Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Saiba como usar o Apache Spark & Hive Tools for Visual Studio Code. Use as ferramentas para criar e enviar trabalhos em lote do Apache Hive, consultas interativas do Hive e scripts PySpark para o Apache Spark. Primeiro, descreveremos como instalar o Spark & Hive Tools no Visual Studio Code. Em seguida, explicaremos como enviar trabalhos para o Spark & Hive Tools.
O Spark & Hive Tools pode ser instalado em plataformas suportadas pelo Visual Studio Code. Observe os seguintes pré-requisitos para diferentes plataformas.
Pré-requisitos
Os seguintes itens são necessários para concluir as etapas neste artigo:
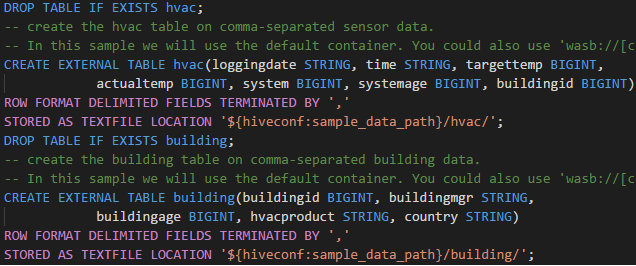
- Um cluster do Azure HDInsight. Para criar um cluster, consulte Introdução ao HDInsight. Utilize um cluster Spark e Hive que suporte uma endpoint Apache Livy.
- Visual Studio Code.
- Mono. Mono é necessário apenas para Linux e macOS.
- Um ambiente interativo PySpark para Visual Studio Code.
- Um diretório local. Este artigo usa
C:\HD\HDexample.
Instalar o Spark & Hive Tools
Depois de atender aos pré-requisitos, você pode instalar o Spark & Hive Tools for Visual Studio Code seguindo estas etapas:
Abra o Visual Studio Code.
Na barra de menus, navegue até Exibir>Extensões.
Na caixa de pesquisa, digite Spark & Hive.
Selecione Spark & Hive Tools nos resultados da pesquisa e, em seguida, selecione Instalar:
Selecione Recarregar quando necessário.
Abrir uma pasta de trabalho
Para abrir uma pasta de trabalho e criar um ficheiro no Visual Studio Code, siga estes passos:
Na barra de menus, navegue até Pasta>Abrir Arquivo...>
C:\HD\HDexamplee, em seguida, selecione o botão Selecionar Pasta. A pasta aparece na vista Explorer à esquerda.No modo de exibição Explorer , selecione a
HDexamplepasta e, em seguida, selecione o ícone Novo arquivo ao lado da pasta de trabalho:
Nomeie o novo ficheiro usando a extensão de ficheiro
.hql(consultas Hive) ou a extensão de ficheiro.py(script Spark). Este exemplo usa HelloWorld.hql.
Definir o ambiente do Azure
Para um usuário de nuvem nacional, siga estas etapas para definir o ambiente do Azure primeiro e, em seguida, use o comando Azure: Entrar para entrar no Azure:
Navegue até Ficheiro>Preferências>Definições.
Pesquisar na seguinte cadeia de caracteres: Azure: Cloud.
Selecione a nuvem nacional na lista:

Ligar a uma conta do Azure
Antes de enviar scripts para seus clusters a partir do Visual Studio Code, o usuário pode entrar na assinatura do Azure ou vincular um cluster HDInsight. Use o nome de utilizador/palavra-passe do Ambari ou a credencial de ingresso no domínio para o cluster ESP para ligar ao seu cluster HDInsight. Siga estas etapas para se conectar ao Azure:
Na barra de menus, navegue até Ver>Paleta de Comandos..., e digite Azure: Entrar:

Siga as instruções de início de sessão para iniciar sessão no Azure. Depois que você estiver conectado, o nome da sua conta do Azure será exibido na barra de status na parte inferior da janela Código do Visual Studio.
Vincular um cluster
Link: Azure HDInsight
Você pode vincular um cluster normal usando um nome de usuário gerenciado pelo Apache Ambari ou pode vincular um cluster Hadoop seguro do Enterprise Security Pack usando um nome de usuário de domínio (como: user1@contoso.com).
Na barra de menus, navegue até Ver>Paleta de Comandos..., e digite Spark / Hive: Vincular um Cluster.

