Caching guidance
캐싱은 시스템의 성능 및 확장성을 개선하는 데 목표를 두는 일반적인 기술입니다. 자주 액세스하는 데이터를 애플리케이션 가까이에 있는 빠른 스토리지에 일시적으로 복사하여 데이터를 캐시합니다. 이 빠른 데이터 스토리지가 원래 원본보다 애플리케이션에 가까이 위치하는 경우 캐싱은 데이터를 보다 신속하게 이용하여 클라이언트 애플리케이션에 대한 응답 시간을 훨씬 향상할 수 있습니다.
캐싱은 클라이언트 인스턴스가 동일한 데이터를 반복적으로 읽는 경우에 가장 효과적입니다. 특히 다음 조건이 모두 원래 데이터 저장소에 적용되는 경우 가장 효과적입니다.
- 상대적으로 정적으로 유지됩니다.
- 캐시 속도와 비교하여 느립니다.
- 높은 수준의 경합이 발생하기 쉽습니다.
- 네트워크 대기 시간으로 인해 액세스 속도가 느려질 수 있는 경우 멀리 떨어져 있습니다.
분산 애플리케이션에서 캐싱
분산 애플리케이션은 일반적으로 데이터를 캐싱할 때 다음 전략 중 하나 또는 둘 다를 구현합니다.
- 애플리케이션 또는 서비스의 인스턴스를 실행하는 컴퓨터에서 데이터가 로컬로 유지되는 프라이빗 캐시를 사용합니다.
- 여러 프로세스 및 컴퓨터에서 액세스할 수 있는 공통 소스 역할을 하는 공유 캐시를 사용합니다.
두 경우 모두 캐싱은 클라이언트 쪽 및 서버 쪽에서 수행할 수 있습니다. 클라이언트 쪽 캐싱은 웹 브라우저 또는 데스크톱 애플리케이션과 같은 시스템에 대한 사용자 인터페이스를 제공하는 프로세스에 의해 수행됩니다. 서버 쪽 캐싱은 원격으로 실행되는 비즈니스 서비스를 제공하는 프로세스에 의해 수행됩니다.
Private caching
가장 기본적인 캐시 유형은 메모리 내 저장소입니다. 단일 프로세스의 주소 공간에 보관되고 해당 프로세스에서 실행되는 코드에 의해 직접 액세스됩니다. 이 유형의 캐시는 빠르게 액세스할 수 있습니다. 또한 적당한 양의 정적 데이터를 저장하는 효과적인 수단을 제공할 수도 있습니다. 캐시의 크기는 일반적으로 프로세스를 호스트하는 컴퓨터에서 사용할 수 있는 메모리 양에 의해 제한됩니다.
메모리에서 물리적으로 가능한 것보다 더 많은 정보를 캐시해야 하는 경우 캐시된 데이터를 로컬 파일 시스템에 쓸 수 있습니다. 이 프로세스는 메모리에 저장된 데이터보다 액세스 속도가 느리지만 네트워크를 통해 데이터를 검색하는 것보다 더 빠르고 안정적이어야 합니다.
이 모델을 동시에 실행하는 애플리케이션 인스턴스가 여러 개 있는 경우 각 애플리케이션 인스턴스에는 자체 데이터 복사본을 보유하는 자체 독립 캐시가 있습니다.
캐시를 과거의 특정 시점에 원래 데이터의 스냅샷으로 간주합니다. 이 데이터가 정적이지 않은 경우 다른 애플리케이션 인스턴스가 캐시에 다른 버전의 데이터를 보유할 가능성이 높습니다. 따라서 이러한 인스턴스에서 수행하는 동일한 쿼리는 그림 1과 같이 다른 결과를 반환할 수 있습니다.

그림 1: 애플리케이션의 여러 인스턴스에서 메모리 내 캐시 사용
Shared caching
공유 캐시를 사용하는 경우 메모리 내 캐싱에서 발생할 수 있는 각 캐시에서 데이터가 다를 수 있다는 우려를 완화하는 데 도움이 될 수 있습니다. 공유 캐싱은 다른 애플리케이션 인스턴스가 캐시된 데이터의 동일한 보기를 볼 수 있도록 합니다. 그림 2와 같이 일반적으로 별도의 서비스의 일부로 호스트되는 별도의 위치에서 캐시를 찾습니다.

그림 2: 공유 캐시 사용
공유 캐싱 접근 방식의 중요한 이점은 이 방법이 제공하는 확장성입니다. 많은 공유 캐시 서비스는 서버 클러스터를 사용하여 구현되고 소프트웨어를 사용하여 클러스터 전체에 데이터를 투명하게 배포합니다. 애플리케이션 인스턴스는 단순히 캐시 서비스에 요청을 보냅니다. 기본 인프라는 클러스터에서 캐시된 데이터의 위치를 결정합니다. 서버를 더 추가하여 캐시 크기를 쉽게 조정할 수 있습니다.
공유 캐싱 방법의 두 가지 주요 단점은 다음과 같습니다.
- 캐시는 더 이상 각 애플리케이션 인스턴스에 로컬로 유지되지 않으므로 액세스 속도가 느립니다.
- 별도의 캐시 서비스를 구현해야 하는 요구 사항은 솔루션에 복잡성을 더할 수 있습니다.
캐싱 사용에 대한 고려 사항
다음 섹션에서는 캐시 디자인 및 사용에 대한 고려 사항을 자세히 설명합니다.
데이터를 캐시할 시기 결정
캐싱은 성능, 확장성 및 가용성을 크게 향상시킬 수 있습니다. 데이터가 많을수록 이 데이터에 액세스해야 하는 사용자 수가 많을수록 캐싱의 이점이 커집니다. 캐싱은 원래 데이터 저장소에서 대량의 동시 요청을 처리하는 것과 관련된 대기 시간 및 경합을 줄입니다.
예를 들어 데이터베이스는 제한된 수의 동시 연결을 지원할 수 있습니다. 그러나 기본 데이터베이스가 아닌 공유 캐시에서 데이터를 검색하면 사용 가능한 연결 수가 현재 소진된 경우에도 클라이언트 애플리케이션에서 이 데이터에 액세스할 수 있습니다. 또한 데이터베이스를 사용할 수 없게 되면 클라이언트 애플리케이션은 캐시에 저장된 데이터를 사용하여 계속할 수 있습니다.
자주 읽지만 자주 수정되지 않는 데이터(예: 쓰기 작업보다 읽기 작업의 비율이 높은 데이터)를 캐싱하는 것이 좋습니다. 그러나 중요한 정보의 신뢰할 수 있는 저장소로 캐시를 사용하지 않는 것이 좋습니다. 대신 애플리케이션에서 잃을 수 없는 모든 변경 내용이 항상 영구 데이터 저장소에 저장되도록 합니다. 캐시를 사용할 수 없는 경우 애플리케이션은 데이터 저장소를 사용하여 계속 작동할 수 있으며 중요한 정보는 손실되지 않습니다.
데이터를 효과적으로 캐시하는 방법 결정
캐시를 효과적으로 사용하는 열쇠는 캐시에 가장 적합한 데이터를 결정하고 적절한 시간에 캐시하는 것입니다. 애플리케이션에서 데이터를 처음 검색할 때 요청 시 캐시에 데이터를 추가할 수 있습니다. 애플리케이션은 데이터 저장소에서 한 번만 데이터를 가져와야 하며, 캐시를 사용하여 후속 액세스를 충족할 수 있습니다.
또는 일반적으로 애플리케이션이 시작될 때(시드라고 하는 접근 방식) 캐시를 미리 부분적으로 또는 완전히 데이터로 채울 수 있습니다. 그러나 이 방법은 애플리케이션이 실행되기 시작할 때 원래 데이터 저장소에 갑자기 높은 부하를 부과할 수 있으므로 큰 캐시에 대한 시드를 구현하는 것이 바람직하지 않을 수 있습니다.
종종 사용 패턴을 분석하면 캐시를 완전히 또는 부분적으로 미리 채울지 여부를 결정하고 캐시할 데이터를 선택하는 데 도움이 될 수 있습니다. 예를 들어 정기적으로(아마도 매일) 애플리케이션을 사용하는 고객을 위해 정적 사용자 프로필 데이터를 사용하여 캐시를 시드할 수 있지만, 애플리케이션을 일주일에 한 번만 사용하는 고객은 시드할 수 없습니다.
캐싱은 일반적으로 변경할 수 없거나 자주 변경되지 않는 데이터에서 잘 작동합니다. 전자 상거래 애플리케이션의 제품 및 가격 정보와 같은 참조 정보 또는 생성 비용이 많이 드는 공유 정적 리소스를 예로 들 수 있습니다. 리소스에 대한 수요를 최소화하고 성능을 향상시키기 위해 애플리케이션 시작 시 이 데이터의 일부 또는 전체를 캐시에 로드할 수 있습니다. 캐시의 참조 데이터를 주기적으로 업데이트하여 up-to-date인지 확인하는 백그라운드 프로세스가 있을 수도 있습니다. 또는 참조 데이터가 변경되면 백그라운드 프로세스가 캐시를 새로 고칠 수 있습니다.
캐싱은 동적 데이터에 덜 유용하지만 이 고려 사항에는 몇 가지 예외가 있습니다(자세한 내용은 이 문서의 뒷부분에 나오는 매우 동적 데이터 캐시 섹션 참조). 원래 데이터가 정기적으로 변경되면 캐시된 정보가 빠르게 부실해지거나 캐시를 원래 데이터 저장소와 동기화하는 오버헤드로 인해 캐싱의 효과가 줄어듭니다.
캐시는 엔터티에 대한 전체 데이터를 포함할 필요가 없습니다. 예를 들어 데이터 항목이 이름, 주소 및 계좌 잔액이 있는 은행 고객과 같은 다중값 개체를 나타내는 경우 이러한 요소 중 일부는 이름 및 주소와 같은 정적 상태로 유지될 수 있습니다. 계정 잔액과 같은 다른 요소는 더 동적일 수 있습니다. 이러한 상황에서는 데이터의 정적 부분을 캐시하고 필요한 경우 나머지 정보만 검색(또는 계산)하는 것이 유용할 수 있습니다.
성능 테스트 및 사용량 분석을 수행하여 캐시의 미리 채우거나 주문형 로드 또는 둘의 조합이 적절한지 확인하는 것이 좋습니다. 결정은 데이터의 변동성 및 사용 패턴에 따라 결정되어야 합니다. 캐시 사용률 및 성능 분석은 부하가 많은 애플리케이션에서 중요하며 확장성이 뛰어나야 합니다. 예를 들어 확장성이 뛰어난 시나리오에서는 캐시를 시드하여 사용량이 많은 시간에 데이터 저장소의 부하를 줄일 수 있습니다.
