모델을 사용하여 지원되는 지역에 배포된 Azure OpenAI 리소스.
적어도 Azure OpenAI 리소스에 대한 Cognitive Services 기여자 역할이 할당되어야 합니다.
자체 데이터가 없으면 GitHub에서 데이터 예를 다운로드합니다.
Microsoft Entra ID 필수 구성 요소
Microsoft Entra ID를 사용하는 권장 키 없는 인증의 경우 다음을 수행해야 합니다.
- Microsoft Entra ID를 사용하여 키 없는 인증에 사용되는 Azure CLI 를 설치합니다.
- 사용자 계정에
Cognitive Services User역할을 할당합니다. Azure Portal의 액세스 제어(IAM)할 수 있습니다.
Azure AI 파운드리 포털을 사용하여 데이터 추가
팁 (조언)
Azure 개발자 CLI를 사용하여 Azure OpenAI On Your Data에 필요한 리소스를 프로그래밍 방식으로 만들 수 있음
Azure AI 파운드리 포털로 이동하고 Azure OpenAI 리소스에 액세스할 수 있는 자격 증명으로 로그인합니다. Azure AI Foundry 리소스가 있는 경우 Azure AI Foundry 프로젝트를 만들 수 있습니다.
왼쪽 창의 플레이그라운드 아래에서 채팅을 선택하고 모델 배포를 선택합니다.
채팅 플레이그라운드에서 데이터 추가를 선택한 다음 데이터 원본 추가를 선택합니다.
표시되는 창의 데이터 원본 선택에서 파일 업로드(미리 보기)를 선택합니다. Azure OpenAI는 데이터에 액세스하고 인덱싱하기 위해 스토리지 리소스와 검색 리소스가 모두 필요합니다.
팁 (조언)
- 자세한 내용은 다음 리소스를 참조하세요.
- 긴 텍스트가 있는 문서 및 데이터 세트의 경우 사용 가능한 데이터 준비 스크립트를 사용하는 것이 좋습니다.
Azure OpenAI가 스토리지 계정에 액세스하려면 CORS(원본 간 리소스 공유)를 설정해야 합니다. Azure Blob Storage 리소스에 대해 CORS가 아직 켜져 있지 않은 경우 CORS 켜기를 선택합니다.
Azure AI 검색 리소스를 선택하고, 연결하면 계정에서 사용량이 발생한다는 데에 확인을 선택합니다. 그런 후 다음을 선택합니다.
파일 업로드 창에서 파일 찾아보기를 선택하고 필수 조건 섹션에서 다운로드한 파일이나 자체 데이터를 선택합니다. 그런 다음 파일 업로드를 선택합니다. 그런 후 다음을 선택합니다.
데이터 관리 창에서 인덱스에 의미 체계 검색 또는 벡터 검색을 사용할지를 선택할 수 있습니다.
중요합니다
- 의미 체계 검색 및 벡터 검색에는 추가 가격이 적용됩니다. 의미 체계 검색 또는 벡터 검색을 사용하도록 설정하려면 기본 이상의 SKU를 선택해야 합니다. 자세한 내용은 가격 책정 계층 차이 및 서비스 제한을 참조하세요.
- 정보 검색 및 모델 응답의 품질을 향상하려면 영어, 프랑스어, 스페인어, 포르투갈어, 이탈리아어, 독일, 중국어(Zh), 일본어, 한국어, 러시아어 및 아랍어와 같은 데이터 원본 언어에 대해 의미 체계 검색을 사용하도록 설정하는 것이 좋습니다.
입력한 세부 정보를 검토하고 저장 및 닫기를 선택하세요. 이제 모델과 채팅할 수 있으며 모델은 데이터 정보를 사용하여 응답을 생성합니다.
리소스 정보 검색
Azure OpenAI 리소스를 사용하여 애플리케이션을 인증하려면 다음 정보를 검색해야 합니다. 이 빠른 시작은 Azure Blob Storage 계정에 데이터를 업로드했으며 Azure AI 검색 인덱스를 만들었다고 가정합니다. Azure AI 파운드리 포털을 사용하여 데이터 추가를 참조하세요.
| 변수 이름 | 가치 |
|---|---|
AZURE_OPENAI_ENDPOINT |
이 값은 Azure Portal에서 Azure OpenAI 리소스를 검사할 때 키 엔드포인트 섹션에서 찾을 수 있습니다. 예제 엔드포인트는 https://my-resoruce.openai.azure.com입니다. |
AZURE_OPENAI_DEPLOYMENT_NAME |
이 값은 모델을 배포할 때 배포에 대해 선택한 사용자 지정 이름에 해당합니다. 이 값은 Azure Portal의 리소스 관리>배포에서 찾을 수 있습니다. |
AZURE_AI_SEARCH_ENDPOINT |
이 값은 Azure Portal에서 Azure AI 검색 리소스를 검사할 때 개요 섹션에서 찾을 수 있습니다. |
AZURE_AI_SEARCH_INDEX |
이 값은 데이터를 저장하기 위해 만든 인덱스의 이름에 해당합니다. 이 값은 Azure Portal에서 Azure AI 검색 리소스를 검사할 때 개요 섹션에서 찾을 수 있습니다. |
설정
새 폴더
use-data-quickstart를 만들고 다음 명령을 사용하여 빠른 시작 폴더로 이동합니다.mkdir use-data-quickstart && cd use-data-quickstart다음 명령을 사용하여
package.json만듭니다.npm init -ypackage.json다음 명령을 사용하여 ECMAScript로 업데이트합니다.npm pkg set type=module다음을 사용하여 JavaScript용 OpenAI 클라이언트 라이브러리를 설치합니다.
