Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
APLICA-SE A: Todas as camadas de gerenciamento de API
Este artigo apresenta recursos no Gerenciamento de API do Azure para ajudá-lo a gerenciar APIs de IA generativas, como as fornecidas pelo Serviço OpenAI do Azure. O Gerenciamento de API do Azure fornece uma variedade de políticas, métricas e outros recursos para aprimorar a segurança, o desempenho e a confiabilidade das APIs que atendem seus aplicativos inteligentes. Coletivamente, esses recursos são chamados de recursos de gateway de IA para suas APIs de IA generativas.
Nota
- Use os recursos de gateway de IA para gerenciar APIs expostas pelo Serviço OpenAI do Azure, disponíveis por meio da API de Inferência de Modelo de IA do Azure ou com modelos compatíveis com OpenAI servidos por meio de provedores de inferência de terceiros.
- Os recursos de gateway de IA são funcionalidades do gateway de API existente da Gestão de API, e não de um gateway de API separado. Para obter mais informações sobre o Gerenciamento de API, consulte Visão geral do Gerenciamento de API do Azure.
Desafios no gerenciamento de APIs de IA generativas
Um dos principais recursos que você tem em serviços de IA generativa são os tokens. O Serviço OpenAI do Azure atribui uma cota para as suas implantações de modelo, expressa em tokens-por-minuto (TPM), que é distribuída entre os seus consumidores de modelo - por exemplo, diferentes aplicações, equipas de desenvolvedores, departamentos dentro da empresa, etc.
O Azure facilita a conexão de um único aplicativo ao Serviço OpenAI do Azure: você pode se conectar diretamente usando uma chave de API com um limite de TPM configurado diretamente no nível de implantação do modelo. No entanto, quando o utilizador começa a aumentar o seu portfólio de aplicações, são apresentados múltiplas aplicações a aceder a pontos de extremidade únicos ou até mesmo múltiplos pontos de extremidade do Serviço OpenAI do Azure, implantados como instâncias de pagamento conforme o uso ou Unidades de Taxa de Transferência Provisionadas (PTU). Isso vem com alguns desafios:
- Como o uso do token é rastreado em vários aplicativos? As cobranças cruzadas podem ser calculadas para vários aplicativos/equipes que usam modelos do Serviço OpenAI do Azure?
- Como você garante que um único aplicativo não consuma toda a cota do TPM, deixando outros aplicativos sem opção de usar modelos do Serviço OpenAI do Azure?
- Como a chave de API é distribuída com segurança em vários aplicativos?
- Como é que a carga é distribuída entre múltiplos endpoints da Azure OpenAI? Consegues garantir que a capacidade comprometida em PTUs é esgotada antes de recorrer a instâncias de pagamento conforme o uso?
O restante deste artigo descreve como o Gerenciamento de API do Azure pode ajudá-lo a enfrentar esses desafios.
Importar recurso do Serviço OpenAI do Azure como uma API
Importar uma API de um ponto de extremidade do Azure OpenAI Service para a gestão de API do Azure usando uma experiência com um clique. O Gerenciamento de API simplifica o processo de integração importando automaticamente o esquema OpenAPI para a API OpenAI do Azure e configura a autenticação para o ponto de extremidade do Azure OpenAI usando identidade gerenciada, removendo a necessidade de configuração manual. Dentro da mesma experiência amigável, você pode pré-configurar políticas para limites de token, métricas de token de emissão e cache semântico.

Política de limite de token
Configure a política de limite de token do Azure OpenAI para gerenciar e impor limites por consumidor de API com base no uso de tokens do Serviço OpenAI do Azure. Com essa política, você pode definir um limite de taxa, expresso em tokens por minuto (TPM). Você também pode definir uma cota de token durante um período especificado, como horária, diária, semanal, mensal ou anual.
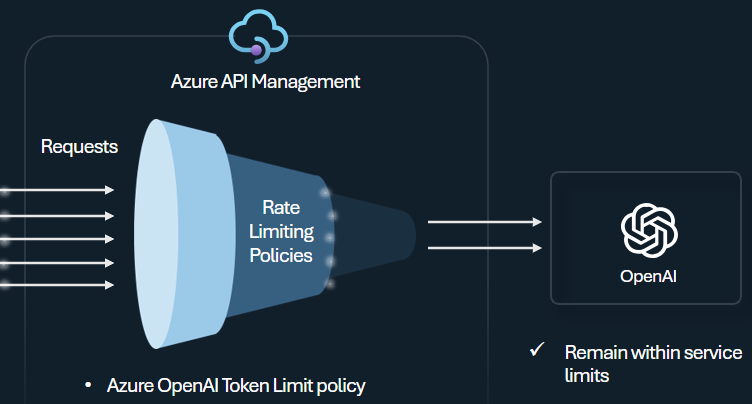
Esta política oferece flexibilidade para atribuir limites baseados em tokens em qualquer chave de contador, como chave de assinatura, endereço IP de origem ou uma chave arbitrária definida por meio de uma expressão de política. A política também permite o pré-cálculo de tokens de prompt do lado do Gerenciamento de API do Azure, minimizando solicitações desnecessárias ao backend do Serviço OpenAI do Azure se o prompt já exceder o limite.