캐싱을 사용하여 애플리케이션이 실행되는 동안 계산이 반복되지 않도록 할 수도 있습니다. 작업이 데이터를 변환하거나 복잡한 계산을 수행하는 경우 작업 결과를 캐시에 저장할 수 있습니다. 나중에 동일한 계산이 필요한 경우 애플리케이션은 단순히 캐시에서 결과를 검색할 수 있습니다.
애플리케이션은 캐시에 저장된 데이터를 수정할 수 있습니다. 그러나 캐시는 언제든지 사라질 수 있는 일시적인 데이터 저장소로 생각하는 것이 좋습니다. 캐시에만 중요한 데이터를 저장하지 마세요. 원본 데이터 저장소의 정보도 유지 관리해야 합니다. 즉, 캐시를 사용할 수 없게 되면 데이터 손실 가능성을 최소화할 수 있습니다.
매우 동적 데이터 캐시
빠르게 변화하는 정보를 영구 데이터 저장소에 저장하면 시스템에 오버헤드가 발생할 수 있습니다. 예를 들어 상태 또는 다른 측정값을 지속적으로 보고하는 디바이스를 고려해 보세요. 애플리케이션이 캐시된 정보가 거의 항상 오래되었다는 이유로 이 데이터를 캐시하지 않도록 선택하는 경우 데이터 저장소에서 이 정보를 저장하고 검색할 때도 동일한 고려 사항이 적용됩니다. 이 데이터를 저장하고 가져오는 데 걸리는 시간이 변경되었을 수 있습니다.
이와 같은 상황에서는 동적 정보를 영구 데이터 저장소 대신 캐시에 직접 저장하는 이점을 고려합니다. 데이터가 중요하지 않고 감사가 필요하지 않은 경우 가끔 변경 내용이 손실되는지는 중요하지 않습니다.
캐시에서 데이터 만료 관리
대부분의 경우 캐시에 보관되는 데이터는 원래 데이터 저장소에 보관된 데이터의 복사본입니다. 원래 데이터 저장소의 데이터는 캐시된 후 변경되어 캐시된 데이터가 부실해질 수 있습니다. 많은 캐싱 시스템을 사용하면 데이터를 만료하도록 캐시를 구성하고 데이터가 만료될 수 있는 기간을 줄일 수 있습니다.
캐시된 데이터가 만료되면 캐시에서 제거되고 애플리케이션은 원래 데이터 저장소에서 데이터를 검색해야 합니다(새로 가져온 정보를 캐시에 다시 넣을 수 있습니다). 캐시를 구성할 때 기본 만료 정책을 설정할 수 있습니다. 많은 캐시 서비스에서는 캐시에 프로그래밍 방식으로 저장할 때 개별 개체의 만료 기간을 규정할 수도 있습니다. 일부 캐시를 사용하면 만료 기간을 절대 값으로 지정하거나 지정된 시간 내에 액세스하지 않을 경우 항목이 캐시에서 제거되도록 하는 슬라이딩 값으로 지정할 수 있습니다. 이 설정은 지정된 개체에 대해서만 캐시 전체 만료 정책을 재정의합니다.
Note
캐시의 만료 기간과 캐시에 포함된 개체를 신중하게 고려합니다. 너무 짧게 만들면 개체가 너무 빨리 만료되고 캐시 사용의 이점을 줄일 수 있습니다. 기간을 너무 길게 만들면 데이터가 부실해질 위험이 있습니다.
데이터가 오랫동안 상주하도록 허용된 경우 캐시가 채워질 수도 있습니다. 이 경우 캐시에 새 항목을 추가하라는 요청이 있으면 제거라고 하는 프로세스에서 일부 항목이 강제로 제거될 수 있습니다. 캐시 서비스는 일반적으로 LRU(최소 사용) 기준으로 데이터를 제거하지만 일반적으로 이 정책을 재정의하고 항목이 제거되지 않도록 할 수 있습니다. 그러나 이 방법을 채택하는 경우 캐시에서 사용할 수 있는 메모리를 초과할 위험이 있습니다. 캐시에 항목을 추가하려고 시도하는 애플리케이션은 예외로 실패합니다.
일부 캐싱 구현은 추가 제거 정책을 제공할 수 있습니다. 몇 가지 유형의 제거 정책이 있습니다. These include:
- 가장 최근에 사용한 정책입니다(데이터가 다시 필요하지 않을 것으로 예상됨).
- 선점 정책(가장 오래된 데이터는 먼저 제거됨).
- 트리거된 이벤트(예: 수정 중인 데이터)를 기반으로 하는 명시적 제거 정책입니다.
클라이언트 쪽 캐시에서 데이터 무효화
클라이언트 쪽 캐시에 저장된 데이터는 일반적으로 클라이언트에 데이터를 제공하는 서비스의 후원을 벗어난 것으로 간주됩니다. 서비스는 클라이언트 쪽 캐시에서 정보를 추가하거나 제거하도록 클라이언트에 직접 강제 적용할 수 없습니다.
즉, 잘못 구성된 캐시를 사용하는 클라이언트가 오래된 정보를 계속 사용할 수 있습니다. 예를 들어 캐시의 만료 정책이 제대로 구현되지 않은 경우 클라이언트는 원래 데이터 원본의 정보가 변경될 때 로컬로 캐시된 오래된 정보를 사용할 수 있습니다.
HTTP 연결을 통해 데이터를 제공하는 웹 애플리케이션을 빌드하는 경우 웹 클라이언트(예: 브라우저 또는 웹 프록시)가 가장 최근 정보를 가져오도록 암시적으로 강제 적용할 수 있습니다. 리소스가 해당 리소스의 URI 변경으로 업데이트되는 경우 이 작업을 수행할 수 있습니다. 웹 클라이언트는 일반적으로 리소스의 URI를 클라이언트 쪽 캐시의 키로 사용하므로 URI가 변경되면 웹 클라이언트는 이전에 캐시된 리소스 버전을 무시하고 대신 새 버전을 가져옵니다.
캐시에서 동시성 관리
캐시는 종종 애플리케이션의 여러 인스턴스에서 공유하도록 설계되었습니다. 각 애플리케이션 인스턴스는 캐시의 데이터를 읽고 수정할 수 있습니다. 따라서 공유 데이터 저장소에서 발생하는 동일한 동시성 문제도 캐시에 적용됩니다. 애플리케이션이 캐시에 저장된 데이터를 수정해야 하는 경우 애플리케이션의 한 인스턴스에서 수행한 업데이트가 다른 인스턴스의 변경 내용을 덮어쓰지 않도록 해야 할 수 있습니다.
데이터의 특성 및 충돌 가능성에 따라 동시성에 대한 두 가지 방법 중 하나를 채택할 수 있습니다.
- Optimistic. 데이터를 업데이트하기 직전에 애플리케이션은 캐시의 데이터가 검색된 이후 변경되었는지 확인합니다. 데이터가 여전히 같으면 변경할 수 있습니다. 그렇지 않으면 애플리케이션이 업데이트할지 여부를 결정해야 합니다. (이 결정을 이끄는 비즈니스 논리는 애플리케이션에 따라 다릅니다.) 이 방법은 업데이트가 드물거나 충돌이 발생할 가능성이 없는 상황에 적합합니다.
- Pessimistic. 데이터를 검색할 때 애플리케이션은 다른 인스턴스가 데이터를 변경하지 못하도록 캐시에 잠깁니다. 이 프로세스는 충돌이 발생할 수 없도록 하지만 동일한 데이터를 처리해야 하는 다른 인스턴스도 차단할 수 있습니다. 비관적 동시성은 솔루션의 확장성에 영향을 줄 수 있으며 단기 작업에만 권장됩니다. 이 방법은 특히 애플리케이션이 캐시의 여러 항목을 업데이트하고 이러한 변경 내용이 일관되게 적용되도록 해야 하는 경우 충돌이 발생할 가능성이 더 큰 상황에 적합할 수 있습니다.
고가용성 및 확장성 구현 및 성능 향상
캐시를 데이터의 기본 리포지토리로 사용하지 마세요. 캐시가 채워진 원래 데이터 저장소의 역할입니다. 원래 데이터 저장소는 데이터의 지속성을 보장합니다.
솔루션에 공유 캐시 서비스의 가용성에 중요한 종속성을 도입하지 않도록 주의하세요. 공유 캐시를 제공하는 서비스를 사용할 수 없는 경우 애플리케이션이 계속 작동할 수 있어야 합니다. 캐시 서비스가 다시 시작될 때까지 기다리는 동안 애플리케이션이 응답하지 않거나 실패하면 안 됩니다.
따라서 캐시 서비스의 가용성을 검색하고 캐시에 액세스할 수 없는 경우 원래 데이터 저장소로 대체하도록 애플리케이션을 준비해야 합니다. The Circuit-Breaker pattern is useful for handling this scenario. The service that provides the cache can be recovered, and once it becomes available, the cache can be repopulated as data is read from the original data store, following a strategy such as the Cache-aside pattern.
그러나 캐시를 일시적으로 사용할 수 없을 때 애플리케이션이 원래 데이터 저장소로 되돌아가는 경우 시스템 확장성에 영향을 줄 수 있습니다. 데이터 저장소가 복구되는 동안 원래 데이터 저장소는 데이터 요청으로 인해 시간 초과 및 연결 실패로 인해 늪에 빠질 수 있습니다.
모든 애플리케이션 인스턴스가 액세스하는 공유 캐시와 함께 애플리케이션의 각 인스턴스에 로컬 프라이빗 캐시를 구현하는 것이 좋습니다. 애플리케이션에서 항목을 검색할 때 먼저 로컬 캐시, 공유 캐시 및 원래 데이터 저장소에서 확인할 수 있습니다. 공유 캐시의 데이터를 사용하거나 공유 캐시를 사용할 수 없는 경우 데이터베이스에서 로컬 캐시를 채울 수 있습니다.
이 방법을 사용하려면 로컬 캐시가 공유 캐시와 관련하여 너무 오래되지 않도록 주의 깊게 구성해야 합니다. 그러나 공유 캐시에 연결할 수 없는 경우 로컬 캐시는 버퍼 역할을 합니다. 그림 3은 이 구조를 보여줍니다.
