Compreender a extração de dados de imagens
A extração de informações alimentada por IA substitui a necessidade de inspecionar manualmente cada parte do conteúdo em busca de insights. A visão computacional pode extrair insights de imagens para descrever as pessoas, lugares, coisas e palavras que representam.
A visão computacional é possibilitada por modelos de aprendizado de máquina que são treinados para reconhecer recursos com base em grandes volumes de imagens existentes. Os modelos de aprendizado de máquina processam imagens transformando as imagens em informações numéricas. Em sua essência, os modelos de visão realizam cálculos sobre as informações numéricas, que resultam em previsões do que está nas imagens.
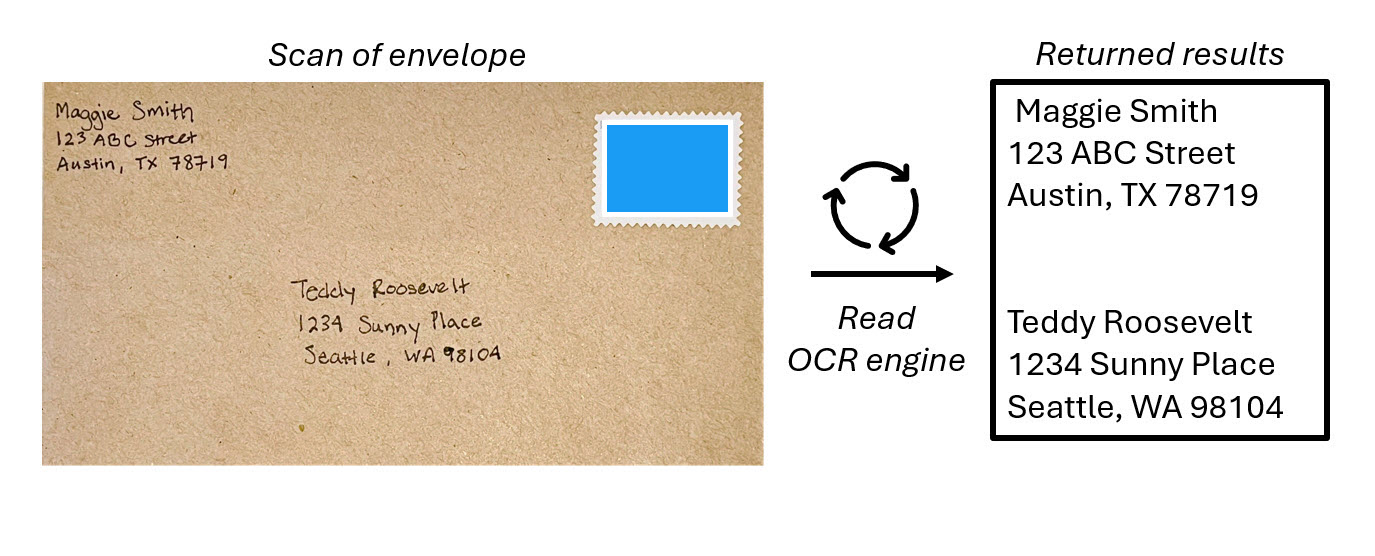
O Reconhecimento Ótico de Caracteres (OCR) ajuda os computadores a reconhecer que um elemento em uma imagem contém texto. OCR é a base do processamento de texto em imagens e usa modelos de aprendizado de máquina que são treinados para reconhecer formas individuais como letras, números, pontuação ou outros elementos de texto. Grande parte do trabalho inicial na implementação deste tipo de capacidade foi realizado pelos serviços postais para apoiar a triagem automática de correio com base em códigos postais. Desde então, o estado da arte para a leitura de texto avançou, e temos modelos que detetam texto impresso ou manuscrito em uma imagem e o digitalizam linha por linha e palavra por palavra.
Observação
Os conceitos de aprendizagem automática associados à visão são abordados em profundidade na Introdução aos conceitos de visão computacional.
Em seguida, vamos ver como os dados são extraídos de formulários com técnicas que se baseiam em OCR.