O exemplo básico a seguir demonstra como definir um limite de TPM de 500 por chave de assinatura:
<azure-openai-token-limit counter-key="@(context.Subscription.Id)"
tokens-per-minute="500" estimate-prompt-tokens="false" remaining-tokens-variable-name="remainingTokens">
</azure-openai-token-limit>
Sugestão
Para gerenciar e impor limites de token para outras APIs LLM, o Gerenciamento de API fornece a política llm-token-limit equivalente.
Política de métrica de token de emissão
A métrica de emissão de token do Azure OpenAI envia dados de métricas para o Application Insights sobre o consumo de tokens LLM através das APIs do Serviço Azure OpenAI. A política ajuda a fornecer uma visão geral da utilização dos modelos do Serviço OpenAI do Azure em vários aplicativos ou consumidores de API. Essa política pode ser útil para cenários de estorno, monitoramento e planejamento de capacidade.

Esta política captura métricas de uso de prompt, conclusão e uso total de tokens e as envia para um namespace do Application Insights da sua escolha. Além disso, pode configurar ou selecionar a partir de dimensões predefinidas para dividir as métricas de uso dos tokens, para que possa analisar as métricas por identificação de subscrição, endereço IP ou uma dimensão personalizada à sua escolha.
Por exemplo, a política a seguir envia métricas para o Application Insights divididas por endereço IP do cliente, API e usuário:
<azure-openai-emit-token-metric namespace="openai">
<dimension name="Client IP" value="@(context.Request.IpAddress)" />
<dimension name="API ID" value="@(context.Api.Id)" />
<dimension name="User ID" value="@(context.Request.Headers.GetValueOrDefault("x-user-id", "N/A"))" />
</azure-openai-emit-token-metric>
Sugestão
Para enviar métricas para outras APIs LLM, o Gerenciamento de API fornece a política llm-emit-token-metric equivalente.
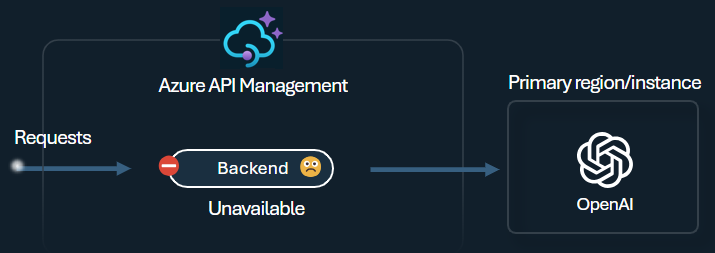
Balanceador de carga de back-end e interruptor de circuito
Um dos desafios ao criar aplicativos inteligentes é garantir que os aplicativos sejam resilientes a falhas de back-end e possam lidar com altas cargas. Ao configurar os seus pontos de extremidade do Serviço OpenAI do Azure usando backends no Gerenciamento de API do Azure, pode equilibrar a carga entre eles. Você também pode definir regras de disjuntor para parar de encaminhar solicitações para os back-ends do Serviço OpenAI do Azure se eles não estiverem respondendo.
O balanceador de carga backend suporta balanceamento de carga em round-robin, ponderado e baseado em prioridades, proporcionando-lhe flexibilidade para definir uma estratégia de distribuição de carga que atenda aos seus requisitos específicos. Por exemplo, defina prioridades dentro da configuração do balanceador de carga para garantir a utilização ideal de endpoints específicos do Azure OpenAI, particularmente aqueles adquiridos como PTUs.
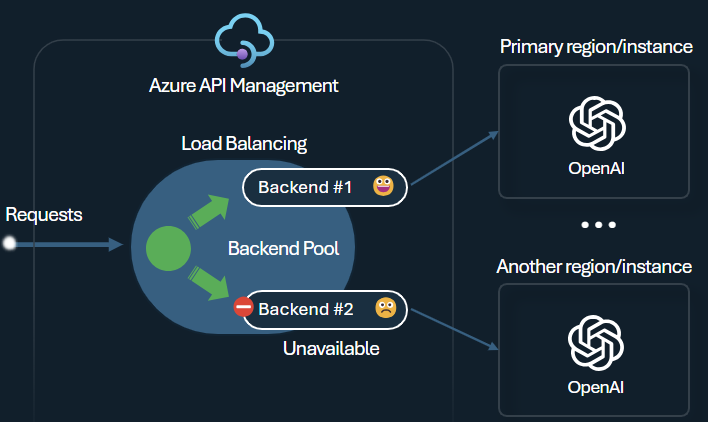
O backend disjuntor apresenta uma duração de desarme dinâmica, aplicando valores do cabeçalho Retry-After fornecido pelo backend. Isso garante a recuperação precisa e oportuna dos backends, maximizando a utilização de seus backends prioritários.
