Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
O Azure Monitor para Azure Cosmos DB fornece uma exibição de métricas para monitorar sua conta e criar painéis. As métricas do Azure Cosmos DB são coletadas por padrão. Esse recurso não exige que você habilite ou configure nada explicitamente.
Definição de métrica
O consumo normalizado de RU é uma métrica entre 0% a 100% usada para ajudar a medir a utilização da taxa de transferência provisionada em um banco de dados ou contêiner. A métrica é emitida em intervalos de 1 minuto e é definida como a utilização máxima de unidades de solicitação por segundo (RU/s) em todos os intervalos de chaves de partição durante o intervalo de tempo. Cada intervalo de chaves de partição é mapeado para uma partição física e é atribuído para manter dados para um intervalo de valores de hash possíveis. Em geral, quanto maior a porcentagem de RU normalizado, mais você utilizou sua taxa de transferência provisionada. A métrica também pode ser usada para exibir a utilização de intervalos de chaves de partição individuais em um banco de dados ou contêiner.
Por exemplo, suponha que você tenha um contêiner onde você define a taxa de transferência máxima de dimensionamento automático de 20.000 RU/s (dimensionado entre 2000 e 20.000 RU/s) e você tem dois intervalos de chaves de partição (partições físicas) P1 e P2. Como o Azure Cosmos DB distribui a taxa de transferência provisionada igualmente em todos os intervalos de chaves de partição, P1 e P2 podem ser dimensionados entre 1000 e 10.000 RU/s. Suponha que em um intervalo de 1 minuto, em um determinado segundo, p1 consumiu 6.000 RUs e P2 consumiu 8.000 RUs. O consumo normalizado de RU de P1 é de 60% e 80% para P2. O consumo geral de RU normalizado de todo o contêiner é de MAX(60%, 80%) = 80%.
Se você estiver interessado em ver o consumo da unidade de solicitação em um intervalo por segundo, juntamente com o tipo de operação, poderá usar os logs de diagnóstico do recurso opcional e consultar a tabela PartitionKeyRUConsumption. Para obter uma visão geral de alto nível das operações e do código de status que seu aplicativo está executando no recurso do Azure Cosmos DB, você pode usar a métrica interna de Solicitações Totais do Azure Monitor (API para NoSQL), Solicitações do Mongo, Solicitações do Gremlin ou Solicitações do Cassandra . Posteriormente, você pode filtrar essas solicitações pelo código de status 429 e dividi-las por Tipo de Operação.
O que esperar e fazer quando RU/s normalizadas for maior
Quando o consumo normalizado de RU atingir 100% para determinado intervalo de chaves de partição e se um cliente ainda fizer solicitações nessa janela de tempo de 1 segundo para esse intervalo de chaves de partição específico, ele receberá um erro de taxa limitada (429).
Isso não significa necessariamente que haja um problema com seu recurso. Por padrão, os SDKs de cliente do Azure Cosmos DB e as ferramentas de importação de dados, como o Azure Data Factory e a biblioteca de execução em massa, repetem as solicitações automaticamente em casos de resposta 429. Eles são repetidos normalmente até nove vezes. Como resultado, embora você possa ver códigos 429 nas métricas, esses erros podem até não ter sido retornados ao seu aplicativo.
Em geral, para uma carga de trabalho de produção, se você vir entre 1-5% das solicitações com erros 429, e a latência de ponta a ponta for aceitável, esse é um sinal saudável de que as RU/s estão sendo utilizadas em sua totalidade. Nesse caso, a métrica de consumo de RU normalizado atingindo 100% significa apenas que, em um determinado segundo, pelo menos um intervalo de chaves de partição usou toda a taxa de transferência provisionada. Isso é aceitável porque a taxa global de 429s ainda é baixa. Nenhuma ação adicional é necessária.
Para determinar qual porcentagem de suas solicitações ao seu banco de dados ou contêiner resultou em 429s, a partir de sua conta do Azure Cosmos DB, navegue até Insights>Solicitações>Total de Solicitações por Código de Status. Filtre para um banco de dados e contêiner específicos. Para a API do Gremlin, use a métrica Solicitações do Gremlin.

Se a métrica de consumo de RU normalizado for consistentemente 100% entre vários intervalos de chaves de partição e a taxa de 429s for maior que 5%, é recomendável aumentar a taxa de transferência. Você pode descobrir quais operações são pesadas e o uso de pico delas utilizando as métricas do Azure Monitor e os logs de diagnóstico do Azure Monitor. Para saber mais sobre as práticas recomendadas, consulte As práticas recomendadas para dimensionar a taxa de transferência provisionada (RU/s).