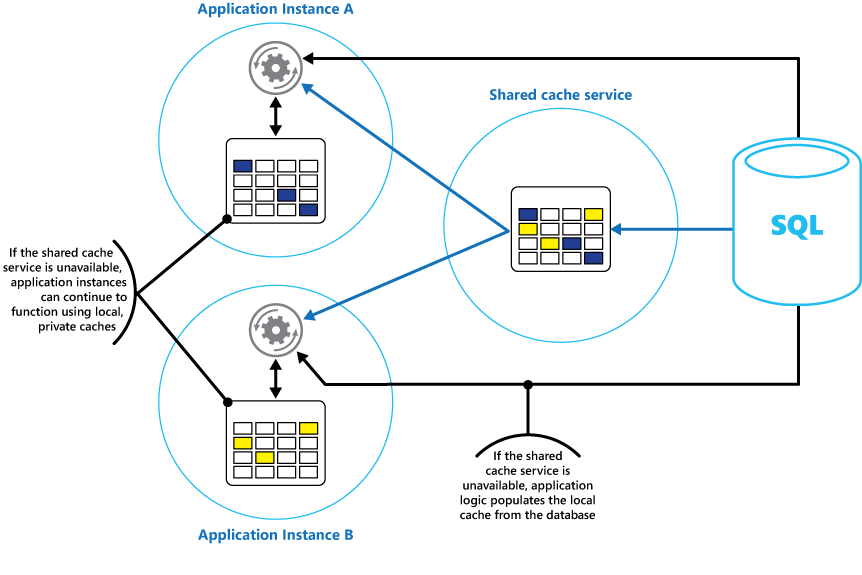
그림 3: 공유 캐시와 함께 로컬 프라이빗 캐시 사용
상대적으로 수명이 긴 데이터를 보유하는 큰 캐시를 지원하기 위해 일부 캐시 서비스는 캐시를 사용할 수 없게 되면 자동 장애 조치를 구현하는 고가용성 옵션을 제공합니다. 이 방법은 일반적으로 주 캐시 서버에 저장된 캐시된 데이터를 보조 캐시 서버로 복제하고 주 서버가 실패하거나 연결이 끊어지면 보조 서버로 전환하는 것을 포함합니다.
여러 대상에 대한 쓰기와 관련된 대기 시간을 줄이기 위해 주 서버의 캐시에 데이터를 쓸 때 보조 서버에 대한 복제가 비동기적으로 발생할 수 있습니다. 이 방법을 사용하면 오류가 발생할 경우 일부 캐시된 정보가 손실될 수 있지만 이 데이터의 비율은 캐시의 전체 크기에 비해 작아야 합니다.
공유 캐시가 큰 경우 경합 가능성을 줄이고 확장성을 개선하기 위해 노드 간에 캐시된 데이터를 분할하는 것이 유용할 수 있습니다. 많은 공유 캐시는 노드를 동적으로 추가(및 제거)하고 파티션 간에 데이터의 균형을 다시 조정하는 기능을 지원합니다. 이 방법에는 노드 컬렉션이 원활한 단일 캐시로 클라이언트 애플리케이션에 표시되는 클러스터링이 포함될 수 있습니다. 그러나 내부적으로 데이터는 부하를 균등하게 분산하는 미리 정의된 배포 전략에 따라 노드 간에 분산됩니다. 가능한 분할 전략에 대한 자세한 내용은 데이터 분할 지침을 참조하세요.
클러스터링을 사용하면 캐시의 가용성도 높아질 수 있습니다. 노드가 실패하면 나머지 캐시에 계속 액세스할 수 있습니다. 클러스터링이 복제 및 장애 조치(failover)와 함께 자주 사용됩니다. 각 노드를 복제할 수 있으며 노드가 실패하면 복제본을 신속하게 온라인 상태로 만들 수 있습니다.
많은 읽기 및 쓰기 작업에는 단일 데이터 값 또는 개체가 포함될 수 있습니다. 그러나 대용량 데이터를 신속하게 저장하거나 검색해야 하는 경우도 있습니다. 예를 들어 캐시 시드에는 캐시에 수백 또는 수천 개의 항목을 쓰는 작업이 포함될 수 있습니다. 애플리케이션은 동일한 요청의 일부로 캐시에서 많은 수의 관련 항목을 검색해야 할 수도 있습니다.
많은 대규모 캐시는 이러한 용도로 일괄 처리 작업을 제공합니다. 이렇게 하면 클라이언트 애플리케이션이 대량의 항목을 단일 요청으로 패키지하고 많은 수의 작은 요청을 수행하는 것과 관련된 오버헤드를 줄일 수 있습니다.
캐싱 및 최종 일관성
캐시 배제 패턴이 작동하려면 캐시를 채우는 애플리케이션 인스턴스가 가장 최근의 일관된 데이터 버전에 액세스할 수 있어야 합니다. 최종 일관성(예: 복제된 데이터 저장소)을 구현하는 시스템에서는 그렇지 않을 수 있습니다.
애플리케이션의 한 인스턴스는 데이터 항목을 수정하고 해당 항목의 캐시된 버전을 무효화할 수 있습니다. 애플리케이션의 다른 인스턴스는 캐시에서 이 항목을 읽으려고 시도할 수 있으므로 캐시 누락이 발생하므로 데이터 저장소에서 데이터를 읽고 캐시에 추가합니다. 그러나 데이터 저장소가 다른 복제본과 완전히 동기화되지 않은 경우 애플리케이션 인스턴스는 캐시를 읽고 이전 값으로 채울 수 있습니다.
데이터 일관성 처리에 대한 자세한 내용은 데이터 일관성 입문을 참조하세요.
캐시된 데이터 보호
사용하는 캐시 서비스에 관계없이 캐시에 저장된 데이터를 무단 액세스로부터 보호하는 방법을 고려합니다. 두 가지 주요 문제가 있습니다.
- 캐시에 있는 데이터의 개인 정보입니다.
- 캐시와 캐시를 사용하는 애플리케이션 간에 흐르는 데이터의 개인 정보입니다.
캐시의 데이터를 보호하기 위해 캐시 서비스는 애플리케이션에서 다음을 지정해야 하는 인증 메커니즘을 구현할 수 있습니다.
- 캐시의 데이터에 액세스할 수 있는 ID입니다.
- 이러한 ID가 수행할 수 있는 작업(읽기 및 쓰기)입니다.
ID에 캐시에 대한 쓰기 또는 읽기 액세스 권한이 부여된 후 데이터 읽기 및 쓰기와 관련된 오버헤드를 줄이기 위해 해당 ID는 캐시의 모든 데이터를 사용할 수 있습니다.
캐시된 데이터의 하위 집합에 대한 액세스를 제한해야 하는 경우 다음 중 하나를 수행할 수 있습니다.
- 다른 캐시 서버를 사용하여 캐시를 파티션으로 분할하고 사용할 수 있어야 하는 파티션의 ID에 대한 액세스 권한만 부여합니다.
- 서로 다른 키를 사용하여 각 하위 집합의 데이터를 암호화하고 각 하위 집합에 대한 액세스 권한이 있어야 하는 ID에만 암호화 키를 제공합니다. 클라이언트 애플리케이션은 캐시의 모든 데이터를 검색할 수 있지만 키가 있는 데이터만 암호 해독할 수 있습니다.
또한 캐시 내/외부로 흐르는 데이터를 보호해야 합니다. 이렇게 하려면 클라이언트 애플리케이션이 캐시에 연결하는 데 사용하는 네트워크 인프라에서 제공하는 보안 기능에 따라 달라집니다. 클라이언트 애플리케이션을 호스트하는 동일한 조직 내의 사이트 서버를 사용하여 캐시를 구현하는 경우 네트워크 자체를 격리하기 위해 추가 단계를 수행하지 않아도 될 수 있습니다. 캐시가 원격으로 위치하고 공용 네트워크(예: 인터넷)를 통해 TCP 또는 HTTP 연결이 필요한 경우 SSL을 구현하는 것이 좋습니다.
Azure에서 캐싱을 구현하기 위한 고려 사항
Azure Cache for Redis는 Azure 데이터 센터에서 서비스로 실행되는 오픈 소스 Redis 캐시의 구현입니다. 애플리케이션이 클라우드 서비스, 웹 사이트 또는 Azure 가상 머신 내에서 구현되는지 여부에 관계없이 Azure 애플리케이션에서 액세스할 수 있는 캐싱 서비스를 제공합니다. 적절한 액세스 키가 있는 클라이언트 애플리케이션에서 캐시를 공유할 수 있습니다.
Azure Cache for Redis는 가용성, 확장성 및 보안을 제공하는 고성능 캐싱 솔루션입니다. 일반적으로 하나 이상의 전용 컴퓨터에 분산된 서비스로 실행됩니다. 빠른 액세스를 보장하기 위해 메모리에 가능한 한 많은 정보를 저장하려고 시도합니다. 이 아키텍처는 느린 I/O 작업을 수행할 필요성을 줄여 짧은 대기 시간과 높은 처리량을 제공하기 위한 것입니다.
Azure Cache for Redis는 클라이언트 애플리케이션에서 사용되는 다양한 API와 호환됩니다. 온-프레미스에서 실행되는 Azure Cache for Redis를 이미 사용하는 기존 애플리케이션이 있는 경우 Azure Cache for Redis는 클라우드에서 캐싱에 대한 빠른 마이그레이션 경로를 제공합니다.
Redis의 기능
Redis는 단순한 캐시 서버 이상입니다. 많은 일반적인 시나리오를 지원하는 광범위한 명령 집합이 포함된 분산 메모리 내 데이터베이스를 제공합니다. 이 내용은 이 문서의 뒷부분에 있는 Redis 캐싱 사용 섹션에서 설명합니다. 이 섹션에서는 Redis에서 제공하는 몇 가지 주요 기능을 요약합니다.
메모리 내 데이터베이스로 Redis
Redis는 읽기 및 쓰기 작업을 모두 지원합니다. Redis에서 쓰기는 로컬 스냅샷 파일 또는 추가 전용 로그 파일에 주기적으로 저장되어 시스템 오류로부터 보호할 수 있습니다. 이 상황은 일시적인 데이터 저장소로 간주되어야 하는 많은 캐시의 경우는 아닙니다.
모든 쓰기는 비동기적이며 클라이언트가 데이터를 읽고 쓰는 것을 차단하지 않습니다. Redis가 실행을 시작하면 스냅샷 또는 로그 파일에서 데이터를 읽고 이를 사용하여 메모리 내 캐시를 생성합니다. For more information, see Redis persistence on the Redis website.
Note
Redis는 치명적인 오류가 발생하는 경우 모든 쓰기가 저장되도록 보장하지는 않지만 최악의 경우 몇 초 분량의 데이터만 손실될 수 있습니다. 캐시는 신뢰할 수 있는 데이터 원본 역할을 하기 위한 것이 아니며, 중요한 데이터가 적절한 데이터 저장소에 성공적으로 저장되도록 캐시를 사용하는 애플리케이션의 책임입니다. For more information, see the Cache-aside pattern.
Redis 데이터 형식
Redis는 값에 해시, 목록 및 집합과 같은 단순 형식 또는 복합 데이터 구조를 포함할 수 있는 키-값 저장소입니다. 이러한 데이터 형식에 대한 원자성 작업 집합을 지원합니다. 키는 영구적이거나 제한된 라이브 시간으로 태그를 지정할 수 있으며, 이때 키와 해당 값은 캐시에서 자동으로 제거됩니다. Redis 키 및 값에 대한 자세한 내용은 Redis 웹 사이트의 Redis 데이터 형식 및 추상화 소개 페이지를 참조하세요.
