Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Você pode inspecionar a qualidade de reconhecimento de um modelo de fala personalizado. Você pode reproduzir o áudio carregado e determinar se o resultado de reconhecimento fornecido está correto. Depois que um teste for criado com êxito, você poderá ver como um modelo transcreveu o conjunto de dados de áudio ou comparar os resultados de dois modelos lado a lado.
O teste de modelo lado a lado é útil para validar qual modelo de reconhecimento de fala é melhor para um aplicativo. Para obter uma medida objetiva de precisão, que requer a entrada de conjuntos de dados de transcrição, consulte Modelo de teste quantitativamente.
Importante
Durante o teste, o sistema realizará uma transcrição. É importante ter isso em mente, pois o preço varia de acordo com a oferta de serviço e o nível de assinatura. Consulte sempre o preço oficial dos serviços de IA do Azure para os detalhes mais recentes.
Criar um teste
Depois de carregar conjuntos de dados de treinamento e teste, você pode criar um teste.
Para testar seu modelo de fala personalizado ajustado, siga estas etapas:
Entre no portal da Fábrica de IA do Azure.
Selecione Ajuste fino no painel esquerdo e selecione Ajuste fino do Serviço de IA.
Selecione a tarefa de ajuste fino de fala personalizada (por nome do modelo) que você iniciou conforme descrito no artigo sobre como iniciar o ajuste fino de fala personalizada.
Selecione Testar modelos>+ Criar teste.

No assistente Criar um novo teste, selecione o tipo de teste. Para um teste de qualidade, selecione Inspecionar qualidade (dados somente áudio). Em seguida, selecione Avançar.
Selecione os dados que você deseja usar para teste. Em seguida, selecione Avançar.
Selecione até dois modelos para avaliar e comparar a precisão. Neste exemplo, selecionamos o modelo que treinamos e o modelo base. Em seguida, selecione Avançar.

Insira um nome e uma descrição para o teste. Em seguida, selecione Avançar.
Examine as configurações e selecione Criar teste. Você será levado de volta à página Testar modelos. O status dos dados é Processamento.


Siga estas instruções para criar um teste:
Entre no Speech Studio.
Navegue até Speech Studio>Fala personalizada e selecione o nome do projeto na lista.
Selecione Modelos de teste>Criar teste.
Escolha Inspecionar qualidade (dados somente de áudio)>Avançar.
Escolha um conjunto de dados de áudio que deseja usar para teste e selecione Avançar. Se não houver conjuntos de dados disponíveis, cancele a instalação e vá para o menu Conjuntos de dados de fala para carregar conjuntos de dados.

Escolha um ou dois modelos para avaliar e comparar a precisão.
Insira o nome do teste e a descrição e selecione Avançar.
Examine as configurações e selecione Salvar e fechar.
Antes de continuar, verifique se você tem a CLI de Fala instalada e configurada.
Para criar um teste, use o spx csr evaluation createcomando. Crie os parâmetros de solicitação de acordo com as seguintes instruções:
- Defina a
projectpropriedade como a ID de um projeto existente. A propriedadeprojecté recomendada para que você também possa gerenciar o ajuste fino da fala personalizada no portal da Fábrica de IA do Azure. Para obter a ID do projeto, consulte Obter a ID do projeto para a documentação da API REST . - Defina a propriedade necessária
model1para a ID de um modelo que você deseja testar. - Defina a propriedade necessária
model2para a ID de outro modelo que você deseja testar. Se você não quiser comparar dois modelos, use o mesmo modelo para ambosmodel1emodel2. - Defina a propriedade necessária
datasetpara a ID de um conjunto de dados que você deseja usar para o teste. - Caso não defina a propriedade
language, a CLI de Fala definirá "en-US" por padrão. Esse parâmetro deve ser a localidade dos conteúdos do conjunto de dados. O local não pode ser alterado posteriormente. A propriedadelanguageda CLI de Fala corresponde à propriedadelocalena solicitação e na resposta JSON. - Defina a propriedade
namenecessária. Esse parâmetro é o nome exibido no portal do Azure AI Foundry. A propriedadenameda CLI de Fala corresponde à propriedadedisplayNamena solicitação e na resposta JSON.
