Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
O mecanismo de execução nativo é um aprimoramento inovador para execuções de trabalho do Apache Spark no Microsoft Fabric. Esse mecanismo vetorizado otimiza o desempenho e a eficiência de suas consultas do Spark, executando-as diretamente em sua infraestrutura de lakehouse. A integração perfeita do mecanismo significa que ele não requer modificações de código e evita o bloqueio do fornecedor. Ela oferece suporte a APIs do Apache Spark, é compatível com o Runtime 1.3 (Apache Spark 3.5) e funciona com os formatos Parquet e Delta. Independentemente da localização dos seus dados no OneLake, ou se você acessar os dados por meio de atalhos, o mecanismo de execução nativo maximiza a eficiência e o desempenho.
O mecanismo de execução nativo eleva significativamente o desempenho da consulta e, ao mesmo tempo, minimiza os custos operacionais. Ele oferece um aprimoramento de velocidade notável, alcançando um desempenho até quatro vezes mais rápido em comparação com o Spark (software de software livre) tradicional, conforme validado pelo TPC-DS benchmark de 1 TB. O mecanismo é hábil em gerenciar uma ampla gama de cenários de processamento de dados, que vão desde a ingestão de dados de rotina, trabalhos em lote e tarefas de ETL (extrair, transformar, carregar), até análises complexas de ciência de dados e consultas interativas responsivas. Os usuários se beneficiam de tempos de processamento acelerados, taxa de transferência aumentada e utilização otimizada de recursos.
O Native Execution Engine é baseado em dois componentes OSS principais: Velox, uma biblioteca de aceleração de banco de dados C++ introduzida pelo Meta, e Apache Gluten (incubação), uma camada intermediária responsável por descarregar a execução de mecanismos SQL baseados em JVM para mecanismos nativos introduzidos pela Intel.
Quando usar o mecanismo de execução nativo
O mecanismo de execução nativo oferece uma solução para executar consultas em conjuntos de dados de grande escala; ele otimiza o desempenho usando os recursos nativos das fontes de dados subjacentes e minimizando a sobrecarga normalmente associada à movimentação e serialização de dados em ambientes tradicionais do Spark. O mecanismo oferece suporte a vários operadores e tipos de dados, incluindo agregado de hash de rollup, BNLJ (Broadcast Nested Loop Unit) e formatos precisos de carimbo de data/hora. No entanto, para se beneficiar totalmente dos recursos do mecanismo, você deve considerar seus casos de uso ideais:
- O mecanismo é eficaz ao trabalhar com dados nos formatos Parquet e Delta, que pode ser processado de forma nativa e eficiente.
- As consultas que envolvem transformações e agregações complexas se beneficiam significativamente dos recursos de processamento colunar e vetorização do mecanismo.
- O aprimoramento de desempenho é mais notável em cenários em que as consultas não acionam o mecanismo de fallback, evitando recursos ou expressões sem suporte.
- O mecanismo é adequado para consultas que são computacionalmente intensivas, em vez de simples ou vinculadas a E/S.
Para obter informações sobre os operadores e funções suportados pelo mecanismo de execução nativo, consulte a documentação do Apache Gluten.
Habilitar o mecanismo de execução nativo
Para usar todos os recursos do mecanismo de execução nativo durante a fase de visualização, configurações específicas são necessárias. Os procedimentos a seguir mostram como ativar esse recurso para notebooks, definições de trabalho do Spark e ambientes inteiros.
Importante
O mecanismo de execução nativo dá suporte à versão mais recente do runtime de GA, que é Runtime 1.3 (Apache Spark 3.5, Delta Lake 3.2). Com a versão do mecanismo de execução nativa no Runtime 1.3, o suporte para a versão anterior — Runtime 1.2 (Apache Spark 3.4, Delta Lake 2.4)— é descontinuado. Incentivamos todos os clientes a atualizar para o Runtime 1.3 mais recente. Se você estiver usando o Mecanismo de Execução Nativa no Runtime 1.2, a aceleração nativa será desabilitada.
Habilitar no nível do ambiente
Para garantir um aprimoramento uniforme do desempenho, habilite o mecanismo de execução nativo em todos os trabalhos e notebooks associados ao seu ambiente:
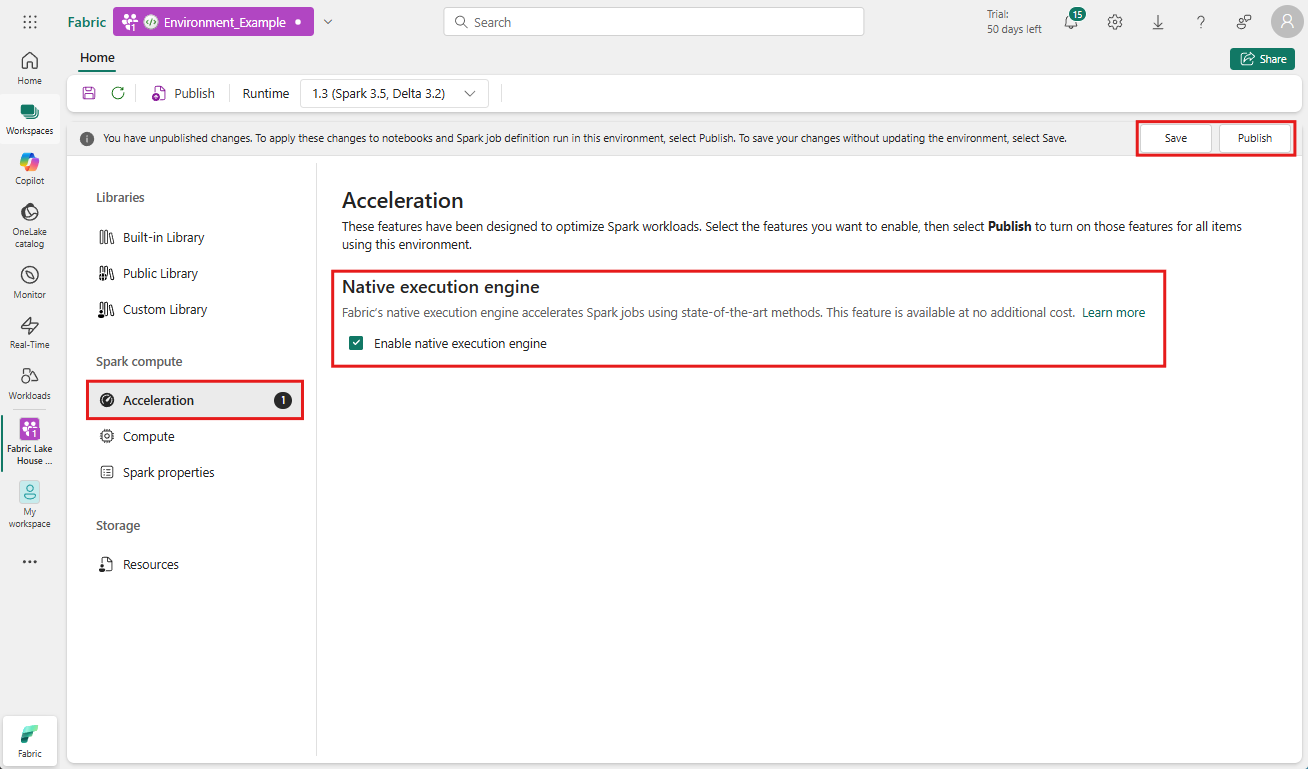
Navegue até o espaço de trabalho que contém seu ambiente e selecione o ambiente. Se você não tiver um ambiente criado, consulte Criar, configurar e usar um ambiente no Fabric.
Em computação do Spark, selecioneAceleração.
Marque a caixa rotulada Habilitar mecanismo de execução nativo.
Salve e publique as alterações.