npm install openai권장하는 암호 없는 인증의 경우:
npm install @azure/identity
TypeScript 코드 추가
다음 코드를 사용하여
index.ts파일을 만듭니다.import { AzureOpenAI } from "openai"; import { DefaultAzureCredential, getBearerTokenProvider } from "@azure/identity"; import "@azure/openai/types"; // Set the Azure and AI Search values from environment variables const endpoint = process.env.AZURE_OPENAI_ENDPOINT || "Your endpoint"; const searchEndpoint = process.env.AZURE_AI_SEARCH_ENDPOINT || "Your search endpoint"; const searchIndex = process.env.AZURE_AI_SEARCH_INDEX || "Your search index"; // keyless authentication const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); // Required Azure OpenAI deployment name and API version const deploymentName = process.env.AZURE_OPENAI_DEPLOYMENT_NAME || "gpt-4"; const apiVersion = process.env.OPENAI_API_VERSION || "2024-07-01-preview"; function getClient(): AzureOpenAI { return new AzureOpenAI({ endpoint, azureADTokenProvider, deployment: deploymentName, apiVersion, }); } async function main() { const client = getClient(); const messages = [ { role: "user", content: "What are my available health plans?" }, ]; console.log(`Message: ${messages.map((m) => m.content).join("\n")}`); const events = await client.chat.completions.create({ stream: true, messages: [ { role: "user", content: "What's the most common feedback we received from our customers about the product?", }, ], max_tokens: 128, model: "", data_sources: [ { type: "azure_search", parameters: { endpoint: searchEndpoint, index_name: searchIndex, authentication: { type: "api_key", key: searchKey, }, }, }, ], }); let response = ""; for await (const event of events) { for (const choice of event.choices) { const newText = choice.delta?.content; if (newText) { response += newText; // To see streaming results as they arrive, uncomment line below // console.log(newText); } } } console.log(response); } main().catch((err) => { console.error("The sample encountered an error:", err); });tsconfig.jsonTypeScript 코드를 전환하기 위한 파일을 만들고, ECMAScript용으로 다음 코드를 복사하세요.{ "compilerOptions": { "module": "NodeNext", "target": "ES2022", // Supports top-level await "moduleResolution": "NodeNext", "skipLibCheck": true, // Avoid type errors from node_modules "strict": true // Enable strict type-checking options }, "include": ["*.ts"] }TypeScript에서 JavaScript로 변환합니다.
tsc다음 명령을 사용하여 Azure에 로그인합니다.
az login다음 명령을 사용하여 코드를 실행합니다.
node index.js
중요합니다
프로덕션의 경우 Azure Key Vault와 같은 자격 증명을 안전하게 저장하고 액세스하는 방법을 사용합니다. 자격 증명 보안에 대한 자세한 내용은 이 보안 문서를 참조하세요.
출력
Message: What are my available health plans?
The available health plans in the Contoso Electronics plan and benefit packages are the Northwind Health Plus and Northwind Standard plans.
필수 조건
- Azure OpenAI
- Azure Blob Storage
- Azure AI 검색
-
지원되는 모델을 사용하여 지원되는 지역에 배포된 Azure OpenAI 리소스.
- 적어도 Azure OpenAI 리소스에 대한 Cognitive Services 기여자 역할이 할당되어야 합니다.
- 자체 데이터가 없으면 GitHub에서 데이터 예를 다운로드합니다.
이러한 링크는 Python용 OpenAI API를 참조합니다. Azure 특정 OpenAI Python SDK가 없습니다. OpenAI 서비스와 Azure OpenA 간에 전환하는 방법을 알아봅니다.
Azure AI 파운드리 포털을 사용하여 데이터 추가
팁 (조언)
Azure 개발자 CLI를 사용하여 Azure OpenAI On Your Data에 필요한 리소스를 프로그래밍 방식으로 만들 수 있음
Azure AI 파운드리 포털로 이동하고 Azure OpenAI 리소스에 액세스할 수 있는 자격 증명으로 로그인합니다. Azure AI Foundry 리소스가 있는 경우 Azure AI Foundry 프로젝트를 만들 수 있습니다.
왼쪽 창의 플레이그라운드 아래에서 채팅을 선택하고 모델 배포를 선택합니다.
채팅 플레이그라운드에서 데이터 추가를 선택한 다음 데이터 원본 추가를 선택합니다.
표시되는 창의 데이터 원본 선택에서 파일 업로드(미리 보기)를 선택합니다. Azure OpenAI는 데이터에 액세스하고 인덱싱하기 위해 스토리지 리소스와 검색 리소스가 모두 필요합니다.
팁 (조언)
- 자세한 내용은 다음 리소스를 참조하세요.
- 긴 텍스트가 있는 문서 및 데이터 세트의 경우 사용 가능한 데이터 준비 스크립트를 사용하는 것이 좋습니다.
Azure OpenAI가 스토리지 계정에 액세스하려면 CORS(원본 간 리소스 공유)를 설정해야 합니다. Azure Blob Storage 리소스에 대해 CORS가 아직 켜져 있지 않은 경우 CORS 켜기를 선택합니다.
