이 페이지에서는 전달자 토큰과 함께 델타 공유 열기 공유 프로토콜을 사용하여 공유된 데이터를 읽는 방법을 설명합니다. 여기에는 다음 도구를 사용하여 공유 데이터를 읽기 위한 지침이 포함되어 있습니다.
- 데이터브릭스
- Apache Spark
- 팬더
- Power BI
- Tableau
이 열린 공유 모델에서는 데이터 공급자가 팀 구성원과 공유하는 자격 증명 파일을 사용하여 공유 데이터에 대한 안전한 읽기 액세스 권한을 얻습니다. 자격 증명이 유효하고 제공자가 데이터를 공유하는 한, 액세스는 지속됩니다. 제공자는 자격 증명의 만료 및 회전을 관리합니다. 데이터에 대한 업데이트는 거의 실시간으로 사용할 수 있습니다. 공유 데이터의 복사본을 읽고 만들 수 있지만 원본 데이터는 수정할 수 없습니다.
메모
Databricks-to-Databricks Delta Sharing를 사용하여 데이터를 공유한 경우 데이터에 액세스하는 데 자격 증명 파일이 필요하지 않으며 이 문서는 적용되지 않습니다. 지침을 보려면 Databricks-to-Databricks Delta Sharing을 사용하여 공유된 데이터 읽기(수신자용)를 참조하세요.
다음 섹션에서는 Azure Databricks, Apache Spark, pandas 및 Power BI를 사용하여 자격 증명 파일을 사용하여 공유 데이터에 액세스하고 읽는 방법을 설명합니다. Delta Sharing 커넥터의 전체 목록과 사용 방법에 대한 정보는 Delta Sharing 오픈 소스 문서를 참조하십시오. 공유 데이터를 액세스하는 데 문제가 발생하면 데이터 제공업체에 문의하세요.
시작하기 전에
데이터 제공자가 공유한 자격 증명 파일은 팀의 한 구성원이 다운로드해야 합니다. 오픈 공유 모델에서 액세스 얻기를 참조하십시오.
그 파일이나 파일 위치를 공유하기 위해 안전한 채널을 사용해야 합니다.
Azure Databricks: 공유 데이터를 오픈 공유 커넥터를 사용하여 읽기
이 섹션에서는 공급자를 가져오고 카탈로그 탐색기 또는 파이썬 노트북에서 공유 데이터를 쿼리하는 방법을 설명합니다.
Azure Databricks 작업 공간이 Unity 카탈로그에 대해 활성화되어 있다면, Catalog Explorer에서 Import 제공자 UI를 사용하십시오. 자격 증명 파일을 저장하거나 지정하지 않고도 다음을 수행할 수 있습니다.
- 단추를 클릭하여 공유에서 카탈로그를 만듭니다.
- Unity 카탈로그 액세스 제어를 사용하여 공유 테이블에 대한 액세스 권한을 부여합니다.
- 표준 Unity 카탈로그 구문을 사용하여 공유 데이터를 쿼리합니다.
Azure Databricks 작업 공간이 Unity Catalog 사용 설정되어 있지 않은 경우, Python 노트북 지침을 예시로 사용하십시오.
카탈로그 탐색기
필요한 권한: 메타스토어 관리자 또는 Unity 카탈로그 메타스토어에 CREATE PROVIDER 대한 권한과 USE PROVIDER 권한이 모두 있는 사용자입니다.
Azure Databricks 작업 영역에서
 을 클릭한 후 카탈로그를 선택하여 카탈로그 탐색기를 엽니다.
을 클릭한 후 카탈로그를 선택하여 카탈로그 탐색기를 엽니다.카탈로그 창의 맨 위에서
 을 클릭합니다. 기어 아이콘을 클릭하고 델타 공유를 선택합니다.
을 클릭합니다. 기어 아이콘을 클릭하고 델타 공유를 선택합니다.또는 즐겨찾기 페이지에서 델타 공유> 버튼을 클릭합니다.
나와 공유함 탭에서 데이터 가져오기를 클릭합니다.
