Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Esta página descreve como transmitir alterações de uma tabela Delta. O Delta Lake está profundamente integrado ao Structured Streaming do Spark por meio de readStream e writeStream. O Delta Lake supera muitas das limitações normalmente associadas aos arquivos e sistemas de fluxo, incluindo:
- Coalescência de pequenos arquivos produzidos pela ingestão de baixa latência.
- Manutenção de processamento "exatamente uma vez" com mais de um fluxo (ou trabalhos em lote simultâneos).
- Descobrir com eficiência quais arquivos são novos ao usar arquivos como origem de um fluxo.
Note
Este artigo descreve o uso de tabelas Delta Lake como fontes e destinos de streaming. Para saber como carregar dados usando tabelas de streaming no Databricks SQL, consulte Usar tabelas de streaming no Databricks SQL.
Para obter informações sobre junções estáticas de fluxo com o Delta Lake, consulte Junções estáticas do Stream.
Alterações de fluxo
Quando se trata de alterações de streaming de uma tabela Delta para processamento incremental, há duas opções a serem consideradas:
- Transmitir de um feed CDC (captura de dados de alteração) de uma tabela Delta.
- Transmita da própria tabela Delta.
A opção 1 é a solução mais robusta e seu código define como você deseja processar diferentes tipos de eventos de alteração, incluindo inserções, atualizações e exclusões. A opção 2 é mais simples porque você não precisa escrever código para processar eventos de alteração. No entanto, a opção 2 só é recomendada quando a tabela Delta de origem é apenas para anexação. Quando há alterações (por exemplo, atualizações e exclusões) na tabela Delta de origem, o mecanismo de Streaming Estruturado gera uma exceção. Você pode lidar com essa exceção reprocessando todos os dados da tabela de origem ou configurando-os para ignorar as alterações na tabela de origem. Para obter mais detalhes, consulte Ignorar atualizações e exclusões.
O Databricks recomenda o streaming do feed CDC de uma tabela Delta (opção 1) em vez da tabela Delta em si (opção 2) sempre que possível.
Opção 1: transmitir de um feed CDC (captura de dados de alteração)
O feed de dados de alterações do Delta Lake registra alterações em uma tabela Delta, incluindo atualizações e exclusões. Quando habilitado, você pode transmitir de um feed de dados de alterações e gravar lógica para processar inserções, atualizações e exclusões em tabelas downstream. Embora a saída de dados do fluxo de dados de alteração difira ligeiramente da tabela Delta que descreve, ainda assim possibilita a propagação de alterações incrementais para tabelas subsidiárias em uma arquitetura de medalhão.
Important
No Databricks Runtime 12.2 LTS e abaixo, você não pode fazer streaming do feed de dados de alteração para uma tabela Delta que tem o mapeamento de colunas habilitado e sofreu uma evolução de esquema não aditiva, como o renomeio ou exclusão de colunas. Consulte Streaming com mapeamento de coluna e alterações de esquema.
Opção 2: Transmitir de uma tabela Delta
O Structured Streaming processa incrementalmente tabelas Delta. Enquanto uma consulta de streaming está ativa em uma tabela Delta, novos registros são processados de forma idempotente à medida que novas versões de tabela são confirmadas na tabela de origem.
Os exemplos de código a seguir mostram a configuração de uma leitura de streaming usando o nome da tabela ou o caminho do arquivo.
Python
spark.readStream.table("table_name")
spark.readStream.load("/path/to/table")
Scala
spark.readStream.table("table_name")
spark.readStream.load("/path/to/table")
Important
Se o esquema de uma tabela Delta for alterado depois que uma leitura de fluxo começar na tabela, a consulta falhará. Para a maioria das alterações de esquema, você pode reiniciar o fluxo para resolver incompatibilidade de esquema e continuar o processamento.
No Databricks Runtime 12.2 LTS e abaixo, não é possível transmitir a partir de uma tabela Delta com o mapeamento de colunas ativado que tenha passado por uma evolução de esquema não aditiva, como renomear ou eliminar colunas. Para obter mais detalhes, consulte Fluxo com mapeamento de coluna e alterações de esquema.