Política de cache semântico
Configure as políticas de cache semântico do Azure OpenAI para otimizar o uso de tokens ao armazenar finalizações para solicitações semelhantes.
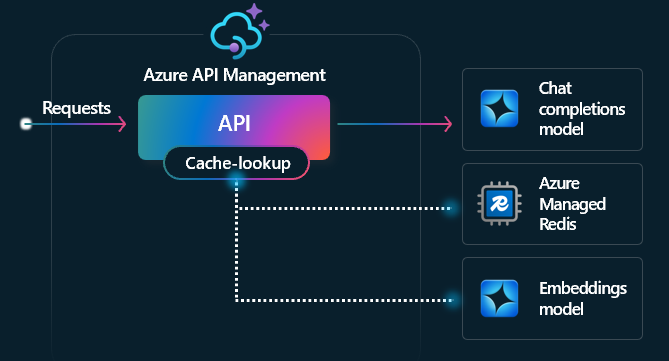
No Gerenciamento de API, habilite o cache semântico usando o Azure Redis Enterprise, o Azure Managed Redis ou outro cache externo compatível com o RediSearch e integrado ao Gerenciamento de API do Azure. Usando a API de Incorporamentos do Serviço Azure OpenAI, as políticas azure-openai-semantic-cache-store e azure-openai-semantic-cache-lookup armazenam e recuperam completações de prompt semanticamente semelhantes do cache. Essa abordagem garante a reutilização das completações, resultando em consumo reduzido de tokens e melhor desempenho de resposta.
Sugestão
Para ativar a cache semântica para outras APIs LLM, a Gestão de API fornece as políticas equivalentes llm-semantic-cache-store-policy e llm-semantic-cache-lookup-policy.
Registrando o uso, prompts e finalizações do token
Você pode habilitar o registro em log para solicitações processadas pelo gateway para APIs REST de modelo de linguagem grande. Para cada pedido, os dados são enviados para o Azure Monitor, incluindo a utilização do token (tokens de prompt, tokens de conclusão e tokens totais), o nome do modelo utilizado e, opcionalmente, as mensagens de pedido e resposta (prompt e conclusão). Grandes solicitações e respostas são divididas em várias entradas de log que são numeradas sequencialmente para reconstrução posterior, se necessário.
O administrador do Gerenciamento de API pode usar logs de gateway LLM juntamente com logs de gateway de Gerenciamento de API para cenários como os seguintes:
- Calcular uso para faturamento - Calcular métricas de uso para faturamento com base no número de tokens consumidos por cada aplicativo ou consumidor de API (por exemplo, segmentado por ID de assinatura ou endereço IP).
- Inspecionar mensagens - De modo a ajudar na depuração ou em auditoria, inspecione e analise prompts e conclusões.
Saiba mais: Registe o uso do token, os prompts e as conclusões para APIs LLM
Política de segurança de conteúdos
Para ajudar a proteger os usuários de conteúdo prejudicial, ofensivo ou enganoso, você pode moderar automaticamente todas as solicitações recebidas para uma API LLM configurando a política llm-content-safety . A política impõe verificações de segurança de conteúdo em prompts LLM, primeiro transmitindo-os para o serviço Azure AI Content Safety antes de enviar para a API LLM do back-end.

Laboratórios e amostras
- Laboratórios para as funcionalidades de gateway de IA no Gerenciamento de API do Azure
- Workshop de portal de IA
- Azure API Management (APIM) - Exemplo do Azure OpenAI (Node.js)
- Código de exemplo Python para usar o Azure OpenAI com Gerenciamento de API
Considerações sobre arquitetura e design
- Arquitetura de referência de gateway de IA usando Gerenciamento de API
- Acelerador da zona de aterragem do gateway do hub de IA
- [Projetando e implementando uma solução de gateway com recursos do Azure OpenAI](/ai/playbook/technology-guidance/generative-ai/dev-starters/gemonitoring API Management with Azurenai-gateway/)
- Utilizar uma gateway em frente a múltiplos deployments ou instâncias do Azure OpenAI
Conteúdos relacionados
- Blog: Apresentando os recursos de IA no Gerenciamento de API do Azure
- Blog: Integrando a Segurança de Conteúdo do Azure com a Gestão de API para Endpoints do Azure OpenAI
- Treinamento: gerencie suas APIs de IA generativas com o Gerenciamento de API do Azure
- Distribuição de carga inteligente para endpoints OpenAI e Gestão de API do Azure
- Autenticar e autorizar o acesso às APIs do Azure OpenAI usando o Gerenciamento de API do Azure