공급자 이름을 입력합니다.
이름에는 공백을 포함할 수 없습니다.
제공자가 공유한 자격 증명 파일을 업로드하십시오.
많은 제공업체는 자신의 Delta Sharing 네트워크를 보유하고 있으며, 이를 통해 주식을 받을 수 있습니다. 더 많은 정보를 보려면 Provider-specific configurations을(를) 참조하세요.
(선택 사항) 설명을 입력합니다.
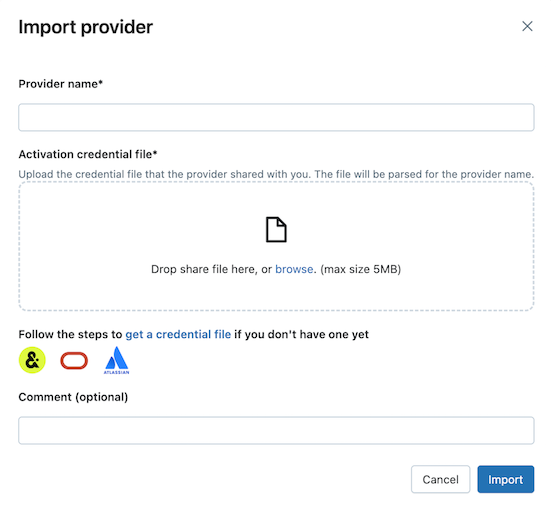
가져오기를 클릭합니다.
공유된 데이터를 통해 카탈로그를 생성하세요.
주식 탭에서 공유 행의 목록 작성을 클릭합니다.
SQL 또는 Databricks CLI를 사용하여 공유에서 카탈로그를 생성하는 방법에 대한 자세한 정보는 공유에서 카탈로그 생성을 참조하십시오.
카탈로그에 대한 접근 권한을 부여하십시오.
팀에게 공유 데이터를 어떻게 제공할 수 있습니까? 및 Delta 공유 카탈로그에서 스키마, 테이블 및 볼륨의 권한 관리를 참조하십시오.
Unity 카탈로그에 등록된 데이터 객체와 마찬가지로 공유 데이터 객체를 읽으십시오.
자세한 내용과 예시는 공유 테이블이나 볼륨에서 데이터 액세스하기를 참조하세요.
파이썬
이 섹션에서는 Azure Databricks 작업 공간에서 노트북을 사용하여 공유 데이터를 액세스하는 방법을 설명합니다. 공유 데이터를 액세스하기 위해 개방형 공유 커넥터를 사용하는 방법을 설명합니다. 사용자 또는 팀의 다른 구성원이 자격 증명 파일을 Azure Databricks에 저장한 다음 이를 사용하여 데이터 공급자의 Azure Databricks 계정에 인증하고 데이터 공급자가 공유한 데이터를 읽습니다.
메모
Azure Databricks 작업 공간이 Unity Catalog에 대해 활성화되지 않았다고 가정합니다. Unity Catalog를 사용하는 경우, 공유에서 읽을 때 자격 증명 파일을 지정할 필요가 없습니다. 공유 테이블에서 읽는 방식은 Unity Catalog에 등록된 다른 테이블에서 읽는 방식과 동일합니다. Databricks는 여기에 제공된 지침 대신 Catalog Explorer에서 제공하는 가져오기 제공자 UI를 사용할 것을 권장합니다.
먼저 Azure Databricks에서 Python 노트북을 사용하여 자격 증명 파일을 저장함으로써 팀의 사용자들이 데이터를 공유할 수 있도록 하십시오.
텍스트 편집기에서 자격 증명 파일을 여세요.
Azure Databricks 작업 영역에서 새 노트북>을 클릭하십시오.
- 이름을 입력하세요.
- 노트북의 기본 언어를 Python으로 설정하십시오.
- 노트북에 연결할 클러스터를 선택하세요.
- 만들기를 클릭합니다.
노트북이 노트북 편집기에서 열립니다.