Azure AI 검색 리소스를 선택하고, 연결하면 계정에서 사용량이 발생한다는 데에 확인을 선택합니다. 그런 후 다음을 선택합니다.
파일 업로드 창에서 파일 찾아보기를 선택하고 필수 조건 섹션에서 다운로드한 파일이나 자체 데이터를 선택합니다. 그런 다음 파일 업로드를 선택합니다. 그런 후 다음을 선택합니다.
데이터 관리 창에서 인덱스에 의미 체계 검색 또는 벡터 검색을 사용할지를 선택할 수 있습니다.
중요합니다
- 의미 체계 검색 및 벡터 검색에는 추가 가격이 적용됩니다. 의미 체계 검색 또는 벡터 검색을 사용하도록 설정하려면 기본 이상의 SKU를 선택해야 합니다. 자세한 내용은 가격 책정 계층 차이 및 서비스 제한을 참조하세요.
- 정보 검색 및 모델 응답의 품질을 향상하려면 영어, 프랑스어, 스페인어, 포르투갈어, 이탈리아어, 독일, 중국어(Zh), 일본어, 한국어, 러시아어 및 아랍어와 같은 데이터 원본 언어에 대해 의미 체계 검색을 사용하도록 설정하는 것이 좋습니다.
입력한 세부 정보를 검토하고 저장 및 닫기를 선택하세요. 이제 모델과 채팅할 수 있으며 모델은 데이터 정보를 사용하여 응답을 생성합니다.
리소스 정보 검색
Azure OpenAI 리소스를 사용하여 애플리케이션을 인증하려면 다음 정보를 검색해야 합니다. 이 빠른 시작은 Azure Blob Storage 계정에 데이터를 업로드했으며 Azure AI 검색 인덱스를 만들었다고 가정합니다. Azure AI 파운드리 포털을 사용하여 데이터 추가를 참조하세요.
| 변수 이름 | 가치 |
|---|---|
AZURE_OPENAI_ENDPOINT |
이 값은 Azure Portal에서 Azure OpenAI 리소스를 검사할 때 키 엔드포인트 섹션에서 찾을 수 있습니다. 예제 엔드포인트는 https://my-resoruce.openai.azure.com입니다. |
AZURE_OPENAI_DEPLOYMENT_NAME |
이 값은 모델을 배포할 때 배포에 대해 선택한 사용자 지정 이름에 해당합니다. 이 값은 Azure Portal의 리소스 관리>배포에서 찾을 수 있습니다. |
AZURE_AI_SEARCH_ENDPOINT |
이 값은 Azure Portal에서 Azure AI 검색 리소스를 검사할 때 개요 섹션에서 찾을 수 있습니다. |
AZURE_AI_SEARCH_INDEX |
이 값은 데이터를 저장하기 위해 만든 인덱스의 이름에 해당합니다. 이 값은 Azure Portal에서 Azure AI 검색 리소스를 검사할 때 개요 섹션에서 찾을 수 있습니다. |
Python 환경 만들기
- 프로젝트에 대해 openai-python이라는 새 폴더와 main.py라는 새 Python 코드 파일을 만듭니다. 해당 디렉터리로 변경합니다.
mkdir openai-python
cd openai-python
- 다음 Python 라이브러리를 설치합니다.
pip install openai
pip install python-dotenv
Python 앱 만들기
- 프로젝트 디렉터리에서 main.py 파일을 열고 다음 코드를 추가합니다.
import os
import openai
import dotenv
dotenv.load_dotenv()
endpoint = os.environ.get("AZURE_OPENAI_ENDPOINT")
api_key = os.environ.get("AZURE_OPENAI_API_KEY")
deployment = os.environ.get("AZURE_OPENAI_DEPLOYMENT_NAME")
client = openai.AzureOpenAI(
azure_endpoint=endpoint,
api_key=api_key,
api_version="2024-10-21",
)
completion = client.chat.completions.create(
model=deployment,
messages=[
{
"role": "user",
"content": "What are my available health plans?",
},
],
extra_body={
"data_sources":[
{
"type": "azure_search",
"parameters": {
"endpoint": os.environ["AZURE_AI_SEARCH_ENDPOINT"],
"index_name": os.environ["AZURE_AI_SEARCH_INDEX"],
"authentication": {
"type": "api_key",
"key": os.environ["AZURE_AI_SEARCH_API_KEY"],
}
}
}
],
}
)
print(f"{completion.choices[0].message.role}: {completion.choices[0].message.content}")
중요합니다
프로덕션의 경우 Azure Key Vault와 같은 자격 증명을 안전하게 저장하고 액세스하는 방법을 사용합니다. 자격 증명 보안에 대한 자세한 내용은 이 보안 문서를 참조하세요.
- 다음 명령을 실행합니다.
python main.py
애플리케이션은 많은 시나리오에서 사용하기에 적합한 JSON 형식으로 응답을 인쇄합니다. 여기에는 쿼리에 대한 답변과 업로드된 파일의 인용이 모두 포함됩니다.
필수 조건
- Azure OpenAI
- Azure Blob Storage
- Azure AI 검색
-
지원되는 모델을 사용하여 지원되는 지역에 배포된 Azure OpenAI 리소스.