Quando habilitado no nível do ambiente, todos os trabalhos e notebooks subsequentes herdam a configuração. Essa herança garante que todas as novas sessões ou recursos criados no ambiente se beneficiem automaticamente dos recursos de execução aprimorados.
Importante
Anteriormente, o mecanismo de execução nativo era habilitado por meio das configurações do Spark dentro da configuração do ambiente. O mecanismo de execução nativo agora pode ser habilitado com mais facilidade usando uma alternância na guia Aceleração das configurações do ambiente. Para continuar a usá-lo, vá para a guia Aceleração e ative a alternância. Você também pode habilitá-lo por meio de propriedades do Spark, se preferir.
Habilitar para um notebook ou definição de trabalho do Spark
Você também pode habilitar o mecanismo de execução nativo para um único notebook ou definição de trabalho do Spark, você deve incorporar as configurações necessárias no início do script de execução:
%%configure
{
"conf": {
"spark.native.enabled": "true",
}
}
Para notebooks, insira os comandos de configuração necessários na primeira célula. Para definições de trabalho do Spark, inclua as configurações na linha de frente da definição de trabalho do Spark. O mecanismo de execução nativo é integrado a pools dinâmicos, portanto, depois de habilitar o recurso, ele entra em vigor imediatamente sem exigir que você inicie uma nova sessão.
Controle no nível de consulta
Os mecanismos para habilitar o Mecanismo de Execução Nativo nos níveis de locatário, espaço de trabalho e ambiente, perfeitamente integrados à interface do usuário, estão em desenvolvimento ativo. Você pode desabilitar o mecanismo de execução nativo para consultas específicas, especialmente se elas envolverem operadores sem suporte no momento (consulte limitações). Para desabilitá-lo, defina a configuração do Spark spark.native.enabled como false para a célula específica que contém sua consulta.
%%sql
SET spark.native.enabled=FALSE;