공유 데이터를 액세스하기 위해 Python이나 pandas를 사용하려면 delta-sharing Python connector를 설치하세요. 노트북 편집기에서 다음 명령을 붙여넣으세요.
%sh pip install delta-sharing셀을 실행하세요.
Python 라이브러리가
delta-sharing아직 설치되지 않은 경우 클러스터에 설치됩니다.새로운 셀에 다음 명령을 붙여넣어 자격 증명 파일의 내용을 DBFS의 폴더에 업로드합니다.
변수를 다음과 같이 교체하세요:
<dbfs-path>: 자격 증명 파일을 저장할 폴더의 경로<credential-file-contents>: 자격 증명 파일의 내용. 이 파일의 경로가 아니라 파일의 복사된 내용입니다.자격 증명 파일은 세 가지 필드를 정의하는 JSON을 포함합니다:
shareCredentialsVersion,endpoint, 그리고bearerToken.%scala dbutils.fs.put("<dbfs-path>/config.share",""" <credential-file-contents> """)
셀을 실행하세요.
자격 증명 파일을 업로드한 후 이 셀을 삭제할 수 있습니다. 모든 작업 공간 사용자는 DBFS에서 자격 증명 파일을 읽을 수 있으며, 작업 공간의 모든 클러스터와 SQL 웨어하우스에서 DBFS에 자격 증명 파일이 제공됩니다. 셀을 삭제하려면 가장 오른쪽에 있는 셀 작업 메뉴 에서 Cell actionsx를 클릭하세요.
이제 자격 증명 파일이 저장되었으므로 노트북을 사용하여 공유된 테이블을 나열하고 읽을 수 있습니다.
파이썬을 사용하여 공유의 테이블을 나열하십시오.
새로운 셀에 다음 명령어를 붙여넣으세요. 위에서 생성한 경로로
<dbfs-path>를 대체하십시오.코드를 실행하면 Python은 클러스터의 DBFS에서 자격증명 파일을 읽습니다.
/dbfs/경로에 저장된 DBFS의 데이터를 액세스하십시오.import delta_sharing client = delta_sharing.SharingClient(f"/dbfs/<dbfs-path>/config.share") client.list_all_tables()셀을 실행하세요.
결과는 여러 개의 테이블 배열과 각 테이블에 대한 메타데이터로 구성됩니다. 다음 출력은 두 개의 표를 보여줍니다.
Out[10]: [Table(name='example_table', share='example_share_0', schema='default'), Table(name='other_example_table', share='example_share_0', schema='default')]출력이 비어 있거나 예상한 테이블이 없는 경우 데이터 공급자에게 문의하세요.
공유된 테이블을 조회합니다.
Scala 사용:
새로운 셀에 다음 명령어를 붙여넣으세요. 코드가 실행되면, 자격 증명 파일은 JVM을 통해 DBFS에서 읽어옵니다.
변수를 다음과 같이 교체하세요:
-
<profile-path>: 자격 증명 파일의 DBFS 경로. 예를 들어,/<dbfs-path>/config.share. -
<share-name>: 테이블의share=값입니다. -
<schema-name>: 테이블의schema=값입니다. -
<table-name>: 테이블의name=값입니다.
%scala spark.read.format("deltaSharing") .load("<profile-path>#<share-name>.<schema-name>.<table-name>").limit(10);셀을 실행하세요. 공유 테이블을 로드할 때마다 원본의 새 데이터가 표시됩니다.
-
SQL 사용:
데이터를 SQL로 쿼리하려면, 공유 테이블에서 워크스페이스에 로컬 테이블을 만든 후, 로컬 테이블을 쿼리합니다. 공유 데이터는 로컬 테이블에 저장되거나 캐시되지 않습니다. 로컬 테이블을 조회할 때마다 공유 데이터의 현재 상태를 확인할 수 있습니다.
새로운 셀에 다음 명령어를 붙여넣으세요.
변수를 다음과 같이 교체하세요:
-
<local-table-name>: 로컬 테이블의 이름. -
<profile-path>: 자격 증명 파일의 위치. -
<share-name>: 테이블의share=값입니다. -
<schema-name>: 테이블의schema=값입니다. -
<table-name>: 테이블의name=값입니다.