- 적어도 Azure OpenAI 리소스에 대한 Cognitive Services 기여자 역할이 할당되어야 합니다.
- 자체 데이터가 없으면 GitHub에서 데이터 예를 다운로드합니다.
Azure AI 파운드리 포털을 사용하여 데이터 추가
팁 (조언)
Azure 개발자 CLI를 사용하여 Azure OpenAI On Your Data에 필요한 리소스를 프로그래밍 방식으로 만들 수 있음
Azure AI 파운드리 포털로 이동하고 Azure OpenAI 리소스에 액세스할 수 있는 자격 증명으로 로그인합니다. Azure AI Foundry 리소스가 있는 경우 Azure AI Foundry 프로젝트를 만들 수 있습니다.
왼쪽 창의 플레이그라운드 아래에서 채팅을 선택하고 모델 배포를 선택합니다.
채팅 플레이그라운드에서 데이터 추가를 선택한 다음 데이터 원본 추가를 선택합니다.
표시되는 창의 데이터 원본 선택에서 파일 업로드(미리 보기)를 선택합니다. Azure OpenAI는 데이터에 액세스하고 인덱싱하기 위해 스토리지 리소스와 검색 리소스가 모두 필요합니다.
팁 (조언)
- 자세한 내용은 다음 리소스를 참조하세요.
- 긴 텍스트가 있는 문서 및 데이터 세트의 경우 사용 가능한 데이터 준비 스크립트를 사용하는 것이 좋습니다.
Azure OpenAI가 스토리지 계정에 액세스하려면 CORS(원본 간 리소스 공유)를 설정해야 합니다. Azure Blob Storage 리소스에 대해 CORS가 아직 켜져 있지 않은 경우 CORS 켜기를 선택합니다.
Azure AI 검색 리소스를 선택하고, 연결하면 계정에서 사용량이 발생한다는 데에 확인을 선택합니다. 그런 후 다음을 선택합니다.
파일 업로드 창에서 파일 찾아보기를 선택하고 필수 조건 섹션에서 다운로드한 파일이나 자체 데이터를 선택합니다. 그런 다음 파일 업로드를 선택합니다. 그런 후 다음을 선택합니다.
데이터 관리 창에서 인덱스에 의미 체계 검색 또는 벡터 검색을 사용할지를 선택할 수 있습니다.
중요합니다
- 의미 체계 검색 및 벡터 검색에는 추가 가격이 적용됩니다. 의미 체계 검색 또는 벡터 검색을 사용하도록 설정하려면 기본 이상의 SKU를 선택해야 합니다. 자세한 내용은 가격 책정 계층 차이 및 서비스 제한을 참조하세요.
- 정보 검색 및 모델 응답의 품질을 향상하려면 영어, 프랑스어, 스페인어, 포르투갈어, 이탈리아어, 독일, 중국어(Zh), 일본어, 한국어, 러시아어 및 아랍어와 같은 데이터 원본 언어에 대해 의미 체계 검색을 사용하도록 설정하는 것이 좋습니다.
입력한 세부 정보를 검토하고 저장 및 닫기를 선택하세요. 이제 모델과 채팅할 수 있으며 모델은 데이터 정보를 사용하여 응답을 생성합니다.
리소스 정보 검색
Azure OpenAI 리소스를 사용하여 애플리케이션을 인증하려면 다음 정보를 검색해야 합니다. 이 빠른 시작은 Azure Blob Storage 계정에 데이터를 업로드했으며 Azure AI 검색 인덱스를 만들었다고 가정합니다. Azure AI 파운드리 포털을 사용하여 데이터 추가를 참조하세요.
| 변수 이름 | 가치 |
|---|---|
AZURE_OPENAI_ENDPOINT |
이 값은 Azure Portal에서 Azure OpenAI 리소스를 검사할 때 키 엔드포인트 섹션에서 찾을 수 있습니다. 예제 엔드포인트는 https://my-resoruce.openai.azure.com입니다. |
AZURE_OPENAI_DEPLOYMENT_NAME |
이 값은 모델을 배포할 때 배포에 대해 선택한 사용자 지정 이름에 해당합니다. 이 값은 Azure Portal의 리소스 관리>배포에서 찾을 수 있습니다. |
AZURE_AI_SEARCH_ENDPOINT |
이 값은 Azure Portal에서 Azure AI 검색 리소스를 검사할 때 개요 섹션에서 찾을 수 있습니다. |
AZURE_AI_SEARCH_INDEX |
이 값은 데이터를 저장하기 위해 만든 인덱스의 이름에 해당합니다. 이 값은 Azure Portal에서 Azure AI 검색 리소스를 검사할 때 개요 섹션에서 찾을 수 있습니다. |
PowerShell 명령의 예
Azure OpenAI 채팅 모델은 대화 형식의 입력으로 작동하도록 최적화되어 있습니다.
messages 변수는 시스템, 사용자, 도구 및 도우미가 기술하는 대화에서 서로 다른 역할을 가진 사전 배열을 전달합니다.
dataSources 변수는 Azure Cognitive Search 인덱스에 연결하고 Azure OpenAI 모델이 데이터를 사용하여 응답할 수 있도록 합니다.
모델에서 응답을 트리거하려면 도우미가 응답할 차례임을 나타내는 사용자 메시지로 끝나야 합니다.
