이 문서에서는 Azure Databricks에서 Google BigQuery 테이블에서 읽고 쓰는 방법을 설명합니다.
중요합니다
레거시 쿼리 페더레이션 설명서가 사용 중지되었으며 업데이트되지 않을 수 있습니다. 이 콘텐츠에 언급된 구성은 Databricks에서 공식적으로 승인되거나 테스트되지 않습니다. Lakehouse Federation이 원본 데이터베이스를 지원하는 경우 Databricks는 대신 이 데이터베이스를 사용하는 것이 좋습니다.
키 기반 인증을 사용하여 BigQuery에 연결해야 합니다.
권한
프로젝트에 BigQuery를 사용하여 읽고 쓸 수 있는 특정 Google 권한이 있어야 합니다.
비고
이 문서에서는 BigQuery 구체화된 뷰에 대해 설명합니다. 자세한 내용은 Google 문서 머티리얼라이즈드 뷰소개를 참조하세요. 다른 BigQuery 용어 및 BigQuery 보안 모델을 알아보려면 Google BigQuery 설명서를 참조하세요.
BigQuery를 사용하여 데이터를 읽고 쓰는 방법은 다음 두 가지 Google Cloud 프로젝트에 따라 달라집니다.
- Project(
project): Azure Databricks가 BigQuery 테이블을 읽거나 쓰는 Google Cloud 프로젝트의 ID입니다. - 부모 프로젝트(
parentProject): 읽기 및 쓰기에 대해 청구할 Google Cloud 프로젝트 ID인 부모 프로젝트의 ID입니다. 키를 생성할 Google 서비스 계정과 연결된 Google Cloud 프로젝트로 설정합니다.
BigQuery에 액세스하는 코드에서 project 및 parentProject 값을 명시적으로 제공해야 합니다. 다음과 유사한 코드를 사용합니다.
spark.read.format("bigquery") \
.option("table", table) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.load()
Google Cloud 프로젝트에 필요한 권한은 project 및 parentProject가 동일한지 여부에 따라 달라집니다. 다음 섹션에서는 각 시나리오에 필요한 사용 권한을 나열합니다.
project 및 parentProject가 일치하는 경우에 필요한 권한
project 및 parentProject 대한 ID가 동일한 경우 다음 표를 사용하여 최소 사용 권한을 확인합니다.
| Azure Databricks 작업 | 프로젝트에 필요한 Google 권한 |
|---|---|
| 구체화된 뷰 없이 BigQuery 테이블 읽기 |
project 프로젝트의 경우:
|
| 구체화된 뷰를 사용하여 BigQuery 테이블을 읽습니다. |
project 프로젝트의 경우:
구체화 프로젝트의 경우:
|
| BigQuery 테이블 작성 |
project 프로젝트의 경우:
|
project 및 parentProject가 다른 경우에 필요한 권한
project 및 parentProject 대한 ID가 다른 경우 다음 표를 사용하여 최소 사용 권한을 확인합니다.
| Azure Databricks 작업 | Google 권한 필요 |
|---|---|
| 구체화된 뷰 없이 BigQuery 테이블 읽기 |
parentProject 프로젝트의 경우:
project 프로젝트의 경우:
|
| 구체화된 뷰를 사용하여 BigQuery 테이블을 읽습니다. |
parentProject 프로젝트의 경우:
project 프로젝트의 경우:
구체화 프로젝트의 경우:
|
| BigQuery 테이블 작성 |
parentProject 프로젝트의 경우:
project 프로젝트의 경우:
|
1단계: Google Cloud 설정
BigQuery Storage API 사용
BigQuery Storage API는 BigQuery가 사용하도록 설정된 새 Google Cloud 프로젝트에서 기본적으로 사용하도록 설정됩니다. 그러나 기존 프로젝트가 있고 BigQuery Storage API가 사용하도록 설정되지 않은 경우 이 섹션의 단계에 따라 사용하도록 설정합니다.
Google Cloud CLI 또는 Google Cloud Console을 사용하여 BigQuery Storage API를 사용하도록 설정할 수 있습니다.
Google Cloud CLI를 사용하여 BigQuery Storage API 사용
gcloud services enable bigquerystorage.googleapis.com
Google Cloud Console을 사용하여 BigQuery Storage API 사용
왼쪽 탐색 창에서 API 및 서비스를 클릭합니다.
API 및 서비스 사용 단추를 클릭합니다.
검색 창에
bigquery storage api입력하고 첫 번째 결과를 선택합니다.
BigQuery Storage API가 사용하도록 설정되어 있는지 확인합니다.

Azure Databricks에 대한 Google 서비스 계정 만들기
Azure Databricks 클러스터에 대한 서비스 계정을 만듭니다. Databricks의 권장 사항에 따라 이 서비스 계정에 해당 작업을 수행하는 데 필요한 최소한의 권한을 부여하는 것이 좋습니다. BigQuery 역할 및 권한을 참조하세요.
Google Cloud CLI 또는 Google Cloud Console을 사용하여 서비스 계정을 만들 수 있습니다.
Google Cloud CLI를 사용하여 Google 서비스 계정 만들기
gcloud iam service-accounts create <service-account-name>
gcloud projects add-iam-policy-binding <project-name> \
--role roles/bigquery.user \
--member="serviceAccount:<service-account-name>@<project-name>.iam.gserviceaccount.com"
gcloud projects add-iam-policy-binding <project-name> \
--role roles/bigquery.dataEditor \
--member="serviceAccount:<service-account-name>@<project-name>.iam.gserviceaccount.com"
서비스 계정에 대한 키를 만듭니다.
gcloud iam service-accounts keys create --iam-account \
"<service-account-name>@<project-name>.iam.gserviceaccount.com" \
<project-name>-xxxxxxxxxxx.json
Google Cloud Console을 사용하여 Google 서비스 계정 만들기
계정을 만들려면 다음을 수행합니다.
왼쪽 탐색 창에서 IAM 및 관리자를 클릭합니다.
서비스 계정을 클릭합니다.
+ 서비스 계정 만들기를 클릭합니다.
서비스 계정 이름 및 설명을 입력합니다.

