딥 러닝
딥 러닝 은 인간의 뇌가 배우는 방식을 에뮬레이트하려는 고급 형태의 기계 학습입니다. 딥 러닝의 핵심은 여기에 표시된 것처럼 수학적 기능을 사용하여 생물학적 뉴런에서 전기 화학 활동을 시뮬레이션하는 인공 신경망 을 만드는 것입니다.
| 생물학적 신경망 | 인공 신경망 |
|---|---|

|

|
| 신경은 전기 화학 자극에 반응하여 발사됩니다. 실행되면 신호가 연결된 뉴런에 전달됩니다. | 각 뉴런은 입력 값(x) 및 가중치 (w)에서 작동하는 함수입니다. 함수는 출력을 전달할지 여부를 결정하는 활성화 함수로 래핑됩니다. |
인공 신경망은 여러 층 의 뉴런으로 구성되며, 본질적으로 심층적으로 중첩된 기능을 정의합니다. 이 아키텍처는 이 기술을 딥 러닝 이라고 하며 이 기술을 통해 생성된 모델을 DNN( 심층 신경망 )이라고도 합니다. 회귀 및 분류를 비롯한 다양한 종류의 기계 학습 문제뿐만 아니라 자연어 처리 및 컴퓨터 비전을 위한 보다 전문화된 모델에 심층 신경망을 사용할 수 있습니다.
이 모듈에서 설명하는 다른 기계 학습 기술과 마찬가지로 딥 러닝에는 하나 이상의 기능(x)의 값을 기반으로 레이블(y)을 예측할 수 있는 함수에 학습 데이터를 맞추는 작업이 포함됩니다. 함수(f(x))는 신경망의 각 계층이 x 에서 작동하는 함수와 연결된 가중치(w) 값을 캡슐화하는 중첩 함수의 외부 계층입니다. 모델을 학습하는 데 사용되는 알고리즘에는 계층을 통해 학습 데이터의 기능 값(x)을 반복적으로 공급하여 1에 대한 출력 값을 계산하고, 모델의 유효성을 검사하여 계산된 값 이 알려진 y 값에서 얼마나 멀리 떨어져 있는지 평가합니다(모델의 오류 또는 손실 수준을 정량화함). 그런 다음 손실을 줄이기 위해 가중치(w)를 수정합니다. 학습된 모델에는 가장 정확한 예측을 생성하는 최종 가중치 값이 포함됩니다.
예제 - 분류에 딥 러닝 사용
심층 신경망 모델이 작동하는 방식을 더 잘 이해하기 위해 신경망을 사용하여 펭귄 종에 대한 분류 모델을 정의하는 예제를 살펴보겠습니다.

