Como funcionam os modelos de linguagem?
Ao longo das últimas décadas, múltiplos desenvolvimentos no campo do processamento de linguagem natural (PNL) resultaram na obtenção de grandes modelos de linguagem (LLMs). O desenvolvimento e a disponibilidade de modelos de linguagem levaram a novas formas de interagir com aplicações e sistemas, nomeadamente através de assistentes e agentes de IA generativa.
Vamos dar uma olhada nos desenvolvimentos históricos para modelos de linguagem que incluem:
- Tokenização: permitir que as máquinas leiam.
- Incorporação de palavras: permitindo que as máquinas capturem a relação entre palavras.
- Desenvolvimentos arquitetónicos: (alterações na conceção de modelos de linguagem) que lhes permitem captar o contexto das palavras.
Tokenização
Como poderá esperar, as máquinas têm dificuldade em decifrar textos, pois dependem principalmente de números. Para ler o texto, precisamos, portanto, converter o texto apresentado em números.
Um importante desenvolvimento para permitir que as máquinas trabalhem mais facilmente com texto tem sido a tokenização. Tokens são cadeias de caracteres com um significado conhecido, geralmente representando uma palavra. Tokenização é transformar palavras em tokens, que são então convertidos em números. Uma abordagem estatística à tokenização é através do uso de um pipeline:
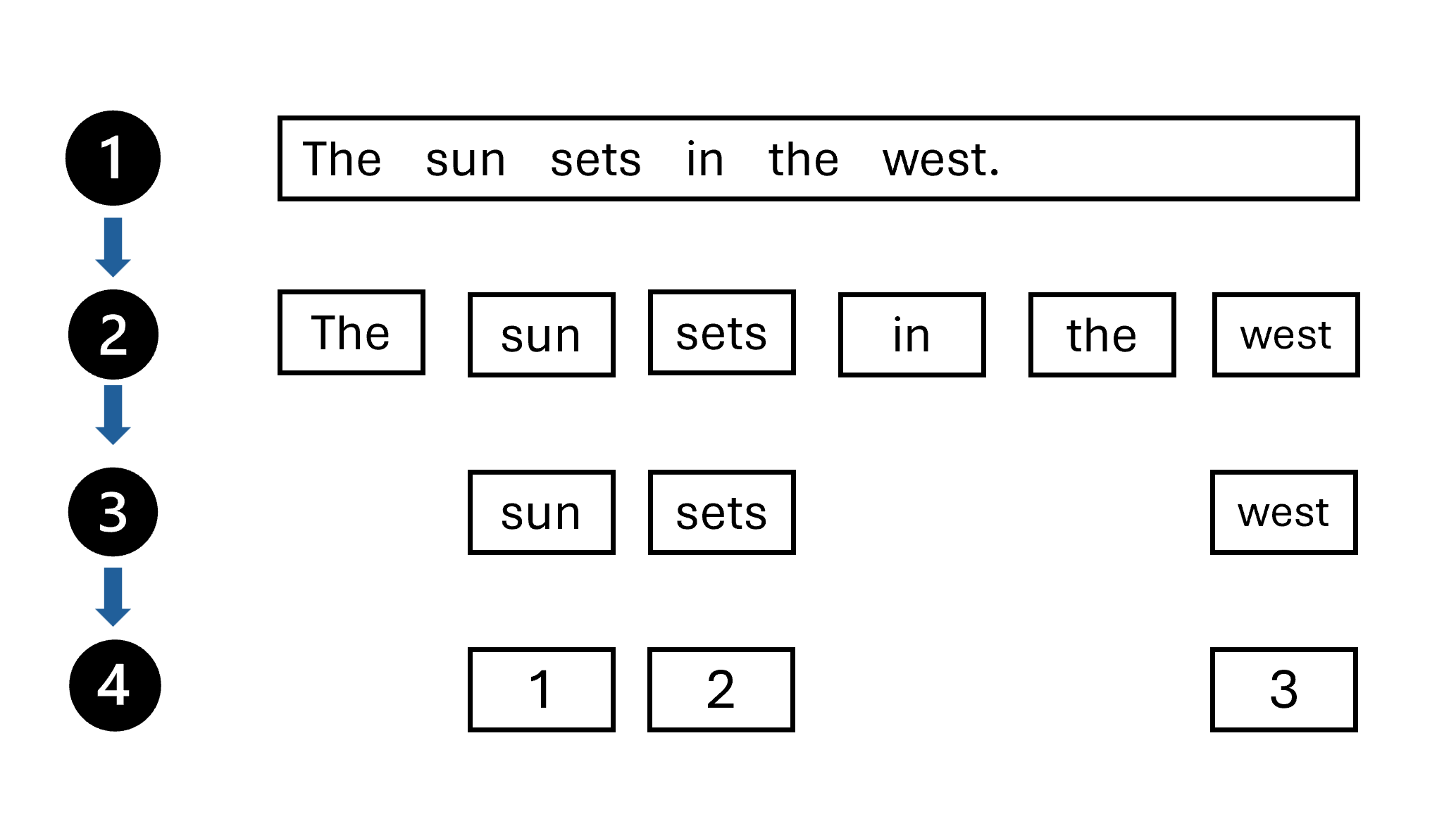
- Comece com o texto que você deseja tokenizar.
- Divida as palavras no texto com base numa regra. Por exemplo, divide as palavras onde houver um espaço em branco.
-
Remoção de palavras irrelevantes. Remova palavras ruidosas que têm pouco significado, como
theea. Um dicionário destas palavras é fornecido para removê-las estruturalmente do texto. - Atribua um número a cada token exclusivo.
A tokenização permitiu que o texto fosse rotulado. Como resultado, técnicas estatísticas poderiam ser usadas para permitir que os computadores encontrem padrões nos dados, em vez de aplicar modelos baseados em regras.
Incorporações de palavras
Um dos conceitos-chave introduzidos pela aplicação de técnicas de deep learning ao PLN é incorporações de palavras (word embeddings). As incorporações de palavras abordam o problema de não ser capaz de definir a relação semântica entre palavras.