Selecione o tipo de cluster vinculado Azure HDInsight.
Insira a URL do cluster HDInsight.
Digite seu nome de usuário Ambari; O padrão é admin.
Digite sua senha Ambari.
Selecione o tipo de cluster.
Defina o nome para exibição do cluster (opcional).
Revise o modo de exibição OUTPUT para verificação.
Nota
O nome de utilizador e a palavra-passe vinculados serão usados se o cluster tiver iniciado sessão na subscrição do Azure e ligado a um cluster.
Link: Ponto final Livy Genérico
Na barra de menus, navegue até Ver>Paleta de Comandos..., e digite Spark / Hive: Vincular um Cluster.
Selecione o tipo de cluster ligado Generic Livy Endpoint.
Insira o ponto de extremidade Livy genérico. Por exemplo: http://10.172.41.42:18080.
Selecione o tipo de autorização Basic ou None. Se você selecionar Básico:
Digite seu nome de usuário Ambari; O padrão é admin.
Digite sua senha Ambari.
Revise o modo de exibição OUTPUT para verificação.
Listar clusters
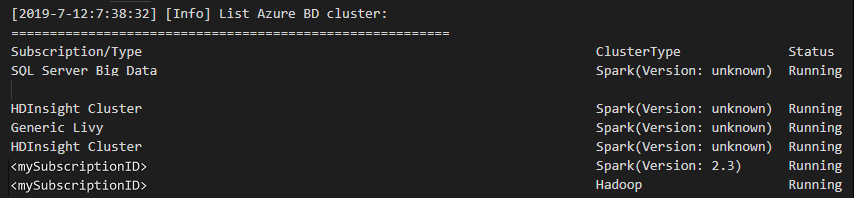
Na barra de menus, navegue até View>Command Palette..., e digite Spark / Hive: List Cluster.
Selecione a assinatura desejada.
Revise a visualização de saída. Esta vista mostra o seu cluster (ou clusters) ligado e todos os clusters na sua subscrição do Azure:
Definir o cluster padrão
Volte a abrir a pasta que foi discutida
HDexampleanteriormente, caso esteja fechada.Selecione o arquivo HelloWorld.hql que foi criado anteriormente. Ele é aberto no editor de scripts.
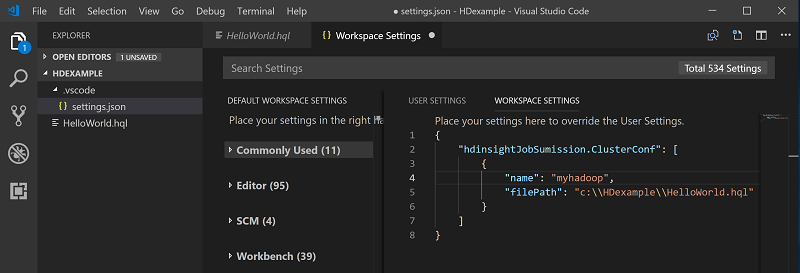
Clique com o botão direito do mouse no editor de scripts e selecione Faísca / Colmeia: Definir cluster padrão.
Conecte-se à sua conta do Azure ou vincule um cluster se ainda não tiver feito isso.
Selecione um cluster como o cluster padrão para o arquivo de script atual. As ferramentas atualizam automaticamente o . VSCode\settings.json arquivo de configuração:
Enviar consultas interativas do Hive e scripts em lote do Hive
Com o Spark & Hive Tools for Visual Studio Code, você pode enviar consultas interativas do Hive e scripts em lote do Hive para seus clusters.
Reabra a
HDexamplepasta que foi discutida anteriormente, se fechada.Selecione o arquivo HelloWorld.hql que foi criado anteriormente. Ele é aberto no editor de scripts.
Copie e cole o seguinte código no arquivo do Hive e salve-o:
SELECT * FROM hivesampletable;Conecte-se à sua conta do Azure ou vincule um cluster se ainda não tiver feito isso.
Clique com o botão direito do mouse no editor de scripts e selecione Hive: Interactive para enviar a consulta ou use o atalho de teclado Ctrl+Alt+I. Selecione Hive: Batch para enviar o script ou use o atalho de teclado Ctrl+Alt+H.