Redis 복제 및 클러스터링
Redis는 가용성을 보장하고 처리량을 유지하는 데 도움이 되는 기본/하위 복제를 지원합니다. Redis 주 노드에 대한 쓰기 작업은 하나 이상의 하위 노드에 복제됩니다. 읽기 작업은 주 또는 하위 계층에서 처리할 수 있습니다.
네트워크 파티션이 있는 경우 하위 사용자는 계속해서 데이터를 제공한 다음 연결이 다시 설정될 때 주 데이터베이스와 투명하게 다시 동기화할 수 있습니다. For further details, visit the Replication page on the Redis website.
또한 Redis는 클러스터링을 제공하므로 데이터를 서버 간에 분할된 데이터베이스로 투명하게 분할하고 부하를 분산할 수 있습니다. 이 기능은 새 Redis 서버를 추가할 수 있고 캐시 크기가 증가함에 따라 데이터를 다시 분할할 수 있으므로 확장성을 향상시킵니다.
또한 기본/하위 복제를 사용하여 클러스터의 각 서버를 복제할 수 있습니다. 이렇게 하면 클러스터의 각 노드에서 가용성이 보장됩니다. 클러스터링 및 분할에 대한 자세한 내용은 Redis 웹 사이트의 Redis 클러스터 자습서 페이지를 참조하세요.
Redis 메모리 사용
Redis 캐시의 크기는 호스트 컴퓨터에서 사용할 수 있는 리소스에 따라 달라집니다. Redis 서버를 구성할 때 사용할 수 있는 최대 메모리 양을 지정할 수 있습니다. 또한 만료 시간을 가지도록 Redis 캐시에서 키를 구성할 수 있으며, 그 후에는 캐시에서 자동으로 제거됩니다. 이 기능을 사용하면 메모리 내 캐시가 이전 또는 부실 데이터로 채워지도록 방지할 수 있습니다.
메모리가 채워짐에 따라 Redis는 여러 정책에 따라 키와 해당 값을 자동으로 제거할 수 있습니다. 기본값은 LRU(최소 최근에 사용됨)이지만 임의로 키를 제거하거나 제거를 완전히 해제하는 등의 다른 정책을 선택할 수도 있습니다(이 경우 캐시에 항목을 추가하려고 하면 가득 차면 실패함). Redis를 LRU 캐시로 사용하는 페이지에서 자세한 정보를 제공합니다.
Redis 트랜잭션 및 일괄 처리
Redis를 사용하면 클라이언트 애플리케이션이 캐시의 데이터를 원자성 트랜잭션으로 읽고 쓰는 일련의 작업을 제출할 수 있습니다. 트랜잭션의 모든 명령은 순차적으로 실행되도록 보장되며, 다른 동시 클라이언트에서 발급한 명령은 서로 얽혀 있지 않습니다.
그러나 관계형 데이터베이스가 수행하므로 이러한 트랜잭션은 실제 트랜잭션이 아닙니다. 트랜잭션 처리는 두 단계로 구성됩니다. 첫 번째는 명령이 큐에 대기되는 경우이고, 두 번째는 명령이 실행되는 경우입니다. 명령 큐 단계 중에 트랜잭션을 구성하는 명령이 클라이언트에 의해 제출됩니다. 구문 오류 또는 잘못된 매개 변수 수와 같은 일부 오류가 이 시점에서 발생하는 경우 Redis는 전체 트랜잭션 처리를 거부하고 삭제합니다.
실행 단계에서 Redis는 큐에 대기 중인 각 명령을 순서대로 수행합니다. 이 단계에서 명령이 실패하면 Redis는 대기 중인 다음 명령을 계속 실행하고 이미 실행된 명령의 효과를 롤백하지 않습니다. 이 간소화된 형태의 트랜잭션은 성능을 유지하고 경합으로 인한 성능 문제를 방지하는 데 도움이 됩니다.
Redis는 일관성 유지를 지원하기 위해 낙관적 잠금의 형태를 구현합니다. For detailed information about transactions and locking with Redis, visit the Transactions page on the Redis website.
Redis는 요청의 비트랜잭션 일괄 처리도 지원합니다. 클라이언트가 Redis 서버에 명령을 보내는 데 사용하는 Redis 프로토콜을 사용하면 클라이언트가 동일한 요청의 일부로 일련의 작업을 보낼 수 있습니다. 이렇게 하면 네트워크에서 패킷 조각화를 줄일 수 있습니다. 일괄 처리가 처리되면 각 명령이 수행됩니다. 이러한 명령 중 잘못된 형식이 있으면 거부되지만(트랜잭션에서는 발생하지 않음) 나머지 명령이 수행됩니다. 일괄 처리의 명령이 처리되는 순서에 대한 보장도 없습니다.
Redis security
Redis는 데이터에 빠르게 액세스하는 데만 중점을 두며 신뢰할 수 있는 클라이언트에서만 액세스할 수 있는 신뢰할 수 있는 환경 내에서 실행되도록 설계되었습니다. Redis는 암호 인증에 따라 제한된 보안 모델을 지원합니다. (권장하지는 않지만 인증을 완전히 제거할 수 있습니다.)
인증된 모든 클라이언트는 동일한 글로벌 암호를 공유하고 동일한 리소스에 액세스할 수 있습니다. 보다 포괄적인 로그인 보안이 필요한 경우 Redis 서버 앞에 고유한 보안 계층을 구현해야 하며 모든 클라이언트 요청은 이 추가 계층을 통과해야 합니다. Redis는 신뢰할 수 없거나 인증되지 않은 클라이언트에 직접 노출되어서는 안 됩니다.
명령을 사용하지 않도록 설정하거나 이름을 바꾸거나 권한 있는 클라이언트만 새 이름을 제공하여 명령에 대한 액세스를 제한할 수 있습니다.
Redis는 어떤 형태의 데이터 암호화도 직접 지원하지 않으므로 모든 인코딩은 클라이언트 애플리케이션에서 수행해야 합니다. 또한 Redis는 어떤 형태의 전송 보안도 제공하지 않습니다. 네트워크를 통해 흐르는 데이터를 보호해야 하는 경우 SSL 프록시를 구현하는 것이 좋습니다.
For more information, visit the Redis security page on the Redis website.
Note
Azure Cache for Redis는 클라이언트가 연결하는 자체 보안 계층을 제공합니다. 기본 Redis 서버는 공용 네트워크에 노출되지 않습니다.
Azure Redis 캐시
Azure Cache for Redis는 Azure 데이터 센터에서 호스트되는 Redis 서버에 대한 액세스를 제공합니다. 액세스 제어 및 보안을 제공하는 외관 역할을 합니다. Azure Portal을 사용하여 캐시를 프로비전할 수 있습니다.
포털은 미리 정의된 여러 구성을 제공합니다. 이 범위는 SSL 통신(개인 정보 보호용)을 지원하는 전용 서비스로 실행되는 53GB 캐시 및 SLA(서비스 수준 계약)가 99.9% 가용성인 마스터/종속 복제부터 공유 하드웨어에서 실행되는 복제(가용성 보장 없음)가 없는 250MB 캐시까지 다양합니다.
Azure Portal을 사용하여 캐시의 제거 정책을 구성하고 제공된 역할에 사용자를 추가하여 캐시에 대한 액세스를 제어할 수도 있습니다. 멤버가 수행할 수 있는 작업을 정의하는 이러한 역할에는 소유자, 기여자 및 읽기 권한자가 포함됩니다. 예를 들어 소유자 역할의 멤버는 캐시(보안 포함)와 해당 콘텐츠를 완벽하게 제어하고, 기여자 역할의 멤버는 캐시에서 정보를 읽고 쓸 수 있으며, 읽기 권한자 역할의 멤버는 캐시에서만 데이터를 검색할 수 있습니다.
대부분의 관리 작업은 Azure Portal을 통해 수행됩니다. 이러한 이유로 구성을 프로그래밍 방식으로 수정하거나, Redis 서버를 종료하거나, 추가 부하를 구성하거나, 디스크에 데이터를 강제로 저장하는 기능을 포함하여 표준 버전의 Redis에서 사용할 수 있는 많은 관리 명령을 사용할 수 없습니다.
Azure Portal에는 캐시의 성능을 모니터링할 수 있는 편리한 그래픽 디스플레이가 포함되어 있습니다. 예를 들어 수행 중인 연결 수, 수행 중인 요청 수, 읽기 및 쓰기 볼륨, 캐시 적중 횟수 및 캐시 누락 수를 볼 수 있습니다. 이 정보를 사용하여 캐시의 효율성을 확인하고 필요한 경우 다른 구성으로 전환하거나 제거 정책을 변경할 수 있습니다.
또한 하나 이상의 중요한 메트릭이 예상 범위를 벗어나는 경우 관리자에게 전자 메일 메시지를 보내는 경고를 만들 수 있습니다. 예를 들어 캐시 누락 수가 지난 1시간 동안 지정된 값을 초과하는 경우 캐시가 너무 작거나 데이터가 너무 빨리 제거될 수 있으므로 관리자에게 경고할 수 있습니다.
캐시에 대한 CPU, 메모리 및 네트워크 사용량을 모니터링할 수도 있습니다.
Azure Cache for Redis를 만들고 구성하는 방법을 보여 주는 자세한 내용과 예제는 Azure 블로그의 Azure Cache for Redis에 대한 Lap 페이지를 참조하세요.
캐싱 세션 상태 및 HTML 출력
Azure 웹 역할을 사용하여 실행되는 ASP.NET 웹 애플리케이션을 빌드하는 경우 세션 상태 정보 및 HTML 출력을 Azure Cache for Redis에 저장할 수 있습니다. Azure Cache for Redis에 대한 세션 상태 공급자를 사용하면 ASP.NET 웹 애플리케이션의 여러 인스턴스 간에 세션 정보를 공유할 수 있으며 클라이언트-서버 선호도를 사용할 수 없고 메모리 내 세션 데이터를 캐싱하는 것이 적절하지 않은 웹 팜 상황에서 매우 유용합니다.
Azure Cache for Redis와 함께 세션 상태 공급자를 사용하면 다음을 비롯한 몇 가지 이점이 제공됩니다.
- 많은 수의 ASP.NET 웹 애플리케이션 인스턴스와 세션 상태를 공유합니다.
- 향상된 확장성을 제공합니다.
- 여러 판독기 및 단일 기록기에 대해 동일한 세션 상태 데이터에 대한 제어된 동시 액세스를 지원합니다.
- 압축을 사용하여 메모리를 절약하고 네트워크 성능을 향상시킵니다.
자세한 내용은 Azure Cache for Redis에 대한 ASP.NET 세션 상태 공급자를 참조하세요.
Note
Azure 환경 외부에서 실행되는 ASP.NET 애플리케이션에서 Azure Cache for Redis에 대한 세션 상태 공급자를 사용하지 마세요. Azure 외부에서 캐시에 액세스하는 대기 시간은 데이터 캐싱의 성능 이점을 제거할 수 있습니다.