As incorporações de palavras são criadas durante o processo de treinamento do modelo de aprendizagem profunda. Durante o treinamento, o modelo analisa os padrões de coocorrência de palavras em frases e aprende a representá-las como vetores. Um vetor representa um caminho através de um ponto no espaço n-dimensional (em outras palavras, uma linha). As relações semânticas são definidas pela semelhança dos ângulos das linhas (ou seja, a direção do caminho). Como as incorporações de palavras representam palavras em um espaço vetorial, a relação entre palavras pode ser facilmente descrita e calculada.
Para criar um vocabulário que encapsula relações semânticas entre os tokens, definimos vetores contextuais, conhecidos como incorporações, para eles. Vetores são representações numéricas de vários valores de informação, por exemplo [10, 3, 1] em que cada elemento numérico representa um atributo particular da informação. Para tokens de idioma, cada elemento do vetor de um token representa algum atributo semântico do token. As categorias específicas para os elementos dos vetores em um modelo de linguagem são determinadas durante o treinamento com base na frequência com que as palavras são usadas juntas ou em contextos semelhantes.
Os vetores representam linhas no espaço multidimensional, descrevendo a direção e a distância ao longo de vários eixos (você pode impressionar seus amigos matemáticos chamando essas amplitude e magnitude). No geral, o vetor descreve a direção e a distância do caminho da origem ao fim.

Os elementos dos tokens no espaço de incorporação representam cada um algum atributo semântico do token, de modo que tokens semanticamente semelhantes devem resultar em vetores que têm uma orientação semelhante – em outras palavras, eles apontam na mesma direção. Uma técnica chamada semelhança do cosseno é usada para determinar se dois vetores têm direções semelhantes (independentemente da distância) e, portanto, representam palavras semanticamente ligadas. Por exemplo, os vetores de incorporação para "cão" e "filhote" descrevem um caminho ao longo de uma direção quase idêntica, que também é bastante semelhante à direção para "gato". O vetor de incorporação para "skateboard", no entanto, descreve a jornada numa direção bastante diferente.
