적용 대상:✅ Microsoft Fabric의 데이터 엔지니어링 및 데이터 과학
Azure Portal에서 Microsoft Fabric을 만들면 용량을 만드는 데 사용되는 구독과 연결된 패브릭 테넌트에 자동으로 추가됩니다. Microsoft Fabric에서 간소화된 설정을 사용하면 용량을 Fabric 테넌트에 연결할 필요가 없습니다. 새로 만든 용량이 관리자 설정 창에 나열되기 때문입니다. 이 구성은 관리자가 엔터프라이즈 분석 팀의 용량 설정을 시작하는 데 더 빠른 환경을 제공합니다.
용량에서 데이터 엔지니어링/데이터 과학 설정을 변경하려면 해당 용량에 대한 관리자 역할이 있어야 합니다. 사용자에게 용량에서 지정할 수 있는 역할에 대한 더 많은 정보를 보려면 용량의 역할을 참조하세요.
다음 단계를 사용하여 Microsoft Fabric 용량에 대한 데이터 엔지니어링/과학 설정을 관리합니다.
설정 옵션을 선택하여 Fabric 계정의 설정 창을 엽니다. 거버넌스 및 인사이트 섹션에서 관리 포털 을 선택합니다.

용량 설정 옵션을 선택하여 메뉴를 확장하고 패브릭 용량 탭을 선택합니다. 여기에 테넌트에서 만든 용량이 표시됩니다. 구성하려는 용량을 선택합니다.
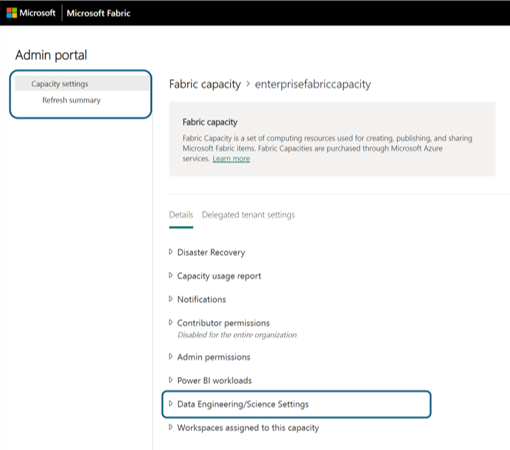
용량 세부 정보 창으로 이동하여 용량에 대한 사용량 및 기타 관리자 컨트롤을 볼 수 있습니다. 데이터 엔지니어링/데이터 과학 설정 섹션으로 이동하고 Spark 컴퓨팅 열기를 선택합니다. 다음 매개 변수를 구성합니다.