마찬가지로 Azure Cache for Redis의 출력 캐시 공급자를 사용하면 ASP.NET 웹 애플리케이션에서 생성된 HTTP 응답을 저장할 수 있습니다. Azure Cache for Redis와 함께 출력 캐시 공급자를 사용하면 복잡한 HTML 출력을 렌더링하는 애플리케이션의 응답 시간을 향상시킬 수 있습니다. 비슷한 응답을 생성하는 애플리케이션 인스턴스는 이 HTML 출력을 새로 생성하는 대신 캐시의 공유 출력 조각을 사용할 수 있습니다. 자세한 내용은 Azure Cache for Redis에 대한 ASP.NET 출력 캐시 공급자를 참조하세요.
사용자 지정 Redis 캐시 빌드
Azure Cache for Redis는 기본 Redis 서버의 외관 역할을 합니다. Azure Redis 캐시(예: 53GB보다 큰 캐시)에서 다루지 않는 고급 구성이 필요한 경우 Azure Virtual Machines를 사용하여 자체 Redis 서버를 빌드하고 호스트할 수 있습니다.
복제를 구현하려는 경우 기본 및 하위 노드 역할을 하는 여러 VM을 만들어야 할 수 있으므로 이는 잠재적으로 복잡한 프로세스입니다. 또한 클러스터를 만들려면 여러 주 서버와 하위 서버가 필요합니다. 높은 수준의 가용성과 확장성을 제공하는 최소 클러스터된 복제 토폴로지에서는 3개의 기본/하위 서버 쌍으로 구성된 6개 이상의 VM으로 구성됩니다(클러스터에는 3개 이상의 주 노드가 포함되어야 함).
대기 시간을 최소화하려면 각 기본/하위 쌍을 가까이에 배치해야 합니다. 그러나 사용할 가능성이 가장 큰 애플리케이션에 가까운 캐시된 데이터를 찾으려는 경우 각 쌍 집합은 서로 다른 지역에 있는 다른 Azure 데이터 센터에서 실행될 수 있습니다. Azure VM으로 실행되는 Redis 노드를 빌드하고 구성하는 예제는 Azure의 CentOS Linux VM에서 Redis 실행을 참조하세요.
Note
이러한 방식으로 자체 Redis 캐시를 구현하는 경우 서비스 모니터링, 관리 및 보안을 담당합니다.
Redis 캐시 분할
캐시 분할에는 여러 컴퓨터에서 캐시를 분할하는 작업이 포함됩니다. 이 구조는 다음을 포함하여 단일 캐시 서버를 사용하는 경우보다 몇 가지 이점을 제공합니다.
- 단일 서버에 저장할 수 있는 것보다 훨씬 큰 캐시를 만듭니다.
- 서버 간에 데이터를 배포하여 가용성을 향상합니다. 한 서버가 실패하거나 액세스할 수 없게 되면 보유하는 데이터를 사용할 수 없지만 나머지 서버의 데이터는 계속 액세스할 수 있습니다. 캐시의 경우 캐시된 데이터는 데이터베이스에 저장된 데이터의 임시 복사본이기 때문에 중요하지 않습니다. 액세스할 수 없게 되는 서버의 캐시된 데이터를 대신 다른 서버에 캐시할 수 있습니다.
- 서버 간에 부하를 분산하여 성능 및 확장성을 향상합니다.
- 데이터에 액세스하는 사용자와 가까운 데이터를 지리적으로 지정하여 대기 시간을 줄입니다.
캐시의 경우 가장 일반적인 분할 형식은 분할입니다. 이 전략에서 각 파티션(또는 분할된 데이터베이스)은 자체적으로 Redis 캐시입니다. 데이터는 다양한 방법을 사용하여 데이터를 배포할 수 있는 분할 논리를 사용하여 특정 파티션으로 전달됩니다. The Sharding pattern provides more information about implementing sharding.
Redis 캐시에서 분할을 구현하려면 다음 방법 중 하나를 사용할 수 있습니다.
- 서버 쪽 쿼리 라우팅. 이 기술에서 클라이언트 애플리케이션은 캐시(아마도 가장 가까운 서버)를 구성하는 Redis 서버에 요청을 보냅니다. 각 Redis 서버는 보유하고 있는 파티션을 설명하는 메타데이터를 저장하고 다른 서버에 있는 파티션에 대한 정보도 포함합니다. Redis 서버는 클라이언트 요청을 검사합니다. 로컬로 확인할 수 있는 경우 요청된 작업을 수행합니다. 그렇지 않으면 요청을 적절한 서버로 전달합니다. 이 모델은 Redis 클러스터링에 의해 구현되며 Redis 웹 사이트의 Redis 클러스터 자습서 페이지에 자세히 설명되어 있습니다. Redis 클러스터링이 클라이언트 애플리케이션에 투명하며, 클라이언트를 다시 구성하지 않고도 추가 Redis 서버를 클러스터에 추가하고 데이터를 다시 분할할 수 있습니다.
- Client-side partitioning. 이 모델에서 클라이언트 애플리케이션에는 요청을 적절한 Redis 서버로 라우팅하는 논리(라이브러리 형식일 수 있음)가 포함되어 있습니다. 이 방법은 Azure Cache for Redis와 함께 사용할 수 있습니다. 여러 Azure Cache for Redis(각 데이터 파티션에 대해 하나씩)를 만들고 요청을 올바른 캐시로 라우팅하는 클라이언트 쪽 논리를 구현합니다. 분할 체계가 변경되면(예: 추가 Azure Cache for Redis가 만들어지는 경우) 클라이언트 애플리케이션을 다시 구성해야 할 수 있습니다.
- Proxy-assisted partitioning. 이 체계에서 클라이언트 애플리케이션은 데이터를 분할하는 방법을 이해하는 중간 프록시 서비스로 요청을 보낸 다음 요청을 적절한 Redis 서버로 라우팅합니다. 이 방법은 Azure Cache for Redis와 함께 사용할 수도 있습니다. 프록시 서비스는 Azure 클라우드 서비스로 구현할 수 있습니다. 이 방법을 사용하려면 서비스를 구현하기 위해 추가적인 복잡성 수준이 필요하며 클라이언트 쪽 분할을 사용하는 것보다 요청을 수행하는 데 시간이 더 오래 걸릴 수 있습니다.
페이지 분할: Redis 웹 사이트의 여러 Redis 인스턴스 간에 데이터를 분할하는 방법은 Redis를 사용하여 분할을 구현하는 방법에 대한 추가 정보를 제공합니다.
Redis 캐시 클라이언트 애플리케이션 구현
Redis는 다양한 프로그래밍 언어로 작성된 클라이언트 애플리케이션을 지원합니다. .NET Framework를 사용하여 새 애플리케이션을 빌드하는 경우 StackExchange.Redis 클라이언트 라이브러리를 사용하는 것이 좋습니다. 이 라이브러리는 Redis 서버에 연결하고, 명령을 보내고, 응답을 받기 위한 세부 정보를 추상화하는 .NET Framework 개체 모델을 제공합니다. Visual Studio에서 NuGet 패키지로 사용할 수 있습니다. 이 동일한 라이브러리를 사용하여 Azure Cache for Redis 또는 VM에서 호스트되는 사용자 지정 Redis 캐시에 연결할 수 있습니다.
Redis 서버에 연결하려면 클래스의 정적 Connect 메서드를 ConnectionMultiplexer 사용합니다. 이 메서드가 만드는 연결은 클라이언트 애플리케이션의 수명 동안 사용하도록 설계되었으며 여러 동시 스레드에서 동일한 연결을 사용할 수 있습니다. Redis 작업을 수행할 때마다 다시 연결하고 연결을 끊지 마세요. 성능이 저하될 수 있기 때문입니다.
Redis 호스트의 주소 및 암호와 같은 연결 매개 변수를 지정할 수 있습니다. Azure Cache for Redis를 사용하는 경우 암호는 Azure Portal을 사용하여 Azure Cache for Redis에 대해 생성되는 기본 또는 보조 키입니다.
Redis 서버에 연결한 후에는 캐시 역할을 하는 Redis Database에서 핸들을 가져올 수 있습니다. Redis 연결은 이 작업을 수행하는 메서드를 제공합니다 GetDatabase . 그런 다음 캐시에서 항목을 검색하고 및 StringGet 메서드를 사용하여 캐시에 StringSet 데이터를 저장할 수 있습니다. 이러한 메서드는 키를 매개 변수로 예상하며 일치하는 값()이 있는 캐시에서 항목을 반환하거나 이 키(StringGetStringSet)를 사용하여 캐시에 항목을 추가합니다.
Redis 서버의 위치에 따라 요청이 서버로 전송되고 응답이 클라이언트에 반환되는 동안 많은 작업에 약간의 대기 시간이 발생할 수 있습니다. StackExchange 라이브러리는 클라이언트 애플리케이션의 응답성을 유지하기 위해 노출하는 많은 메서드의 비동기 버전을 제공합니다. 이러한 메서드는 .NET Framework에서 작업 기반 비동기 패턴을 지원합니다.
다음 코드 조각은 라는 RetrieveItem메서드를 보여줍니다. Redis 및 StackExchange 라이브러리를 기반으로 캐시 배제 패턴의 구현을 보여 줍니다. 메서드는 문자열 키 값을 사용하고 메서드(비동기 버전StringGetAsync)를 호출 StringGet 하여 Redis 캐시에서 해당 항목을 검색하려고 시도합니다.
항목을 찾을 수 없는 경우 메서드(StackExchange 라이브러리의 일부가 아닌 로컬 메서드)를 사용하여 GetItemFromDataSourceAsync 기본 데이터 원본에서 가져옵니다. 그런 다음 메서드를 사용하여 StringSetAsync 캐시에 추가되므로 다음에 더 빨리 검색할 수 있습니다.
// Connect to the Azure Redis cache
ConfigurationOptions config = new ConfigurationOptions();
config.EndPoints.Add("<your DNS name>.redis.cache.windows.net");
config.Password = "<Redis cache key from management portal>";
ConnectionMultiplexer redisHostConnection = ConnectionMultiplexer.Connect(config);
IDatabase cache = redisHostConnection.GetDatabase();
...
private async Task<string> RetrieveItem(string itemKey)
{
// Attempt to retrieve the item from the Redis cache
string itemValue = await cache.StringGetAsync(itemKey);
// If the value returned is null, the item was not found in the cache
// So retrieve the item from the data source and add it to the cache
if (itemValue == null)
{
itemValue = await GetItemFromDataSourceAsync(itemKey);
await cache.StringSetAsync(itemKey, itemValue);
}
// Return the item
return itemValue;
}
및 StringGet 메서드는 StringSet 문자열 값을 검색하거나 저장하는 것으로 제한되지 않습니다. 바이트 배열로 직렬화된 모든 항목을 사용할 수 있습니다. .NET 개체를 저장해야 하는 경우 바이트 스트림으로 serialize하고 메서드를 StringSet 사용하여 캐시에 쓸 수 있습니다.