Nem sempre você verá o erro 429 de limitação da taxa apenas porque a RU normalizada atingiu 100%. Isso ocorre porque a RU normalizada é um único valor que representa o uso máximo em todos os intervalos de chaves de partição. Um intervalo de chaves de partição pode estar ocupado, mas os outros intervalos de chaves de partição podem atender solicitações sem problemas. Por exemplo, uma única operação, como um procedimento armazenado que consome todas as RU/s em um intervalo de chaves de partição, levará a um curto pico na métrica de consumo normalizado de RU/s. Nesses casos, não haverá erros imediatos de limitação de taxa se a taxa de solicitação geral for baixa ou as solicitações forem feitas a outras partições em intervalos de chaves de partição diferentes.
Para saber mais, confira Diagnosticar e solucionar problemas de 429 exceções.
Como monitorar partições frequentes
A métrica de consumo de RU normalizado pode ser usada para monitorar se a carga de trabalho possui uma partição frequente. Uma partição em chamas ocorre quando uma ou algumas chaves de partição lógicas consomem uma quantidade desproporcional do total de RU/s devido a um volume de solicitação mais alto. Isso pode ser causado por um design de chave de partição que não distribui as solicitações de maneira uniforme. Isso resulta em muitas solicitações sendo direcionadas para um pequeno subconjunto de partições lógicas (o que implica intervalos de chave de partição) que se tornam quentes. Como todos os dados de uma partição lógica residem em um intervalo de chaves de partição e o total de RU/s é distribuído uniformemente entre todos os intervalos de chaves de partição, uma partição ativa pode levar a erros 429 e ao uso ineficiente da taxa de transferência.
Como identificar uma partição ativa
Para verificar se há uma partição da camada de acesso frequente, navegue até Insights>Taxa de Transferência>Consumo de RU Normalizado (%) por PartitionKeyRangeID. Filtre para um banco de dados e contêiner específicos.
Cada PartitionKeyRangeId é mapeada para uma partição física. Se houver um PartitionKeyRangeId que tenha maior consumo normalizado de RU do que outros (por exemplo, um está consistentemente em 100%, mas outros estão em 30% ou menos), isso pode ser um sinal de uma partição aquecida.
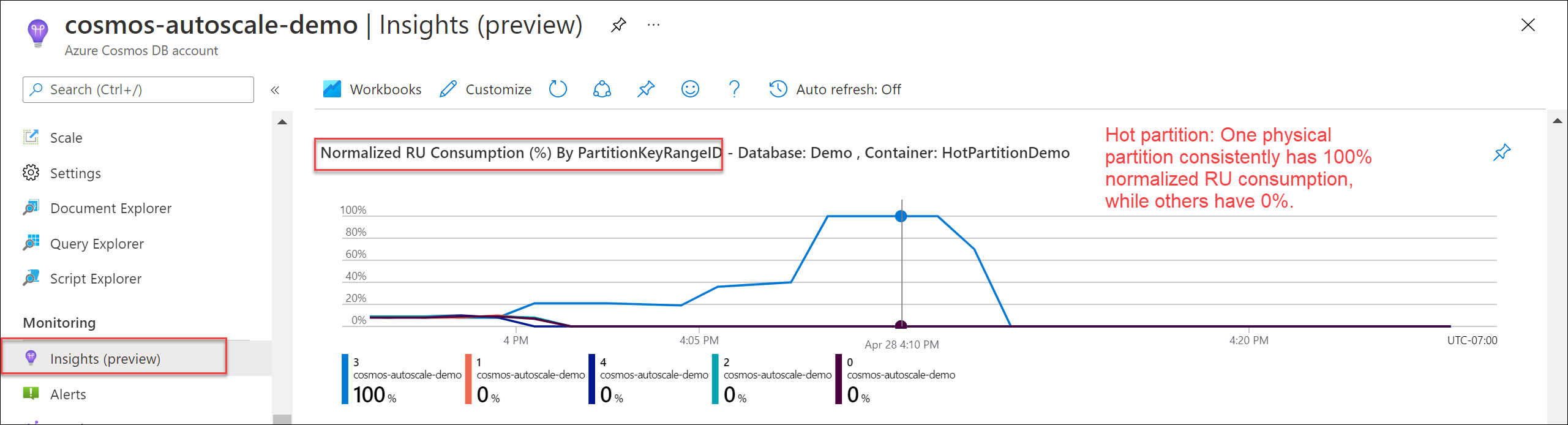
Para identificar as partições lógicas que consomem mais RU/s, consulte Como identificar a partição ativa.