Se você não tiver especificado um cluster padrão, selecione um cluster. As ferramentas também permitem enviar um bloco de código em vez de todo o arquivo de script usando o menu de contexto. Após alguns momentos, os resultados da consulta aparecem em uma nova guia:
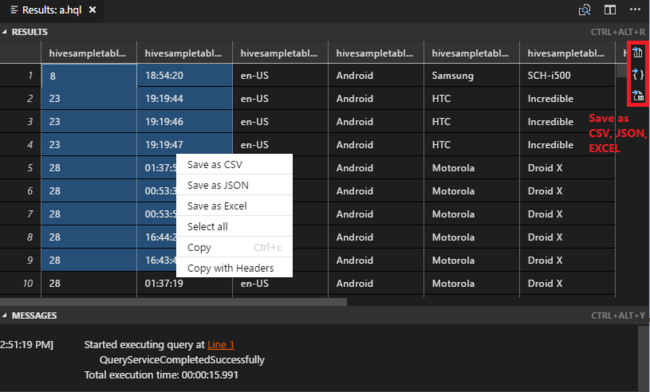
Painel RESULTADOS : Você pode salvar todo o resultado como um arquivo CSV, JSON ou Excel em um caminho local ou apenas selecionar várias linhas.
Painel MENSAGENS : Quando você seleciona um número de linha , ele salta para a primeira linha do script em execução.
Enviar consultas interativas do PySpark
Pré-requisito para o Pyspark interativo
Observe aqui que a versão do Jupyter Extension (ms-jupyter): v2022.1.1001614873 e a versão Python Extension (ms-python): v2021.12.1559732655, Python 3.6.x e 3.7.x são necessárias para consultas interativas do PySpark do HDInsight.
Os usuários podem executar o PySpark interativo das seguintes maneiras.
Usando o comando interativo PySpark no arquivo PY
Usando o comando interativo PySpark para enviar as consultas, siga estas etapas:
Reabra a
pasta que foi discutida anteriormente , se estiver fechada. Crie um novo arquivo HelloWorld.py , seguindo as etapas anteriores .
Copie e cole o seguinte código no arquivo de script:
from operator import add from pyspark.sql import SparkSession spark = SparkSession.builder \ .appName('hdisample') \ .getOrCreate() lines = spark.read.text("/HdiSamples/HdiSamples/FoodInspectionData/README").rdd.map(lambda r: r[0]) counters = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) coll = counters.collect() sortedCollection = sorted(coll, key = lambda r: r[1], reverse = True) for i in range(0, 5): print(sortedCollection[i])O prompt para instalar o kernel PySpark/Synapse Pyspark é exibido no canto inferior direito da janela. Você pode clicar no botão Instalar para prosseguir para as instalações do PySpark/Synapse Pyspark, ou clicar no botão Ignorar para pular esta etapa.
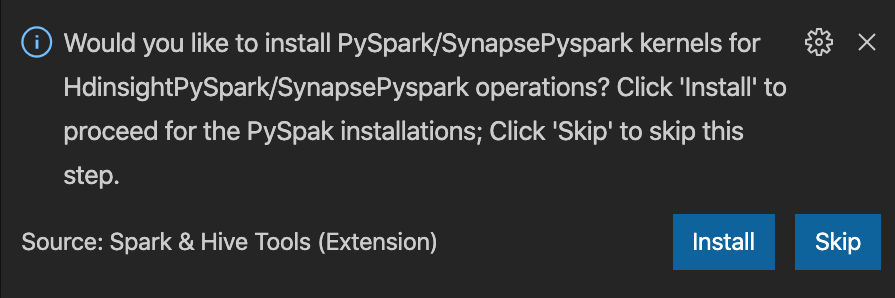
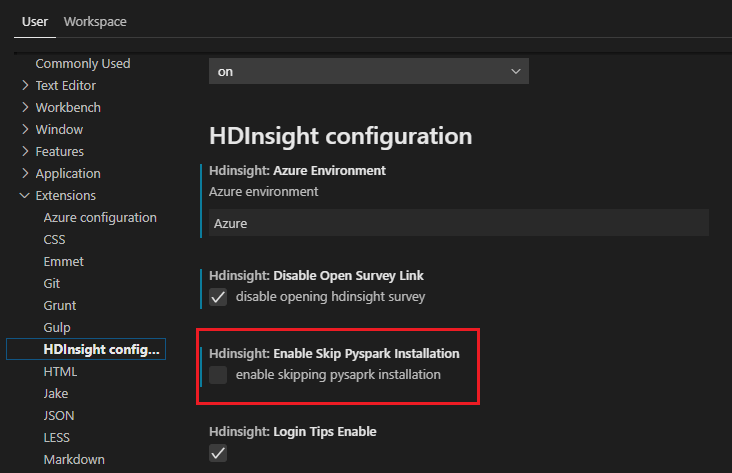
Se precisar de instalá-lo mais tarde, pode navegar até Ficheiro>Preferências>Definições e, em seguida, nas Definições, desmarcar HDInsight: Ativar Ignorar Instalação do Pyspark.
Se a instalação for bem-sucedida na etapa 4, a caixa de mensagem "PySpark instalado com êxito" é exibida no canto inferior direito da janela. Clique no botão Recarregar para recarregar a janela.

Na barra de menus, navegue até View>Command Palette... ou use o atalho de teclado Shift + Ctrl + P e digite Python: Select Interpreter para iniciar o Jupyter Server.

Selecione a opção Python abaixo.

Na barra de menus, navegue até View>Command Palette... ou use o atalho de teclado Shift + Ctrl + P e digite Developer: Reload Window.

Conecte-se à sua conta do Azure ou vincule um cluster se ainda não tiver feito isso.
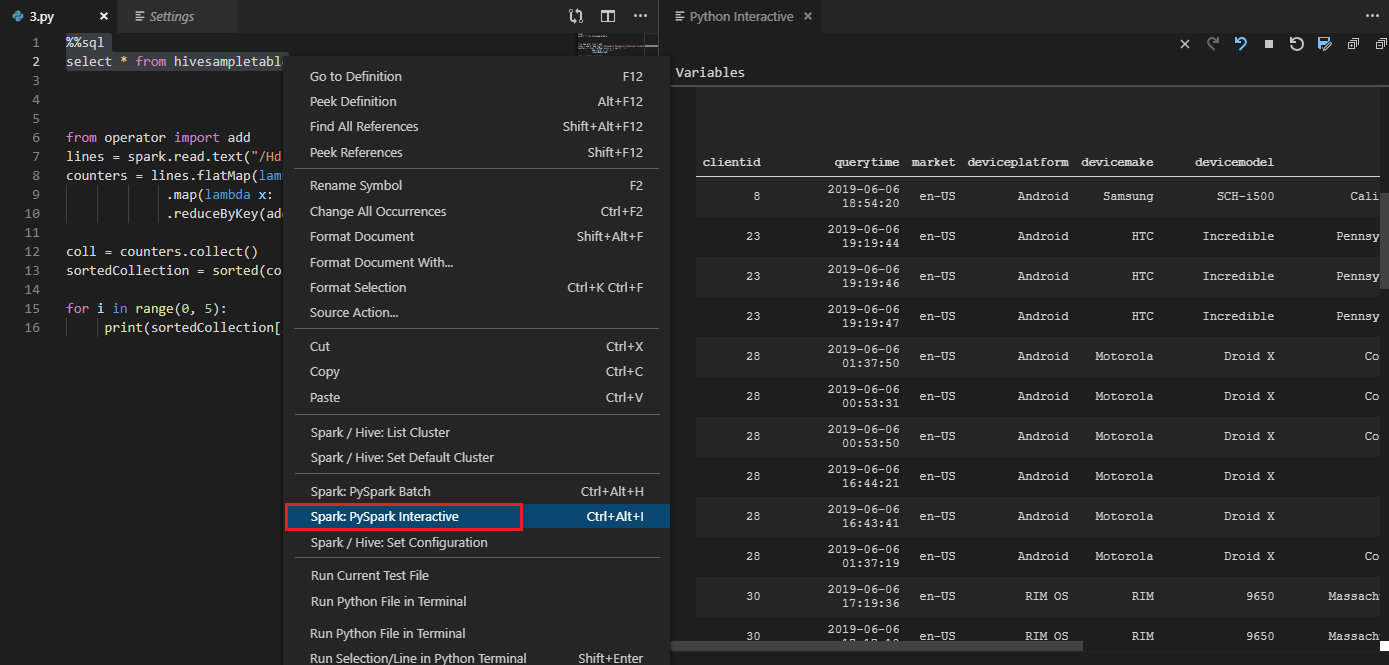
Selecione todo o código, clique com o botão direito do mouse no editor de scripts e selecione Spark: PySpark Interactive / Synapse: Pyspark Interactive para enviar a consulta.

Selecione o cluster, se você não tiver especificado um cluster padrão. Depois de alguns momentos, os resultados do Python Interactive aparecem em uma nova guia. Clique em PySpark para mudar o kernel para PySpark / Synapse Pyspark, e o código será executado com sucesso. Se você quiser alternar para o kernel Synapse Pyspark, a desativação das configurações automáticas no portal do Azure é incentivada. Caso contrário, pode levar muito tempo para ativar o cluster e definir o kernel de sinapse para o primeiro uso. Se as ferramentas também permitirem que você envie um bloco de código em vez de todo o arquivo de script usando o menu de contexto:

Digite %%info e pressione Shift+Enter para exibir as informações do trabalho (opcional):

A ferramenta também suporta a consulta Spark SQL :
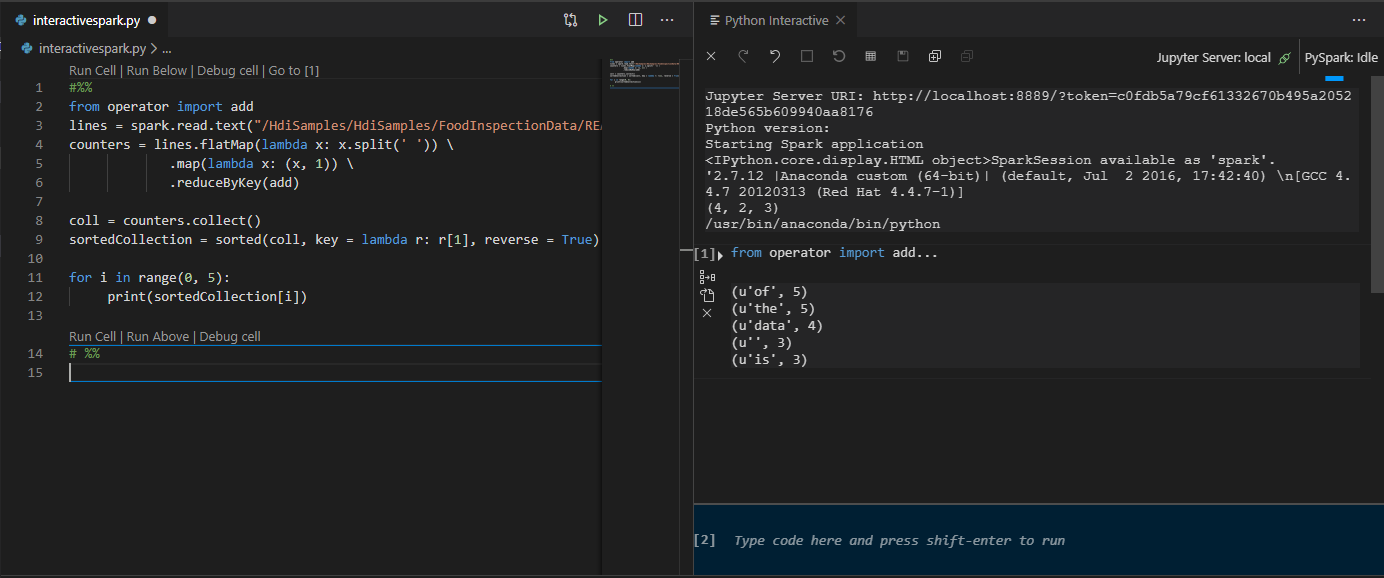
Execute uma consulta interativa no arquivo PY usando um comentário #%%
Adicione #%% antes do código Py para obter experiência no notebook.
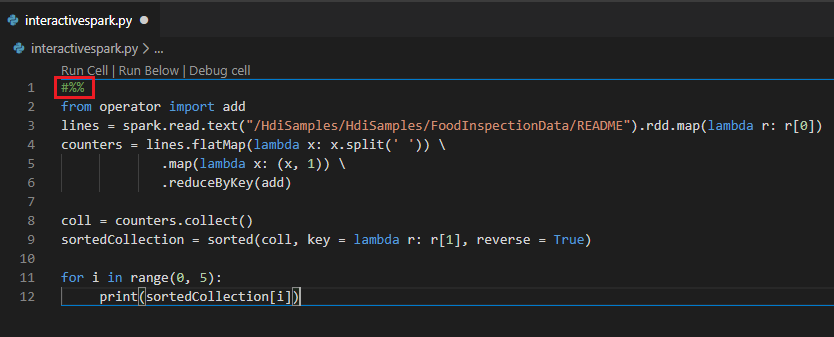
Clique em Executar Célula. Após alguns momentos, os resultados do Python Interactive aparecem em uma nova guia. Clique em PySpark para mudar o kernel para PySpark/Synapse PySpark, em seguida, clique em Run Cell novamente, e o código será executado com sucesso.
Aproveite o suporte IPYNB da extensão Python
Você pode criar um Jupyter Notebook por comando a partir da Paleta de Comandos ou criando um novo
.ipynbarquivo em seu espaço de trabalho. Para obter mais informações, consulte Trabalhando com blocos de anotações Jupyter no Visual Studio CodeClique no botão Executar célula, siga as instruções para definir o cluster/pool de faíscas padrão (sugerimos que se defina o cluster/pool padrão sempre antes de abrir um bloco de anotações) e, em seguida, Recarregue a janela.
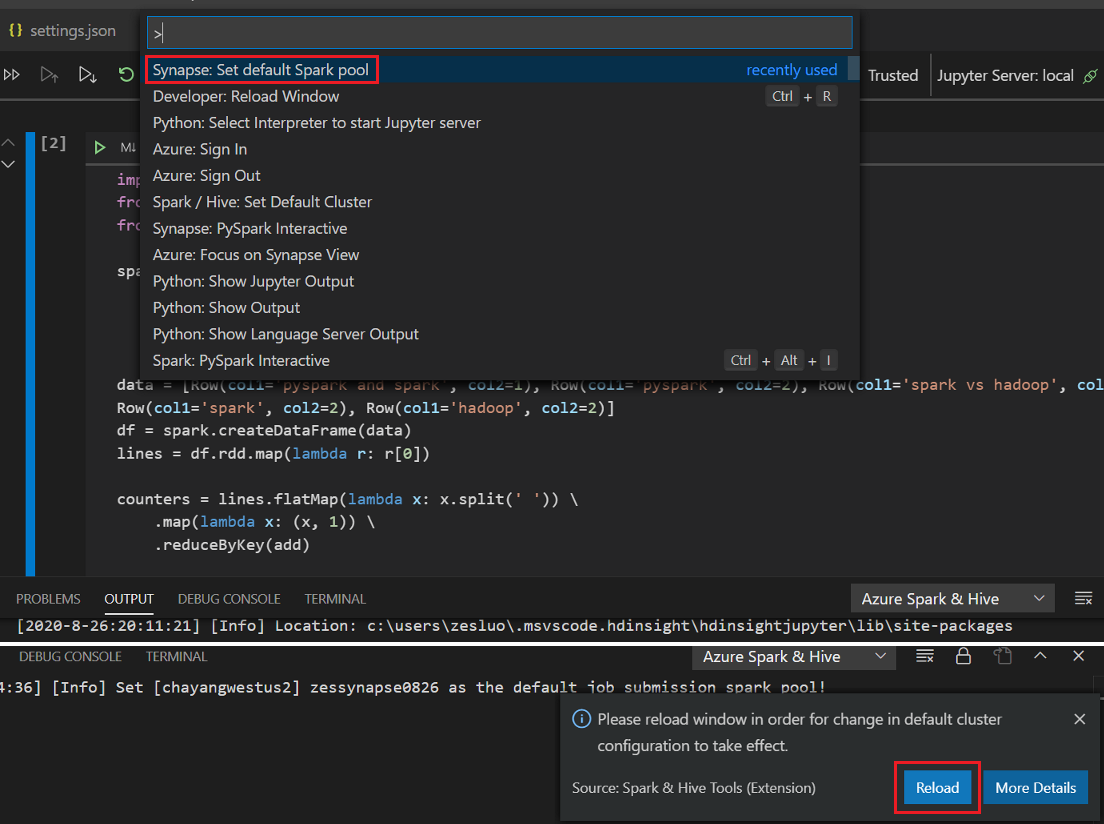
Clique em PySpark para mudar o kernel para PySpark / Synapse Pyspark e, em seguida, clique em Run Cell, depois de um tempo, o resultado será exibido.

Nota
Para o erro de instalação do Synapse PySpark, uma vez que a sua dependência não será mais mantida por outra equipa, isto também deixará de ser mantido. Se você tentar usar o Synapse Pyspark interativo, alterne para usar o Azure Synapse Analytics em vez disso. E é uma mudança a longo prazo.
Enviar tarefa em lote do PySpark
Reabra a
HDexamplepasta que discutiu anteriormente, caso esteja fechada.Crie um novo arquivo BatchFile.py seguindo as etapas anteriores .
Copie e cole o seguinte código no arquivo de script:
from __future__ import print_function import sys from operator import add from pyspark.sql import SparkSession if __name__ == "__main__": spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() lines = spark.read.text('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv').rdd.map(lambda r: r[0]) counts = lines.flatMap(lambda x: x.split(' '))\ .map(lambda x: (x, 1))\ .reduceByKey(add) output = counts.collect() for (word, count) in output: print("%s: %i" % (word, count)) spark.stop()Conecte-se à sua conta do Azure ou vincule um cluster se ainda não tiver feito isso.
Clique com o botão direito do mouse no editor de scripts e selecione Spark: PySpark Batch ou Synapse: PySpark Batch*.
Selecione um cluster/pool de Spark para submeter a sua tarefa de PySpark:

Depois de enviar um trabalho Python, os logs de envio aparecem na janela OUTPUT no Visual Studio Code. A URL da interface do usuário do Spark e a URL da interface do usuário do Yarn também são mostradas. Se enviar o trabalho em lote para um pool do Apache Spark, as URLs do histórico do Spark UI e do aplicativo Spark Job UI também serão mostradas. Você pode abrir a URL em um navegador da Web para acompanhar o status do trabalho.
Integração com o HDInsight Identity Broker (HIB)
Conectar-se ao cluster ESP do HDInsight com o ID Broker (HIB)
Você pode seguir as etapas normais para entrar na assinatura do Azure para se conectar ao cluster ESP do HDInsight com o ID Broker (HIB). Após entrar, você verá a lista de clusters no Azure Explorer. Para obter mais instruções, consulte Conectar-se ao cluster HDInsight.
Executar um trabalho Hive/PySpark num cluster ESP do HDInsight com ID Broker (HIB)
Para executar um trabalho de hive, você pode seguir as etapas normais para enviar o trabalho para o cluster ESP do HDInsight com o ID Broker (HIB). Consulte Submeter consultas interativas do Hive e scripts do Hive em lote para obter mais instruções.
Para executar um trabalho interativo do PySpark, você pode seguir as etapas normais para enviar o trabalho para o cluster ESP do HDInsight com o ID Broker (HIB). Consulte o envio de consultas interativas do PySpark.
Para executar um trabalho em lote do PySpark, você pode seguir as etapas normais para enviar o trabalho para o cluster ESP do HDInsight com ID Broker (HIB). Consulte Submeter tarefa em lote do PySpark para obter mais instruções.
Configuração do Apache Livy
A configuração do Apache Livy é suportada. Você pode configurá-lo no . VSCode\settings.json na pasta de espaço de trabalho. Atualmente, a configuração do Livy suporta apenas script Python. Para obter mais informações, consulte Livy README.
Como acionar a configuração do Livy
Método 1
- Na barra de menus, navegue até Ficheiro>Preferências>Configurações.
- Na caixa Configurações de Pesquisa, digite Envio de Trabalho do HDInsight: Livy Conf.
- Selecione Editar em settings.json para o resultado de pesquisa relevante.
Método 2
Envie um arquivo e observe que a pasta é adicionada .vscode automaticamente à pasta de trabalho. Você pode ver a configuração do Livy selecionando .vscode\settings.json.
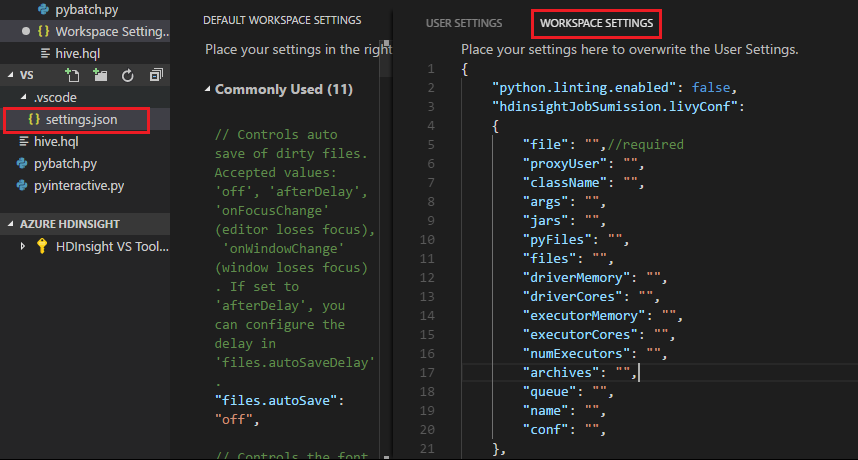
As configurações do projeto:
Nota
Para as configurações driverMemory e executorMemory , defina o valor e a unidade. Por exemplo: 1g ou 1024m.
Configurações Livy suportadas:
POST /lotes
Corpo do pedido
nome descrição tipo ficheiro Arquivo contendo o aplicativo a ser executado Caminho (obrigatório) proxyUser Utilizador a ser representado ao executar a tarefa String className Classe principal do aplicativo Java/Spark String args Argumentos de linha de comando para o aplicativo Lista de cadeias de caracteres frascos Frascos a serem utilizados nesta sessão Lista de cadeias de caracteres Ficheiros py Arquivos Python a serem usados nesta sessão Lista de cadeias de caracteres ficheiros Ficheiros a utilizar nesta sessão Lista de cadeias de caracteres driverMemória Quantidade de memória a ser utilizada para o processo do controlador String driverCores Número de núcleos a serem usados para o processo do controlador Int memória do executor Quantidade de memória a ser usada por processo de execução String executorCores Número de núcleos a serem usados para cada executor Int numExecutores Número de executores a serem iniciados para esta sessão Int Arquivos Arquivos a utilizar nesta sessão Lista de cadeias de caracteres fila Nome da fila YARN a ser enviada String nome Nome desta sessão String conf Propriedades de configuração do Spark Mapa da chave=val Corpo da resposta O objeto Batch criado.
nome descrição tipo ID ID da Sessão Int ID do aplicativo ID do aplicativo desta sessão String appInfo Informações detalhadas sobre a aplicação Mapa de key=val registo Linhas de log Lista de cadeias de caracteres estado Estado do lote fio Nota
A configuração Livy atribuída é exibida no painel de saída quando você envia o script.
Integração com o Azure HDInsight a partir do Explorer
Você pode visualizar a Tabela do Hive em seus clusters diretamente por meio do explorador do Azure HDInsight :
Conecte-se à sua conta do Azure se ainda não tiver feito isso.
Selecione o ícone do Azure na coluna mais à esquerda.
No painel esquerdo, expanda AZURE: HDINSIGHT. As assinaturas e clusters disponíveis são listados.
Expanda o cluster para exibir o banco de dados de metadados do Hive e o esquema de tabela.
Clique com o botão direito do rato na tabela Hive. Por exemplo: hivesampletable. Selecione Pré-visualizar.
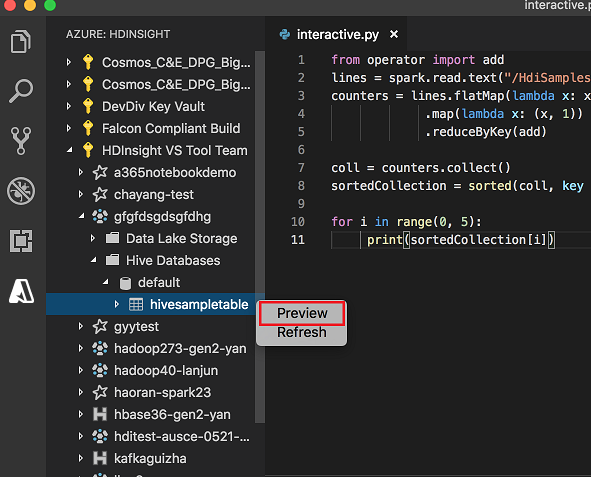
A janela Visualizar resultados abre:
Janela de pré-visualização dos resultados do Spark & Hive para Visual Studio Code.
Painel Resultados
Você pode salvar todo o resultado como um arquivo CSV, JSON ou Excel em um caminho local ou apenas selecionar várias linhas.
Painel de Mensagens
Quando o número de linhas na tabela é maior que 100, você vê a seguinte mensagem: "As primeiras 100 linhas são exibidas para a tabela Hive."
Quando o número de linhas na tabela é menor ou igual a 100, você vê a seguinte mensagem: "60 linhas são exibidas para a tabela Hive."
Quando não há conteúdo na tabela, você vê a seguinte mensagem: "
0 rows are displayed for Hive table."Nota
No Linux, instale o xclip para permitir a cópia de dados de tabelas.

Características adicionais
O Spark & Hive for Visual Studio Code também oferece suporte aos seguintes recursos:
Preenchimento automático do IntelliSense. Sugestões aparecem para palavras-chave, métodos, variáveis e outros elementos de programação. Ícones diferentes representam diferentes tipos de objetos:
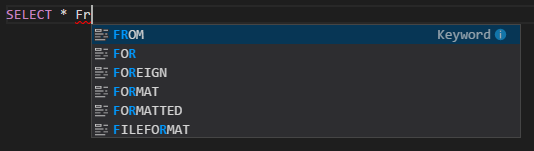
Marcador de erro do IntelliSense. O serviço de linguagem sublinha erros de edição no script do Hive.
Destaques de sintaxe. O serviço de linguagem usa cores diferentes para diferenciar variáveis, palavras-chave, tipo de dados, funções e outros elementos de programação:
Função somente de leitor
Os usuários aos quais é atribuída a função somente leitor para o cluster não podem enviar trabalhos para o cluster HDInsight, nem exibir o banco de dados do Hive. Entre em contacto com o administrador do cluster para atualizar a sua função para Operador de Cluster HDInsight no portal Azure. Se você tiver credenciais Ambari válidas, poderá vincular manualmente o cluster usando as diretrizes a seguir.
Navegar no cluster HDInsight
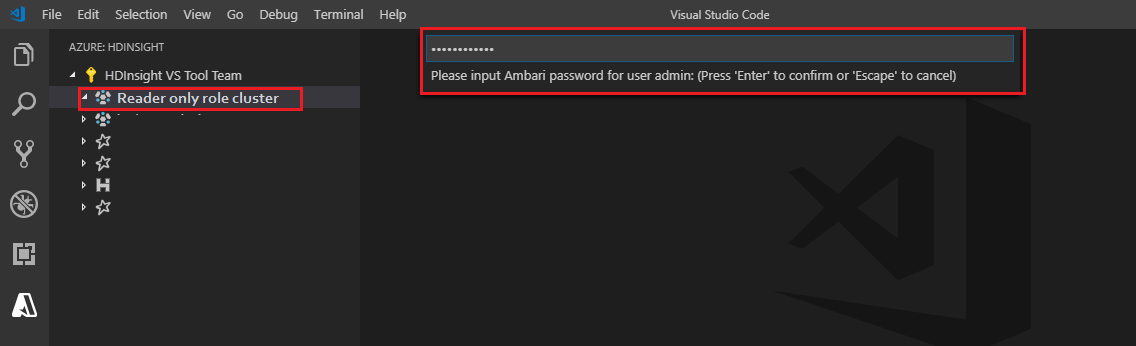
Ao selecionar o explorador do Azure HDInsight para expandir um cluster HDInsight, você será solicitado a vincular o cluster se tiver a função somente leitor para o cluster. Use o método a seguir para vincular ao cluster usando suas credenciais Ambari.
Enviar o trabalho para o cluster HDInsight
Ao enviar o trabalho para um cluster HDInsight, você será solicitado a vincular o cluster se estiver na função somente leitor para o cluster. Use as etapas a seguir para vincular ao cluster usando credenciais do Ambari.
Ligação ao cluster
Insira um nome de usuário Ambari válido.
Introduza uma palavra-passe válida.

Nota
Você pode usar
Spark / Hive: List Clusterpara verificar o cluster vinculado:
Azure Data Lake Storage Gen2
Navegar numa conta do Data Lake Storage Gen2
Selecione o explorador do Azure HDInsight para expandir uma conta do Data Lake Storage Gen2. Você será solicitado a inserir a chave de acesso de armazenamento se sua conta do Azure não tiver acesso ao armazenamento Gen2. Depois que a chave de acesso for validada, a conta do Data Lake Storage Gen2 será expandida automaticamente.
Enviar trabalhos para um cluster HDInsight com o Data Lake Storage Gen2
Envie um trabalho para um cluster HDInsight usando o Data Lake Storage Gen2. Você será solicitado a inserir a chave de acesso de armazenamento se sua conta do Azure não tiver acesso de gravação ao armazenamento Gen2. Depois que a chave de acesso for validada, o trabalho será enviado com sucesso.

Nota
Você pode obter a chave de acesso para a conta de armazenamento no portal do Azure. Para obter mais informações, consulte Gerenciar chaves de acesso da conta de armazenamento.
Desvincular o cluster
Na barra de menus, vá para Exibir>Paleta de Comandos, e depois digite Spark / Hive: Desvincular um Cluster.
Selecione um cluster para desvincular.
Consulte a visualização OUTPUT para verificação.
Terminar sessão
Na barra de menus, vá para Ver>Paleta de Comandos e digite Azure: Sair.
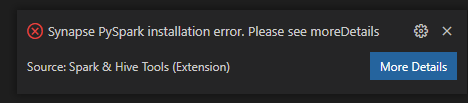
Problemas Conhecidos
Erro de instalação do Synapse PySpark.
Para erro de instalação do Synapse PySpark, uma vez que sua dependência não será mais mantida por outra equipe, ela não será mais mantida. Se tentar usar o Synapse Pyspark interativo, utilize Azure Synapse Analytics em vez disso. E é uma mudança a longo prazo.
Próximos passos
Para obter um vídeo que demonstra o uso do Spark & Hive para Visual Studio Code, consulte Spark & Hive para Visual Studio Code.