Aqui está um exemplo de comando da CLI de Fala que cria um teste:
spx csr evaluation create --api-version v3.2 --project aaaabbbb-0000-cccc-1111-dddd2222eeee --dataset bbbbcccc-1111-dddd-2222-eeee3333ffff --model1 ccccdddd-2222-eeee-3333-ffff4444aaaa --model2 ccccdddd-2222-eeee-3333-ffff4444aaaa --name "My Inspection" --description "My Inspection Description"
Importante
Você deve definir --api-version v3.2. A CLI de Fala usa a API REST, mas ainda não dá suporte a versões posteriores v3.2.
Você deve receber um corpo de resposta no seguinte formato:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/ddddeeee-3333-ffff-4444-aaaa5555bbbb",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/ccccdddd-2222-eeee-3333-ffff4444aaaa"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/ccccdddd-2222-eeee-3333-ffff4444aaaa"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/bbbbcccc-1111-dddd-2222-eeee3333ffff"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/eeeeffff-4444-aaaa-5555-bbbb6666cccc"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/eeeeffff-4444-aaaa-5555-bbbb6666cccc"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/aaaabbbb-0000-cccc-1111-dddd2222eeee"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": -1.0,
"sentenceErrorRate1": -1.0,
"sentenceCount1": -1,
"wordCount1": -1,
"correctWordCount1": -1,
"wordSubstitutionCount1": -1,
"wordDeletionCount1": -1,
"wordInsertionCount1": -1,
"wordErrorRate2": -1.0,
"sentenceErrorRate2": -1.0,
"sentenceCount2": -1,
"wordCount2": -1,
"correctWordCount2": -1,
"wordSubstitutionCount2": -1,
"wordDeletionCount2": -1,
"wordInsertionCount2": -1
},
"lastActionDateTime": "2024-07-14T21:21:39Z",
"status": "NotStarted",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
A propriedade de nível superiorself no corpo da resposta é o URI da avaliação. Use esse URI para obter detalhes sobre o projeto e os resultados do teste. Você também usa esse URI para atualizar ou excluir a avaliação.
Para obter ajuda da Speech CLI com avaliações, execute o seguinte comando:
spx help csr evaluation
Para criar um teste, use a operação Evaluations_Create da API REST de Conversão de fala em texto . Construa o corpo da solicitação de acordo com as seguintes instruções:
- Defina a
projectpropriedade como a ID de um projeto existente. A propriedadeprojecté recomendada para que você também possa gerenciar o ajuste fino da fala personalizada no portal da Fábrica de IA do Azure. Para obter a ID do projeto, consulte Obter a ID do projeto para a documentação da API REST . - Configure a
model1propriedade necessária para o URI de um modelo que você deseja testar. - Defina a
model2propriedade necessária para o URI de outro modelo que você deseja testar. Se você não quiser comparar dois modelos, use o mesmo modelo para ambosmodel1emodel2. - Defina a
datasetpropriedade necessária para o URI de um conjunto de dados que você deseja usar para o teste. - Defina a propriedade
localenecessária. Essa propriedade deve ser a localidade dos conteúdos do conjunto de dados. O local não pode ser alterado posteriormente. - Defina a propriedade
displayNamenecessária. Essa propriedade é o nome exibido no portal do Azure AI Foundry.
