Compreender os modelos de visão modernos
As CNNs estão no centro das soluções de visão computacional há muitos anos. Embora sejam comumente usados para resolver problemas de classificação de imagem, conforme descrito anteriormente, eles também são a base para modelos de visão computacional mais complexos. Por exemplo, os modelos de deteção de objetos combinam camadas de extração de recursos CNN com a identificação de regiões de interesse em imagens para localizar várias classes de objeto na mesma imagem.
Transformadores
A maioria dos avanços na visão computacional ao longo das décadas foi impulsionada por melhorias nos modelos baseados na CNN. No entanto, em outra disciplina de IA - processamento de linguagem natural (NLP), outro tipo de arquitetura de rede neural, chamado de transformador , permitiu o desenvolvimento de modelos sofisticados para a linguagem. Os transformadores funcionam processando grandes volumes de dados e codificando tokens de linguagem (representando palavras ou frases individuais) como incorporações baseadas em vetores (matrizes de valores numéricos). Você pode pensar em uma incorporação como representando um conjunto de dimensões que cada uma representa algum atributo semântico do token. As incorporações são criadas de tal forma que os tokens que são comumente usados no mesmo contexto definem vetores que estão mais alinhados do que palavras não relacionadas.
Como um exemplo simples, o diagrama a seguir mostra algumas palavras codificadas como vetores tridimensionais e plotadas em um espaço 3D:
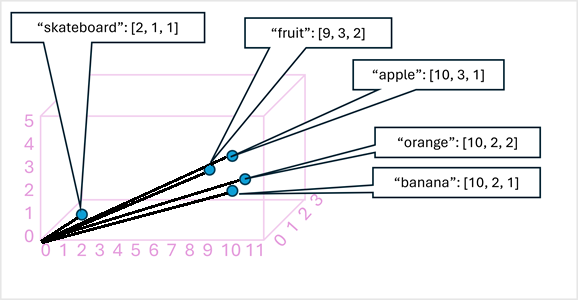
Tokens que são semanticamente semelhantes são codificados em direções semelhantes, criando um modelo de linguagem semântica que torna possível construir soluções sofisticadas de PNL para análise de texto, tradução, geração de linguagem e outras tarefas.
Observação
Usamos apenas três dimensões, porque isso é fácil de visualizar. Na realidade, os codificadores em redes de transformadores criam vetores com muito mais dimensões, definindo relações semânticas complexas entre tokens com base em cálculos algébricos lineares. A matemática envolvida é complexa, assim como a arquitetura de um modelo de transformador. Nosso objetivo aqui é apenas fornecer uma compreensão conceitual de como a codificação cria um modelo que encapsula relações entre entidades.
Modelos multimodais
O sucesso dos transformadores como forma de construir modelos de linguagem levou os pesquisadores de IA a considerar se a mesma abordagem seria eficaz para dados de imagem. O resultado é o desenvolvimento de modelos multimodais, em que os modelos são treinados usando um grande volume de imagens legendadas, sem rótulos fixos. Um codificador de imagem extrai recursos de imagens com base em valores de pixel e os combina com incorporações de texto criadas por um codificador de idioma. O modelo geral encapsula as relações entre incorporações de token de linguagem natural e recursos de imagem, conforme mostrado aqui:
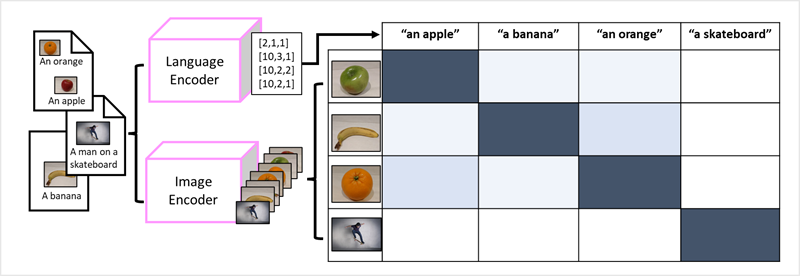
Reunindo tudo
Os modelos de visão modernos são treinados com grandes volumes de imagens legendadas da internet e incluem um codificador de linguagem e um codificador de imagem. Muitas vezes, os usuários interagem e adaptam modelos de fundação . Os modelos de base são modelos gerais pré-treinados nos quais você pode criar vários modelos adaptativos para tarefas especializadas. Por exemplo, você pode adaptar um modelo de fundação para executar:
- Classificação da imagem: Identificar a que categoria pertence uma imagem.
- Deteção de objetos: localizar objetos individuais dentro de uma imagem.
- Descrição de Imagens: Geração de descrições apropriadas de imagens.
- Marcação: Compilar uma lista de tags de texto relevantes para uma imagem.
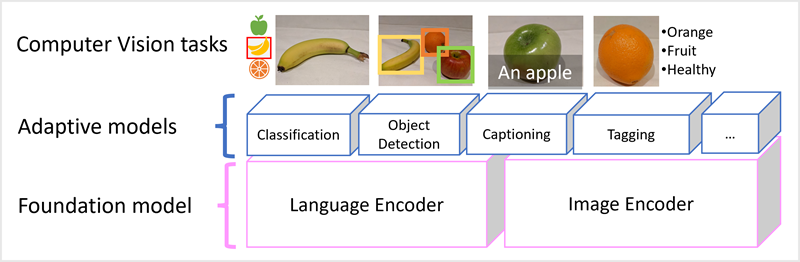
Os modelos multimodais estão na vanguarda da visão computacional e da IA em geral, e espera-se que impulsionem avanços nos tipos de solução que a IA torna possível.