%sql DROP TABLE IF EXISTS table_name; CREATE TABLE <local-table-name> USING deltaSharing LOCATION "<profile-path>#<share-name>.<schema-name>.<table-name>"; SELECT * FROM <local-table-name> LIMIT 10;명령을 실행하면 공유 데이터가 직접 쿼리됩니다. 테스트로 테이블이 쿼리되고 처음 10개의 결과가 반환됩니다.
-
출력이 비어 있거나 예상한 데이터가 없는 경우 데이터 공급자에게 문의하세요.
Apache Spark: 공유 데이터를 읽기
공유 데이터를 Spark 3.x 이상을 사용하여 액세스하려면 다음 단계를 따르십시오.
이러한 지침에서는 데이터 공급자가 공유한 자격 증명 파일에 액세스할 수 있다고 가정합니다. 오픈 공유 모델에서 액세스 얻기를 참조하십시오.
메모
Unity 카탈로그에 대해 사용하도록 설정된 Azure Databricks 작업 영역에서 Spark를 사용하고 가져오기 공급자 UI를 사용하여 공급자와 공유를 가져온 경우 이 섹션의 지침은 적용되지 않습니다. Unity Catalog에 등록된 다른 테이블과 마찬가지로 공유 테이블에 액세스할 수 있습니다.
delta-sharing Python 연결 프로그램을 설치하거나 자격 증명 파일의 경로를 제공할 필요가 없습니다. Azure Databricks 참조: 열린 공유 커넥터을 사용하여 공유 데이터를 읽습니다.
델타 쉐어링 Python 및 Spark 커넥터를 설치하세요.
공유된 데이터와 관련된 메타데이터, 예를 들어 당신에게 공유된 테이블 목록에 접근하려면 다음의 절차를 따르세요. 이 예제는 파이썬을 사용합니다.
델타 공유 Python 커넥터를 설치하세요:
pip install delta-sharingApache Spark 커넥터를 설치합니다.
Spark를 사용하여 공유된 테이블 나열하기
공유된 항목에서 테이블을 나열하십시오. 다음 예에서 <profile-path>을(를) 자격 증명 파일의 위치로 교체하세요.
import delta_sharing
client = delta_sharing.SharingClient(f"<profile-path>/config.share")
client.list_all_tables()
결과는 여러 개의 테이블 배열과 각 테이블에 대한 메타데이터로 구성됩니다. 다음 출력은 두 개의 표를 보여줍니다.
Out[10]: [Table(name='example_table', share='example_share_0', schema='default'), Table(name='other_example_table', share='example_share_0', schema='default')]
출력이 비어 있거나 예상한 테이블이 없는 경우 데이터 공급자에게 문의하세요.
Spark를 사용하여 공유 데이터를 액세스합니다.
다음 변수들을 바꿔가며 다음을 실행하십시오.
-
<profile-path>: 자격 증명 파일의 위치. -
<share-name>: 테이블의share=값입니다. -
<schema-name>: 테이블의schema=값입니다. -
<table-name>: 테이블의name=값입니다. -
<version-as-of>: 선택 사항. 데이터를 로드할 테이블의 버전. 데이터 제공자가 테이블의 기록을 공유하는 경우에만 작동합니다.delta-sharing-spark0.5.0 이상이 필요합니다. -
<timestamp-as-of>: 선택 사항. 주어진 타임스탬프 이전 또는 해당 시점의 버전에서 데이터를 불러옵니다. 데이터 제공자가 테이블의 기록을 공유하는 경우에만 작동합니다.delta-sharing-spark0.6.0 이상 필요합니다.
파이썬
delta_sharing.load_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>", version=<version-as-of>)
spark.read.format("deltaSharing")\
.option("versionAsOf", <version-as-of>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")\
.limit(10))
delta_sharing.load_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>", timestamp=<timestamp-as-of>)
spark.read.format("deltaSharing")\
.option("timestampAsOf", <timestamp-as-of>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")\
.limit(10))
스칼라
다음 변수들을 바꿔가며 다음을 실행하십시오.