팁 (조언)
temperature 또는 top_p 같이 모델의 응답을 변경하는 데 사용할 수 있는 몇 가지 매개 변수가 있습니다. 자세한 내용은 참조 설명서를 참조하세요.
# Azure OpenAI metadata variables
$openai = @{
api_key = $Env:AZURE_OPENAI_API_KEY
api_base = $Env:AZURE_OPENAI_ENDPOINT # your endpoint should look like the following https://YOUR_RESOURCE_NAME.openai.azure.com/
api_version = '2023-07-01-preview' # this may change in the future
name = 'YOUR-DEPLOYMENT-NAME-HERE' #This will correspond to the custom name you chose for your deployment when you deployed a model.
}
$acs = @{
search_endpoint = 'YOUR ACS ENDPOINT' # your endpoint should look like the following https://YOUR_RESOURCE_NAME.search.windows.net/
search_key = 'YOUR-ACS-KEY-HERE' # or use the Get-Secret cmdlet to retrieve the value
search_index = 'YOUR-INDEX-NAME-HERE' # the name of your ACS index
}
# Completion text
$body = @{
dataSources = @(
@{
type = 'AzureCognitiveSearch'
parameters = @{
endpoint = $acs.search_endpoint
key = $acs.search_key
indexName = $acs.search_index
}
}
)
messages = @(
@{
role = 'user'
content = 'What are my available health plans?'
}
)
} | convertto-json -depth 5
# Header for authentication
$headers = [ordered]@{
'api-key' = $openai.api_key
}
# Send a completion call to generate an answer
$url = "$($openai.api_base)/openai/deployments/$($openai.name)/extensions/chat/completions?api-version=$($openai.api_version)"
$response = Invoke-RestMethod -Uri $url -Headers $headers -Body $body -Method Post -ContentType 'application/json'
return $response.choices.messages[1].content
예제 출력
The available health plans in the Contoso Electronics plan and benefit packages are the Northwind Health Plus and Northwind Standard plans.
중요합니다
프로덕션의 경우 Azure Key Vault를 사용한 PowerShell 비밀 관리와 같은 자격 증명을 안전하게 저장하고 액세스하는 방법을 사용합니다. 자격 증명 보안에 대한 자세한 내용은 이 보안 문서를 참조하세요.
웹앱을 사용하여 모델과 채팅
데이터를 사용하는 Azure OpenAI 모델과 채팅을 시작하려면 GitHub에서 제공하는 Azure AI 파운드리 포털 또는 예제 코드를 사용하여 웹앱을 배포할 수 있습니다. 이 앱은 Azure App Service를 사용하여 배포하고 쿼리를 보내기 위한 사용자 인터페이스를 제공합니다. 이 앱은 데이터를 사용하는 Azure OpenAI 모델 또는 데이터를 사용하지 않는 모델과 사용할 수 있습니다. 요구 사항, 설정 및 배포에 대한 지침은 리포지토리의 추가 정보 파일을 참조하세요. 필요에 따라 소스 코드를 변경하여 웹앱의 프런트 엔드 및 백 엔드 논리를 사용자 지정할 수 있습니다.
필수 조건
- Azure OpenAI
- Azure Blob Storage
- Azure AI 검색
-
지원되는 모델을 사용하여 지원되는 지역에 배포된 Azure OpenAI 리소스.
- 적어도 Azure OpenAI 리소스에 대한 Cognitive Services 기여자 역할이 할당되어야 합니다.
- 자체 데이터가 없으면 GitHub에서 데이터 예를 다운로드합니다.
Azure AI 파운드리 포털을 사용하여 데이터 추가
팁 (조언)
Azure 개발자 CLI를 사용하여 Azure OpenAI On Your Data에 필요한 리소스를 프로그래밍 방식으로 만들 수 있음
Azure AI 파운드리 포털로 이동하고 Azure OpenAI 리소스에 액세스할 수 있는 자격 증명으로 로그인합니다. Azure AI Foundry 리소스가 있는 경우 Azure AI Foundry 프로젝트를 만들 수 있습니다.
왼쪽 창의 플레이그라운드 아래에서 채팅을 선택하고 모델 배포를 선택합니다.
채팅 플레이그라운드에서 데이터 추가를 선택한 다음 데이터 원본 추가를 선택합니다.
표시되는 창의 데이터 원본 선택에서 파일 업로드(미리 보기)를 선택합니다. Azure OpenAI는 데이터에 액세스하고 인덱싱하기 위해 스토리지 리소스와 검색 리소스가 모두 필요합니다.
팁 (조언)
- 자세한 내용은 다음 리소스를 참조하세요.
- 긴 텍스트가 있는 문서 및 데이터 세트의 경우 사용 가능한 데이터 준비 스크립트를 사용하는 것이 좋습니다.
Azure OpenAI가 스토리지 계정에 액세스하려면 CORS(원본 간 리소스 공유)를 설정해야 합니다. Azure Blob Storage 리소스에 대해 CORS가 아직 켜져 있지 않은 경우 CORS 켜기를 선택합니다.
Azure AI 검색 리소스를 선택하고, 연결하면 계정에서 사용량이 발생한다는 데에 확인을 선택합니다. 그런 후 다음을 선택합니다.