Depois de executar a consulta na qual o mecanismo de execução nativo está desabilitado, você deve reativá-lo para células subsequentes definindo spark.native.enabled como true. Essa etapa é necessária porque o Spark executa células de código sequencialmente.
%%sql
SET spark.native.enabled=TRUE;
Identificar operações executadas pelo mecanismo
Há vários métodos para determinar se um operador em seu trabalho do Apache Spark foi processado usando o mecanismo de execução nativo.
Interface do usuário do Spark e servidor de histórico do Spark
Acesse a interface do usuário do Spark ou o servidor de histórico do Spark para localizar a consulta que você precisa inspecionar. Para acessar a interface do usuário da Web do Spark, navegue até sua Definição de Trabalho do Spark e execute-a. Na guia Execuções, selecione ... ao lado do Nome do aplicativo e selecione Abrir a interface do usuário da Web do Spark. Você também pode acessar a interface do usuário do Spark na guia Monitorar no workspace. Selecione o notebook ou pipeline; na página de monitoramento, há um link direto para a Interface do usuário do Spark para trabalhos ativos.

No plano de consulta exibido na interface do usuário do Spark, procure os nomes de nó que terminam com o sufixo Transformer, *NativeFileScan ou VeloxColumnarToRowExec. O sufixo indica que o mecanismo de execução nativo executou a operação. Por exemplo, nós podem ser rotulados como RollUpHashAggregateTransformer, ProjectExecTransformer, BroadcastHashJoinExecTransformer, ShuffledHashJoinExecTransformer ou BroadcastNestedLoopJoinExecTransformer.

Explicação de DataFrame
Como alternativa, você pode executar o comando df.explain() em seu notebook para exibir o plano de execução. Na saída, procure os mesmos sufixos Transformer, *NativeFileScan ou VeloxColumnarToRowExec. Esse método fornece uma maneira rápida de confirmar se operações específicas estão sendo manipuladas pelo mecanismo de execução nativo.

Mecanismo de fallback
Em alguns casos, o mecanismo de execução nativo pode não ser capaz de executar uma consulta devido a motivos como recursos sem suporte. Nesses casos, a operação recai sobre o mecanismo Spark tradicional. Esse mecanismo de fallback automático garante que não haja interrupção no fluxo de trabalho.