Limitar taxa de entrada de dados
As seguintes opções estão disponíveis para controlar os microlotes:
-
maxFilesPerTrigger: quantos arquivos novos serão considerados em todos os microlotes. O padrão é 1000. -
maxBytesPerTrigger: quantos dados são processados em cada microbatch. Essa opção define um "máximo flexível", o que significa que um lote processa aproximadamente essa quantidade de dados e pode processar mais do que o limite para fazer com que a consulta de streaming avance em casos em que a menor unidade de entrada é maior que esse limite. Isso não está definido por padrão.
Se você usar maxBytesPerTrigger em conjunto com maxFilesPerTrigger, o microlote processará os dados até que o limite maxFilesPerTrigger ou maxBytesPerTrigger seja atingido.
Note
Nos casos em que as transações da tabela de origem são limpas devido à logRetentionDurationconfiguração e a consulta de streaming tenta processar essas versões, por padrão, a consulta falha para evitar a perda de dados. Você pode definir a opção failOnDataLoss como false para ignorar dados perdidos e continuar o processamento.
Ignorar atualizações e exclusões
Ao transmitir de uma tabela Delta, o Streaming Estruturado não manipula a entrada que não é um acréscimo e gera uma exceção se ocorrerem modificações na tabela que está sendo usada como fonte. Há duas estratégias principais para lidar com alterações que não podem ser propagadas automaticamente downstream:
- Você pode excluir a saída e o ponto de verificação e reiniciar o fluxo desde o início.
- Você pode definir uma das seguintes opções:
-
skipChangeCommits(recomendado): ignora transações que excluem ou modificam registros existentes. Essa opção incluiignoreDeletes. -
ignoreDeletes(herdado): ignora transações que excluem dados nos limites de partição. Essa opção lida apenas com eliminações completas de partição.
-
Note
O Databricks recomenda usar skipChangeCommits.
No Databricks Runtime 12.2 LTS e em versões superiores, skipChangeCommits descontinua a configuração anterior ignoreChanges. No Databricks Runtime 11.3 LTS e inferior, ignoreChanges é a única opção suportada.
A semântica para ignoreChanges difere muito de skipChangeCommits. Com ignoreChanges habilitado, os arquivos de dados reescritos na tabela de origem são emitidos novamente após uma operação de alteração de dados, como UPDATE, MERGE INTO, DELETE (dentro de partições) ou OVERWRITE. Linhas inalteradas geralmente são emitidas junto com novas linhas, portanto, os consumidores downstream devem ser capazes de lidar com duplicatas. As exclusões não são propagadas por downstream.
ignoreChanges incorpora ignoreDeletes.
skipChangeCommits ignora totalmente as operações de alteração de arquivo. Os arquivos de dados reescritos na tabela de origem devido à operação de alteração de dados, como UPDATE, MERGE INTO, DELETE e OVERWRITE são totalmente ignorados. Para refletir as alterações em tabelas de origem upstream, você deve implementar uma lógica separada para propagar essas alterações.
As cargas de trabalho configuradas com ignoreChanges continuam a operar usando semântica conhecida, mas o Databricks recomenda usar skipChangeCommits para todas as novas cargas de trabalho. Migrar cargas de trabalho usando ignoreChanges para skipChangeCommits exigir lógica de refatoração.
Example
Por exemplo, suponha que você tenha uma tabela user_events com as colunas date, user_email e action que é particionada por date. Você transmite a saída da tabela user_events e precisa excluir dados dela devido à GDPR.
Quando você exclui em limites de partição (ou seja, WHERE está em uma coluna de partição), os arquivos já são segmentados por valor, de modo que a exclusão apenas remove esses arquivos dos metadados. Ao excluir uma partição inteira de dados, você pode usar o seguinte:
spark.readStream
.option("ignoreDeletes", "true")
.table("user_events")
Se você excluir dados em várias partições (nesse exemplo, filtrando emuser_email) use a seguinte sintaxe:
spark.readStream
.option("skipChangeCommits", "true")
.table("user_events")
Se você atualizar um user_email com a instrução UPDATE, o arquivo que contém o user_email em questão será reescrito. Use skipChangeCommits para ignorar os arquivos de dados alterados.
O Databricks recomenda usar skipChangeCommits em vez de ignoreDeletes, a menos que você tenha certeza de que as exclusões são sempre quedas completas de partição.