Faça uma solicitação HTTP POST usando o URI, conforme mostrado no exemplo a seguir. Substitua YourSpeechResoureKey pela chave de recurso de Fala, substitua YourServiceRegion pela sua região do recurso de Fala e defina as propriedades do corpo da solicitação, conforme descrito anteriormente.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourSpeechResoureKey" -H "Content-Type: application/json" -d '{
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/ccccdddd-2222-eeee-3333-ffff4444aaaa"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/ccccdddd-2222-eeee-3333-ffff4444aaaa"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/bbbbcccc-1111-dddd-2222-eeee3333ffff"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/aaaabbbb-0000-cccc-1111-dddd2222eeee"
},
"displayName": "My Inspection",
"description": "My Inspection Description",
"locale": "en-US"
}' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations"
Você deve receber um corpo de resposta no seguinte formato:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/ddddeeee-3333-ffff-4444-aaaa5555bbbb",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/ccccdddd-2222-eeee-3333-ffff4444aaaa"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/ccccdddd-2222-eeee-3333-ffff4444aaaa"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/bbbbcccc-1111-dddd-2222-eeee3333ffff"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/eeeeffff-4444-aaaa-5555-bbbb6666cccc"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/eeeeffff-4444-aaaa-5555-bbbb6666cccc"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/aaaabbbb-0000-cccc-1111-dddd2222eeee"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": -1.0,
"sentenceErrorRate1": -1.0,
"sentenceCount1": -1,
"wordCount1": -1,
"correctWordCount1": -1,
"wordSubstitutionCount1": -1,
"wordDeletionCount1": -1,
"wordInsertionCount1": -1,
"wordErrorRate2": -1.0,
"sentenceErrorRate2": -1.0,
"sentenceCount2": -1,
"wordCount2": -1,
"correctWordCount2": -1,
"wordSubstitutionCount2": -1,
"wordDeletionCount2": -1,
"wordInsertionCount2": -1
},
"lastActionDateTime": "2024-07-14T21:21:39Z",
"status": "NotStarted",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
A propriedade de nível superiorself no corpo da resposta é o URI da avaliação. Use esse URI para obter detalhes sobre o projeto de avaliação e os resultados do teste. Você também usa esse URI para atualizar ou excluir a avaliação.
Obter resultados do teste
Você deve obter os resultados do teste e inspecionar os conjuntos de dados de áudio em comparação com os resultados da transcrição de cada modelo.
Quando o status do teste for Bem-sucedido, você poderá exibir os resultados. Selecione o teste para exibir os resultados.
Siga estas etapas para obter resultados de teste:
- Entre no Speech Studio.
- Selecione Fala personalizada> Nome do projeto >Testar modelos.
- Selecione o link pelo nome do teste.
- Depois que o teste for concluído, conforme indicado pelo conjunto de status como Bem-sucedido, você deverá ver os resultados que incluem o número WER para cada modelo testado.
Essa página lista todos os enunciados no conjunto de dados e os resultados de reconhecimento, junto com a transcrição do conjunto de dados enviado. Você pode alternar vários tipos de erro, incluindo inserção, exclusão e substituição. Ao ouvir o áudio e comparar os resultados de reconhecimento em cada coluna, decida qual modelo atende às suas necessidades e determine se são necessários mais aprimoramentos e treinamento.
Antes de continuar, verifique se você tem a CLI de Fala instalada e configurada.
Para obter resultados de teste, use o spx csr evaluation status comando. Crie os parâmetros de solicitação de acordo com as seguintes instruções:
- Defina a propriedade
evaluationnecessária como o ID da avaliação da qual você deseja obter resultados de teste.
Veja um exemplo de comando da CLI de Fala que obtém os resultados do teste:
spx csr evaluation status --api-version v3.2 --evaluation ddddeeee-3333-ffff-4444-aaaa5555bbbb
Importante
Você deve definir --api-version v3.2. A CLI de Fala usa a API REST, mas ainda não dá suporte a versões posteriores v3.2.
Os modelos, conjunto de dados de áudio, transcrições e mais detalhes são retornados no corpo da resposta.