Consumo normalizado de Unidades de Solicitação (RU) e escalonamento automático
A métrica de consumo de RU normalizado será mostrada como 100% se pelo menos 1 intervalo de chaves de partição usar todas as RU/s alocadas em qualquer segundo determinado no intervalo de tempo. Uma pergunta comum que surge é: por que o consumo normalizado de RU é de 100%, mas o Azure Cosmos DB não dimensionou as RU/s para a taxa de transferência máxima com dimensionamento automático?
Observação
As informações a seguir descrevem a implementação atual de autoscale e podem mudar no futuro.
Quando você usa o dimensionamento automático, o Azure Cosmos DB dimensiona as RU/s para a taxa de transferência máxima somente quando o consumo de RU normalizado é de 100% para um período de tempo contínuo e sustentado em um intervalo de cinco segundos. Isso é feito para garantir que a lógica de dimensionamento seja amigável ao custo para o usuário, pois garante que picos momentâneos únicos não levem a dimensionamento desnecessário e custo mais alto. Quando há picos momentâneos, o sistema normalmente é dimensionado para um valor superior ao dimensionado anteriormente para RU/s, mas inferior ao máximo de RU/s.
Por exemplo, suponha que você tenha um contêiner com um dimensionamento automático para uma taxa de transferência máxima de 20.000 RU/s (escalando entre 2.000 e 20.000 RU/s) e dois intervalos de chaves de partição. Cada intervalo de chaves de partição pode ser dimensionado entre 1000 e 10.000 RU/s. Como o dimensionamento automático provisiona todos os recursos necessários antecipadamente, você pode usar até 20.000 RU/s a qualquer momento.
Agora vamos dizer que você tem um pico intermitente de tráfego:
Por um segundo, a Partição 1 atinge 10.000 RU/s e depois cai para 1.000 RU/s nos próximos quatro segundos.
Simultaneamente, a Partição 2 aumenta para 8.000 RU/s e cai para 1.000 RU/s nos próximos 4 segundos.
É assim que as métricas se comportam:
O consumo de RU normalizado (que mostra o uso máximo no intervalo em todas as partições) mostrará 100% de utilização, pois a Partição 1 atingiu seu máximo por 1 segundo.
No entanto, a taxa de transferência provisionada e as métricas de RU dimensionadas automaticamente não são escaladas verticalmente até o máximo de RU/s apenas devido a um pico de 1 segundo. Ele é dimensionado com base no intervalo de 5 segundos para ser econômico. Portanto, para o exemplo anterior, o consumo de RU de partição 1 e partição 2 não atinge 10.000 RU/s com base no intervalo de 5 segundos.
Dessa forma, mesmo que o dimensionamento automático não tenha sido dimensionado ao máximo, você ainda conseguiu usar o total de RU/s disponíveis. Para verificar o consumo de RU/s, você pode usar o recurso opcional do Logs de Diagnóstico para consultar o consumo geral de RU/s em um nível por segundo em todos os intervalos de chaves de partição.
CDBPartitionKeyRUConsumption
| where TimeGenerated >= (todatetime('2022-01-28T20:35:00Z')) and TimeGenerated <= todatetime('2022-01-28T20:40:00Z')
| where DatabaseName == "MyDatabase" and CollectionName == "MyContainer"
| summarize sum(RequestCharge) by bin(TimeGenerated, 1sec), PartitionKeyRangeId
| render timechart
Em geral, para uma carga de trabalho de produção usando o dimensionamento automático, se você vir entre 1-5% das solicitações com erros 429, e a latência de ponta a ponta for aceitável, esse é um sinal saudável de que as RU/s estão sendo utilizadas em sua totalidade. Mesmo que o consumo normalizado de RU ocasionalmente atinja 100% e o dimensionamento automático não seja dimensionado até o máximo de RU/s, não há problemas, pois a taxa geral de erros 429 é baixa. Nenhuma ação é necessária.
Dica
Se você estiver usando o dimensionamento automático e descobrir que o consumo normalizado de RU é consistentemente 100% e você é dimensionado consistentemente para o máximo de RU/s, isso é um sinal de que usar a taxa de transferência manual pode ser mais econômico. Para determinar se o dimensionamento automático ou a taxa de transferência manual é melhor para sua carga de trabalho, consulte Como escolher entre a taxa de transferência provisionada padrão (manual) e a de dimensionamento automático. O Azure Cosmos DB também envia recomendações de custo com base nos seus padrões de carga de trabalho para recomendar a taxa de transferência manual ou de dimensionamento automático.
Exibir a métrica de consumo normalizado de unidade de solicitação
Entre no portal do Azure.
Selecione Monitor na barra de menus de navegação à esquerda e selecione Métricas.

No painel Métricas>Selecionar um recurso > escolha a assinatura necessária e o grupo de recursos. Para o Tipo de recurso, selecione Contas do Azure Cosmos DB, escolha uma das contas existentes do Azure Cosmos DB e selecione Aplicar.