-
<profile-path>: 자격 증명 파일의 위치. -
<share-name>: 테이블의share=값입니다. -
<schema-name>: 테이블의schema=값입니다. -
<table-name>: 테이블의name=값입니다. -
<version-as-of>: 선택 사항. 데이터를 로드할 테이블의 버전. 데이터 제공자가 테이블의 기록을 공유하는 경우에만 작동합니다.delta-sharing-spark0.5.0 이상이 필요합니다. -
<timestamp-as-of>: 선택 사항. 주어진 타임스탬프 이전 또는 해당 시점의 버전에서 데이터를 불러옵니다. 데이터 제공자가 테이블의 기록을 공유하는 경우에만 작동합니다.delta-sharing-spark0.6.0 이상 필요합니다.
spark.read.format("deltaSharing")
.option("versionAsOf", <version-as-of>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
.limit(10)
spark.read.format("deltaSharing")
.option("timestampAsOf", <version-as-of>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
.limit(10)
스파크를 사용하여 공유 변경 데이터 피드를 액세스하기
소스 테이블의 변경 데이터 피드(CDF)가 활성화되어 있고 테이블 기록이 귀하와 공유된 경우, 다음 명령을 실행하여 이 변수들을 대체하고 변경 데이터 피드에 접근할 수 있습니다.
delta-sharing-spark 0.5.0 이상이 필요합니다.
하나의 시작 매개변수만 제공되어야 합니다.
-
<profile-path>: 자격 증명 파일의 위치. -
<share-name>: 테이블의share=값입니다. -
<schema-name>: 테이블의schema=값입니다. -
<table-name>: 테이블의name=값입니다. -
<starting-version>: 선택 사항. 쿼리의 시작 버전, 포함된 Long 타입으로 지정합니다. -
<ending-version>: 선택 사항. 쿼리의 끝 버전, 포함됨. 종료 버전이 제공되지 않으면 API는 최신 테이블 버전을 사용합니다. -
<starting-timestamp>: 선택 사항. 쿼리의 시작 타임스탬프는 이 타임스탬프보다 크거나 같은 버전으로 변환됩니다. 형식yyyy-mm-dd hh:mm:ss[.fffffffff]으로 문자열로 지정합니다. -
<ending-timestamp>: 선택 사항. 쿼리의 종료 타임스탬프, 이것은 이 타임스탬프보다 이전에 생성되었거나 이 타임스탬프와 같은 버전으로 변환됩니다. 형식yyyy-mm-dd hh:mm:ss[.fffffffff]으로 문자열로 지정하십시오.
파이썬
delta_sharing.load_table_changes_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_version=<starting-version>,
ending_version=<ending-version>)
delta_sharing.load_table_changes_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_timestamp=<starting-timestamp>,
ending_timestamp=<ending-timestamp>)
spark.read.format("deltaSharing").option("readChangeFeed", "true")\
.option("statingVersion", <starting-version>)\
.option("endingVersion", <ending-version>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
spark.read.format("deltaSharing").option("readChangeFeed", "true")\
.option("startingTimestamp", <starting-timestamp>)\
.option("endingTimestamp", <ending-timestamp>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
스칼라
spark.read.format("deltaSharing").option("readChangeFeed", "true")
.option("statingVersion", <starting-version>)
.option("endingVersion", <ending-version>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
spark.read.format("deltaSharing").option("readChangeFeed", "true")
.option("startingTimestamp", <starting-timestamp>)
.option("endingTimestamp", <ending-timestamp>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
출력이 비어 있거나 예상한 데이터가 없는 경우 데이터 공급자에게 문의하세요.
Spark Structured Streaming을 사용하여 공유 테이블에 접근하기
테이블 기록이 당신과 공유된 경우, 공유된 데이터를 스트리밍으로 읽을 수 있습니다.
delta-sharing-spark 0.6.0 이상 필요합니다.