Você deve receber um corpo de resposta no seguinte formato:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/ddddeeee-3333-ffff-4444-aaaa5555bbbb",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/ccccdddd-2222-eeee-3333-ffff4444aaaa"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/ccccdddd-2222-eeee-3333-ffff4444aaaa"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/bbbbcccc-1111-dddd-2222-eeee3333ffff"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/eeeeffff-4444-aaaa-5555-bbbb6666cccc"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/eeeeffff-4444-aaaa-5555-bbbb6666cccc"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/aaaabbbb-0000-cccc-1111-dddd2222eeee"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": 0.028900000000000002,
"sentenceErrorRate1": 0.667,
"tokenErrorRate1": 0.12119999999999999,
"sentenceCount1": 3,
"wordCount1": 173,
"correctWordCount1": 170,
"wordSubstitutionCount1": 2,
"wordDeletionCount1": 1,
"wordInsertionCount1": 2,
"tokenCount1": 165,
"correctTokenCount1": 145,
"tokenSubstitutionCount1": 10,
"tokenDeletionCount1": 1,
"tokenInsertionCount1": 9,
"tokenErrors1": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
},
"wordErrorRate2": 0.028900000000000002,
"sentenceErrorRate2": 0.667,
"tokenErrorRate2": 0.12119999999999999,
"sentenceCount2": 3,
"wordCount2": 173,
"correctWordCount2": 170,
"wordSubstitutionCount2": 2,
"wordDeletionCount2": 1,
"wordInsertionCount2": 2,
"tokenCount2": 165,
"correctTokenCount2": 145,
"tokenSubstitutionCount2": 10,
"tokenDeletionCount2": 1,
"tokenInsertionCount2": 9,
"tokenErrors2": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
}
},
"lastActionDateTime": "2024-07-14T21:22:45Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
Para obter ajuda da Speech CLI com avaliações, execute o seguinte comando:
spx help csr evaluation
Para obter os resultados do teste, comece usando a operação Evaluations_Get da API REST de Conversão de fala em texto.
Faça uma solicitação HTTP GET usando o URI, conforme mostrado no exemplo a seguir. Substitua YourEvaluationId por sua ID de avaliação, substitua YourSpeechResoureKey pela sua chave de recurso de Fala e substitua YourServiceRegion pela sua região de recurso de Fala.
curl -v -X GET "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/YourEvaluationId" -H "Ocp-Apim-Subscription-Key: YourSpeechResoureKey"
Os modelos, conjunto de dados de áudio, transcrições e mais detalhes são retornados no corpo da resposta.
Você deve receber um corpo de resposta no seguinte formato:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/ddddeeee-3333-ffff-4444-aaaa5555bbbb",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/ccccdddd-2222-eeee-3333-ffff4444aaaa"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/ccccdddd-2222-eeee-3333-ffff4444aaaa"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/bbbbcccc-1111-dddd-2222-eeee3333ffff"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/eeeeffff-4444-aaaa-5555-bbbb6666cccc"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/eeeeffff-4444-aaaa-5555-bbbb6666cccc"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/aaaabbbb-0000-cccc-1111-dddd2222eeee"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": 0.028900000000000002,