만들기를 클릭합니다.
서비스 계정에 대한 역할을 지정합니다. 역할 드롭다운 선택에서
BigQuery입력하고 다음 역할을 추가합니다.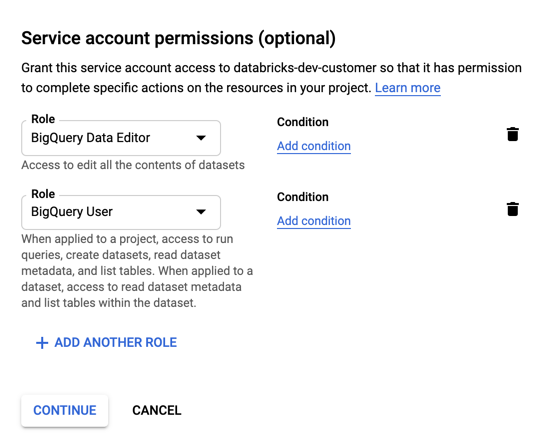
계속을 클릭합니다.
완료를 클릭합니다.
서비스 계정에 대한 키를 만들려면 다음을 수행합니다.
서비스 계정 목록에서 새로 만든 계정을 클릭합니다.
키 섹션에서 > 새 키 만들기 버튼을 클릭합니다.

JSON 키 형식을 수락합니다.
만들기를 클릭합니다. JSON 키 파일이 컴퓨터에 다운로드됩니다.
중요합니다
서비스 계정에 대해 생성하는 JSON 키 파일은 Google Cloud 계정의 데이터 세트 및 리소스에 대한 액세스를 제어하기 때문에 권한 있는 사용자와만 공유해야 하는 프라이빗 키입니다.
임시 스토리지를 위한 GCS(Google Cloud Storage) 버킷 만들기
BigQuery에 데이터를 쓰려면 데이터 원본이 GCS 버킷에 액세스해야 합니다.
왼쪽 탐색 창에서 스토리지를 클릭합니다.
버킷 만들기를 클릭합니다.

버킷 세부 정보를 구성합니다.

만들기를 클릭합니다.
권한 탭 및 구성원 추가를 클릭합니다.
버킷의 서비스 계정에 다음 권한을 제공합니다.

저장을 클릭합니다.
2단계: Azure Databricks 설정
BigQuery 테이블에 액세스하도록 클러스터를 구성하려면 JSON 키 파일을 Spark 구성으로 제공해야 합니다. 로컬 도구를 사용하여 JSON 키 파일을 Base64로 인코딩합니다. 보안을 위해 키에 액세스할 수 있는 웹 기반 또는 원격 도구를 사용하지 마세요.
클러스터를 구성할 때:
Spark 구성 탭에서 다음 Spark 구성을 추가합니다. <base64-keys>를 Base64로 인코딩된 JSON 키 파일 문자열로 바꿉니다. 대괄호 안에 있는 다른 항목(예: <client-email>)을 JSON 키 파일의 해당 필드 값으로 바꿉니다.
credentials <base64-keys>
spark.hadoop.google.cloud.auth.service.account.enable true
spark.hadoop.fs.gs.auth.service.account.email <client-email>
spark.hadoop.fs.gs.project.id <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key <private-key>
spark.hadoop.fs.gs.auth.service.account.private.key.id <private-key-id>
BigQuery 테이블 읽기 및 쓰기
BigQuery 테이블을 읽으려면 지정해야 합니다
df = spark.read.format("bigquery") \
.option("table",<table-name>) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.load()
BigQuery 테이블에 쓰려면 지정하십시오
df.write.format("bigquery") \
.mode("<mode>") \
.option("temporaryGcsBucket", "<bucket-name>") \
.option("table", <table-name>) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.save()
여기서 <bucket-name>은 Google Cloud Storage(GCS) 버킷 만들기에서 생성한 임시 스토리지에 대한 버킷의 이름입니다.
및 <project-id> 값에 대한 요구 사항에 대해 알아보려면 <parent-id> 참조하세요.
BigQuery에서 외부 테이블 만들기
중요합니다
이 기능은 Unity 카탈로그에서 지원되지 않습니다.
Databricks에서 BigQuery에서 직접 데이터를 읽는 관리되지 않는 테이블을 선언할 수 있습니다.
CREATE TABLE chosen_dataset.test_table
USING bigquery
OPTIONS (
parentProject 'gcp-parent-project-id',
project 'gcp-project-id',
temporaryGcsBucket 'some-gcp-bucket',
materializationDataset 'some-bigquery-dataset',
table 'some-bigquery-dataset.table-to-copy'
)
Python Notebook 예제: DataFrame에 Google BigQuery 테이블 로드
다음 Python Notebook은 Google BigQuery 테이블을 Azure Databricks DataFrame에 로드합니다.
Google BigQuery Python 샘플 노트북
Scala Notebook 예제: DataFrame에 Google BigQuery 테이블 로드
다음 Scala Notebook은 Google BigQuery 테이블을 Azure Databricks DataFrame에 로드합니다.