지원되는 옵션:
-
ignoreDeletes: 데이터를 삭제하는 트랜잭션을 무시합니다. -
ignoreChanges: 데이터 변경 작업 (예:UPDATE,MERGE INTO,DELETE(파티션 내) 또는OVERWRITE)으로 인해 소스 테이블의 파일이 다시 작성된 경우 업데이트를 재처리하십시오. 변경되지 않은 행도 계속 내보낼 수 있습니다. 따라서 귀하의 다운스트림 소비자들은 중복을 처리할 수 있어야 합니다. 삭제는 하류로 전파되지 않습니다.ignoreChanges가ignoreDeletes를 포함합니다. 따라서ignoreChanges을 사용하면 원본 테이블의 삭제 또는 업데이트로 인해 스트림이 중단되지 않습니다. -
startingVersion: 시작할 공유 테이블 버전. 테이블의 모든 변경 사항은 이 버전부터(포함) 스트리밍 소스를 통해 읽힙니다. -
startingTimestamp: 시작할 타임스탬프입니다. 타임스탬프(포함) 이후 커밋된 모든 테이블 변경 사항은 스트리밍 소스에서 읽을 수 있습니다. 예시:"2023-01-01 00:00:00.0". -
maxFilesPerTrigger: 각 마이크로 배치에서 고려해야 할 새 파일 수. -
maxBytesPerTrigger: 각 마이크로 배치에서 처리되는 데이터의 양. 이 옵션은 "소프트 맥스"를 설정합니다. 이는 배치가 대략 이 정도의 데이터를 처리하지만, 가장 작은 입력 단위가 이 한계보다 클 경우 스트리밍 쿼리를 진행시키기 위해 한계를 초과하여 데이터를 처리할 수도 있음을 의미합니다. -
readChangeFeed: 스트림은 공유 테이블의 변경 데이터 피드를 읽습니다.
지원되지 않는 옵션:
Trigger.availableNow
샘플 구조화된 스트리밍 쿼리
스칼라
spark.readStream.format("deltaSharing")
.option("startingVersion", 0)
.option("ignoreChanges", true)
.option("maxFilesPerTrigger", 10)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
파이썬
spark.readStream.format("deltaSharing")\
.option("startingVersion", 0)\
.option("ignoreDeletes", true)\
.option("maxBytesPerTrigger", 10000)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
삭제 벡터 또는 컬럼 매핑이 활성화된 테이블 읽기
중요한
이 기능은 공개 미리 보기 상태에 있습니다.
삭제 벡터는 귀하의 제공자가 공유 Delta 테이블에서 활성화할 수 있는 저장소 최적화 기능입니다. 삭제 벡터란 무엇입니까?을 참조하십시오.
Azure Databricks는 또한 Delta 테이블에 대한 열 매핑을 지원합니다. Delta Lake 열 매핑을 사용하여 열 이름 바꾸기 및 삭제를 참조하세요.
제공자가 삭제 벡터 또는 열 매핑이 활성화된 테이블을 공유한 경우, delta-sharing-spark 3.1 이상의 버전에서 실행 중인 컴퓨트를 사용하여 테이블을 읽을 수 있습니다. Databricks 클러스터를 사용하는 경우, Databricks Runtime 14.1 이상을 실행하는 클러스터를 통해 배치 읽기를 수행할 수 있습니다. CDF와 스트리밍 쿼리는 Databricks 런타임 14.2 이상이 필요합니다.
공유 테이블의 테이블 기능을 기반으로 자동으로 responseFormat을 해결할 수 있으므로 배치 쿼리를 있는 그대로 실행할 수 있습니다.
변경 데이터 피드(CDF)를 읽거나 삭제 벡터 또는 열 매핑이 활성화된 공유 테이블에서 스트리밍 쿼리를 수행하려면 추가 옵션 responseFormat=delta을/를 설정해야 합니다.
다음 예는 배치, CDF 및 스트리밍 쿼리를 보여줍니다.
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder()
.appName("...")
.master("...")
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
.getOrCreate()
val tablePath = "<profile-file-path>#<share-name>.<schema-name>.<table-name>"
// Batch query
spark.read.format("deltaSharing").load(tablePath)
// CDF query
spark.read.format("deltaSharing")
.option("readChangeFeed", "true")
.option("responseFormat", "delta")
.option("startingVersion", 1)
.load(tablePath)
// Streaming query
spark.readStream.format("deltaSharing").option("responseFormat", "delta").load(tablePath)
판다스: 공유 데이터를 읽다
pandas 0.25.3 이상의 공유 데이터에 액세스하려면 다음 단계를 수행합니다.
이러한 지침에서는 데이터 공급자가 공유한 자격 증명 파일에 액세스할 수 있다고 가정합니다. 오픈 공유 모델에서 액세스 얻기를 참조하십시오.
메모
Azure Databricks 워크스페이스에서 Unity Catalog가 활성화된 상태로 pandas를 사용하고 있고, import provider UI를 통해 공급자와 공유 항목을 가져왔다면, 이 섹션의 지침은 적용되지 않습니다. Unity Catalog에 등록된 다른 테이블과 마찬가지로 공유 테이블에 액세스할 수 있습니다.
delta-sharing Python 연결 프로그램을 설치하거나 자격 증명 파일의 경로를 제공할 필요가 없습니다. Azure Databricks 참조: 열린 공유 커넥터을 사용하여 공유 데이터를 읽습니다.
델타 공유 Python 커넥터 설치하기
데이터를 공유할 때 관련된 메타데이터를 액세스하려면, 예를 들어 귀하와 공유된 테이블 목록과 같은 정보를 보려면, delta-sharing Python connector를 설치해야 합니다.
pip install delta-sharing
팬더스를 사용하여 공유 테이블 목록을 작성하세요.
공유에 있는 테이블을 나열하려면 다음 명령을 실행하고, <profile-path>/config.share을 자격 증명 파일의 위치로 바꾸십시오.
import delta_sharing
client = delta_sharing.SharingClient(f"<profile-path>/config.share")
client.list_all_tables()
출력이 비어 있거나 예상한 테이블이 없는 경우 데이터 공급자에게 문의하세요.
pandas를 사용하여 공유 데이터에 액세스
Python을 사용하여 pandas의 공유 데이터에 액세스하려면 다음을 실행하여 변수를 다음과 같이 바꿉니다.
-
<profile-path>: 자격 증명 파일의 위치. -
<share-name>: 테이블의share=값입니다. -
<schema-name>: 테이블의schema=값입니다. -
<table-name>: 테이블의name=값입니다.
import delta_sharing
delta_sharing.load_as_pandas(f"<profile-path>#<share-name>.<schema-name>.<table-name>")
pandas를 사용하여 공유 변경 데이터 피드 액세스
공유 테이블의 변경 데이터 피드를 pandas에서 Python을 사용하여 액세스하려면, 변수를 다음과 같이 교체하여 아래 코드를 실행하십시오. 데이터 공급자가 테이블의 변경 데이터 피드를 공유했는지 여부에 따라 변경 데이터 피드가 제공되지 않을 수 있습니다.
-
<starting-version>: 선택 사항. 쿼리의 시작 버전, 포함된 -
<ending-version>: 선택 사항. 쿼리의 끝 버전, 포함됨. -
<starting-timestamp>: 선택 사항. 쿼리의 시작 타임스탬프. 이 항목은 이 타임스탬프보다 크거나 같은 버전으로 변환됩니다. -
<ending-timestamp>: 선택 사항. 쿼리의 종료 타임스탬프. 이 시간표 이전이나 같은 시간에 생성된 버전으로 변환됩니다.
import delta_sharing
delta_sharing.load_table_changes_as_pandas(
f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_version=<starting-version>,
ending_version=<starting-version>)
delta_sharing.load_table_changes_as_pandas(
f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_timestamp=<starting-timestamp>,
ending_timestamp=<ending-timestamp>)
출력이 비어 있거나 예상한 데이터가 없는 경우 데이터 공급자에게 문의하세요.
