Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Aplica-se a:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Important
Os Clusters de Big Data do Microsoft SQL Server 2019 foram desativados. O suporte para clusters de Big Data do SQL Server 2019 terminou em 28 de fevereiro de 2025. Para obter mais informações, consulte a postagem no blog de anúncios e as opções de Big Data na plataforma microsoft SQL Server.
Um dos principais cenários para clusters de Big Data é a capacidade de enviar trabalhos do Spark para o SQL Server. O recurso de envio de trabalhos do Spark permite que você envie arquivos Jar ou Py locais com referências a clusters de Big Data do SQL Server 2019. Ele também permite que você execute arquivos Jar ou Py, que já estão localizados no sistema de arquivos HDFS.
Prerequisites
Ferramentas de Big Data do SQL Server 2019:
- Azure Data Studio
- Extensão do SQL Server 2019
- kubectl
Conectar o Azure Data Studio ao gateway do HDFS/Spark de seu cluster de Big Data.
Abrir caixa de diálogo de envio de trabalho do Spark
Há várias maneiras de abrir a caixa de diálogo de envio de trabalho do Spark. As maneiras incluem o Painel, o Menu de Contexto no Pesquisador de Objetos e a Paleta de Comandos.
Para abrir a caixa de diálogo de envio de trabalho do Spark, clique em Novo Trabalho do Spark no painel.

Ou clique com o botão direito do mouse no cluster no Pesquisador de Objetos e selecione Enviar Trabalho do Spark no menu de contexto.

Para abrir a caixa de diálogo de envio de trabalho do Spark com os campos Jar/Py preenchidos, clique com o botão direito do mouse em um arquivo Jar/Py no Pesquisador de Objetos e selecione Enviar Trabalho do Spark no menu de contexto.

Use Enviar Trabalho do Spark na paleta de comandos digitando Ctrl+Shift+P (no Windows) e Cmd+Shift+P (no Mac).

Enviar trabalho do Spark
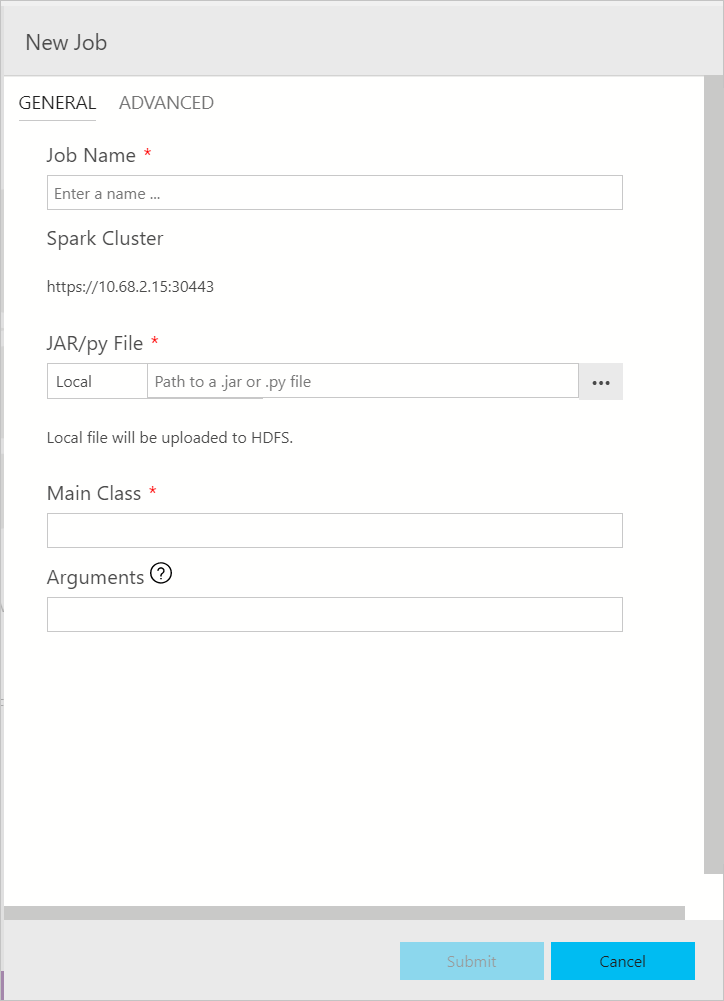
A caixa de diálogo de envio de trabalho do Spark é exibida da seguinte forma. Insira o nome do trabalho, o caminho do arquivo JAR/Py, a classe principal e os dados dos demais campos. A origem do arquivo JAR/Py pode ser local ou o HDFS. Se o trabalho do Spark tiver Jars de referência, arquivos Py ou arquivos adicionais, clique na guia AVANÇADO e insira os caminhos dos arquivos correspondentes. Clique em Enviar para enviar o trabalho do Spark.

Monitorar envio de trabalho do Spark
Após o trabalho do Spark ser enviado, as informações de status do envio e da execução do trabalho do Spark serão exibidas no Histórico de Tarefas à esquerda. Os detalhes sobre o progresso e os logs também são exibidos na janela de SAÍDA na parte inferior.
Quando o trabalho do Spark estiver em andamento, o painel Histórico de Tarefas e a janela de SAÍDA serão atualizados com o progresso.

Quando o trabalho do Spark é concluído com êxito, os links das interfaces do usuário do Spark e do YARN aparecem na janela de SAÍDA. Clique nos links para obter mais informações.

Next steps
Para obter mais informações sobre os clusters de Big Data do SQL Server e os cenários relacionados, confira O que são Clusters de Big Data do SQL Server.