Empreendimentos arquitetónicos
A arquitetura, ou design, de um modelo de aprendizado de máquina descreve a estrutura e a organização de seus vários componentes e processos. Ele define como os dados são processados, como os modelos são treinados e avaliados e como as previsões são geradas. Um dos primeiros avanços na arquitetura de modelos de linguagem foram as Redes Neurais Recorrentes (RNNs).
Para compreender um texto não é apenas entender palavras individuais, apresentadas isoladamente. As palavras podem diferir em seu significado dependendo do contexto em que são apresentadas. Em outras palavras, a frase em torno de uma palavra importa para o significado da palavra.
Os RNNs são capazes de levar em conta o contexto das palavras através de várias etapas sequenciais. Cada etapa leva uma entrada e um estado oculto. Imagine que a entrada em cada passo seja uma nova palavra. Cada etapa também produz uma saída. O estado oculto pode servir como uma memória da rede, armazenando o resultado do passo anterior e passando-o como entrada para o próximo passo.
Imagine uma frase como:
Vincent Van Gogh was a painter most known for creating stunning and emotionally expressive artworks, including ...
Para saber qual palavra vem a seguir, precisa lembrar o nome do pintor. A frase precisa ser completada, pois ainda falta a última palavra. Uma palavra ausente ou mascarada em tarefas de PNL geralmente é representada com [MASK]. Ao utilizar o token especial [MASK] numa frase, pode informar um modelo de linguagem que precisa prever qual é o token ou valor em falta.
Simplificando a frase de exemplo, pode fornecer a seguinte entrada a um RNN: Vincent was a painter known for [MASK].

O RNN toma cada token como uma entrada, processa-o e atualiza o estado oculto com uma memória desse token. Quando o próximo token é processado como nova entrada, o estado oculto do passo anterior é atualizado.
Finalmente, o último token é apresentado como entrada para o modelo, nomeadamente o token [MASK]. Indicar que há informações em falta e que o modelo precisa prever o seu valor. A RNN então usa o estado oculto para prever que a saída deve ser algo como Starry Night

Desafios com RNNs
No exemplo, o estado oculto contém as informações Vincent, is, painter e know. Com RNNs, cada um desses tokens é igualmente importante no estado oculto e, portanto, igualmente considerados ao prever a saída.
As RNNs permitem que o contexto seja incluído ao decifrar o significado de uma palavra em relação à frase completa. No entanto, à medida que o estado oculto de um RNN é atualizado com cada token, a informação relevante real, ou sinal, pode ser perdida.
No exemplo fornecido, o nome de Vincent Van Gogh está no início da frase, enquanto a máscara está no fim. No passo final, quando a máscara é apresentada como entrada, o estado oculto pode conter uma grande quantidade de informação que é irrelevante para prever a saída da máscara. Como o estado oculto tem um tamanho limitado, as informações relevantes podem até ser apagadas para dar lugar a informações novas e mais recentes.
Quando lemos esta frase, sabemos que apenas certas palavras são essenciais para prever a última palavra. "Um RNN, no entanto, inclui toda a informação (relevante e irrelevante) num estado oculto." Como resultado, as informações relevantes podem se tornar um sinal fraco no estado oculto, o que significa que podem ser ignoradas porque há muitas outras informações irrelevantes influenciando o modelo.
Até agora, descrevemos como os modelos de linguagem podem ler texto através da tokenização e como eles podem entender a relação entre as palavras através da incorporação de palavras. Explorámos também como os modelos de linguagem do passado tentavam captar o contexto das palavras. Em seguida, aprenda como as limitações dos modelos anteriores são tratadas nos modelos de linguagem atuais com arquitetura de transformadores.