Monitorar consultas e DataFrames executados pelo mecanismo
Para entender melhor como o mecanismo de execução nativo é aplicado a consultas SQL e operações DataFrame e para analisar detalhadamente os níveis de estágio e operador, você pode consulta a interface do usuário do Spark e o servidor de histórico do Spark para obter informações mais detalhadas sobre a execução do mecanismo nativo.
Guia Mecanismo de execução nativo
Você pode navegar para a nova guia “Gluten SQL / DataFrame” para exibir as informações de build do Gluten e os detalhes de execução da consulta. A tabela Consultas fornece insights sobre o número de nós em execução no mecanismo nativo e aqueles que voltam para a JVM para cada consulta.

Grafo de execução de consulta
Você também pode selecionar na descrição da consulta para a visualização do plano de execução de consulta do Apache Spark. O grafo de execução fornece detalhes de execução nativos entre estágios e suas respectivas operações. As cores da tela de fundo diferenciam os mecanismo de execução: verde representa o mecanismo de execução nativo, enquanto azul-claro indica que a operação está sendo executada no mecanismo JVM padrão.

Limitações
Embora o NEE (Mecanismo de Execução Nativa) no Microsoft Fabric aumente significativamente o desempenho dos trabalhos do Apache Spark, ele atualmente tem as seguintes limitações:
Limitações existentes
Recursos incompatíveis do Spark: o mecanismo de execução nativo atualmente não dá suporte a UDFs (funções definidas pelo usuário), à
array_containsfunção ou ao streaming estruturado. Se essas funções ou recursos sem suporte forem usados diretamente ou por meio de bibliotecas importadas, o Spark será revertido para seu mecanismo padrão.Formatos de arquivo sem suporte: consultas aos formatos
JSON,XMLeCSVnão são aceleradas pelo mecanismo de execução nativo. O padrão retorna ao mecanismo regular da JVM do Spark para execução.Modo ANSI sem suporte: o mecanismo de execução nativo não dá suporte ao modo SQL ANSI. Caso esteja habilitado, a execução retornará ao vanilla Spark engine.
Incompatibilidades de tipo em filtro de data: Para se beneficiar da aceleração do mecanismo de execução nativa, garanta que ambos os lados de uma comparação de data tenham o mesmo tipo de dado. Por exemplo, em vez de comparar uma
DATETIMEcoluna com um literal de cadeia de caracteres, converta-a explicitamente conforme mostrado:CAST(order_date AS DATE) = '2024-05-20'
Outras considerações e limitações
Incompatibilidade de conversão decimal para Float: ao converter de
DECIMALparaFLOAT, o Spark preserva a precisão convertendo-a em uma cadeia de caracteres e analisando-a. O NEE (via Velox) executa uma conversão direta da representação internaint128_t, o que pode resultar em discrepâncias de arredondamento.Erros de configuração de fuso horário: definir um fuso horário não reconhecido no Spark faz com que o trabalho falhe em NEE, enquanto o Spark JVM o manipula normalmente. Por exemplo:
"spark.sql.session.timeZone": "-08:00" // May cause failure under NEEComportamento de arredondamento inconsistente: a
round()função se comporta de forma diferente no NEE devido à sua dependência emstd::round, que não replica a lógica de arredondamento do Spark. Isso pode levar a inconsistências numéricas nos resultados de arredondamento.Verificação de chave duplicada ausente na função
map(): quandospark.sql.mapKeyDedupPolicyé definido como EXCEPTION, o Spark gera um erro para chaves duplicadas. O NEE atualmente ignora essa verificação e permite que a consulta tenha êxito incorretamente.
Exemplo:SELECT map(1, 'a', 1, 'b'); -- Should fail, but returns {1: 'b'}Variação de ordem em
collect_list()com classificação: Ao usar eDISTRIBUTE BY, o Spark preserva a ordem dos elementos emSORT BY. O NEE pode retornar valores em uma ordem diferente devido a diferenças aleatórias, o que pode resultar em expectativas incompatíveis para a lógica sensível à ordenação.Incompatibilidade de tipo intermediário para
collect_list()/collect_set(): o Spark usaBINARYcomo o tipo intermediário para essas agregações, enquanto o NEE usaARRAY. Essa incompatibilidade pode levar a problemas de compatibilidade durante o planejamento ou execução da consulta.