Especificar posição inicial
Você pode usar as opções a seguir para especificar o ponto inicial da fonte de streaming Delta Lake sem processar a tabela inteira.
startingVersion: a versão do Delta Lake a ser iniciada. O Databricks recomenda omitir essa opção para a maioria das cargas de trabalho. Quando não definido, o fluxo começa a partir da última versão disponível, incluindo um instantâneo completo da tabela naquele momento e alterações futuras como dados de alterações.Se especificado, o fluxo lê todas as alterações na tabela Delta começando com a versão especificada (inclusive). Se a versão especificada não estiver mais disponível, o fluxo não será iniciado. Você pode obter as versões de commit da coluna
versionda saída do comando DESCRIBE HISTORY.Para retornar apenas as alterações mais recentes, especifique
latest.startingTimestamp: o carimbo de data/hora do qual começar. Todas as alterações de tabela confirmadas no registro de data e hora ou depois dele (inclusive) são lidas pelo leitor de streaming. Se o carimbo de data e hora fornecido preceder todas as confirmações de tabela, a leitura de streaming começará com o carimbo de data e hora mais antigo disponível. Um destes:- Uma cadeia de caracteres de um carimbo de data/hora. Por exemplo,
"2019-01-01T00:00:00.000Z". - Uma cadeia de caracteres de data. Por exemplo,
"2019-01-01".
- Uma cadeia de caracteres de um carimbo de data/hora. Por exemplo,
Não é possível definir as duas opções ao mesmo tempo. Elas entram em vigor somente ao iniciar uma nova consulta de streaming. Se uma consulta de streaming tiver sido iniciada e o progresso tiver sido registrado no ponto de verificação, essas opções serão ignoradas.
Important
Embora você possa iniciar a fonte de streaming de uma versão ou carimbo de data/hora especificado, o esquema da fonte de streaming é sempre o esquema mais recente da tabela Delta. Você deve garantir que não haja nenhuma alteração de esquema incompatível na tabela Delta após a versão ou o carimbo de data/hora especificados. Caso contrário, a fonte de streaming pode retornar resultados incorretos ao ler os dados com um esquema incorreto.
Example
Por exemplo, vamos supor que você tenha uma tabela user_events. Se você quiser ler as alterações desde a versão 5, use:
spark.readStream
.option("startingVersion", "5")
.table("user_events")
Se você quiser ler as alterações desde 18/10/2018, use:
spark.readStream
.option("startingTimestamp", "2018-10-18")
.table("user_events")
Processa o instantâneo inicial sem que os dados sejam removidos
Este recurso está disponível no Databricks Runtime 11.3 LTS e superior.
Ao usar uma tabela Delta como fonte de fluxo, a consulta primeiro processa todos os dados presentes na tabela. A tabela Delta nesta versão é chamada de captura instantânea inicial. Por padrão, os arquivos de dados da tabela Delta são processados com base em qual arquivo foi modificado pela última vez. No entanto, o último tempo de modificação não representa necessariamente a ordem de tempo do evento de registro.
Em uma consulta de streaming com estado com uma marca d'água definida, processar arquivos por tempo de modificação pode resultar em registros sendo processados na ordem errada. Isso pode levar a registros caindo como eventos tardios pela marca d'água.
Você pode evitar o problema de queda de dados habilitando a seguinte opção:
- withEventTimeOrder: se o instantâneo inicial deve ser processado na ordem do tempo do evento.
Com a ordem de tempo do evento habilitada, o intervalo de tempo do evento dos dados iniciais do instantâneo é dividido em buckets de tempo. Cada microlote processa um conjunto filtrando os dados dentro de um determinado intervalo de tempo. As opções de configuração maxFilesPerTrigger e maxBytesPerTrigger ainda são aplicáveis para controlar o tamanho do microlote, mas apenas de forma aproximada devido à natureza do processamento.
O gráfico abaixo mostra esse processo:
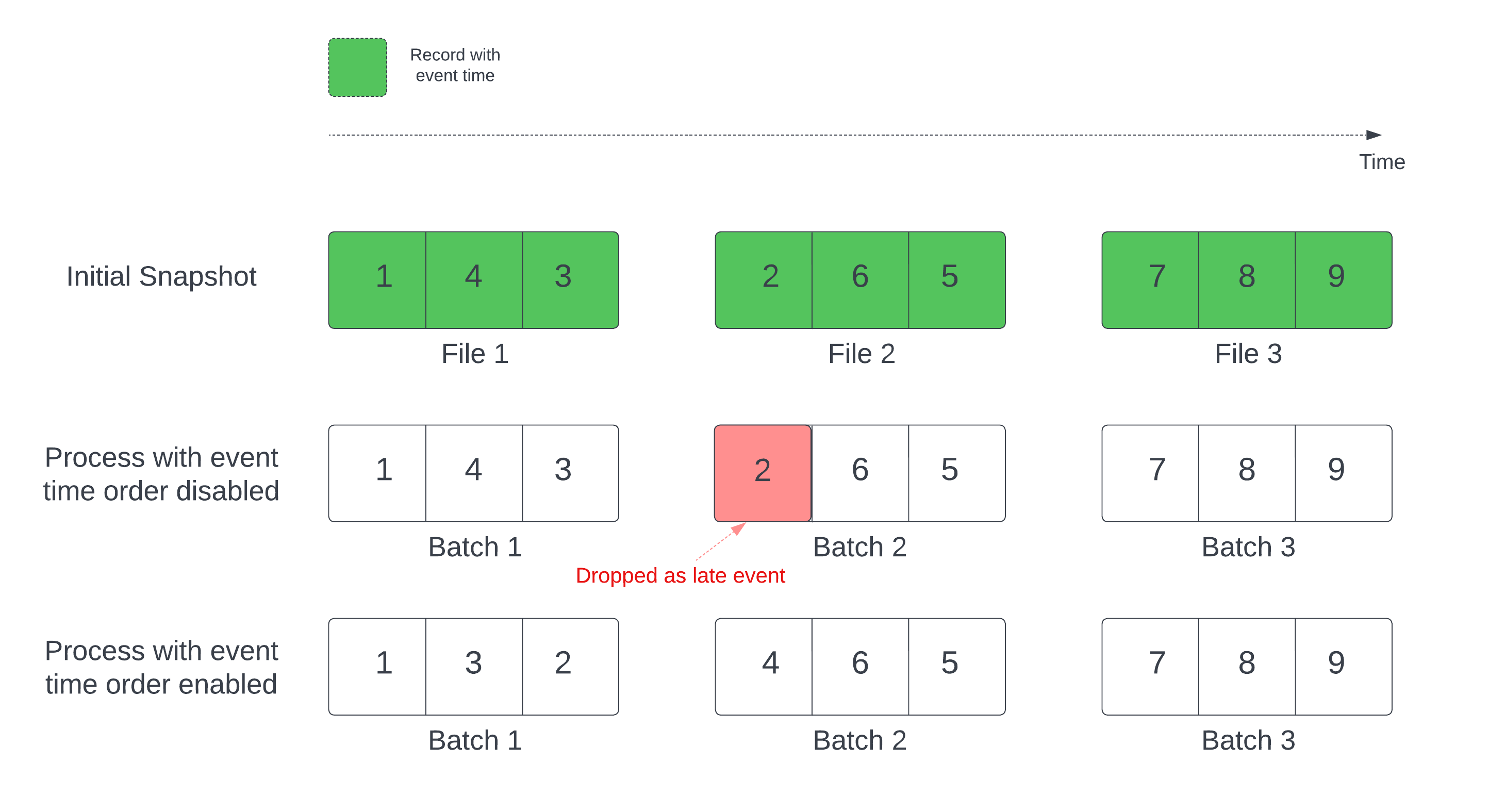
Informações importantes sobre esse recurso:
- O problema da queda de dados só acontece quando o instantâneo Delta inicial de uma consulta de streaming com estado é processado na ordem padrão.
- Você não poderá alterar
withEventTimeOrderdepois que a consulta de fluxo for iniciada enquanto o instantâneo inicial ainda estiver sendo processado. Para reiniciar comwithEventTimeOrderalterado, você precisa excluir o ponto de verificação. - Se você estiver executando uma consulta de fluxo com o EventTimeOrder habilitado, não poderá rebaixar para uma versão do DBR que não dê suporte a esse recurso até que o processamento inicial do instantâneo esteja concluído. Se você precisar fazer downgrade, poderá aguardar a conclusão do instantâneo inicial ou excluir o ponto de verificação e reiniciar a consulta.
- Não há suporte para esse recurso nos seguintes cenários incomuns:
- A coluna de tempo do evento é uma coluna gerada e há transformações de não projeção entre a origem Delta e a marca d'água.
- Há uma marca d'água que tem mais de uma fonte Delta na consulta de fluxo.
- Com a ordem de tempo do evento habilitada, o desempenho do processamento de instantâneo inicial delta pode ser mais lento.
- Cada microlote examina o instantâneo inicial para filtrar dados dentro do intervalo de tempo correspondente ao evento. Para uma ação de filtro mais rápida, é recomendável usar uma coluna de origem Delta como a hora do evento para que a omissão de dados possa ser aplicada (verifique Omissão de dados para o Delta Lake para saber quando é aplicável). Além disso, o particionamento de tabela ao longo da coluna de tempo do evento pode acelerar ainda mais o processamento. Você pode verificar a interface do usuário do Spark para ver quantos arquivos delta são verificados em busca de um microlote específico.
Example
Suponha que você tenha uma tabela user_events com uma coluna event_time. Sua consulta de streaming é uma consulta de agregação. Se você quiser garantir que não haja nenhuma queda de dados durante o processamento de instantâneo inicial, poderá usar:
spark.readStream
.option("withEventTimeOrder", "true")
.table("user_events")
.withWatermark("event_time", "10 seconds")
Note
Você também pode habilitar isso com a configuração do Spark no cluster que se aplicará a todas as consultas de streaming: spark.databricks.delta.withEventTimeOrder.enabled true
Tabela Delta como coletor
Você também pode gravar dados em uma tabela Delta usando o fluxo estruturado. O log de transações do Delta Lake garante o processamento exatamente uma vez, mesmo quando houver outros fluxos ou consultas em lote sendo executados simultaneamente na tabela.
Ao gravar em uma tabela Delta usando um coletor de Streaming Estruturado, você pode observar confirmações vazias com epochId = -1. Eles são esperados e normalmente ocorrem:
- No primeiro lote de cada execução da consulta de streaming (isso acontece em todos os lotes para
Trigger.AvailableNow) - Quando um esquema é alterado (como adicionar uma coluna).
Esses commits vazios não afetam a correção ou o desempenho da consulta de maneira significativa. Eles são intencionais e não indicam um erro.
Note
A função VACUUM do Delta Lake remove todos os arquivos não gerenciados pelo Delta Lake, mas ignora todos os diretórios que começam com _. Você pode armazenar pontos de verificação com segurança ao lado de outros dados e metadados para uma tabela Delta usando uma estrutura de diretório, como <table-name>/_checkpoints.
Metrics
Você pode descobrir o número de bytes e o número de arquivos que ainda serão processados em um processo de consulta de streaming como as métricas numBytesOutstanding e numFilesOutstanding. Métricas adicionais incluem:
-
numNewListedFiles: número de arquivos do Delta Lake listados para calcular a lista de pendências para esse lote.-
backlogEndOffset: a versão da tabela usada para calcular a lista de pendências.
-
Se você estiver executando o fluxo em um notebook, poderá ver essas métricas na guia Dados brutos no painel de progresso de consulta de transmissão:
{
"sources": [
{
"description": "DeltaSource[file:/path/to/source]",
"metrics": {
"numBytesOutstanding": "3456",
"numFilesOutstanding": "8"
}
}
]
}
Modo de acréscimo
Por padrão, os fluxos são executados no modo de acréscimo, que adiciona novos registros à tabela.
Use o método toTable ao fazer streaming para tabelas, como no exemplo a seguir:
Python
(events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
)
Scala
events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
Modo completo
Você também pode usar o Structured Streaming para substituir a tabela inteira a cada lote. Um exemplo de caso de uso é computar um resumo usando a agregação:
Python
(spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
)
Scala
spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
O exemplo anterior atualiza continuamente uma tabela que contém o número agregado de eventos por cliente.
Para aplicativos com requisitos de latência mais lenientes, você pode economizar recursos de computação com gatilhos de uso único. Use para atualizar tabelas de agregação de resumo em um horário definido, processando somente os novos dados que chegaram desde a última atualização.
Upsert de consultas de streaming usando foreachBatch
Você pode usar uma combinação de merge e foreachBatch para gravar upserts complexas de uma consulta de streaming em uma tabela Delta. Veja Usar o foreachBatch para gravar em coletores de dados arbitrários.
Esse padrão tem várias aplicações, incluindo as seguintes:
- Escreva agregações em streaming no modo de atualização: Isso é muito mais eficiente do que o modo completo.
-
Gravar um fluxo de alterações de banco de dados em uma tabela Delta: a consulta de mesclagem para gravação de dado de alteração pode ser usada no
foreachBatchpara aplicar continuamente um fluxo de alterações a uma tabela Delta. -
Gravar um fluxo de dados na tabela Delta com eliminação de duplicação: a consulta de mesclagem somente inserção para a eliminação de duplicação pode ser usada no
foreachBatchpara gravar dados continuamente (com duplicatas) em uma tabela Delta com a eliminação de duplicação automática.
Note
- Certifique-se de que sua
mergeinstrução dentro deleforeachBatchseja idempotente, pois as reinicializações da consulta de streaming podem aplicar a operação no mesmo lote de dados várias vezes. - Quando
mergeé usado emforeachBatch, a taxa de dados de entrada da consulta de streaming (relatada por meio deStreamingQueryProgresse visível no gráfico de taxa do notebook) pode ser informada como um múltiplo da taxa real em que os dados são gerados na origem. Isso ocorre porque omergelê os dados de entrada várias vezes fazendo com que as métricas de entrada sejam multiplicadas. Se esse for um gargalo, você poderá armazenar em cache o DataFrame do lote antesmergee, em seguida, desarmazená-lo em cache apósmerge.
O exemplo a seguir demonstra como você pode usar o SQL no foreachBatch para realizar essa tarefa:
Scala
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
// Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
// Use the view name to apply MERGE
// NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
microBatchOutputDF.sparkSession.sql(s"""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
# Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
# Use the view name to apply MERGE
# NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
# In Databricks Runtime 10.5 and below, you must use the following:
# microBatchOutputDF._jdf.sparkSession().sql("""
microBatchOutputDF.sparkSession.sql("""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
Você também pode optar por usar as APIs do Delta Lake para executar upserts de streaming, como no exemplo a seguir:
Scala
import io.delta.tables.*
val deltaTable = DeltaTable.forName(spark, "table_name")
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
deltaTable.as("t")
.merge(
microBatchOutputDF.as("s"),
"s.key = t.key")
.whenMatched().updateAll()
.whenNotMatched().insertAll()
.execute()
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
from delta.tables import *
deltaTable = DeltaTable.forName(spark, "table_name")
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
(deltaTable.alias("t").merge(
microBatchOutputDF.alias("s"),
"s.key = t.key")
.whenMatchedUpdateAll()
.whenNotMatchedInsertAll()
.execute()
)
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
Gravações da tabela Idempotente no foreachBatch
Note
O Databricks recomenda configurar uma gravação de streaming separada para cada coletor que você quer atualizar em vez de usar foreachBatch. Isso ocorre porque as gravações em várias tabelas são serializadas ao usar 'foreachBatch', o que reduz a paralelização e aumenta a latência geral.
As tabelas Delta oferecem suporte às seguintes opções DataFrameWriter para que as gravações em várias tabelas na foreachBatch sejam idempotentes:
-
txnAppId: uma cadeia de caracteres exclusiva que você pode passar em cada gravação DataFrame. Por exemplo, você pode usar a ID do StreamingQuery comotxnAppId. -
txnVersion: um número que aumenta de forma monotônica e atua como a versão da transação.
O Delta Lake usa uma combinação de txnAppId e txnVersion para identificar gravações duplicadas e ignorá-las.
Se uma gravação em lote for interrompida com uma falha, a execução novamente do lote usará o mesmo aplicativo e ID de lote para ajudar o tempo de execução a identificar corretamente as gravações duplicadas e ignorá-las. A ID do aplicativo (txnAppId) pode ser qualquer cadeia de caracteres exclusiva gerada pelo usuário, e não precisa estar relacionada à ID do fluxo. Veja Usar o foreachBatch para gravar em coletores de dados arbitrários.
Warning
Se você excluir o ponto de verificação de streaming e reiniciar a consulta com um novo ponto de verificação, deverá fornecer um txnAppId diferente. Novos pontos de verificação começam com uma ID de lote de 0. O Delta Lake usa a ID e o txnAppId do lote como uma chave exclusiva e ignora lotes com valores já vistos.
O exemplo de código a seguir demonstra esse padrão:
Python
app_id = ... # A unique string that is used as an application ID.
def writeToDeltaLakeTableIdempotent(batch_df, batch_id):
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # ___location 1
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # ___location 2
streamingDF.writeStream.foreachBatch(writeToDeltaLakeTableIdempotent).start()
Scala
val appId = ... // A unique string that is used as an application ID.
streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // ___location 1
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // ___location 2
}