Em seguida, você pode selecionar uma métrica na lista de métricas disponíveis. Você pode selecionar métricas específicas para unidades de solicitação, armazenamento, latência, disponibilidade, Cassandra e outros. Para saber mais detalhadamente sobre todas as métricas disponíveis nesta lista, consulte o artigo Métricas por categoria. Neste exemplo, vamos selecionar métrica Consumo Normalizado de RU e Max como o valor de agregação.
Além desses detalhes, você também pode selecionar o Intervalo de tempo e a Granularidade de tempo das métricas. Você pode exibir as métricas de, no máximo, os últimos 30 dias. Depois que você aplicar o filtro, um gráfico será exibido com base no seu filtro.
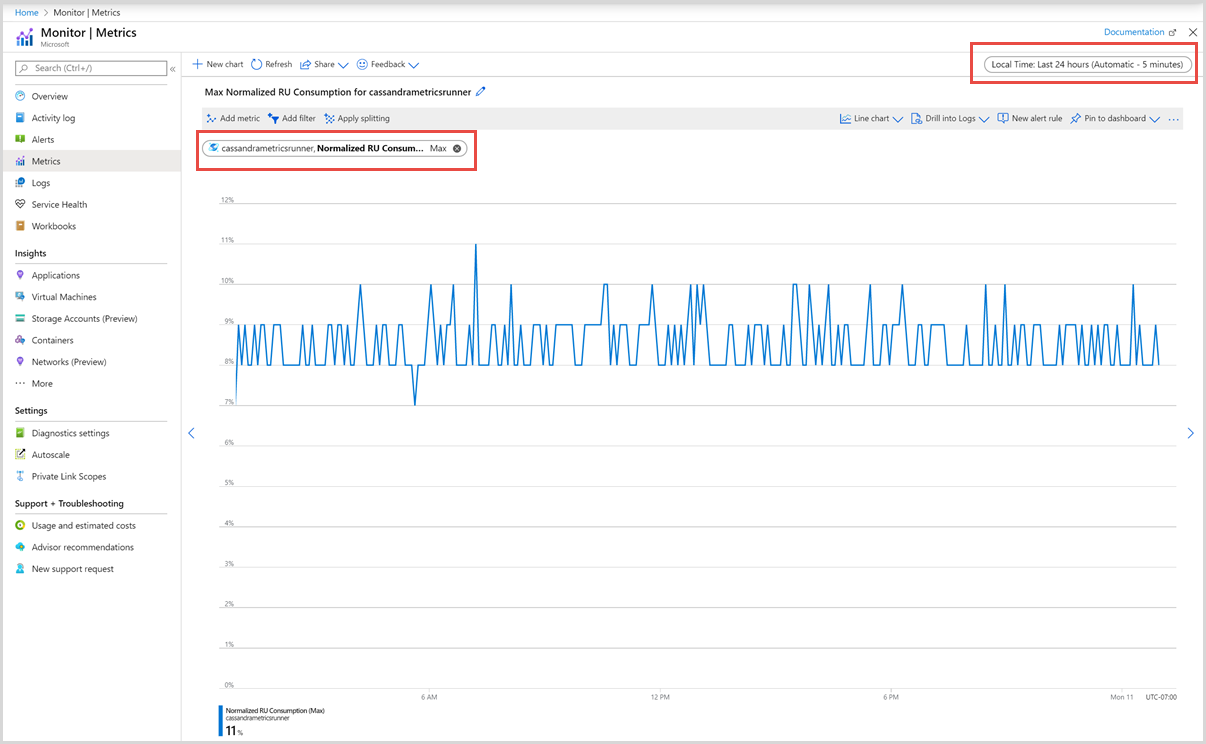



Filtros para a métrica de consumo de RU normalizado
Você também pode filtrar as métricas e o gráfico exibidos por um CollectionName, DatabaseName, PartitionKeyRangeID e Region específicos. Para filtrar as métricas, selecione Adicionar filtro e escolha a propriedade necessária, como CollectionName e valor correspondente em que você está interessado. O grafo então exibe as métricas de consumo normalizado de RU pelo contêiner para o período selecionado.
Você pode agrupar as métricas usando a opção Aplicar divisão. Para bancos de dados de taxa de transferência compartilhada, a métrica de RU normalizada mostra os dados somente na granularidade dos bancos de dados, mas ela não mostra nenhum dado por coleção. Portanto, para o banco de dados de taxa de transferência compartilhada, você não verá nenhum dado quando aplicar a divisão pelo nome da coleção.
A métrica de consumo normalizado de unidade de solicitação para cada contêiner é exibida conforme mostrado na imagem a seguir:
