XmlDataDocument 클래스는 XmlDocument의 파생 클래스이며 XML 데이터를 포함합니다. XmlDataDocument의 장점은 관계형 데이터와 계층적 데이터 간의 브리지를 제공한다는 점입니다. DataSet에 바인딩할 수 있는 XmlDocument이며 두 클래스 모두 두 클래스에 포함된 데이터에 대한 변경 내용을 동기화할 수 있습니다. DataSet에 바인딩된 XmlDocument를 사용하면 XML을 관계형 데이터와 통합할 수 있으며 데이터를 XML 또는 관계형 형식으로 나타낼 필요가 없습니다. 둘 다 수행할 수 있으며 데이터의 단일 표현으로 제한되지 않습니다.
두 보기에서 데이터를 사용할 수 있는 이점은 다음과 같습니다.
XML 문서의 구조화된 부분은 데이터 세트에 매핑하고 효율적으로 저장, 인덱싱 및 검색할 수 있습니다.
관계형으로 저장된 XML 데이터를 통해 커서 모델을 통해 변환, 유효성 검사 및 탐색을 효율적으로 수행할 수 있습니다. XML이 XmlDocument 모델에 저장되는 경우보다 관계형 구조에 대해 더 효율적으로 수행할 수 있습니다.
DataSet은 XML의 일부를 저장할 수 있습니다. 즉, XPath 또는 XslTransform 을 사용하여 해당 요소와 관심 있는 특성만 데이터 세트 에 저장할 수 있습니다. 여기에서 변경 내용을 XmlDataDocument의 더 큰 데이터로 전파하여 필터링된 더 작은 데이터 하위 집합을 변경할 수 있습니다.
SQL Server에서 DataSet 에 로드된 데이터에 대해 변환을 실행할 수도 있습니다. 또 다른 옵션은 .NET Framework 클래스 스타일 관리 WinForm 및 WebForm 컨트롤을 XML 입력 스트림에서 채워진 DataSet 에 바인딩하는 것입니다.
XmlDataDocument는 XslTransform을 지원하는 것 외에도 관계형 데이터를 XPath 쿼리 및 유효성 검사에 노출합니다. 기본적으로 모든 XML 서비스는 관계형 데이터를 통해 사용할 수 있으며, 컨트롤 바인딩, codegen 등과 같은 관계형 기능은 XML 충실도를 손상시키지 않고 XML의 구조화된 프로젝션을 통해 사용할 수 있습니다.
XmlDataDocument는 XmlDocument에서 상속되므로 W3C DOM의 구현을 제공합니다. XmlDataDocument가 관련되어 있고 데이터 하위 집합을 데이터 세트 내에 저장한다는 사실은 데이터 세트가 어떤 방식으로든 XmlDocument로의 사용을 제한하거나 변경하지 않습니다. XmlDocument를 사용하도록 작성된 코드는 XmlDataDocument에 대해 변경되지 않고 작동합니다. DataSet은 테이블, 열, 관계 및 제약 조건을 정의하여 동일한 데이터의 관계형 보기를 제공하며 독립 실행형 메모리 내 사용자 데이터 저장소입니다.
다음 그림에서는 XML 데이터가 DataSet 및 XmlDataDocument와 서로 다른 연결을 보여 줍니다.
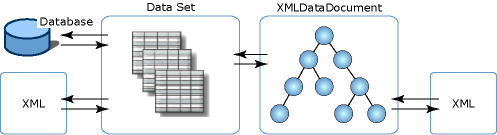
이 그림은 XML 데이터를 데이터 세트에 직접 로드할 수 있음을 보여 줍니다. 이를 통해 관계형 방식으로 XML을 직접 조작할 수 있습니다. 또는 XML을 XmlDataDocument인 DOM의 파생 클래스로 로드한 후 DataSet과 로드 및 동기화할 수 있습니다. DataSet 및 XmlDataDocument는 단일 데이터 집합을 통해 동기화되므로 한 저장소의 데이터에 대한 변경 내용이 다른 저장소에 반영됩니다.
XmlDataDocument는 XmlDocument에서 모든 편집 및 탐색 기능을 상속합니다. DataSet과 동기화된 XmlDataDocument 및 상속된 기능을 사용하는 것이 XML을 DataSet에 직접 로드하는 것보다 더 적절한 옵션인 경우가 있습니다. 다음 표에서는 DataSet을 로드하는 데 사용할 방법을 선택할 때 고려할 항목을 보여 줍니다.
| XML을 DataSet에 직접 로드하는 경우 | XmlDataDocument를 DataSet과 동기화하는 경우 |
|---|---|
| DataSet의 데이터 쿼리는 XPath보다 SQL을 사용하는 것이 더 쉽습니다. | 데이터 세트의 데이터에 대해 XPath 쿼리가 필요합니다. |
| 원본 XML에서 요소 순서를 보존하는 것은 중요하지 않습니다. | 원본 XML에서 요소 순서를 보존하는 것이 중요합니다. |
| 원본 XML에서는 요소와 서식 사이의 공백을 유지할 필요가 없습니다. | 원본 XML의 공백 및 서식 유지는 매우 중요합니다. |
데이터 세트에 직접 XML을 로드하고 쓰는 것이 요구 사항을 충족하는 경우 XML에서 데이터 세트 로드 및 데이터 세트를 XML 데이터로 쓰기를 참조하세요.
XmlDataDocument에서 DataSet을 로드하는 것이 요구 사항을 충족하는 경우 XML 문서와 데이터 세트 동기화를 참조하세요.
참고하십시오
GitHub에서 Microsoft와 공동 작업
이 콘텐츠의 원본은 GitHub에서 찾을 수 있으며, 여기서 문제와 끌어오기 요청을 만들고 검토할 수도 있습니다. 자세한 내용은 참여자 가이드를 참조하세요.
.NET