마찬가지로 메서드를 사용하여 StringGet .NET 개체로 역직렬화하여 캐시에서 개체를 읽을 수 있습니다. 다음 코드는 IDatabase 인터페이스에 대한 확장 메서드 집합( GetDatabase Redis 연결 메서드가 개체를 IDatabase 반환함) 및 이러한 메서드를 사용하여 개체를 읽고 캐시에 쓰는 BlogPost 몇 가지 샘플 코드를 보여 줍니다.
public static class RedisCacheExtensions
{
public static async Task<T> GetAsync<T>(this IDatabase cache, string key)
{
return Deserialize<T>(await cache.StringGetAsync(key));
}
public static async Task<object> GetAsync(this IDatabase cache, string key)
{
return Deserialize<object>(await cache.StringGetAsync(key));
}
public static async Task SetAsync(this IDatabase cache, string key, object value)
{
await cache.StringSetAsync(key, Serialize(value));
}
static byte[] Serialize(object o)
{
byte[] objectDataAsStream = null;
if (o != null)
{
var jsonString = JsonSerializer.Serialize(o);
objectDataAsStream = Encoding.ASCII.GetBytes(jsonString);
}
return objectDataAsStream;
}
static T Deserialize<T>(byte[] stream)
{
T result = default(T);
if (stream != null)
{
var jsonString = Encoding.ASCII.GetString(stream);
result = JsonSerializer.Deserialize<T>(jsonString);
}
return result;
}
}
다음 코드에서는 이러한 확장 메서드를 사용하여 캐시 배제 패턴에 따라 serialize 가능한 RetrieveBlogPost 개체를 읽고 캐시에 쓰는 메서드 BlogPost 를 보여 줍니다.
// The BlogPost type
public class BlogPost
{
private HashSet<string> tags;
public BlogPost(int id, string title, int score, IEnumerable<string> tags)
{
this.Id = id;
this.Title = title;
this.Score = score;
this.tags = new HashSet<string>(tags);
}
public int Id { get; set; }
public string Title { get; set; }
public int Score { get; set; }
public ICollection<string> Tags => this.tags;
}
...
private async Task<BlogPost> RetrieveBlogPost(string blogPostKey)
{
BlogPost blogPost = await cache.GetAsync<BlogPost>(blogPostKey);
if (blogPost == null)
{
blogPost = await GetBlogPostFromDataSourceAsync(blogPostKey);
await cache.SetAsync(blogPostKey, blogPost);
}
return blogPost;
}
Redis는 클라이언트 애플리케이션이 여러 비동기 요청을 보내는 경우 명령 파이프라인을 지원합니다. Redis는 엄격한 순서로 명령을 수신하고 응답하는 대신 동일한 연결을 사용하여 요청을 멀티플렉싱할 수 있습니다.
이 방법은 네트워크를 보다 효율적으로 사용하여 대기 시간을 줄이는 데 도움이 됩니다. 다음 코드 조각은 두 고객의 세부 정보를 동시에 검색하는 예제를 보여 줍니다. 이 코드는 두 개의 요청을 제출한 다음 결과를 받기 위해 대기하기 전에 다른 처리(표시되지 않음)를 수행합니다.
Wait 캐시 개체의 메서드는 .NET Framework Task.Wait 메서드와 비슷합니다.
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
var task1 = cache.StringGetAsync("customer:1");
var task2 = cache.StringGetAsync("customer:2");
...
var customer1 = cache.Wait(task1);
var customer2 = cache.Wait(task2);
Azure Cache for Redis를 사용할 수 있는 클라이언트 애플리케이션을 작성하는 방법에 대한 자세한 내용은 Azure Cache for Redis 설명서를 참조하세요. More information is also available at StackExchange.Redis.
동일한 웹 사이트의 파이프라인 및 멀티플렉서 페이지에서는 Redis 및 StackExchange 라이브러리를 사용한 비동기 작업 및 파이프라인에 대한 자세한 정보를 제공합니다.
Redis 캐싱 사용
캐싱 문제에 Redis를 가장 간단하게 사용하는 것은 키-값 쌍입니다. 여기서 값은 이진 데이터를 포함할 수 있는 임의의 길이의 해석되지 않은 문자열입니다. 기본적으로 문자열로 처리할 수 있는 바이트 배열입니다. 이 시나리오는 이 문서의 앞부분에서 Redis Cache 클라이언트 애플리케이션 구현 섹션에 설명되어 있습니다.
키에는 해석되지 않은 데이터도 포함되므로 모든 이진 정보를 키로 사용할 수 있습니다. 그러나 키가 길수록 저장하는 데 더 많은 공간이 소요되고 조회 작업을 수행하는 데 더 오래 걸립니다. 유용성과 유지 관리의 용이성을 위해 키 영역을 신중하게 디자인하고 의미 있는(자세한 내용은 아님) 키를 사용합니다.
예를 들어 "customer:100"과 같은 구조적 키를 사용하여 단순히 "100"이 아닌 ID가 100인 고객의 키를 나타냅니다. 이 체계를 사용하면 다양한 데이터 형식을 저장하는 값을 쉽게 구분할 수 있습니다. 예를 들어 "orders:100" 키를 사용하여 ID가 100인 주문의 키를 나타낼 수도 있습니다.
1차원 이진 문자열 외에도 Redis 키-값 쌍의 값은 목록, 집합(정렬 및 정렬되지 않음) 및 해시를 비롯한 보다 구조화된 정보를 포함할 수 있습니다. Redis는 이러한 형식을 조작할 수 있는 포괄적인 명령 집합을 제공하며, 이러한 명령의 대부분은 StackExchange와 같은 클라이언트 라이브러리를 통해 .NET Framework 애플리케이션에서 사용할 수 있습니다. Redis 웹 사이트의 Redis 데이터 형식 및 추상화 소개 페이지에서는 이러한 형식과 이를 조작하는 데 사용할 수 있는 명령에 대한 자세한 개요를 제공합니다.
이 섹션에서는 이러한 데이터 형식 및 명령에 대한 몇 가지 일반적인 사용 사례를 요약합니다.
원자성 및 일괄 처리 작업 수행
Redis는 문자열 값에 대한 일련의 원자성 가져오기 및 설정 작업을 지원합니다. 이러한 작업은 별도의 GET 명령과 SET 명령을 사용할 때 발생할 수 있는 경합 위험을 제거합니다. 사용 가능한 작업은 다음과 같습니다.
INCR,INCRBY및DECRDECRBY- 정수 숫자 데이터 값에 대한 원자성 증가 및 감소 작업을 수행합니다. StackExchange 라이브러리는 이러한 작업을 수행하고 캐시에IDatabase.StringIncrementAsync저장된 결과 값을 반환하기 위해 오버로드된 버전의 및IDatabase.StringDecrementAsync메서드를 제공합니다. 다음 코드 조각에서는 이러한 메서드를 사용하는 방법을 보여 줍니다.ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... await cache.StringSetAsync("data:counter", 99); ... long oldValue = await cache.StringIncrementAsync("data:counter"); // Increment by 1 (the default) // oldValue should be 100 long newValue = await cache.StringDecrementAsync("data:counter", 50); // Decrement by 50 // newValue should be 50GETSET키와 연결된 값을 검색하고 새 값으로 변경하는 입니다. StackExchange 라이브러리를 사용하면 이 작업을 메서드를IDatabase.StringGetSetAsync통해 사용할 수 있습니다. 아래 코드 조각은 이 메서드의 예를 보여줍니다. 이 코드는 이전 예제의 "data:counter" 키와 연결된 현재 값을 반환합니다. 그런 다음 이 키의 값을 모두 동일한 작업의 일부로 0으로 다시 설정합니다.ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... string oldValue = await cache.StringGetSetAsync("data:counter", 0);MGET및MSET- 문자열 값 집합을 단일 작업으로 반환하거나 변경할 수 있습니다. 다음 예제와 같이 이IDatabase.StringGetAsync기능을 지원하기 위해 메서드와IDatabase.StringSetAsync메서드가 오버로드됩니다.ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... // Create a list of key-value pairs var keysAndValues = new List<KeyValuePair<RedisKey, RedisValue>>() { new KeyValuePair<RedisKey, RedisValue>("data:key1", "value1"), new KeyValuePair<RedisKey, RedisValue>("data:key99", "value2"), new KeyValuePair<RedisKey, RedisValue>("data:key322", "value3") }; // Store the list of key-value pairs in the cache cache.StringSet(keysAndValues.ToArray()); ... // Find all values that match a list of keys RedisKey[] keys = { "data:key1", "data:key99", "data:key322"}; // values should contain { "value1", "value2", "value3" } RedisValue[] values = cache.StringGet(keys);
이 문서의 앞부분에 있는 Redis 트랜잭션 및 일괄 처리 섹션에 설명된 대로 여러 작업을 단일 Redis 트랜잭션으로 결합할 수도 있습니다. StackExchange 라이브러리는 인터페이스를 통해 ITransaction 트랜잭션을 지원합니다.
메서드를 ITransaction 사용하여 개체를 만듭니다 IDatabase.CreateTransaction . 개체에서 제공하는 메서드를 사용하여 트랜잭션에 명령을 호출합니다 ITransaction .
인터페이스는 ITransaction 모든 메서드가 비동기적이라는 점을 제외하고 인터페이스에서 IDatabase 액세스하는 메서드와 유사한 메서드 집합에 대한 액세스를 제공합니다. 즉, 메서드가 호출될 때만 ITransaction.Execute 수행됩니다. 메서드에서 반환 ITransaction.Execute 되는 값은 트랜잭션이 성공적으로 만들어졌는지(true) 또는 실패한 경우(false)를 나타냅니다.
다음 코드 조각은 동일한 트랜잭션의 일부로 두 개의 카운터를 증가시키고 감소시키는 예제를 보여 줍니다.
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
ITransaction transaction = cache.CreateTransaction();
var tx1 = transaction.StringIncrementAsync("data:counter1");
var tx2 = transaction.StringDecrementAsync("data:counter2");
bool result = transaction.Execute();
Console.WriteLine("Transaction {0}", result ? "succeeded" : "failed");
Console.WriteLine("Result of increment: {0}", tx1.Result);
Console.WriteLine("Result of decrement: {0}", tx2.Result);
Redis 트랜잭션은 관계형 데이터베이스의 트랜잭션과 다릅니다. 이 메서드는 Execute 실행할 트랜잭션을 구성하는 모든 명령을 큐에 대기하기만 하면 해당 명령 중 형식이 잘못된 경우 트랜잭션이 중지됩니다. 모든 명령이 성공적으로 큐에 대기된 경우 각 명령은 비동기적으로 실행됩니다.
명령이 실패하면 다른 명령은 계속 처리됩니다. If you need to verify that a command has completed successfully, you must fetch the results of the command by using the Result property of the corresponding task, as shown in the example above. Reading the Result property will block the calling thread until the task has completed.
자세한 내용은 Redis의 트랜잭션을 참조하세요.
일괄 처리 작업을 수행할 때 StackExchange 라이브러리의 인터페이스를 사용할 IBatch 수 있습니다. 이 인터페이스는 모든 메서드가 비동기적이라는 점을 제외하고 인터페이스에서 IDatabase 액세스하는 것과 유사한 메서드 집합에 대한 액세스를 제공합니다.
다음 예제와 같이 메서드를 IBatchIDatabase.CreateBatch 사용하여 개체를 만든 다음 메서드를 IBatch.Execute 사용하여 일괄 처리를 실행합니다. 이 코드는 단순히 문자열 값을 설정하고, 이전 예제에 사용된 것과 동일한 카운터를 증가 및 감소시키고, 결과를 표시합니다.
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
IBatch batch = cache.CreateBatch();
batch.StringSetAsync("data:key1", 11);
var t1 = batch.StringIncrementAsync("data:counter1");
var t2 = batch.StringDecrementAsync("data:counter2");
batch.Execute();
Console.WriteLine("{0}", t1.Result);
Console.WriteLine("{0}", t2.Result);
트랜잭션과 달리 일괄 처리의 명령이 잘못된 형식으로 인해 실패하는 경우 다른 명령이 계속 실행될 수 있음을 이해하는 것이 중요합니다. 이 메서드는 IBatch.Execute 성공 또는 실패의 표시를 반환하지 않습니다.
실행 및 캐시 잊기 작업 수행
Redis는 명령 플래그를 사용하여 화재 및 잊기 작업을 지원합니다. 이 경우 클라이언트는 단순히 작업을 시작하지만 결과에는 관심이 없으며 명령이 완료될 때까지 기다리지 않습니다. 아래 예제에서는 INCR 명령을 실행 및 잊기 작업으로 수행하는 방법을 보여줍니다.
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
await cache.StringSetAsync("data:key1", 99);
...
cache.StringIncrement("data:key1", flags: CommandFlags.FireAndForget);
자동으로 만료 키 지정
Redis 캐시에 항목을 저장하는 경우 항목이 캐시에서 자동으로 제거되는 시간 제한을 지정할 수 있습니다. 명령을 사용하여 TTL 키가 만료되기까지의 시간을 쿼리할 수도 있습니다. 이 명령은 메서드를 사용하여 IDatabase.KeyTimeToLive StackExchange 애플리케이션에서 사용할 수 있습니다.
다음 코드 조각은 키의 만료 시간을 20초로 설정하고 키의 나머지 수명을 쿼리하는 방법을 보여 주는 코드 조각입니다.
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Add a key with an expiration time of 20 seconds
await cache.StringSetAsync("data:key1", 99, TimeSpan.FromSeconds(20));
...
// Query how much time a key has left to live
// If the key has already expired, the KeyTimeToLive function returns a null
TimeSpan? expiry = cache.KeyTimeToLive("data:key1");
또한 STACKExchange 라이브러리에서 메서드로 KeyExpireAsync 사용할 수 있는 EXPIRE 명령을 사용하여 만료 시간을 특정 날짜 및 시간으로 설정할 수도 있습니다.
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Add a key with an expiration date of midnight on 1st January 2015
await cache.StringSetAsync("data:key1", 99);
await cache.KeyExpireAsync("data:key1",
new DateTime(2015, 1, 1, 0, 0, 0, DateTimeKind.Utc));
...
Tip
StackExchange 라이브러리를 통해 메서드로 IDatabase.KeyDeleteAsync 사용할 수 있는 DEL 명령을 사용하여 캐시에서 항목을 수동으로 제거할 수 있습니다.
태그를 사용하여 캐시된 항목 상호 연결
Redis 집합은 단일 키를 공유하는 여러 항목의 컬렉션입니다. SADD 명령을 사용하여 집합을 만들 수 있습니다. SMEMBERS 명령을 사용하여 집합의 항목을 검색할 수 있습니다. StackExchange 라이브러리는 메서드를 사용하여 SADD 명령을 IDatabase.SetAddAsync 구현하고 메서드를 사용하여 SMEMBERS 명령을 IDatabase.SetMembersAsync 구현합니다.
기존 집합을 결합하여 SDIFF(차이 설정), SINTER(교차 집합) 및 SUNION(집합 공용 구조체) 명령을 사용하여 새 집합을 만들 수도 있습니다. StackExchange 라이브러리는 메서드에서 IDatabase.SetCombineAsync 이러한 작업을 통합합니다. 이 메서드의 첫 번째 매개 변수는 수행할 set 작업을 지정합니다.
다음 코드 조각은 집합이 관련 항목의 컬렉션을 신속하게 저장하고 검색하는 데 유용할 수 있는 방법을 보여 줍니다. 이 코드는 이 문서의 앞부분에서 Redis Cache 클라이언트 애플리케이션 구현 섹션에 설명된 형식을 사용합니다 BlogPost .
BlogPost 개체에는 ID, 제목, 순위 점수 및 태그 컬렉션의 네 가지 필드가 포함됩니다. 아래의 첫 번째 코드 조각은 개체의 C# 목록을 BlogPost 채우는 데 사용되는 샘플 데이터를 보여줍니다.
List<string[]> tags = new List<string[]>
{
new[] { "iot","csharp" },
new[] { "iot","azure","csharp" },
new[] { "csharp","git","big data" },
new[] { "iot","git","database" },
new[] { "database","git" },
new[] { "csharp","database" },
new[] { "iot" },
new[] { "iot","database","git" },
new[] { "azure","database","big data","git","csharp" },
new[] { "azure" }
};
List<BlogPost> posts = new List<BlogPost>();
int blogKey = 0;
int numberOfPosts = 20;
Random random = new Random();
for (int i = 0; i < numberOfPosts; i++)
{
blogKey++;
posts.Add(new BlogPost(
blogKey, // Blog post ID
string.Format(CultureInfo.InvariantCulture, "Blog Post #{0}",
blogKey), // Blog post title
random.Next(100, 10000), // Ranking score
tags[i % tags.Count])); // Tags--assigned from a collection
// in the tags list
}
각 BlogPost 개체에 대한 태그를 Redis 캐시에 집합으로 저장하고 각 집합을 해당 BlogPostID와 연결할 수 있습니다. 이렇게 하면 애플리케이션이 특정 블로그 게시물에 속하는 모든 태그를 빠르게 찾을 수 있습니다. 반대 방향으로 검색을 사용하도록 설정하고 특정 태그를 공유하는 모든 블로그 게시물을 찾으려면 키의 태그 ID를 참조하는 블로그 게시물을 포함하는 다른 집합을 만들 수 있습니다.
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Tags are easily represented as Redis Sets
foreach (BlogPost post in posts)
{
string redisKey = string.Format(CultureInfo.InvariantCulture,
"blog:posts:{0}:tags", post.Id);
// Add tags to the blog post in Redis
await cache.SetAddAsync(
redisKey, post.Tags.Select(s => (RedisValue)s).ToArray());
// Now do the inverse so we can figure out which blog posts have a given tag
foreach (var tag in post.Tags)
{
await cache.SetAddAsync(string.Format(CultureInfo.InvariantCulture,
"tag:{0}:blog:posts", tag), post.Id);
}
}
이러한 구조를 사용하면 많은 일반적인 쿼리를 매우 효율적으로 수행할 수 있습니다. 예를 들어 다음과 같이 블로그 게시물 1의 모든 태그를 찾아 표시할 수 있습니다.
// Show the tags for blog post #1
foreach (var value in await cache.SetMembersAsync("blog:posts:1:tags"))
{
Console.WriteLine(value);
}
다음과 같이 교차 설정 작업을 수행하여 블로그 게시물 1 및 블로그 게시물 2에 공통적인 모든 태그를 찾을 수 있습니다.
// Show the tags in common for blog posts #1 and #2
foreach (var value in await cache.SetCombineAsync(SetOperation.Intersect, new RedisKey[]
{ "blog:posts:1:tags", "blog:posts:2:tags" }))
{
Console.WriteLine(value);
}
또한 특정 태그가 포함된 모든 블로그 게시물을 찾을 수 있습니다.
// Show the ids of the blog posts that have the tag "iot".
foreach (var value in await cache.SetMembersAsync("tag:iot:blog:posts"))
{
Console.WriteLine(value);
}
최근에 액세스한 항목 찾기
많은 애플리케이션에 필요한 일반적인 작업은 가장 최근에 액세스한 항목을 찾는 것입니다. 예를 들어 블로깅 사이트에서 가장 최근에 읽은 블로그 게시물에 대한 정보를 표시할 수 있습니다.
Redis 목록을 사용하여 이 기능을 구현할 수 있습니다. Redis 목록에는 동일한 키를 공유하는 여러 항목이 포함되어 있습니다. 목록은 이중 큐 역할을합니다. LPUSH(왼쪽 푸시) 및 RPUSH(오른쪽 푸시) 명령을 사용하여 목록의 양쪽 끝에 항목을 푸시할 수 있습니다. LPOP 및 RPOP 명령을 사용하여 목록의 양쪽 끝에서 항목을 검색할 수 있습니다. LRANGE 및 RRANGE 명령을 사용하여 요소 집합을 반환할 수도 있습니다.
아래 코드 조각에서는 StackExchange 라이브러리를 사용하여 이러한 작업을 수행하는 방법을 보여 줍니다. 이 코드는 BlogPost 이전 예제의 형식을 사용합니다. 사용자가 IDatabase.ListLeftPushAsync 블로그 게시물을 읽을 때 메서드는 Redis 캐시의 "blog:recent_posts" 키와 연결된 목록에 블로그 게시물의 제목을 푸시합니다.
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
string redisKey = "blog:recent_posts";
BlogPost blogPost = ...; // Reference to the blog post that has just been read
await cache.ListLeftPushAsync(
redisKey, blogPost.Title); // Push the blog post onto the list
더 많은 블로그 게시물을 읽으면 제목이 동일한 목록으로 푸시됩니다. 목록은 타이틀이 추가된 순서에 따라 정렬됩니다. 가장 최근에 읽은 블로그 게시물은 목록의 왼쪽 끝에 있습니다. (동일한 블로그 게시물을 두 번 이상 읽는 경우 목록에 여러 항목이 포함됩니다.)
메서드를 사용하여 가장 최근에 읽은 게시물의 제목을 표시할 IDatabase.ListRange 수 있습니다. 이 메서드는 목록, 시작점 및 끝점을 포함하는 키를 사용합니다. 다음 코드는 목록의 왼쪽 끝에 있는 10개의 블로그 게시물(0에서 9까지의 항목)의 제목을 검색합니다.
// Show latest ten posts
foreach (string postTitle in await cache.ListRangeAsync(redisKey, 0, 9))
{
Console.WriteLine(postTitle);
}
이 메서드는 ListRangeAsync 목록에서 항목을 제거하지 않습니다. 이렇게 하려면 해당 및 IDatabase.ListLeftPopAsync 메서드를 IDatabase.ListRightPopAsync 사용할 수 있습니다.
목록이 무기한 증가하지 않도록 하려면 목록을 트리밍하여 정기적으로 항목을 선별할 수 있습니다. 아래 코드 조각은 목록에서 가장 왼쪽에 있는 항목 5개를 제외한 모든 항목을 제거하는 방법을 보여줍니다.
await cache.ListTrimAsync(redisKey, 0, 5);
리더 보드 구현
기본적으로 집합의 항목은 특정 순서로 유지되지 않습니다. ZADD 명령(StackExchange 라이브러리의 IDatabase.SortedSetAdd 메서드)을 사용하여 정렬된 집합을 만들 수 있습니다. 항목은 명령에 대한 매개 변수로 제공되는 점수라는 숫자 값을 사용하여 정렬됩니다.
다음 코드 조각은 블로그 게시물의 제목을 순서가 지정된 목록에 추가합니다. 이 예제에서 각 블로그 게시물에는 블로그 게시물의 순위가 포함된 점수 필드도 있습니다.
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
string redisKey = "blog:post_rankings";
BlogPost blogPost = ...; // Reference to a blog post that has just been rated
await cache.SortedSetAddAsync(redisKey, blogPost.Title, blogPost.Score);
다음 방법을 사용하여 블로그 게시물 제목 및 점수를 오름차순으로 검색할 IDatabase.SortedSetRangeByRankWithScores 수 있습니다.
foreach (var post in await cache.SortedSetRangeByRankWithScoresAsync(redisKey))
{
Console.WriteLine(post);
}
Note
또한 StackExchange 라이브러리는 점수 순서로 IDatabase.SortedSetRangeByRankAsync 데이터를 반환하는 메서드를 제공하지만 점수를 반환하지는 않습니다.
내림차순으로 항목을 검색하고 메서드에 추가 매개 변수를 제공하여 반환되는 항목 수를 제한할 IDatabase.SortedSetRangeByRankWithScoresAsync 수도 있습니다. 다음 예제에서는 상위 10개 블로그 게시물의 제목과 점수를 표시합니다.
foreach (var post in await cache.SortedSetRangeByRankWithScoresAsync(
redisKey, 0, 9, Order.Descending))
{
Console.WriteLine(post);
}
다음 예제에서는 지정된 점수 범위에 속하는 항목으로 반환되는 항목을 제한하는 데 사용할 수 있는 메서드를 사용합니다 IDatabase.SortedSetRangeByScoreWithScoresAsync .
// Blog posts with scores between 5000 and 100000
foreach (var post in await cache.SortedSetRangeByScoreWithScoresAsync(
redisKey, 5000, 100000))
{
Console.WriteLine(post);
}
채널을 사용한 메시지
Redis 서버는 데이터 캐시 역할을 하는 것 외에도 고성능 게시자/구독자 메커니즘을 통해 메시징을 제공합니다. 클라이언트 애플리케이션은 채널을 구독할 수 있으며, 다른 애플리케이션 또는 서비스는 채널에 메시지를 게시할 수 있습니다. 그러면 구독 애플리케이션이 이러한 메시지를 수신하고 처리할 수 있습니다.
Redis는 채널 구독에 사용할 클라이언트 애플리케이션에 대한 SUBSCRIBE 명령을 제공합니다. 이 명령은 애플리케이션이 메시지를 수락할 하나 이상의 채널 이름을 예상합니다. StackExchange 라이브러리에는 .NET Framework 애플리케이션이 구독하고 채널에 게시할 수 있는 인터페이스가 포함되어 ISubscription 있습니다.
Redis 서버에 대한 연결 방법을 사용하여 ISubscription 개체를 만듭니 GetSubscriber 다. 그런 다음 이 개체의 메서드를 사용하여 채널에서 SubscribeAsync 메시지를 수신 대기합니다. 다음 코드 예제에서는 "messages:blogPosts"라는 채널을 구독하는 방법을 보여 줍니다.
ConnectionMultiplexer redisHostConnection = ...;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
...
await subscriber.SubscribeAsync("messages:blogPosts", (channel, message) => Console.WriteLine("Title is: {0}", message));
메서드의 Subscribe 첫 번째 매개 변수는 채널의 이름입니다. 이 이름은 캐시의 키에서 사용하는 것과 동일한 규칙을 따릅니다. 이름은 모든 이진 데이터를 포함할 수 있지만 비교적 짧고 의미 있는 문자열을 사용하여 좋은 성능과 유지 관리를 보장하는 것이 좋습니다.
또한 채널에서 사용하는 네임스페이스는 키에서 사용하는 네임스페이스와는 별개입니다. 즉, 이름이 같은 채널과 키를 사용할 수 있지만 애플리케이션 코드를 유지 관리하기가 더 어려워질 수 있습니다.
두 번째 매개 변수는 작업 대리자입니다. 이 대리자는 채널에 새 메시지가 나타날 때마다 비동기적으로 실행됩니다. 이 예제에서는 단순히 콘솔에 메시지를 표시합니다(메시지에 블로그 게시물의 제목이 포함됨).
채널에 게시하기 위해 애플리케이션은 Redis PUBLISH 명령을 사용할 수 있습니다. StackExchange 라이브러리는 이 작업을 수행하는 메서드를 제공합니다 IServer.PublishAsync . 다음 코드 조각은 "messages:blogPosts" 채널에 메시지를 게시하는 방법을 보여 줍니다.
ConnectionMultiplexer redisHostConnection = ...;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
...
BlogPost blogPost = ...;
subscriber.PublishAsync("messages:blogPosts", blogPost.Title);
게시/구독 메커니즘에 대해 이해해야 하는 몇 가지 사항이 있습니다.
- 여러 구독자는 동일한 채널을 구독할 수 있으며 모두 해당 채널에 게시된 메시지를 받게 됩니다.
- 구독자는 구독한 후에 게시된 메시지만 받습니다. 채널은 버퍼링되지 않으며 메시지가 게시되면 Redis 인프라는 각 구독자에게 메시지를 푸시한 다음 제거합니다.
- 기본적으로 메시지는 구독자가 보낸 순서대로 수신됩니다. 많은 수의 메시지와 많은 구독자 및 게시자가 있는 매우 활성 상태인 시스템에서는 메시지의 순차적 배달이 보장되면 시스템 성능이 저하될 수 있습니다. 각 메시지가 독립적이고 순서가 중요하지 않은 경우 Redis 시스템에서 동시 처리를 사용하도록 설정하여 응답성을 향상시킬 수 있습니다. 구독자가 사용하는 연결의 PreserveAsyncOrder를 false로 설정하여 StackExchange 클라이언트에서 이 작업을 수행할 수 있습니다.
ConnectionMultiplexer redisHostConnection = ...;
redisHostConnection.PreserveAsyncOrder = false;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
Serialization considerations
직렬화 형식을 선택하는 경우 성능, 상호 운용성, 버전 관리, 기존 시스템과의 호환성, 데이터 압축 및 메모리 오버헤드 간의 절충을 고려합니다. 성능을 평가할 때 벤치마크는 컨텍스트에 따라 크게 달라집니다. 실제 워크로드를 반영하지 않을 수 있으며 최신 라이브러리 또는 버전을 고려하지 않을 수 있습니다. 모든 시나리오에 대해 "가장 빠른" 직렬 변환기는 하나도 없습니다.
고려해야 할 몇 가지 옵션은 다음과 같습니다.
Protocol Buffers (also called protobuf) is a serialization format developed by Google for serializing structured data efficiently. 강력한 형식의 정의 파일을 사용하여 메시지 구조를 정의합니다. 그런 다음, 이러한 정의 파일은 메시지를 직렬화하고 역직렬화하기 위해 언어별 코드로 컴파일됩니다. Protobuf는 기존 RPC 메커니즘을 통해 사용하거나 RPC 서비스를 생성할 수 있습니다.
Apache Thrift uses a similar approach, with strongly typed definition files and a compilation step to generate the serialization code and RPC services.
Apache Avro provides similar functionality to Protocol Buffers and Thrift, but there's no compilation step. 대신 직렬화된 데이터에는 항상 구조를 설명하는 스키마가 포함됩니다.
JSON is an open standard that uses human-readable text fields. 광범위한 플랫폼 간 지원을 제공합니다. JSON은 메시지 스키마를 사용하지 않습니다. 텍스트 기반 형식이기 때문에 와이어를 통해 매우 효율적이지 않습니다. 그러나 경우에 따라 캐시된 항목을 HTTP를 통해 클라이언트에 직접 반환할 수 있습니다. 이 경우 JSON을 저장하면 다른 형식에서 역직렬화한 다음 JSON으로 직렬화하는 비용이 절감될 수 있습니다.
BSON(이진 JSON)은 JSON 과 유사한 구조를 사용하는 이진 serialization 형식입니다. BSON은 JSON을 기준으로 가볍고, 스캔하기 쉽고, 직렬화 및 역직렬화가 빨라지도록 설계되었습니다. 페이로드는 JSON과 크기가 비슷합니다. 데이터에 따라 BSON 페이로드가 JSON 페이로드보다 작거나 클 수 있습니다. BSON에는 JSON에서 사용할 수 없는 몇 가지 추가 데이터 형식, 특히 BinData(바이트 배열의 경우) 및 Date가 있습니다.
MessagePack is a binary serialization format that is designed to be compact for transmission over the wire. 메시지 스키마 또는 메시지 유형 검사가 없습니다.
Bond is a cross-platform framework for working with schematized data. 언어 간 직렬화 및 역직렬화를 지원합니다. 여기에 나열된 다른 시스템과의 주목할 만한 차이점은 상속, 형식 별칭 및 제네릭에 대한 지원입니다.
gRPC is an open-source RPC system developed by Google. 기본적으로 프로토콜 버퍼를 정의 언어 및 기본 메시지 교환 형식으로 사용합니다.
Next steps
- Azure Cache for Redis 설명서
- Azure Cache for Redis FAQ
- 작업 기반 비동기 패턴
- Redis documentation
- StackExchange.Redis
- 데이터 분할 가이드
Related resources
다음 패턴은 애플리케이션에서 캐싱을 구현할 때 시나리오와도 관련이 있을 수 있습니다.
Cache-aside pattern: This pattern describes how to load data on demand into a cache from a data store. 이 패턴은 캐시에 저장된 데이터와 원래 데이터 저장소의 데이터 간에 일관성을 유지하는 데도 도움이 됩니다.
The Sharding pattern provides information about implementing horizontal partitioning to help improve scalability when storing and accessing large volumes of data.