기능 데이터(x)는 펭귄의 일부 측정값으로 구성됩니다. 구체적인 측정값은 다음과 같습니다.
- 펭귄 청구서 길이
- 펭귄 청구서 깊이
- 펭귄 플리퍼의 길이입니다.
- 펭귄 가중치
이 경우 x 는 4개의 값 또는 수학적으로 x=[x1,x2,x3,x4]의 벡터입니다.
우리가 예측하려고하는 레이블 (y)은 펭귄의 종이며 세 가지 가능한 종일 수 있습니다.
- 아델리 ()
- 젠투
- 친스트랩(Chinstrap)
이는 기계 학습 모델이 관찰이 속한 가장 가능성이 큰 클래스를 예측해야 하는 분류 문제의 예입니다. 분류 모델은 각 클래스에 대한 확률로 구성된 레이블을 예측하여 이 작업을 수행합니다. 즉, y는 확률 값이 세 개인 벡터입니다. 가능한 각 클래스에 대해 하나씩 : [P(y=0|x), P(y=1|x), P(y=2|x)].
이 네트워크를 사용하여 예측된 펭귄 클래스를 유추하는 프로세스는 다음과 같습니다.
- 펭귄 관찰을 위한 기능 벡터는 각 x 값에 대한 뉴런으로 구성된 신경망의 입력 계층으로 공급됩니다. 이 예제에서는 다음 x 벡터가 입력으로 사용됩니다 . [37.3, 16.8, 19.2, 30.0]
- 뉴런의 첫 번째 계층에 대한 함수는 각각 x 값과 w 가중치를 결합하여 가중치 합계를 계산하고, 다음 계층에 전달될 임계값을 충족하는지 여부를 결정하는 활성화 함수에 전달합니다.
- 계층의 각 뉴런은 다음 계층의 모든 뉴런에 연결되므로(아키텍처가 완전히 연결된 네트워크라고도 함) 각 계층의 결과가 출력 계층에 도달할 때까지 네트워크를 통해 전달됩니다.
- 출력 계층은 값의 벡터를 생성합니다. 이 경우 softmax 또는 유사한 함수를 사용하여 펭귄의 세 가지 가능한 클래스에 대한 확률 분포를 계산합니다. 이 예제에서 출력 벡터는 [0.2, 0.7, 0.1]입니다.
- 벡터의 요소는 클래스 0, 1 및 2의 확률을 나타냅니다. 두 번째 값은 가장 높으므로 모델은 펭귄의 종은 1 (젠투)임을 예측합니다.
신경망은 어떻게 학습하나요?
신경망의 가중치는 레이블에 대한 예측 값을 계산하는 방법의 중심입니다. 학습 프로세스 중에 모델은 가장 정확한 예측을 생성할 가중치를 학습 합니다. 이 학습이 어떻게 진행되는지 이해하기 위해 학습 프로세스를 좀 더 자세히 살펴보겠습니다.
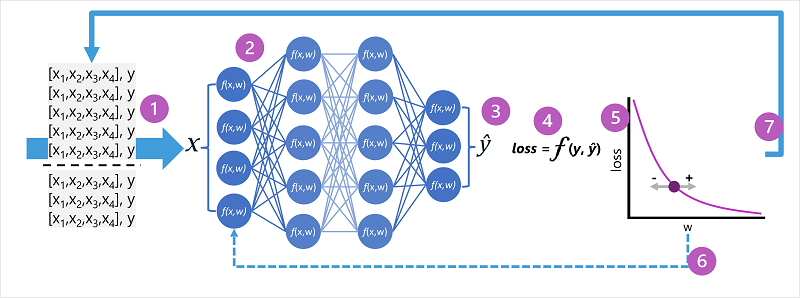
- 학습 및 유효성 검사 데이터 세트가 정의되고 학습 기능이 입력 계층에 공급됩니다.
- 네트워크의 각 계층에 있는 뉴런은 해당 가중치(처음에 임의로 할당됨)를 적용하고 네트워크를 통해 데이터를 공급합니다.
- 출력 계층은 ŷ에 대한 계산된 값을 포함하는 벡터를 생성합니다. 예를 들어 펭귄 클래스 예측의 출력은 [0.3]일 수 있습니다. 0.1. 0.6].
- 손실 함수는 예측된 값을 알려진 y 값과 비교하고 차이를 집계하는 데 사용됩니다(손실이라고 함). 예를 들어 이전 단계에서 출력을 반환한 사례에 대해 알려진 클래스가 Chinstrap인 경우 y 값은 [0.0, 0.0, 1.0]이어야 합니다. 이와 ŷ 벡터 간의 절대 차이는 [0.3, 0.1, 0.4]입니다. 실제로 손실 함수는 여러 사례에 대한 집계 분산을 계산하고 단일 손실 값으로 요약합니다.
- 전체 네트워크는 기본적으로 하나의 큰 중첩 함수이므로 최적화 함수는 차등 미적분을 사용하여 손실에 대한 네트워크의 각 가중치의 영향을 평가하고 전체 손실의 양을 줄이기 위해 조정(위 또는 아래로)할 수 있는 방법을 결정할 수 있습니다. 특정 최적화 기술은 다를 수 있지만 일반적으로 손실을 최소화하기 위해 각 가중치를 늘리거나 줄이는 그라데이션 하강 방식을 포함합니다.
- 가중치 변경 내용은 네트워크의 계층에 백프로파일되어 이전에 사용된 값을 대체합니다.
- 이 프로세스는 손실이 최소화되고 모델이 허용 가능한 정확하게 예측될 때까지 여러 반복( epoch라고 함)을 통해 반복됩니다.
비고
한 번에 하나씩 네트워크를 통해 전달되는 학습 데이터의 각 사례를 쉽게 생각할 수 있지만 실제로 데이터는 행렬로 일괄 처리되고 선형 대수 계산을 사용하여 처리됩니다. 이러한 이유로 신경망 학습은 벡터 및 행렬 조작에 최적화된 GPU(그래픽 처리 장치)가 있는 컴퓨터에서 가장 잘 수행됩니다.