참고
패브릭 용량 관리 포털에서 데이터 엔지니어링/과학 설정을 탐색하려면 하나 이상의 작업 영역을 패브릭 용량에 연결해야 합니다.
관리자 제어: 시작 풀 사용 안 함
이제 용량 관리자는 용량에 연결된 작업 영역에서 시작 풀 사용을 사용하지 않도록 선택할 수 있습니다. 사용하지 않도록 설정하면 사용자 및 작업 영역 관리자는 더 이상 시작 풀을 컴퓨팅 옵션으로 볼 수 없습니다. 대신 용량 관리자가 명시적으로 만들고 관리하는 사용자 지정 풀을 사용해야 합니다.
이 기능은 컴퓨팅 사용량에 대한 중앙 집중식 거버넌스를 제공하여 컴퓨팅 크기 조정, 비용 및 일정 동작을 보다 엄격하게 제어할 수 있도록 합니다.
팁 (조언)
이 설정은 컴퓨팅 패턴을 표준화하고 기본 시작 풀을 통해 임의 소비를 방지하려는 대규모 조직에서 특히 유용합니다.
관리자 제어: 작업 수준 버스팅 스위치
Microsoft Fabric은 Spark VCore에 대해 3× 버스팅을 지원하므로 단일 작업에서 기본 용량이 제공하는 것보다 더 많은 컴퓨팅 코어를 일시적으로 사용할 수 있습니다. 이렇게 하면 전체 용량 사용률을 허용하여 활동 버스트 중에 작업 성능이 향상됩니다.
용량 관리자는 이제 관리 포털에서 사용할 수 있는 "작업 수준 버스팅 사용 안 함" 스위치를 사용하여 이 동작을 제어할 수 있습니다.
위치:
Admin Portal → Capacity Settings → [Select Capacity] → Data Engineering/Science Settings → Spark Compute동작:
- 사용(기본값): 단일 Spark 작업은 전체 버스트 제한(최대 3× Spark VCore)을 사용할 수 있습니다.
- 사용 안 함: 개별 Spark 작업은 기본 용량 할당에 제한되어 동시성을 유지하고 독점을 방지합니다.
참고
이 스위치는 패브릭 용량에서 Spark 작업을 실행하는 경우에만 사용할 수 있습니다. 자동 크기 조정 청구 옵션을 사용하는 경우 다음 때문에 이 스위치가 자동으로 비활성화됩니다.
- 자동 크기 조정 청구는 순수 사용량 기반 요금제를 따릅니다.
- 사용 버스트를 허용하고 이를 24시간 동안 균형 있게 조절할 수 있는 스무딩 창이 없습니다.
- 버스팅은 주문형 자동 크기 조정 컴퓨팅이 아닌 예약된 용량의 기능입니다.
사용 사례 및 예제
| 시나리오 | 설정 | 행동 |
|---|---|---|
| 무거운 ETL 워크로드 | 버스팅 활성화 (기본값) | 작업은 전체 버스트 용량을 사용할 수 있습니다. 예를 들어, F64에서 384개의 Spark VCore를 사용할 수 있습니다. |
| 다중 사용자 대화형 전자 필기장 | 버스팅 사용 안 함 | 작업 사용량이 제한되어(예: F64의 Spark VCore 128개) 동시성이 향상됩니다. |
| 자동 크기 조정 청구 기능이 활성화되었습니다. | 버스팅 컨트롤 을 사용할 수 없음 | 모든 Spark 사용량은 주문형으로 청구됩니다. 기본 용량을 초과하여 사용되지 않습니다. |
팁 (조언)
이 스위치를 사용하여 처리량 또는 동시성을 최적화합니다.
- 대규모 작업 및 파이프라인에 대해 버스팅을 사용하도록 설정합니다.
- 많은 사용자가 있는 대화형 또는 공유 환경에 대해 사용하지 않도록 설정합니다.
Microsoft Fabric의 데이터 엔지니어링 및 데이터 과학용 용량 풀
Spark 설정의 풀 목록 섹션에서 추가 를 클릭하여 패브릭 용량에 대한 사용자 지정 풀 을 만듭니다.
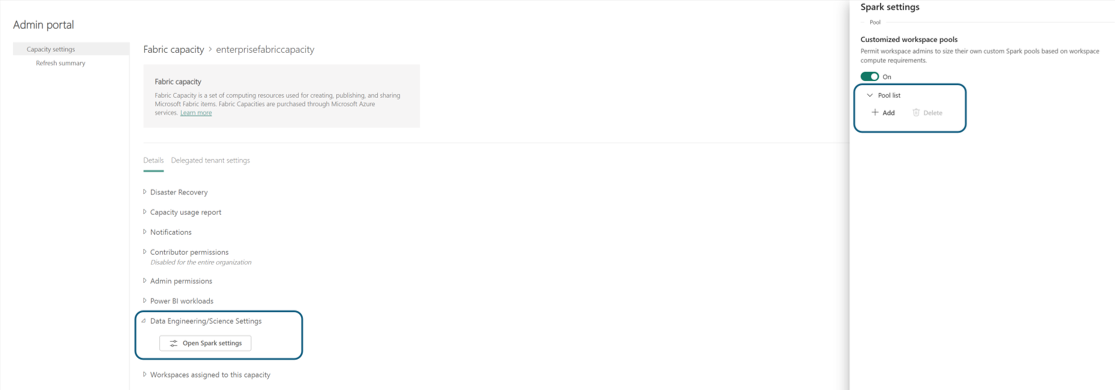
풀 만들기 페이지로 이동하여 다음을 수행할 수 있습니다.
- 풀 이름 지정
- 노드 패밀리 및 노드 크기 선택
- 최소 및 최대 노드 설정
- 실행기의 자동 크기 조정 및 동적 할당 사용/사용 안 함

만들기를 선택하여 설정을 저장합니다.




참고
용량 수준 사용자 지정 풀의 시작 대기 시간은 2~3분입니다. 더 빠른 Spark 세션 시작(<5초)을 위해 활성화된 경우 시작 풀을 사용합니다.
생성되면 다음에서 용량 풀을 사용할 수 있게 됩니다.
- 작업 영역 설정의 풀 선택 드롭다운
- 작업 영역의 환경 컴퓨팅 설정 페이지


이렇게 하면 중앙 집중식 컴퓨팅 거버넌스가 가능합니다. 관리자는 표준화된 풀을 만들고 필요에 따라 작업 영역 수준 사용자 지정을 사용하지 않도록 설정하여 작업 영역의 관리자가 풀 설정을 수정하거나 직접 만들지 못하게 할 수 있습니다.