"sentenceErrorRate1": 0.667,
"tokenErrorRate1": 0.12119999999999999,
"sentenceCount1": 3,
"wordCount1": 173,
"correctWordCount1": 170,
"wordSubstitutionCount1": 2,
"wordDeletionCount1": 1,
"wordInsertionCount1": 2,
"tokenCount1": 165,
"correctTokenCount1": 145,
"tokenSubstitutionCount1": 10,
"tokenDeletionCount1": 1,
"tokenInsertionCount1": 9,
"tokenErrors1": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
},
"wordErrorRate2": 0.028900000000000002,
"sentenceErrorRate2": 0.667,
"tokenErrorRate2": 0.12119999999999999,
"sentenceCount2": 3,
"wordCount2": 173,
"correctWordCount2": 170,
"wordSubstitutionCount2": 2,
"wordDeletionCount2": 1,
"wordInsertionCount2": 2,
"tokenCount2": 165,
"correctTokenCount2": 145,
"tokenSubstitutionCount2": 10,
"tokenDeletionCount2": 1,
"tokenInsertionCount2": 9,
"tokenErrors2": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
}
},
"lastActionDateTime": "2024-07-14T21:22:45Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
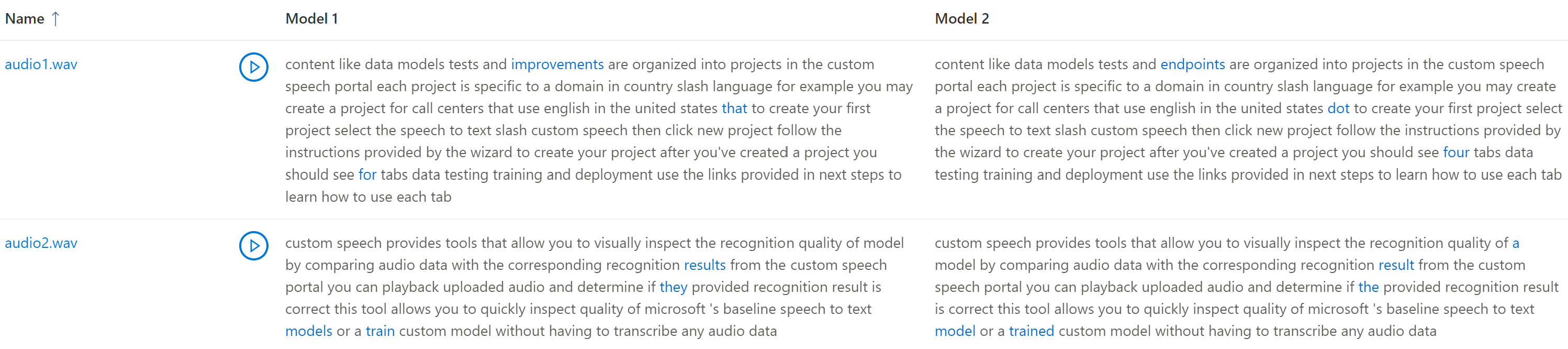
Comparar transcrição com áudio
Você pode inspecionar a saída de transcrição de cada modelo testado, em relação ao conjunto de dados de entrada de áudio. Se você incluiu dois modelos no teste, pode comparar a qualidade de transcrição deles lado a lado.
Para revisar a qualidade das transcrições:
- Entre no Speech Studio.
- Selecione Fala personalizada> Nome do projeto >Testar modelos.
- Selecione o link pelo nome do teste.
- Reproduza um arquivo de áudio enquanto lê a transcrição correspondente por um modelo.
Se o conjunto de dados de teste incluir vários arquivos de áudio, você verá várias linhas na tabela. Se você incluiu dois modelos no teste, as transcrições são mostradas em colunas lado a lado. As diferenças de transcrição entre os modelos são mostradas em fonte de texto azul.
Antes de continuar, verifique se você tem a CLI de Fala instalada e configurada.
O conjunto de dados de teste de áudio, transcrições e modelos testados são retornados nos resultados do teste. Se apenas um modelo tiver sido testado, o valor model1 corresponderá a model2, e o valor transcription1 corresponderá a transcription2.
Para revisar a qualidade das transcrições:
- Baixe o conjunto de dados de teste de áudio, a menos que você já tenha uma cópia.
- Baixe as transcrições de saída.
- Reproduza um arquivo de áudio enquanto lê a transcrição correspondente por um modelo.
Se você estiver comparando a qualidade entre dois modelos, preste atenção especial às diferenças entre as transcrições de cada modelo.
O conjunto de dados de teste de áudio, transcrições e modelos testados são retornados nos resultados do teste. Se apenas um modelo tiver sido testado, o valor model1 corresponderá a model2, e o valor transcription1 corresponderá a transcription2.
Para revisar a qualidade das transcrições:
- Baixe o conjunto de dados de teste de áudio, a menos que você já tenha uma cópia.
- Baixe as transcrições de saída.
- Reproduza um arquivo de áudio enquanto lê a transcrição correspondente por um modelo.
Se você estiver comparando a qualidade entre dois modelos, preste atenção especial às diferenças entre as transcrições de cada modelo.