파일 업로드 창에서 파일 찾아보기를 선택하고 필수 조건 섹션에서 다운로드한 파일이나 자체 데이터를 선택합니다. 그런 다음 파일 업로드를 선택합니다. 그런 후 다음을 선택합니다.
데이터 관리 창에서 인덱스에 의미 체계 검색 또는 벡터 검색을 사용할지를 선택할 수 있습니다.
중요합니다
- 의미 체계 검색 및 벡터 검색에는 추가 가격이 적용됩니다. 의미 체계 검색 또는 벡터 검색을 사용하도록 설정하려면 기본 이상의 SKU를 선택해야 합니다. 자세한 내용은 가격 책정 계층 차이 및 서비스 제한을 참조하세요.
- 정보 검색 및 모델 응답의 품질을 향상하려면 영어, 프랑스어, 스페인어, 포르투갈어, 이탈리아어, 독일, 중국어(Zh), 일본어, 한국어, 러시아어 및 아랍어와 같은 데이터 원본 언어에 대해 의미 체계 검색을 사용하도록 설정하는 것이 좋습니다.
입력한 세부 정보를 검토하고 저장 및 닫기를 선택하세요. 이제 모델과 채팅할 수 있으며 모델은 데이터 정보를 사용하여 응답을 생성합니다.
Microsoft Entra ID 필수 구성 요소
Microsoft Entra ID를 사용하는 권장 키 없는 인증의 경우 다음을 수행해야 합니다.
- Microsoft Entra ID를 사용하여 키 없는 인증에 사용되는 Azure CLI 를 설치합니다.
- 사용자 계정에
Cognitive Services User역할을 할당합니다. Azure Portal의 액세스 제어(IAM)할 수 있습니다.
설정
새 폴더
dall-e-quickstart를 만들고 다음 명령을 사용하여 빠른 시작 폴더로 이동합니다.mkdir dall-e-quickstart && cd dall-e-quickstartMicrosoft Entra ID로 권장되는 키 없는 인증의 경우 다음 명령을 사용하여 Azure에 로그인합니다.
az login
리소스 정보 검색
Azure OpenAI 리소스를 사용하여 애플리케이션을 인증하려면 다음 정보를 검색해야 합니다. 이 빠른 시작은 Azure Blob Storage 계정에 데이터를 업로드했으며 Azure AI 검색 인덱스를 만들었다고 가정합니다. Azure AI 파운드리 포털을 사용하여 데이터 추가를 참조하세요.
| 변수 이름 | 가치 |
|---|---|
AZURE_OPENAI_ENDPOINT |
이 값은 Azure Portal에서 Azure OpenAI 리소스를 검사할 때 키 엔드포인트 섹션에서 찾을 수 있습니다. 예제 엔드포인트는 https://my-resoruce.openai.azure.com입니다. |
AZURE_OPENAI_DEPLOYMENT_NAME |
이 값은 모델을 배포할 때 배포에 대해 선택한 사용자 지정 이름에 해당합니다. 이 값은 Azure Portal의 리소스 관리>배포에서 찾을 수 있습니다. |
AZURE_AI_SEARCH_ENDPOINT |
이 값은 Azure Portal에서 Azure AI 검색 리소스를 검사할 때 개요 섹션에서 찾을 수 있습니다. |
AZURE_AI_SEARCH_INDEX |
이 값은 데이터를 저장하기 위해 만든 인덱스의 이름에 해당합니다. 이 값은 Azure Portal에서 Azure AI 검색 리소스를 검사할 때 개요 섹션에서 찾을 수 있습니다. |
빠른 시작 실행
이 빠른 시작의 샘플 코드는 권장되는 키 없는 인증에 Microsoft Entra ID를 사용합니다. API 키를 사용하려는 경우 구현을 NewDefaultAzureCredential .로 NewKeyCredential바꿀 수 있습니다.
azureOpenAIEndpoint := os.Getenv("AZURE_OPENAI_ENDPOINT")
credential, err := azidentity.NewDefaultAzureCredential(nil)
client, err := azopenai.NewClient(azureOpenAIEndpoint, credential, nil)
샘플을 실행하려면 다음을 수행합니다.
quickstart.go라는 새 파일을 만듭니다. 다음 코드를 quickstart.go 파일에 복사합니다.