Power BI: 공유된 데이터 읽기
Power BI Delta Sharing 커넥터는 Delta Sharing 개방형 프로토콜을 통해 공유된 데이터 세트를 발견하고, 분석하며, 시각화할 수 있도록 합니다.
요구 사항
- Power BI Desktop 2.99.621.0 이상
- 데이터 제공자가 공유한 자격 증명 파일에 대한 액세스. 오픈 공유 모델에서 액세스 얻기를 참조하십시오.
Databricks에 연결하기
Azure Databricks에 Delta Sharing 커넥터를 사용하여 연결하려면 다음을 수행하십시오:
- 공유된 자격 증명 파일을 텍스트 편집기로 열어 엔드포인트 URL과 토큰을 검색하십시오.
- Power BI Desktop를 열어보세요.
- 데이터 가져오기 메뉴에서 Delta Sharing을 검색하세요.
- 연결기를 선택하고 Connect를 클릭하세요.
- 자격 증명 파일에서 복사한 엔드포인트 URL을 Delta Sharing Server URL 필드에 입력하세요.
- 고급 옵션 탭에서 선택적으로 행 제한을 설정하여 다운로드할 수 있는 최대 행 수를 지정하십시오. 이 값은 기본적으로 100만 행으로 설정됩니다.
- OK를 클릭합니다.
- 인증을 위해 자격 증명 파일에서 검색한 토큰을 Bearer Token에 복사하십시오.
- 연결을 클릭합니다.
Power BI Delta 공유 커넥터의 제한 사항
Power BI Delta 공유 커넥터에는 다음과 같은 제한 사항이 있습니다:
- 커넥터가 불러오는 데이터는 사용자의 기계 메모리에 맞아야 합니다. 이 요구 사항을 관리하기 위해, 커넥터는 Power BI Desktop의 고급 옵션 탭에서 설정한 행 제한으로 가져온 행 수를 제한합니다.
Tableau: 공유 데이터 읽기
Tableau Delta Sharing 커넥터를 사용하면 Delta Sharing 오픈 프로토콜을 통해 공유된 데이터셋을 발견하고, 분석하며, 시각화할 수 있습니다.
요구 사항
- Tableau Desktop 및 Tableau Server 2024.1 이상
- 데이터 제공자가 공유한 자격 증명 파일에 대한 액세스. 오픈 공유 모델에서 액세스 얻기를 참조하십시오.
Azure Databricks에 연결하기
Azure Databricks에 Delta Sharing 커넥터를 사용하여 연결하려면 다음을 수행하십시오:
- Tableau Exchange로 이동하여 지시에 따라 Delta Sharing Connector를 다운로드한 후 적절한 데스크톱 폴더에 넣으십시오.
- Tableau Desktop을 열기.
- 커넥터 페이지에서 “Delta Sharing by Databricks”를 검색하세요.
- 업로드 공유 파일을 선택하고 제공자가 공유한 인증서 파일을 선택하세요.
- 데이터 가져오기를 클릭합니다.
- 데이터 탐색기에서 테이블을 선택하세요.
- 선택적으로 SQL 필터 또는 행 제한을 추가하십시오.
- "표 데이터 가져오기"를 클릭하세요.
Tableau Delta Sharing 커넥터의 제한 사항
Tableau Delta Sharing Connector에는 다음과 같은 제한 사항이 있습니다:
- 커넥터가 불러오는 데이터는 사용자의 기계 메모리에 맞아야 합니다. 이 요구 사항을 관리하기 위해 커넥터는 가져온 행 수를 Tableau에서 설정한 행 제한으로 제한합니다.
- 모든 열은 유형
String으로 반환됩니다. - SQL 필터는 Delta Sharing 서버가 predicateHint를 지원하는 경우에만 작동합니다.
- 삭제 벡터는 지원되지 않습니다.
새 자격 증명 요청
자격 증명 활성화 URL 또는 다운로드한 자격 증명이 손실, 손상 또는 손상되었거나 공급자가 새 자격 증명을 보내지 않고 만료되는 경우 공급자에게 문의하여 새 자격 증명을 요청합니다.