package main import ( "context" "fmt" "log" "os" "github.com/Azure/azure-sdk-for-go/sdk/ai/azopenai" "github.com/Azure/azure-sdk-for-go/sdk/azcore" "github.com/Azure/azure-sdk-for-go/sdk/azcore/to" ) func main() { azureOpenAIEndpoint := os.Getenv("AZURE_OPENAI_ENDPOINT") credential, err := azidentity.NewDefaultAzureCredential(nil) client, err := azopenai.NewClient(azureOpenAIEndpoint, credential, nil) modelDeploymentID := os.Getenv("AZURE_OPENAI_DEPLOYMENT_NAME") // Azure AI Search configuration searchIndex := os.Getenv("AZURE_AI_SEARCH_INDEX") searchEndpoint := os.Getenv("AZURE_AI_SEARCH_ENDPOINT") searchAPIKey := os.Getenv("AZURE_AI_SEARCH_API_KEY") if modelDeploymentID == "" || azureOpenAIEndpoint == "" || searchIndex == "" || searchEndpoint == "" || searchAPIKey == "" { fmt.Fprintf(os.Stderr, "Skipping example, environment variables missing\n") return } client, err := azopenai.NewClientWithKeyCredential(azureOpenAIEndpoint, credential, nil) if err != nil { // Implement application specific error handling logic. log.Printf("ERROR: %s", err) return } resp, err := client.GetChatCompletions(context.TODO(), azopenai.ChatCompletionsOptions{ Messages: []azopenai.ChatRequestMessageClassification{ &azopenai.ChatRequestUserMessage{Content: azopenai.NewChatRequestUserMessageContent("What are my available health plans?")}, }, MaxTokens: to.Ptr[int32](512), AzureExtensionsOptions: []azopenai.AzureChatExtensionConfigurationClassification{ &azopenai.AzureSearchChatExtensionConfiguration{ // This allows Azure OpenAI to use an Azure AI Search index. // Answers are based on the model's pretrained knowledge // and the latest information available in the designated data source. Parameters: &azopenai.AzureSearchChatExtensionParameters{ Endpoint: &searchEndpoint, IndexName: &searchIndex, Authentication: &azopenai.OnYourDataAPIKeyAuthenticationOptions{ Key: &searchAPIKey, }, }, }, }, DeploymentName: &modelDeploymentID, }, nil) if err != nil { // Implement application specific error handling logic. log.Printf("ERROR: %s", err) return } fmt.Fprintf(os.Stderr, "Extensions Context Role: %s\nExtensions Context (length): %d\n", *resp.Choices[0].Message.Role, len(*resp.Choices[0].Message.Content)) fmt.Fprintf(os.Stderr, "ChatRole: %s\nChat content: %s\n", *resp.Choices[0].Message.Role, *resp.Choices[0].Message.Content, ) }다음 명령을 실행하여 새 Go 모듈을 만듭니다.
go mod init quickstart.go실행
go mod tidy하여 필요한 종속성을 설치합니다.go mod tidy다음 명령을 실행하여 샘플을 실행합니다.
go run quickstart.go
애플리케이션은 쿼리에 대한 답변과 업로드된 파일의 인용을 포함하여 응답을 출력합니다.
필수 조건
- Azure OpenAI
- Azure Blob Storage
- Azure AI 검색
-
지원되는 모델을 사용하여 지원되는 지역에 배포된 Azure OpenAI 리소스.
- 적어도 Azure OpenAI 리소스에 대한 Cognitive Services 기여자 역할이 할당되어야 합니다.
- 자체 데이터가 없으면 GitHub에서 데이터 예를 다운로드합니다.
Azure AI 파운드리 포털을 사용하여 데이터 추가
팁 (조언)
Azure 개발자 CLI를 사용하여 Azure OpenAI On Your Data에 필요한 리소스를 프로그래밍 방식으로 만들 수 있음
Azure AI 파운드리 포털로 이동하고 Azure OpenAI 리소스에 액세스할 수 있는 자격 증명으로 로그인합니다. Azure AI Foundry 리소스가 있는 경우 Azure AI Foundry 프로젝트를 만들 수 있습니다.
왼쪽 창의 플레이그라운드 아래에서 채팅을 선택하고 모델 배포를 선택합니다.
채팅 플레이그라운드에서 데이터 추가를 선택한 다음 데이터 원본 추가를 선택합니다.
표시되는 창의 데이터 원본 선택에서 파일 업로드(미리 보기)를 선택합니다. Azure OpenAI는 데이터에 액세스하고 인덱싱하기 위해 스토리지 리소스와 검색 리소스가 모두 필요합니다.
팁 (조언)
- 자세한 내용은 다음 리소스를 참조하세요.
- 긴 텍스트가 있는 문서 및 데이터 세트의 경우 사용 가능한 데이터 준비 스크립트를 사용하는 것이 좋습니다.
Azure OpenAI가 스토리지 계정에 액세스하려면 CORS(원본 간 리소스 공유)를 설정해야 합니다. Azure Blob Storage 리소스에 대해 CORS가 아직 켜져 있지 않은 경우 CORS 켜기를 선택합니다.
Azure AI 검색 리소스를 선택하고, 연결하면 계정에서 사용량이 발생한다는 데에 확인을 선택합니다. 그런 후 다음을 선택합니다.
파일 업로드 창에서 파일 찾아보기를 선택하고 필수 조건 섹션에서 다운로드한 파일이나 자체 데이터를 선택합니다. 그런 다음 파일 업로드를 선택합니다. 그런 후 다음을 선택합니다.
데이터 관리 창에서 인덱스에 의미 체계 검색 또는 벡터 검색을 사용할지를 선택할 수 있습니다.
중요합니다
- 의미 체계 검색 및 벡터 검색에는 추가 가격이 적용됩니다. 의미 체계 검색 또는 벡터 검색을 사용하도록 설정하려면 기본 이상의 SKU를 선택해야 합니다. 자세한 내용은 가격 책정 계층 차이 및 서비스 제한을 참조하세요.
- 정보 검색 및 모델 응답의 품질을 향상하려면 영어, 프랑스어, 스페인어, 포르투갈어, 이탈리아어, 독일, 중국어(Zh), 일본어, 한국어, 러시아어 및 아랍어와 같은 데이터 원본 언어에 대해 의미 체계 검색을 사용하도록 설정하는 것이 좋습니다.
입력한 세부 정보를 검토하고 저장 및 닫기를 선택하세요. 이제 모델과 채팅할 수 있으며 모델은 데이터 정보를 사용하여 응답을 생성합니다.
리소스 정보 검색
Azure OpenAI 리소스를 사용하여 애플리케이션을 인증하려면 다음 정보를 검색해야 합니다. 이 빠른 시작은 Azure Blob Storage 계정에 데이터를 업로드했으며 Azure AI 검색 인덱스를 만들었다고 가정합니다. Azure AI 파운드리 포털을 사용하여 데이터 추가를 참조하세요.
| 변수 이름 | 가치 |
|---|---|
AZURE_OPENAI_ENDPOINT |
이 값은 Azure Portal에서 Azure OpenAI 리소스를 검사할 때 키 엔드포인트 섹션에서 찾을 수 있습니다. 예제 엔드포인트는 https://my-resoruce.openai.azure.com입니다. |
AZURE_OPENAI_DEPLOYMENT_NAME |
이 값은 모델을 배포할 때 배포에 대해 선택한 사용자 지정 이름에 해당합니다. 이 값은 Azure Portal의 리소스 관리>배포에서 찾을 수 있습니다. |
AZURE_AI_SEARCH_ENDPOINT |
이 값은 Azure Portal에서 Azure AI 검색 리소스를 검사할 때 개요 섹션에서 찾을 수 있습니다. |
AZURE_AI_SEARCH_INDEX |
이 값은 데이터를 저장하기 위해 만든 인덱스의 이름에 해당합니다. 이 값은 Azure Portal에서 Azure AI 검색 리소스를 검사할 때 개요 섹션에서 찾을 수 있습니다. |
cURL 명령 예제
Azure OpenAI 채팅 모델은 대화 형식의 입력으로 작동하도록 최적화되어 있습니다.
messages 변수는 시스템, 사용자, 도구 및 도우미가 기술하는 대화에서 서로 다른 역할을 가진 사전 배열을 전달합니다.
dataSources 변수는 Azure AI 검색 인덱스에 연결하고 Azure OpenAI 모델이 데이터를 사용하여 응답할 수 있도록 합니다.
모델에서 응답을 트리거하려면 도우미가 응답할 차례임을 나타내는 사용자 메시지로 끝나야 합니다.
팁 (조언)
temperature 또는 top_p 같이 모델의 응답을 변경하는 데 사용할 수 있는 몇 가지 매개 변수가 있습니다. 자세한 내용은 참조 설명서를 참조하세요.
curl -i -X POST $AZURE_OPENAI_ENDPOINT/openai/deployments/$AZURE_OPENAI_DEPLOYMENT_NAME/chat/completions?api-version=2024-10-21 \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d \
'
{
"data_sources": [
{
"type": "azure_search",
"parameters": {
"endpoint": "'$AZURE_AI_SEARCH_ENDPOINT'",
"index_name": "'$AZURE_AI_SEARCH_INDEX'",
"authentication": {
"type": "api_key",
"key": "'$AZURE_AI_SEARCH_API_KEY'"
}
}
}
],
"messages": [
{
"role": "user",
"content": "What are my available health plans?"
}
]
}
'
예제 출력
{
"id": "12345678-1a2b-3c4e5f-a123-12345678abcd",
"model": "gpt-4",
"created": 1709835345,
"object": "extensions.chat.completion",
"choices": [
{
"index": 0,
"finish_reason": "stop",
"message": {
"role": "assistant",
"content": "The available health plans in the Contoso Electronics plan and benefit packages are the Northwind Health Plus and Northwind Standard plans. [doc1].",
"end_turn": true,
"context": {
"citations": [
{
"content": "...",
"title": "...",
"url": "https://mysearch.blob.core.windows.net/xyz/001.txt",
"filepath": "001.txt",
"chunk_id": "0"
}
],
"intent": "[\"Available health plans\"]"
}
}
}
],
"usage": {
"prompt_tokens": 3779,
"completion_tokens": 105,
"total_tokens": 3884
},
"system_fingerprint": "fp_65792305e4"
}
웹앱을 사용하여 모델과 채팅
데이터를 사용하는 Azure OpenAI 모델과 채팅을 시작하려면 GitHub에서 제공하는 Azure AI 파운드리 포털 또는 예제 코드를 사용하여 웹앱을 배포할 수 있습니다. 이 앱은 Azure App Service를 사용하여 배포하고 쿼리를 보내기 위한 사용자 인터페이스를 제공합니다. 이 앱은 데이터를 사용하는 Azure OpenAI 모델 또는 데이터를 사용하지 않는 모델과 사용할 수 있습니다. 요구 사항, 설정 및 배포에 대한 지침은 리포지토리의 추가 정보 파일을 참조하세요. 필요에 따라 소스 코드를 변경하여 웹앱의 프런트 엔드 및 백 엔드 논리를 사용자 지정할 수 있습니다.
자원을 정리하세요
Azure OpenAI 또는 Azure AI 검색 리소스를 정리하고 제거하려면 리소스 또는 리소스 그룹을 삭제하면 됩니다. 리소스 그룹을 삭제하면 해당 리소스 그룹에 연결된 다른 모든 리소스가 함께 삭제됩니다.
다음 단계
- Azure AI Foundry 모델의 Azure OpenAI에서 데이터를 사용하는 방법에 대해 자세히 알아보기
- GitHub의 채팅 앱 샘플 코드.